【笔记】什么是预排序遍历树算法(MPTT)
在了解什么是『**预排序遍历树算法**』之前,我们先思考一个问题如何处理『**多级分类的子分类查询**』。例如: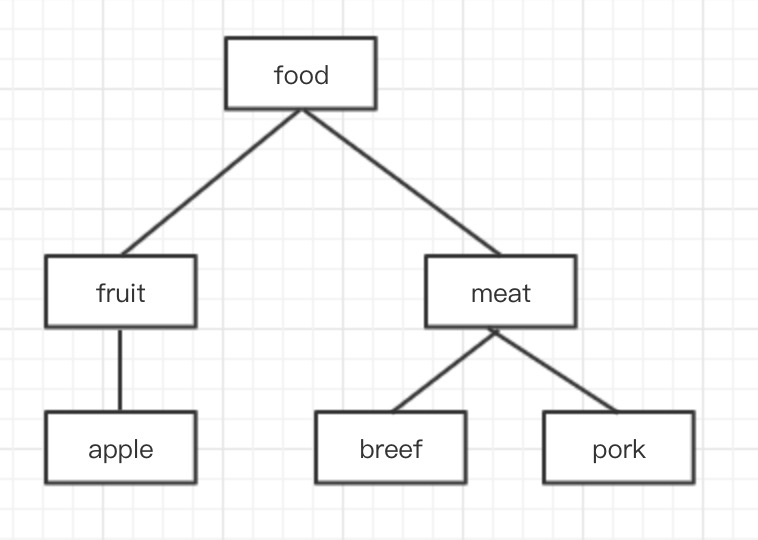
我们,要存储途中数据表示的层级关系,一种最简单的方案,存储当前分类的名称,以及上一级分类的名称,通常我们称这种存储结构为『**邻接表**』。
数据库存储结构:
| 分类名称|父级分类|
|--|--|
|food||
|fruit | food |
|meat| food |
|apple| fruit |
|breef| meat|
|pork | meat|
这种方式有什么问题:**查询效率过低**。当我们在程序里查询 food 的子分类时,要先在数据库中,查询 food 的一级子分类(fruit、meat)、在对一级分类的子分类进行递归查询,需要进行 logN 次( N 为子分类个数) I/O 操作(向数据库进行查询),这样的查询效率不高,但是很容易实现。
而 MPTT 预排序生成树算法正是为了解决多层级关系数据的查询效率问题。
# MPTT 是什么?
MPTT(Modified Preorder Tree Taversal)预排序遍历树算法,主要应用于层级关系的存储和遍历。
在 MPTT 中是如何表示层级关系的:
!(https://img-blog.csdnimg.cn/20191108145727149.png)
MTTP 不直接存储父分类信息,而是通过 left、right 指来表示层级关系。
还是以 food 为例,我们从头开始构建一棵『**预排序遍历树**』。
```sql
# 创建数据表,left_value、right_value 表示左右子树区间
CREATE TABLE `product_category` (
`id` int(11) NOT NULL AUTO_INCREMENT,
category_name varchar(20) not null,
left_value int(10) not null,
right_value int(10) not null,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
```
然后开始插入 food 的一级子分类,根据当前分类的 left_value 来确定插入分类的左右值,同时更新受影响的其他分类。
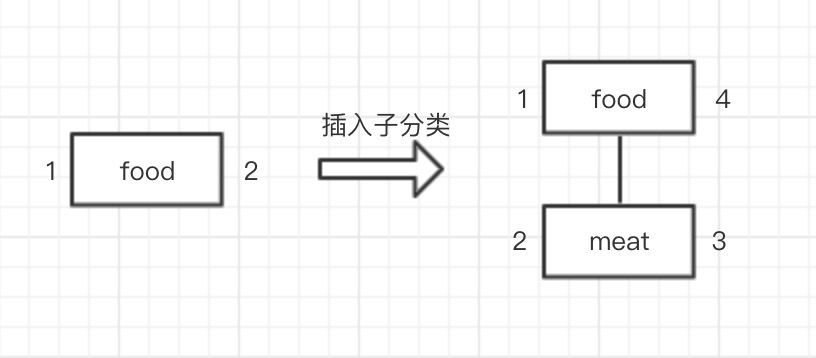
**show code,插入子分类**
```sql
INSERT into product_category(category_name,`left_value`,`right_value`)
values('food',1,2); # 插入 food 数据
# 锁表,防止被同时修改,数据不一致
lock table `product_category` write;
# 插入 food 子分类
select @myLeft := `left_value`
from `product_category`
where category_name='food';
# 更新其他收影响分类左右区间值
update product_category SET left_value=left_value+2
where left_value>@myLeft;
update product_category set right_value=right_value+2
where right_value>@myLeft;
# 插入子分类信息
INSERT into product_category(category_name,`left_value`,`right_value`)
values('meat',@myLeft+1,@myLeft+2);
unlock tables; # 解除表锁定
```
除了插入子分类的方式,我们还可以选择 **插入同级分类**,和插入子分类的区别在于,插入点的左右值取决于被插入点的 right_value。
```sql
# 插入 meat 同级分类
lock table `product_category` write;
select @myRight := `right_value`
from `product_category`
where category_name='meat';
update product_category SET left_value=left_value+2
where left_value>@myRight;
update product_category set right_value=right_value+2
where right_value>@myRight;
INSERT into product_category(category_name,`left_value`,`right_value`)
values('fruit',@myRight+1,@myRight+2);
unlock tables;
```
**删除指定分类**,也等于删除包括指定分类在内的所有子分类,所有受影响左右子分类都受影响。
```sql
# 删除 meat 分类
lock table `product_category` write;
select @myLeft:= `left_value`,@myRight:= `right_value`,@myDiff:=@myRight-@myLeft+1
from `product_category`
where `category_name`='meat';
delete from `product_category`
where `left_value`>=@myLeft and `right_value`<=@myRight;
update `product_category`
set `right_value`=`right_value`-@myDiff
where `right_value`>@myRight;
update `product_category`
set `left_value`=`right_value`-@myDiff
where `left_value`>@myLeft;
unlock tables;
```
那如何 **查询指定分类的子分类** 呢?
```sql
select @myLeft:= `left_value`,@myRight:= `right_value`
from `product_category`
where `category_name`='meat'; # 指定分类名称
select *
from `product_category`
where `left_value`>=@myLeft and `right_value`<=@myRight; # 不包括指定分类,去掉等号即可
```
通过 MPTT 我们查询某一特定分类的子分类信息只要做两次查询操作,解决了『**邻接表**』递归查询的低效查询问题。
# 『**邻接表**』和『**预排序遍历树**』的优劣
『**邻接表**』,适用于 **增删改** 操作较多的场景,每次删改只需要修改一条数据。在查询方面,随着 **分类层级的增加**『**邻接表**』的递归查询效率逐渐降低。
『**预排序遍历树**』,适用于 **查询** 操作较多的场景,**查询的效率不受分类层级的增加的影响**,但是随着数据的增多,每增删数据,都要同时操作多条受影响数据,执行效率逐渐下降。
具体要选择哪一种存储结构和算法,需要根据具体的应用场景来做选择。 6666666666666~ {:301_973:}一看到算法头就大 感谢分享,叉叉树 唯我独宅 发表于 2019-11-9 10:29
一看到算法头就大
严格来说这个只是解决特定场景的一种方式
页:
[1]