DEX文件解析--6、dex文件字段和方法定义解析
本帖最后由 windy_ll 于 2022-4-1 20:32 编辑# 一、前言
**   前几篇文章链接:**
**      (https://www.52pojie.cn/thread-1057245-1-1.html)**
**      (https://www.52pojie.cn/thread-1070218-1-1.html)**
**      (https://www.52pojie.cn/thread-1148568-1-1.html)**
**      (https://www.52pojie.cn/thread-1151528-1-1.html)**
**      (https://www.52pojie.cn/thread-1158006-1-1.html)**
**    PS:阅读之前,最好知道关于dex文件字符串、类的类型以及方法原型是怎么解析出来的!!!**
---
# 二、Dex文件中的字段
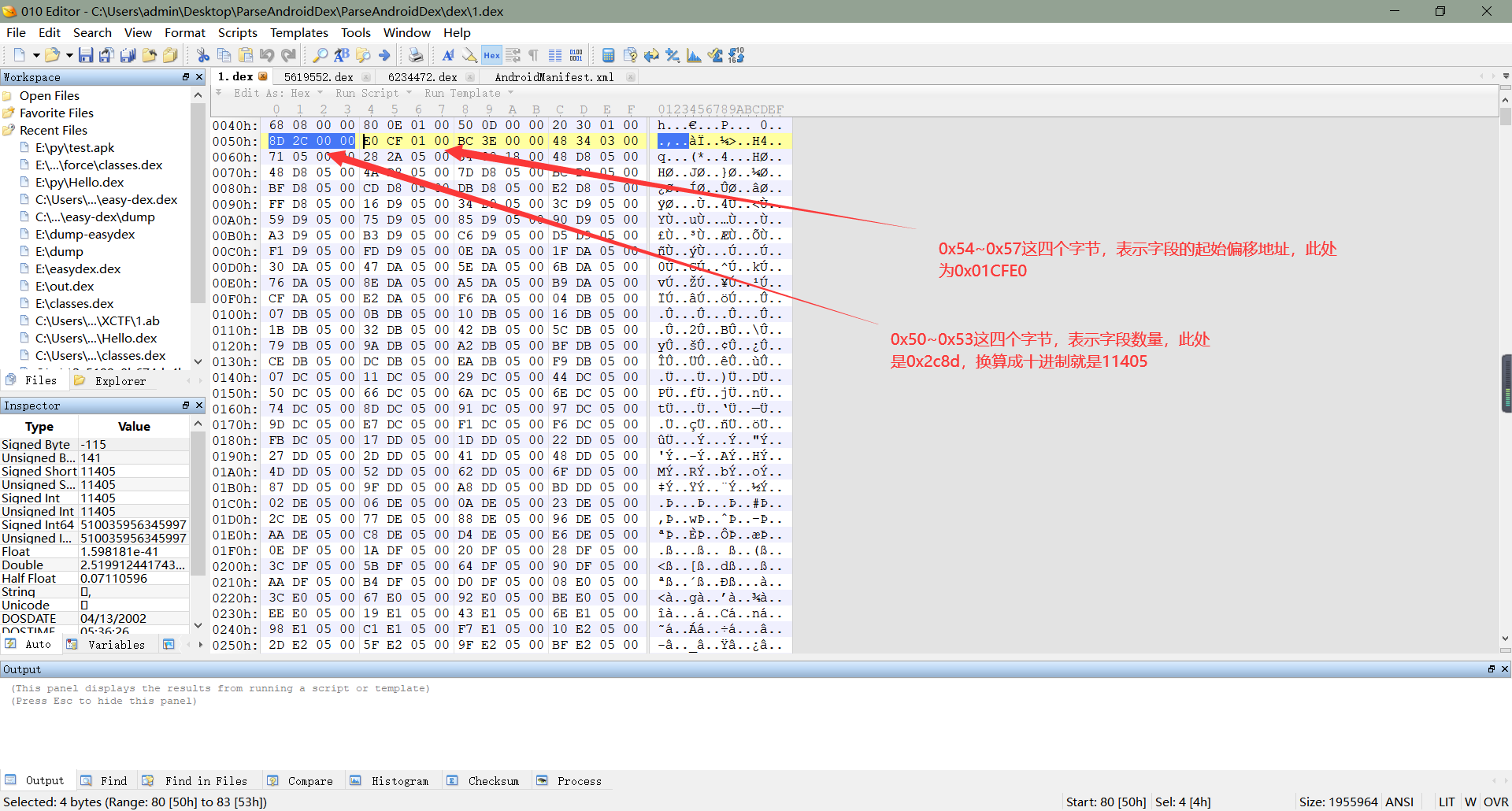
**    1、在dex文件头中,关于字段(ps:字段可以简单理解成定义的变量或者常量)相关的信息有8个字节,在`0x50~0x53`这四个字节,按小端序存储这dex文件中的字段数量,在`0x54~0x57`这四个字节,存储这读取字段的起始偏移地址,如下所示:**
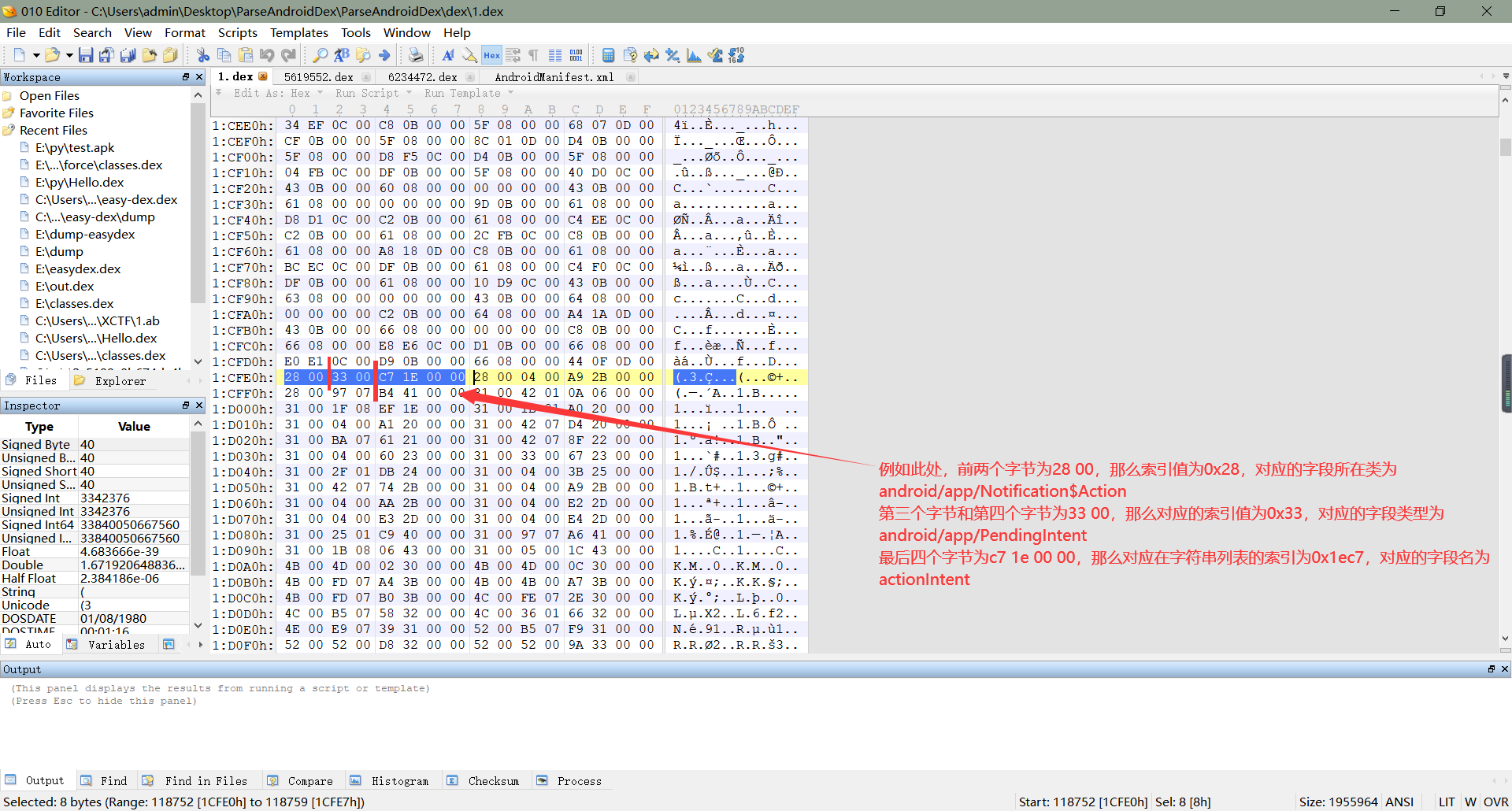
**    2、根据上面的字段起始偏移地址,我们可以找到字段,表示一个字段需要用八个字节,其中,前两个字节为我们在前面解析出来类的类型列表的索引,通过该索引找到的类的类型表示该字段在该类中被定义的(ps:我是这么理解的,如有不对,还请纠正);第三个字节和第四个字节,也是类的类型列表的索引,表示该字段的类型,例如我们在java某个类中定义了一个变量`int