逆向笔记之C基础(二)
# 逆向笔记之C基础(二)本文笔记均来自于对滴水逆向教程的学习,通过学习教程记录的笔记,个人所见所得。
## 内存图

## 数据类型与数据存储
| C语言数据类型 | 汇编数据宽度 |
| ------------- | ------------ |
| char | byte |
| short | word |
| int | dword |
| long | dword |
1. 无符号跟有符号,在内存中存储的是一样的,根据使用的人来决定
2. 默认有符号,**类型转换--比较大小--数学运算要注意**
3. 有符号跟无符号,比较会改掉,jbe跟jle 低于等于,小于等于
### 浮点类型
这部分就是计算机组成原理
float的存储方法
12.5 在内存中存储为
整数部分: 12
| 计算 | 余数 |
| ------ | ---- |
| 12/2=6 | 0 |
| 6/2=3| 0 |
| 3/2=1| 1 |
| 1/2=0| 1 |
从下往上: 1100
小数部分: 0.5
| 计算 | 小数 |
| --------- | ---- |
| 0.5*2=1.0 | 1 |
从上往下:1
1100.1=1.1001*2的3次方
1位符号位 中间8位指数 后面23位尾数
尾数从左往右写就行
中间8位开头,左移为1,右移为0,
后面7位,存储指数-1,比如3次方,就是存10,如果是-2次方就是-3,也就是fd, 11111101,然后只取后7位
127 +(3) = 130 = 0x82 = 1000 0010 这里直接加指数
0 10000010 10010000000000000000000
0100 0001 0100 1000 0000 0000 0000 0000
41480000
如果是-12.5呢
就变成
1100 0001 0100 1000 0000 0000 0000 0000
C1480000
###练习
将CallingConvention.exe逆向成C语言
```c
int __fastcall Add5(int num1, int num2, int num3, int num4, int num5)
{
int result1 = Add3(num1, num2, num3);//8
int result2 = Add2(num1, num2);//4
return Add2(result1, result2);//12=c
}
int __cdecl Add2(int num1, int num2)
{
return num1+num2;
}
int __stdcall Add3(int num1, int num2, int num3)
{
return num1+num2+num3;
}
int main()
{
int result1 = Add5(1,3,4,6,7);
printf("%d", result1);
}
```
## 编码
ASCII 英文字符
GB2312或GB2312-80 中文字符,两个字节一个汉字
#### 练习
截取字符串
比如 china中国verygood天朝nice
fn(5) = china
fn(6) = china中
fn(8) = china中国v
```c
#include <stdio.h>
#include <string.h>
char str[]= {"china中国verygood天朝nice"};
int getString(int length)
{
int have=0;
int all = sizeof(str)/sizeof(char);
// 不能超过length,和总长度all
char temp;
for(int i=0; have < length && i < all; i++)
{
if(str >= 'A' && str <= 'z')
{
printf("%c", str);
}
else
{
printf("%c%c%c", str, str, str);
i += 2;
}
have += 1;
}
}
int main()
{
getString(16);
return 0;
}
```
指针做乘法运算
```c
#include <stdio.h>
int main()
{
int a=1;
int *result = (int *)((long)&a * 32) ;
printf("%p", result);
return 0;
}
```
原来强转int *老是说信息丢失报错,改成long就不报错了
## 数组练习
1. 假设现在有5个班,每个班10个人,设计一个二维数组存储这些人的年龄.
2. 如果想知道第二个班的第6个人的年龄,应该如何获取?编译器该如何获取?
3. 打印所有班级,所有学生的年龄(每个班级打印一行).
4. 将第二个班级的超过20岁的学生的年龄修改为21岁.
5. 打印出每个班级学生的年龄的和.
6. 数组一: 数组二:将两个数组中所有数据进行从小到大的排序,存储到另一个数组中.
