DEX文件解析--4、dex类的类型解析
本帖最后由 windy_ll 于 2022-4-1 20:38 编辑# 一、前言
**  前几篇系列文章链接:**
**    (https://www.52pojie.cn/thread-1057245-1-1.html)**
**    (https://www.52pojie.cn/thread-1070218-1-1.html)**
**    (https://www.52pojie.cn/thread-1148568-1-1.html)**
---
# 二、DEX文件中的类的类型
**    1、Dex文件中关于类的类型需要知道字符串是怎么解析的,如果不知道的,可以看一下我的上一篇文章。好了,切入正题,关于类的类型,就是一个对象的所属的类(大概这么理解吧。。。),例如在java中一个字符串,它的类型就是`java/lang/String`。在Dex文件头中,跟类的类型有关的一共有八个字节,分别是位于`0x40`处占四个字节表示类的类型的数量和位于`0x44`处占四个字节表示类的类型索引值的起始偏移地址,如下所示:**
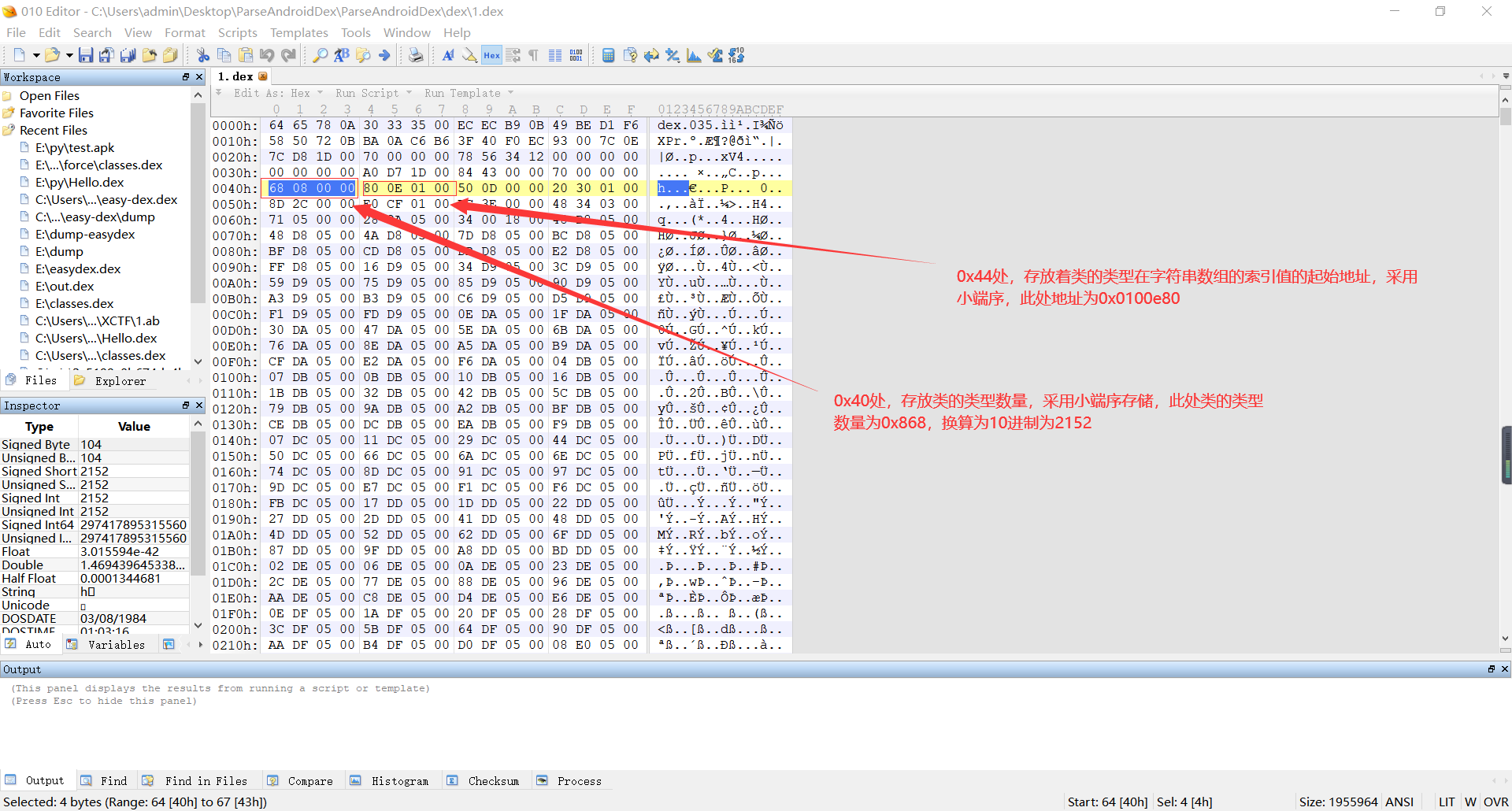
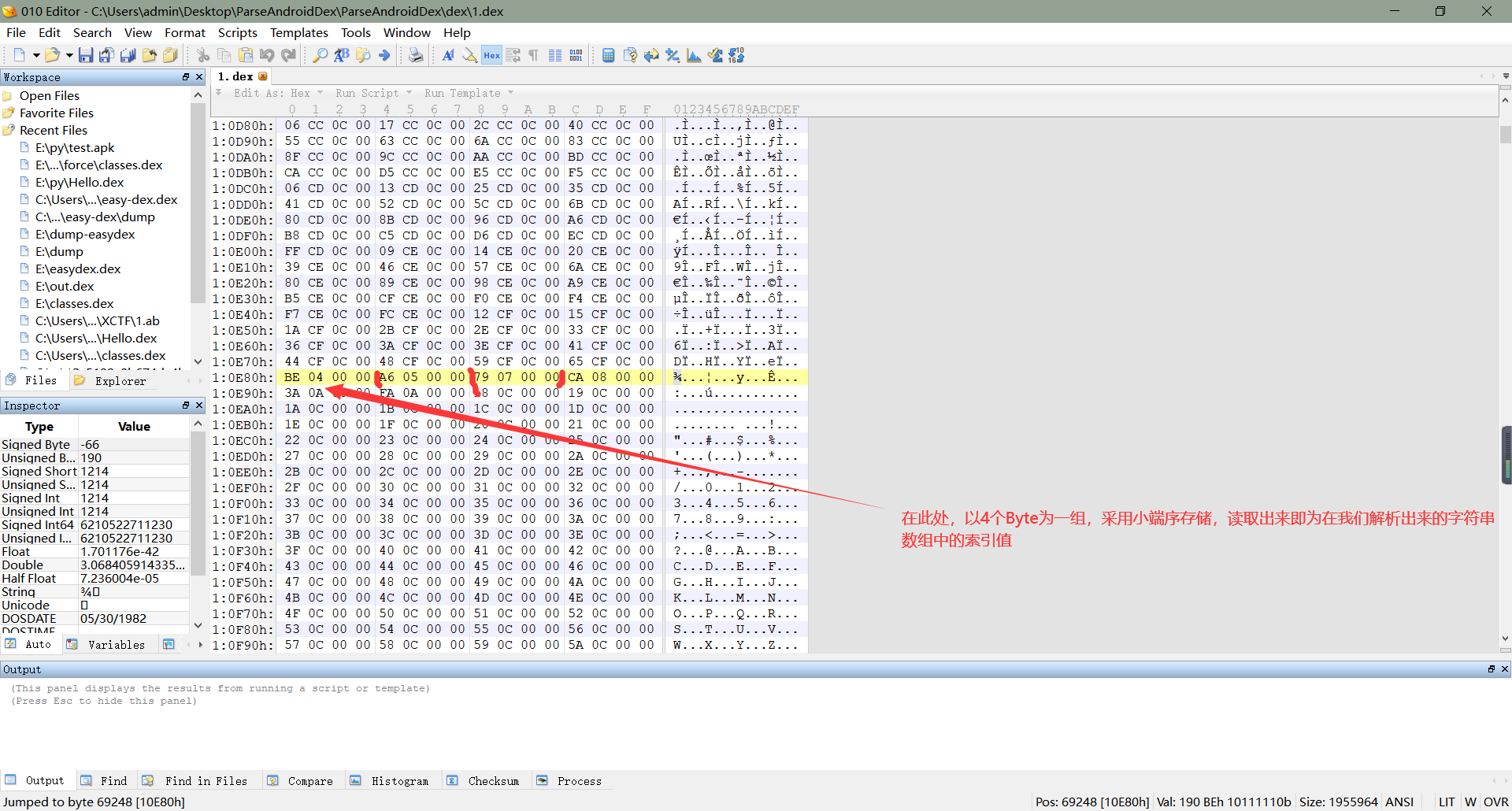
**    2、关于类的类型数量,没什么好说的,只需要注意它是以小端序存储的,读取的时候注意即可。对于类的类型偏移地址,找到偏移地址后,它是以四个字节为一组,对应了在解析出来的字符串数组中的索引值,例如下图中的第一组,它的数据是`BE 04 00 00`,我们读取出来就是`0x04BE`(同样采用的小端序存储),对应的类的类型就是`字符串数组`。**
---