a`,那么我们此处解析出来的字段类型就是`int`;最后四个字节,则是我们前面解析出来字符串列表的索引,通过该索引找到的字符串表示字段的,例如我们定义了一个变量`String test;`,那么我们在这里解析出来的就是`test`,如下图所示:**
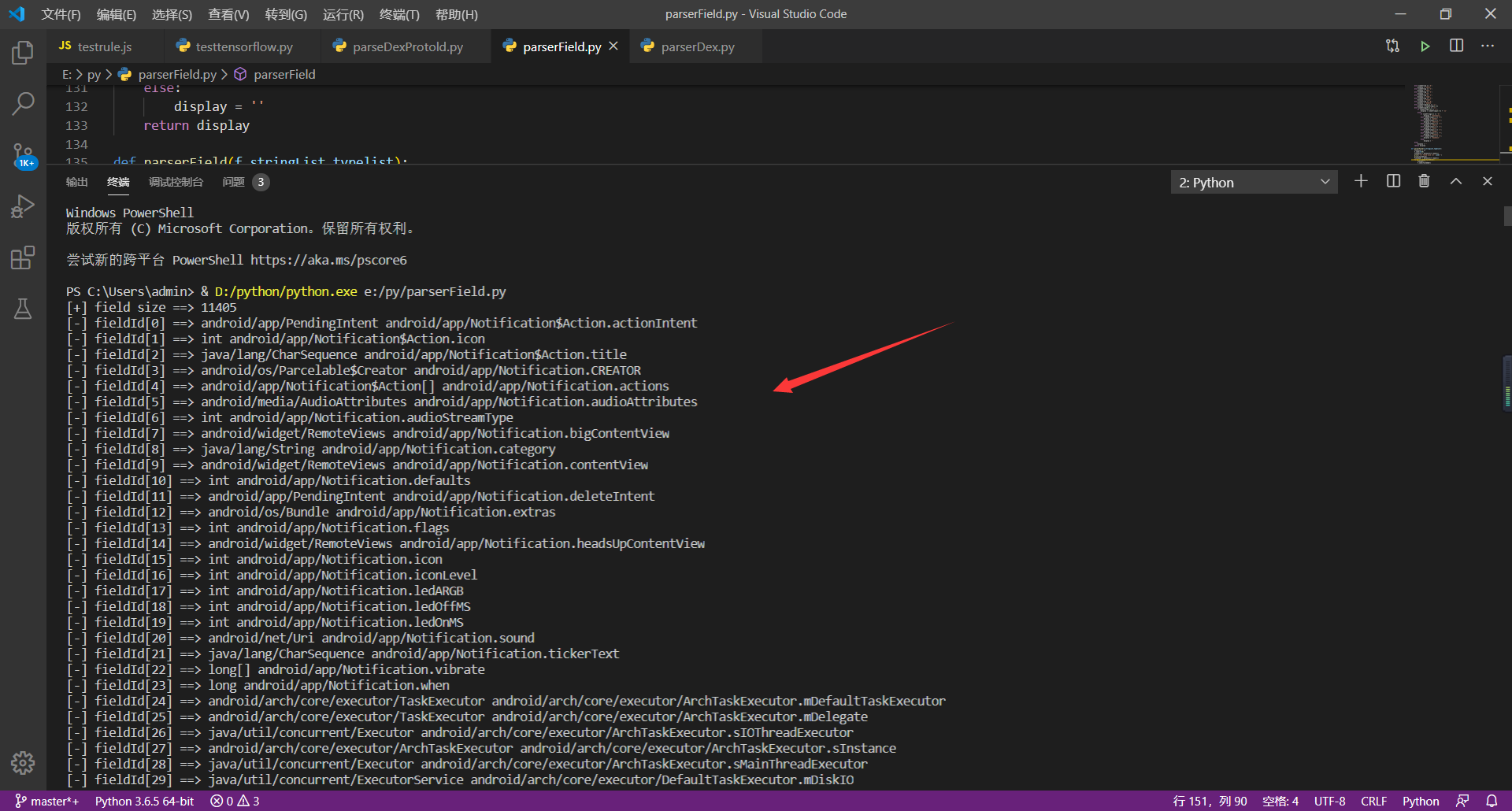
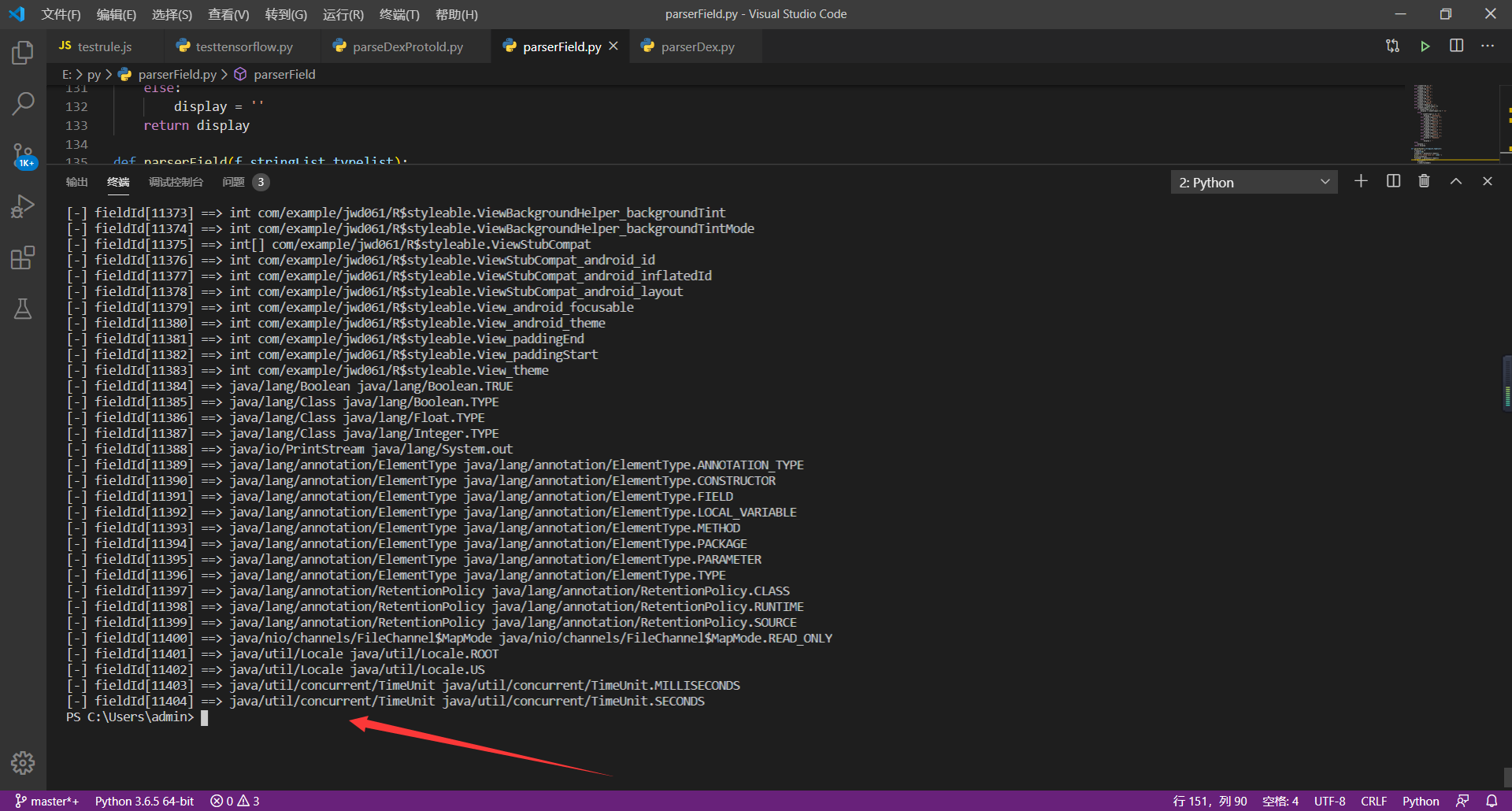
**解析代码运行截图:**
**解析代码:**
import binascii
import os
import sys
def byte2int(bs):
tmp = bytearray(bs)
tmp.reverse()
rl = bytes(tmp)
rl = str(binascii.b2a_hex(rl),encoding='UTF-8')
rl = int(rl,16)
return rl
def getStringsCount(f):
f.seek(0x38)
stringsId = f.read(4)
count = byte2int(stringsId)
return count
def getStringByteArr(f,addr):
byteArr = bytearray()
f.seek(addr + 1)
b = f.read(1)
b = str(binascii.b2a_hex(b),encoding='UTF-8')
b = int(b,16)
index = 2
while b != 0:
byteArr.append(b)
f.seek(addr + index)
b = f.read(1)