### 解答
1-5
```c
int age =
{
{1,2,3,4,5,6,7,8,9,10},
{1,21,22,23,5,6,7,8,9,10},
{1,2,3,4,5,6,7,8,9,10},
{1,2,3,4,5,6,7,8,9,10},
{1,2,3,4,5,6,7,8,9,10}
};
void Printf(int array[], int num, int per)
{
for(int i=0; i< num; i++) //class
{
for(int j=0; j<per; j++)
{
printf("%d ", array);
}
printf("\n");
}
}
void setAge(int array[], int age)
{
for(int j=0; j<10; j++)
{
if(array > 20)
array = 21;
}
}
void getAverage(int array[], int num, int per)
{
for(int i=0; i< num; i++) //class
{
int average=0;
for(int j=0; j<per; j++)
{
average += array;
}
printf("%d班:%d\n", i, average/per);
}
}
int main(int argc, char* argv[])
{
int a = age; // age
Printf(age, 5, 10);
printf("\n");
setAge(age, 20);
Printf(age, 5, 10);
printf("\n");
getAverage(age, 5, 10);
return 0;
}
```
6 严格意义并不算归并排序,这里已经有序了,所以只是归并排序的一部分
```c
int array2={3,5,7,9,12,25,34,55};
int array1={4,7,9,11,13,16};
int main(int argc, char* argv[])
{
int result;
int *p = array1;
int *k = array2;
int i=0;
while(i < 14)
{
if(*p > *k)
{
if(*k)
{
result = *k;
k++;
}
else
{
result = *p;
p++;
}
}
else
{
if(*p)
{
result = *p;
p++;
}
else
{
result = *k;
k++;
}
}
i++;
}
for(i=0; i < 14; i++)
{
printf("%d ", result);
}
return 0;
}
```
## 函数
函数的概念

CC是int 3,防止缓冲区溢出,CPU会断下
函数入口

函数的出口:
MOV EAX,DWORD PTR SS:上面的这个函数将计算结果存储到EAX中
ADD EAX,DWORD PTR SS:我们称为返回值
思考:
函数的计算结果除了放在寄存器中,还可以放在什么地方?
还可以通过寄存器传参
#### 裸函数
```C
void __declspec(naked) Plus()
{
}
```
跟空函数不一样
```C
void Plus()
{
}
```
裸函数依旧是个call,不过里面没有内容
```C
void __declspec(naked) Plus()
{
__asm ret
}
```
这样的就可以正常运行,因为这样会retn
#### 手写汇编实现Add函数
```C
int __declspec(naked) Plus(int x, int y)
{
__asm
{
push ebp
mov ebp,esp
sub esp,0x40
push ebx
push edi
push esi
mov eax,0xCCCCCCCC
mov ecx,0x10
lea edi,dword ptr ds:
rep stosd
mov eax,dword ptr ds:
add eax,dword ptr ds:
pop esi
pop edi
pop ebx
mov esp,ebp
pop ebp
ret
}
}
```
####
## if语句逆向分析
### if语句判定
来个影响标志位语句,然后jcc,极有可能就是if语句
c语言与汇编指令是反着来的,比如<=在汇编里就是jg
### if_else判断



### if_else练习
1. 参数 =num1, =num2, =num3
2. 局部变量=0,=1,=2
3. 全局变量无
4. 功能分析直接分析代码
5. 返回值存在eax里,有
```c
int func(int num1, int num2, int num3)
{
int local1=0,local2=1,local3=2;
if(num1 <= num2)
{
local1 = local2-1;
}else if(num2 >= num3)
{
local1 = local3+1;
}else if(num1 > num2)
{
local1 = local2+local3;
}else
{
local1 = local3+local2-1;
}
return local1;
}
```
## 类型转换
movsx 先符号扩展,在传送(有符号用)
```assembly
mov al,0ff
movsx cx,al # 取al的符号位,最前面是1,所以全补1
mov al,80 # 取al符号位,全补0
movsx cx,al
```
movzx 先零扩展,在传送 (无符号用)
```assembly
mov al,0ff
movzx cx,al #只在前面补0
```
```c
void test()
{
char i = 0xff; //用movsx转换
short j = i;
int k = i;
}
```
```c
void test()
{
unsigned char i = 0xff; //用movzx转换
unsigned short j = i;
unsigned int k = i;
}
```
大转小,利用宽度就行,想想内存中如何存值
```c