# 三、解析脚本
** PS:我电脑上脚本运行环境python3.6**
**运行效果:**
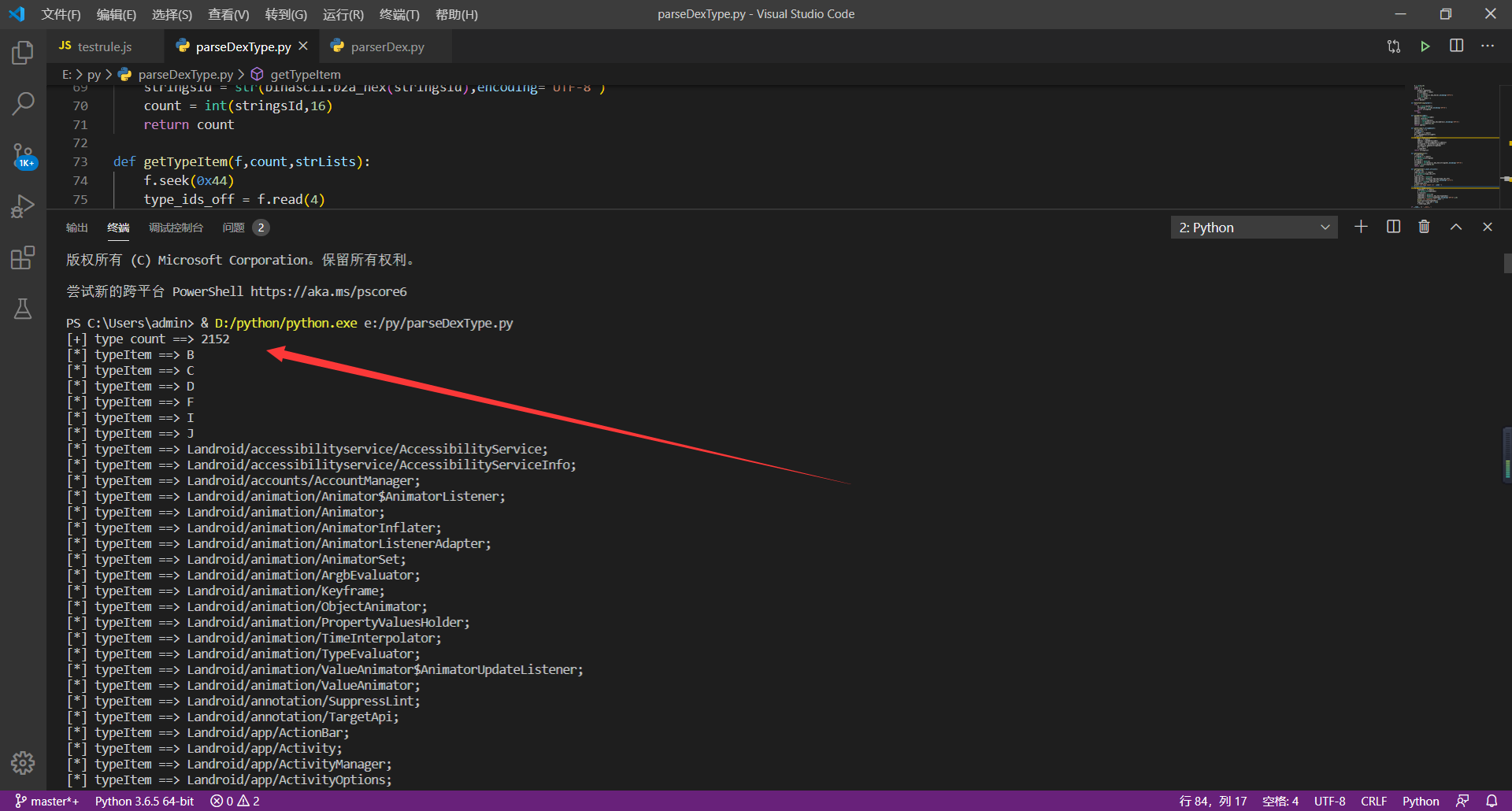
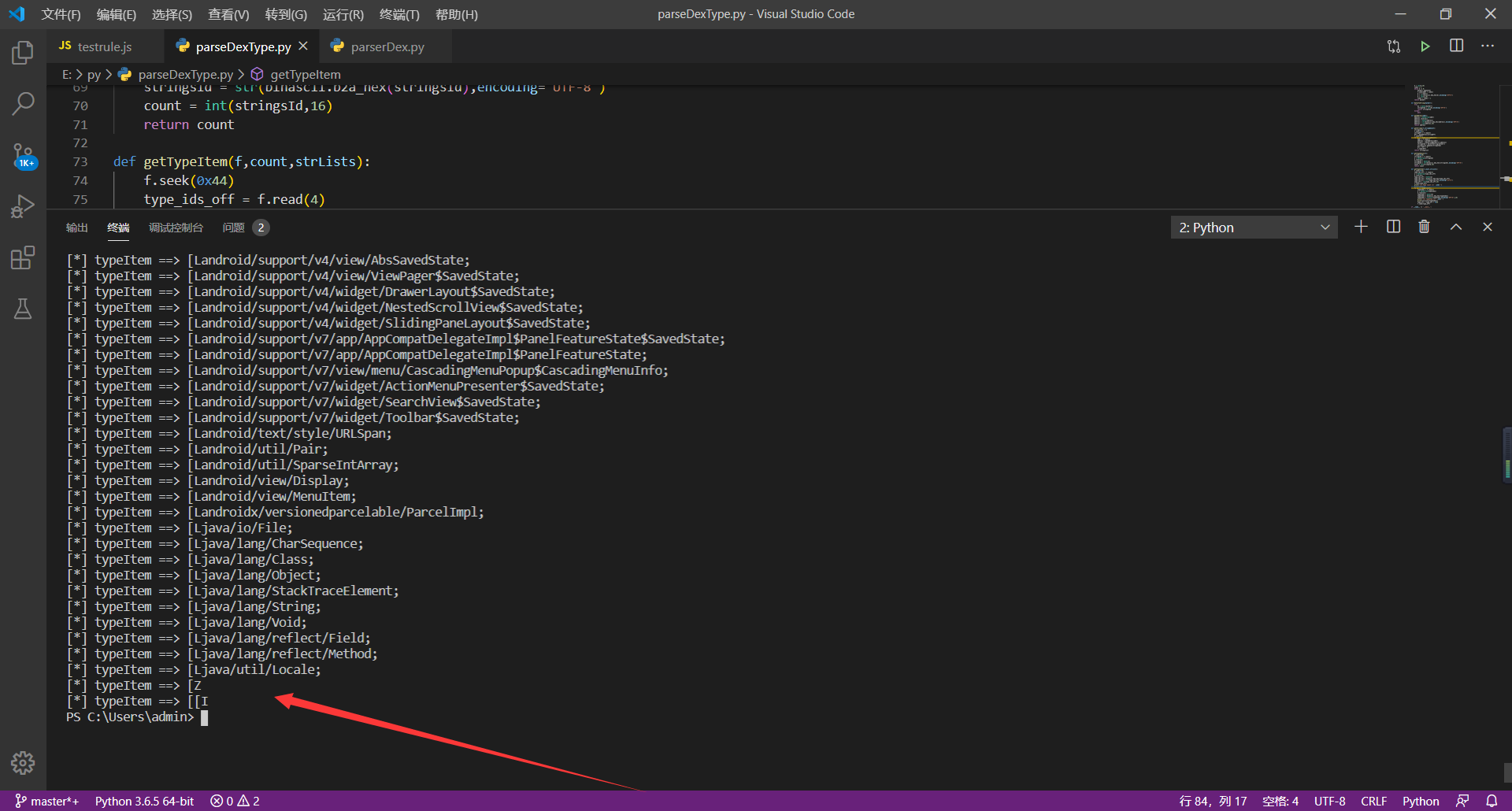
**代码如下:**
import binascii
import os
import sys
def getStringsCount(f):
f.seek(0x38)
stringsId = f.read(4)
a = bytearray(stringsId)
a.reverse()
stringsId = bytes(a)
stringsId = str(binascii.b2a_hex(stringsId),encoding='UTF-8')
count = int(stringsId,16)
return count
def getStringByteArr(f,addr):
byteArr = bytearray()
f.seek(addr + 1)
b = f.read(1)
b = str(binascii.b2a_hex(b),encoding='UTF-8')
b = int(b,16)
index = 2
while b != 0:
byteArr.append(b)
f.seek(addr + index)
b = f.read(1)