b = str(binascii.b2a_hex(b),encoding='UTF-8')
b = int(b,16)
index = index + 1
return byteArr
def BytesToString(byteArr):
try:
bs = bytes(byteArr)
stringItem = str(bs,encoding='UTF-8')
return stringItem
except:
pass
def getAddress(addr):
address = bytearray(addr)
address.reverse()
address = bytes(address)
address = str(binascii.b2a_hex(address),encoding='UTF-8')
address = int(address,16)
return address
def getStrings(f,stringAmount):
stringsList = []
f.seek(0x3c)
stringOff = f.read(4)
Off = getAddress(stringOff)
f.seek(Off)
for i in range(stringAmount):
addr = f.read(4)
address = getAddress(addr)
byteArr = getStringByteArr(f,address)
stringItem = BytesToString(byteArr)
stringsList.append(stringItem)
Off = Off + 4
f.seek(Off)
return stringsList
def getTypeAmount(f):
f.seek(0x40)
stringsId = f.read(4)
count = byte2int(stringsId)
return count
def getTypeItem(f,count,strLists):
typeList = []
f.seek(0x44)
type_ids_off = f.read(4)
type_off = byte2int(type_ids_off)
f.seek(type_off)
for i in range(count):
typeIndex = f.read(4)
typeIndex = byte2int(typeIndex)
typeList.append(strLists)
type_off = type_off + 0x04
f.seek(type_off)
return typeList
def changeDisplay(viewString):
display = ''
if viewString == 'V':
display = 'void'
elif viewString == 'Z':
display = 'boolean'
elif viewString == 'B':
display = 'byte'
elif viewString == 'S':
display = 'short'
elif viewString == 'C':
display = 'char'
elif viewString == 'I':
display = 'int'
elif viewString == 'J':
display = 'long'
elif viewString == 'F':
display = 'float'
elif viewString == 'D':
display = 'double'
elif viewString == 'L':