void test()
{
int i =0x12345678;
short j = i;
char k = i;
}
```
0x0: 78563412 实际存储
short的话,肯定就是5678
char的话肯定就是78
有符号跟无符号相加 变成有符号
无符号跟有符号相加 变成无符号
是以自身为基准
## 结构体
```c
struct AA
{
}
```
返回结构体
```assembly
lea eax,
push eax
call
# 这样利用地址存储返回的结构体
```
### 结构体基础练习
1. 定义一个结构体Gamer用来存储一个游戏中的角色的信息,包括血值、等级、坐标等信息
- 具体包含哪些信息自由设计
- 但这些包含的类型中,必须要有一个成员是结构体类型
2. 定义一个函数,用来给这个结构体变量赋值
3. 定义一个函数,用来显示这个结构体变量的所有成员信息
c语言都没经常写,复习下吧,练练手
```c
struct Point
{
float x;
float y;
float z;
};
struct Gamer
{
int blood;
int level;
Point point;
};
Gamer gamer;
void setGamer(int blood,int level,Point point)
{
gamer.blood = blood;
gamer.level = level;
gamer.point = point;
}
void showGamer()
{
printf("blood is:%d\n", gamer.blood);
printf("level is:%d\n", gamer.level);
printf("point is x:%f,y:%f,z:%f\n", gamer.point.x, gamer.point.y, gamer.point.z);
}
int main(int argc, char* argv[])
{
Point where;
where.x = 1;
where.y = 2;
where.z = 3;
setGamer(1,1,where);
showGamer();
return 0;
}
```
### 结构体对齐
```c
#pragma pack(n)
//结构体 对齐参数:n为字节对齐数,其取值为1、2、4、8,默认是8。
#pragma pack
```
对齐原则:
1. 数据成员对齐规则:结构的数据成员,第一个数据成员放在offset为0的地方,以后每个数据成员存储的起始位置要从该成员大小的整数倍开始(比如int在32位机为4字节,则要从4的整数倍地址开始存储).
2. 结构体的总大小,也就是sizeof的结果,必须是其内部最大成员的整数倍,不足的要补齐。
3. 该成员大小的整数倍开始(比如int在32位机为4字节,则要从4的整数倍地址开始存储).(struct a里存有struct b,b里有char,int,double等元素,那b应该从8的整数倍开始存储.)
4. 对齐参数如果比结构体成员的sizeof值小,该成员的偏移量应该以此值为准.
### 结构体对齐练习
1. 定义一个结构体Monster,能够存储怪的各种信息(至少有一个成员是结构体类型)。
2. 声明一个Monster类型的数组,长度为10.
3. 编写一个函数,为第二题中的数组赋值.
4. 编写一个函数,能够通过怪物ID,打印当前这个怪物的所有信息.
```c
struct Point
{
float x;
float y;
float z;
};
struct Monster
{
int blood;
int level;
Point point;
};
Monster monster;
void setMonster()
{
for(int i=0; i<10; i++)
{
monster.blood = 100;
monster.level = 10;
monster.point.x = 2;
monster.point.y = 3;
monster.point.z = 4;
}
}
void showMonster(int id)
{
printf("blood: %d\n", monster.blood);
printf("level: %d\n", monster.level);
printf("x: %f\n", monster.point.x);
printf("y: %f\n", monster.point.y);
printf("z: %f\n", monster.point.z);
}
int main(int argc, char* argv[])
{
setMonster();
showMonster(2);
return 0;
}
```
#### 分析下面结构体的内存分配
```c
struct S1
{
char c;
double i;
};
struct S2
{
char c1;
S1 s;
char c2;
char c3;
};
struct S3
{
char c1;
S1 s;
char c2;
double c3;
};
struct S4
{
int c1;
char c2;
}
```
S1结构体
结果是16,c按一字节对齐,是c,然后结构体内最大是double,8个字节,所以按8字节补全,合起来16个字节,也就是0x10字节
S2结构体
结果是16+2*8=32=0x20
首先char都是按1字节对齐了,然后S1分析过了,是16字节,整体按double补全,所以开头一个char 补全7个字节,后面两个char,补全6个字节,中间16个字节
S3结构体
结果是16+2*8+8=40=0x28
S1依旧16字节,char c1是1字节,按最大8字节补齐,c2旁边没有,也按8字节补齐,double接上
S4结构体
结果是4+8+4 = 16
char类型数组相当于叠了10个char,所以一个个叠下去最后剩下两个,两个按int补齐,所有就是16字节
#### 总结
大胆猜想,小心论证,做完后实验,与理论相同
## Switch语句逆向
通过这些问题进行学习Switch语句
1. break加与不加有什么特点?default语句可以省略吗?