b = str(binascii.b2a_hex(b),encoding='UTF-8')
b = int(b,16)
index = index + 1
return byteArr
def BytesToString(byteArr):
try:
bs = bytes(byteArr)
stringItem = str(bs,encoding='UTF-8')
return stringItem
except:
pass
def getAddress(addr):
address = bytearray(addr)
address.reverse()
address = bytes(address)
address = str(binascii.b2a_hex(address),encoding='UTF-8')
address = int(address,16)
return address
def getStrings(f,stringAmount):
stringsList = []
f.seek(0x3c)
stringOff = f.read(4)
Off = getAddress(stringOff)
f.seek(Off)
for i in range(stringAmount):
addr = f.read(4)
address = getAddress(addr)
byteArr = getStringByteArr(f,address)
stringItem = BytesToString(byteArr)
stringsList.append(stringItem)
Off = Off + 4
f.seek(Off)
return stringsList
def getTypeAmount(f):
f.seek(0x40)
stringsId = f.read(4)
a = bytearray(stringsId)
a.reverse()
stringsId = bytes(a)
stringsId = str(binascii.b2a_hex(stringsId),encoding='UTF-8')
count = int(stringsId,16)
return count
def getTypeItem(f,count,strLists):
f.seek(0x44)
type_ids_off = f.read(4)
a = bytearray(type_ids_off)
a.reverse()
type_ids_off = bytes(a)
type_ids_off = binascii.b2a_hex(type_ids_off)
type_ids_off = str(type_ids_off,encoding='utf-8')
type_off = int(type_ids_off,16)
f.seek(type_off)
print('[+] type count ==> ',end='')
print(count)
for i in range(count):
typeIndex = f.read(4)
b = bytearray(typeIndex)
b.reverse()
typeIndex = bytes(b)
typeIndex = binascii.b2a_hex(typeIndex)
typeIndex = int(str(typeIndex,encoding='UTF-8'),16)
print('[*] typeItem ==> ',end='')
print(strLists)
type_off = type_off + 0x04
f.seek(type_off)
if __name__ == '__main__':
filename = str(os.path.join(sys.path)) + '\\1.dex'
f = open(filename,'rb',True)
stringsCount = getStringsCount(f)
strList = getStrings(f,stringsCount)
typeCount = getTypeAmount(f)
getTypeItem(f,typeCount,strList)
f.close()
# 四、样本以及代码下载链接
**  百度网盘:(https://pan.baidu.com/s/1Z1nn8hroxX-2jGaKvhmIZQ);提取码:1eao** geniusrot 发表于 2020-4-8 19:23
比我考大学难多了
要不是国家普及大学教育,估计高中都上不成。在我们的年代,顶多是初中生 厉害啊老兄 顶一下,老哥666,待学习{:1_899:} {:1_907:}比我考大学难多了
感谢分享。楼主辛苦。