答: 不加,每个都会执行,可以省略,不过怕会出错
2. 添加case后面的值,一个一个增加,观察反汇编代码的变化(何时生成大表).
3. 将3中的常量值的顺序打乱,观察反汇编代码(观察顺序是否会影响生成大表).
答: 不会
4. 将case后面的值改成从100开始到109,观察汇编变化(观察值较大时是否生成大表).
答: 会,减的常数不同
5. 将连续的10项中抹去1项或者2项,观察反汇编有无变化(观察大表空缺位置的处理).
答: 无,空缺位置填充了default分支
6. 在10项中连续抹去,不要抹去最大值和最小值(观察何时生成小表).
答:大表+小表,达到一定数量会生成小表,小表用来查偏移,直接跳,节省内存
7. 将case后面常量表达式改成毫不连续的值,观察反汇编变化.
答:搜索二叉树,骚啊
总结:
1. switch分支少于4个没意思,因为会生成类似if_else的结构
2. sub ecx,常数,是为了跳转表转向,将其转换成index
3. 4个分支上会生成大表,直接计算地址,而大表需要连续的数值判断,如果相隔太大,会生成if_else结构
### 练习
#### 写一个switch语句,不生产大表也不生产小表,贴出对应的反汇编
这个分支少于4个就会生成if_else结构
```assembly
8: switch(num)
9: {
0040D708 mov eax,dword ptr
0040D70B mov dword ptr ,eax
0040D70E cmp dword ptr ,1
0040D712 je func+32h (0040d722)
0040D714 cmp dword ptr ,2
0040D718 je func+41h (0040d731)
0040D71A cmp dword ptr ,3
0040D71E je func+50h (0040d740)
0040D720 jmp func+5Dh (0040d74d)
10: case 1:
11: printf("1\n");
0040D722 push offset string "1\n" (00422024)
0040D727 call printf (00401060)
0040D72C add esp,4
12: break;
0040D72F jmp func+5Dh (0040d74d)
13: case 2:
14: printf("2\n");
0040D731 push offset string "2\n" (00422020)
0040D736 call printf (00401060)
0040D73B add esp,4
15: break;
0040D73E jmp func+5Dh (0040d74d)
16: case 3:
17: printf("3\n");
0040D740 push offset string "Hello World!\n" (0042201c)
0040D745 call printf (00401060)
0040D74A add esp,4
18: break;
19: }
20: }
```
#### 写一个switch语句,只生成大表,贴出对应的反汇编.
这个分支多于4个就可以生成
```assembly
8: switch(num)
9: {
0040D7B8 mov eax,dword ptr
0040D7BB mov dword ptr ,eax
0040D7BE mov ecx,dword ptr
0040D7C1 sub ecx,1
0040D7C4 mov dword ptr ,ecx
0040D7C7 cmp dword ptr ,3
0040D7CB ja $L590+0Dh (0040d811)
0040D7CD mov edx,dword ptr
0040D7D0 jmp dword ptr
10: case 1:
11: printf("1\n");
0040D7D7 push offset string "1\n" (00422028)
0040D7DC call printf (00401060)
0040D7E1 add esp,4
12: break;
0040D7E4 jmp $L590+0Dh (0040d811)
13: case 2:
14: printf("2\n");
0040D7E6 push offset string "2\n" (00422024)
0040D7EB call printf (00401060)
0040D7F0 add esp,4
15: break;
0040D7F3 jmp $L590+0Dh (0040d811)
16: case 3:
17: printf("3\n");
0040D7F5 push offset string "3\n" (00422020)
0040D7FA call printf (00401060)
0040D7FF add esp,4
18: break;
0040D802 jmp $L590+0Dh (0040d811)
19: case 4:
20: printf("4\n");
0040D804 push offset string "4\n" (0042201c)
0040D809 call printf (00401060)
0040D80E add esp,4
21: break;
22: }
23: }
```
还有一种大表,带default的
```assembly
8: switch(num)
9: {
00401038 mov eax,dword ptr
0040103B mov dword ptr ,eax
0040103E mov ecx,dword ptr
00401041 sub ecx,1
00401044 mov dword ptr ,ecx
00401047 cmp dword ptr ,9
0040104B ja $L598+0Fh (004010d3)
00401051 mov edx,dword ptr
00401054 jmp dword ptr
10: case 1:
11: printf("1\n");
0040105B push offset string "1\n" (00422040)
00401060 call printf (004011b0)
00401065 add esp,4
12: break;
00401068 jmp $L598+1Ch (004010e0)
13: /*
14: case 2:
15: printf("2\n");
16: break;
17:
18: case 3:
19: printf("3\n");
20: break;
21: */
22: case 4:
23: printf("4\n");
0040106A push offset string "4\n" (0042203c)
0040106F call printf (004011b0)
00401074 add esp,4
24: break;
00401077 jmp $L598+1Ch (004010e0)
25: case 5:
26: printf("5\n");
00401079 push offset string "5\n" (00422038)
0040107E call printf (004011b0)
00401083 add esp,4
27: break;
00401086 jmp $L598+1Ch (004010e0)
28: case 6:
29: printf("6\n");
00401088 push offset string "6\n" (00422034)
0040108D call printf (004011b0)
00401092 add esp,4
30: break;
00401095 jmp $L598+1Ch (004010e0)
31: case 7:
32: printf("7\n");
00401097 push offset string "7\n" (00422030)
0040109C call printf (004011b0)
004010A1 add esp,4
33: break;
004010A4 jmp $L598+1Ch (004010e0)
34: case 8:
35: printf("8\n");
004010A6 push offset string "8\n" (0042202c)
004010AB call printf (004011b0)
004010B0 add esp,4
36: break;
004010B3 jmp $L598+1Ch (004010e0)
37: case 9:
38: printf("9\n");
004010B5 push offset string "9\n" (00422028)
004010BA call printf (004011b0)
004010BF add esp,4
39: break;
004010C2 jmp $L598+1Ch (004010e0)
40: case 10:
41: printf("10\n");
004010C4 push offset string "10\n" (00422024)
004010C9 call printf (004011b0)
004010CE add esp,4
42: break;
004010D1 jmp $L598+1Ch (004010e0)
43: default:
44: printf("error\n");
004010D3 push offset string "error\n" (0042201c)
004010D8 call printf (004011b0)
004010DD add esp,4
45: break;
46: }
47: }
```
> 004010F15B 10 40 00[.@.
> 004010F5D3 10 40 00..@.
> 004010F9D3 10 40 00..@.
> 004010FD6A 10 40 00j.@.
> 0040110179 10 40 00y.@.
> 0040110588 10 40 00..@.
> 0040110997 10 40 00..@.
> 0040110DA6 10 40 00..@.
> 00401111B5 10 40 00..@.
这是生成的大表,中间被我注释掉的全部生成了default语句
#### 写一个switch语句,生成大表和小表,贴出对应的反汇编.
11个注释掉6个后终于生成了小表
```assembly
8: switch(num)
9: {
00401038 mov eax,dword ptr
0040103B mov dword ptr ,eax
0040103E mov ecx,dword ptr
00401041 sub ecx,1
00401044 mov dword ptr ,ecx
00401047 cmp dword ptr ,9
0040104B ja $L590+0Fh (0040109b)
0040104D mov eax,dword ptr
00401050 xor edx,edx
00401052 mov dl,byte ptr(004010cd)
00401058 jmp dword ptr
10: case 1:
11: printf("1\n");
0040105F push offset string "7\n" (00422030)
00401064 call printf (004011b0)
00401069 add esp,4
12: break;
0040106C jmp $L590+1Ch (004010a8)
13: /*
14: case 2:
15: printf("2\n");
16: break;
17:
18: case 3:
19: printf("3\n");
20: break;
21:
22: case 4:
23: printf("4\n");
24: break;
25:
26: case 5:
27: printf("5\n");
28: break;
29:
30: case 6:
31: printf("6\n");
32: break;
33:
34: case 7:
35: printf("7\n");
36: break;
37: */
38: case 8:
39: printf("8\n");
0040106E push offset string "8\n" (0042202c)
00401073 call printf (004011b0)
00401078 add esp,4
40: break;
0040107B jmp $L590+1Ch (004010a8)
41: case 9:
42: printf("9\n");
0040107D push offset string "9\n" (00422028)
00401082 call printf (004011b0)
00401087 add esp,4
43: break;
0040108A jmp $L590+1Ch (004010a8)
44: case 10:
45: printf("10\n");
0040108C push offset string "10\n" (00422024)
00401091 call printf (004011b0)
00401096 add esp,4
46: break;
00401099 jmp $L590+1Ch (004010a8)
47: default:
48: printf("error\n");
0040109B push offset string "error\n" (0042201c)
004010A0 call printf (004011b0)
004010A5 add esp,4
49: break;
50: }
51: }
```
这就是小表
> 004010CD00 04 04 04....
> 004010D104 04 04 01....
小表查找的语句
```assembly
040104D mov eax,dword ptr
00401050 xor edx,edx
00401052 mov dl,byte ptr(004010cd)
00401058 jmp dword ptr
```
小表就是个存了偏移的表,通过比较,取出相对应的偏移位置,然后在jmp
## 循环语句
1. do..while
2. while
3. for
### 练习
#### 为do..while语句生成的反汇编填写注释.
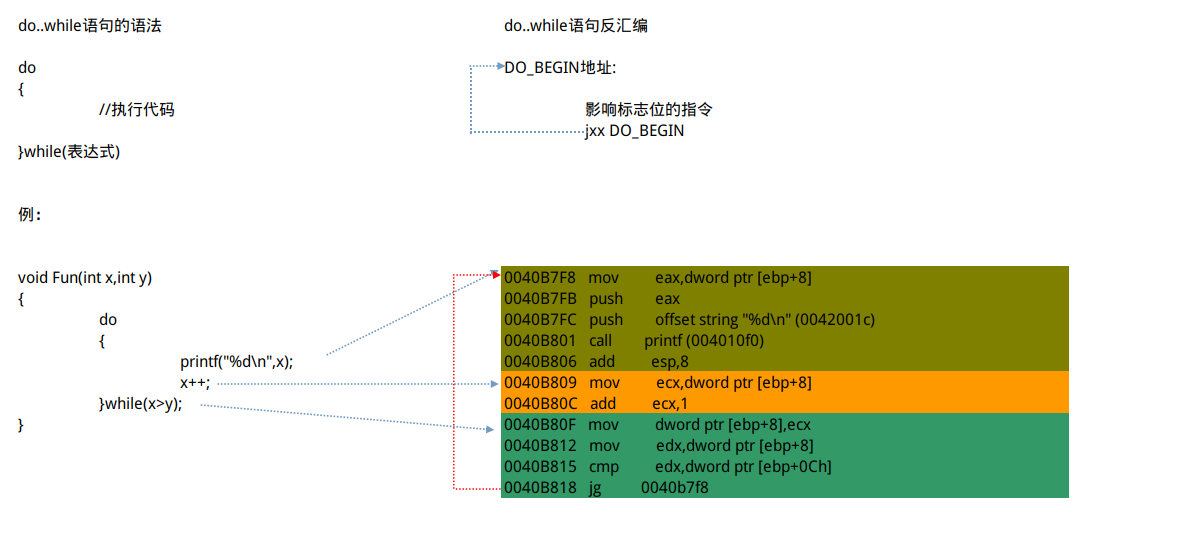
```assembly
9: do{
10: printf("A");
0040103F push offset string "error\n" (0042201c)
00401044 call printf (004011b0)
00401049 add esp,4
11: }while(i++ < 10);
0040104C mov eax,dword ptr
0040104F mov ecx,dword ptr
00401052 add ecx,1
00401055 mov dword ptr ,ecx
00401058 cmp eax,0Ah
0040105B jl func+1Fh (0040103f)
```
do while先执行,后面cmp跳转回去,明显特征,只有往上跳,没有往下跳的
总结:
1. 根据条件跳转指令所跳转到的地址,可以得到循环语句块的起始地址。
2. 根据条件跳转指令所在的地址,可以得到循环语句块的结束地址。
3. 条件跳转的逻辑与源码相同。
#### 为while语句生成的反汇编填写注释.

```assembly
9: while(i++ < 10)
0040103F mov eax,dword ptr
00401042 mov ecx,dword ptr
00401045 add ecx,1
00401048 mov dword ptr ,ecx
0040104B cmp eax,0Ah
0040104E jge func+3Fh (0040105f)
10: {
11: printf("A");
00401050 push offset string "error\n" (0042201c)
00401055 call printf (004011b0)
0040105A add esp,4
12: };
0040105D jmp func+1Fh (0040103f)
```
while语句特征,先cmp比较,然后在执行,最后往上跳,特征,cmp后才会执行
总结:
1. 根据条件跳转指令所跳转到的地址,可以得到循环语句块的结束地址;
2. 根据jmp 指令所跳转到的地址,可以得到循环语句块的起始地址;
3. 在还原while 比较时,条件跳转的逻辑与源码相反。
#### 为for语句生成的反汇编填写注释.
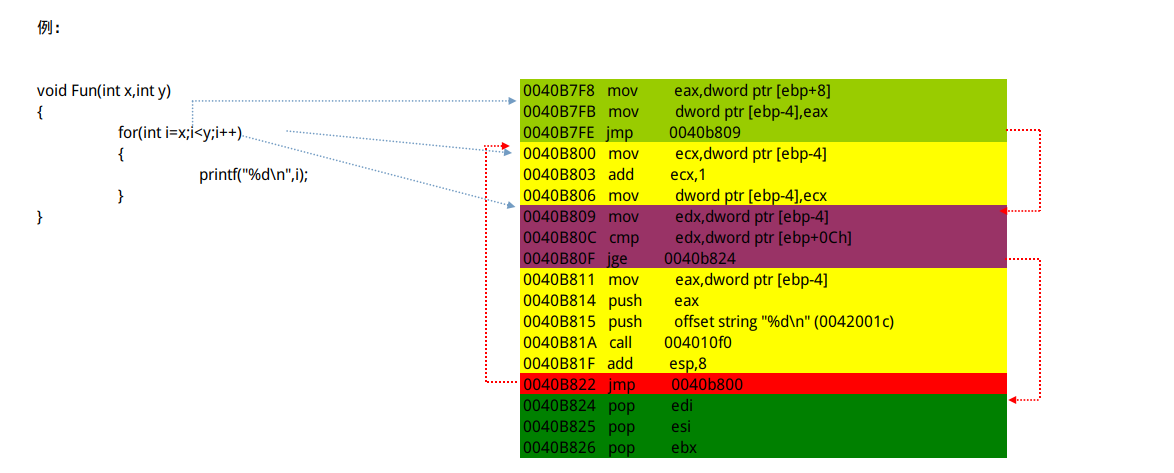
```assembly
9: for(i=0; i<10; i++)
0040103F mov dword ptr ,0
00401046 jmp func+31h (00401051)
00401048 mov eax,dword ptr
0040104B add eax,1
0040104E mov dword ptr ,eax
00401051 cmp dword ptr ,0Ah
00401055 jge func+4Ah (0040106a)
10: {
11: printf("%d" , i);
00401057 mov ecx,dword ptr
0040105A push ecx
0040105B push offset string "1" (0042201c)
00401060 call printf (004011b0)
00401065 add esp,8
12: }
00401068 jmp func+28h (00401048)
```
for循环的话,开头跳去比较,比较过后执行,最后自增
总结:
1. 第一个jmp 指令之前为赋初值部分.
2. 第一个jmp 指令所跳转的地址为循环条件判定部分起始.
3. 判断条件后面的跳转指令条件成立时跳转的循环体外面
4. 条件判断跳转指令所指向的地址上面有一个jmp jmp地址为表达式3的起始位置 不错不错{:1_893:} 收藏了,很基础的,谢谢分享。 赞赞赞,之前学了c之后就不经常用了,现在还得拾回来。 基础知识啊,棒棒 学习了,感谢分享 期待以后的笔记,共同学习 学了一万遍,每次还是从这里开始 学完了,等待更新