display = viewString
elif viewString == '[':
if viewString == 'L':
display = viewString + '[]'
else:
if viewString == 'Z':
display = 'boolean[]'
elif viewString == 'B':
display = 'byte[]'
elif viewString == 'S':
display = 'short[]'
elif viewString == 'C':
display = 'char[]'
elif viewString == 'I':
display = 'int[]'
elif viewString == 'J':
display = 'long[]'
elif viewString == 'F':
display = 'float[]'
elif viewString == 'D':
display = 'double[]'
else:
display = ''
else:
display = ''
return display
def parserField(f,stringList,typelist):
fieldList = []
f.seek(0x50)
fieldSize = byte2int(f.read(4))
print('[+] field size ==> ',end='')
print(fieldSize)
fieldAddr = byte2int(f.read(4))
for i in range(fieldSize):
fieldStr = ''
f.seek(fieldAddr)
classIdx = typelist
f.seek(fieldAddr + 2)
typeIdx = typelist
f.seek(fieldAddr + 4)
nameIdx = stringList
fieldAddr += 8
fieldStr = changeDisplay(typeIdx) + ' ' + changeDisplay(classIdx) + '.' + nameIdx
fieldList.append(fieldStr)
k = 0
for fieldItem in fieldList:
print(f'[-] fieldId[{k}] ==> ',end='')
print(fieldItem)
k += 1
if __name__ == '__main__':
filename = str(os.path.join(sys.path)) + '\\1.dex'
f = open(filename,'rb',True)
stringsCount = getStringsCount(f)
strList = getStrings(f,stringsCount)
typeCount = getTypeAmount(f)
typeList = getTypeItem(f,typeCount,strList)
parserField(f,strList,typeList)
f.close()
---
# 三、Dex文件中的方法定义
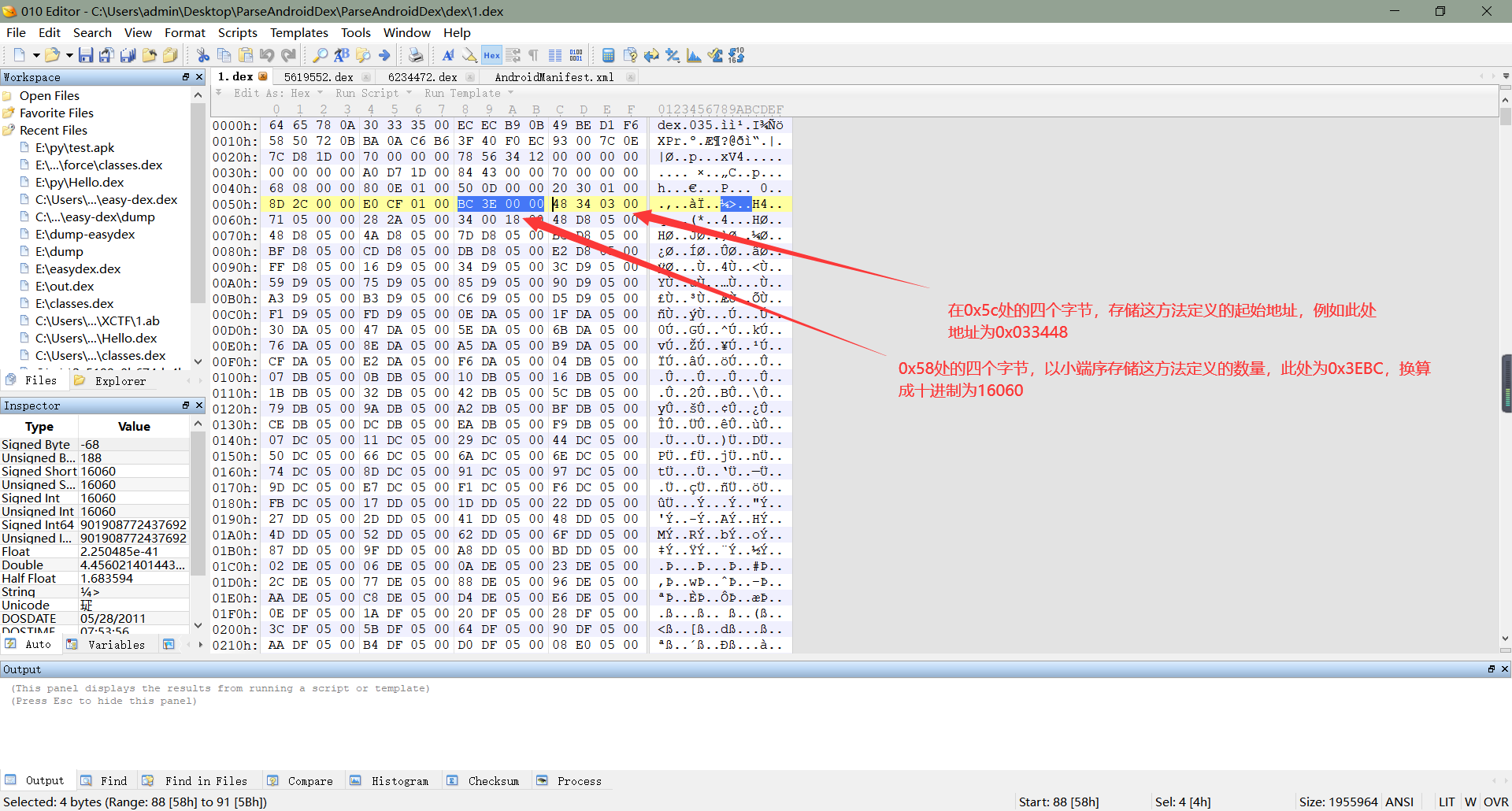
**    1、在dex文件头中,关于方法定义的信息同样是八个字节,分别位于`0x58`处和`0x5c`处。在`0x58`处的四个字节,指明了dex文件中方法定义的数量,在`0x5c`处的四个字节,表明了dex文件中的方法定义的起始地址(ps:都是以小端序存储的),如下图所示:**
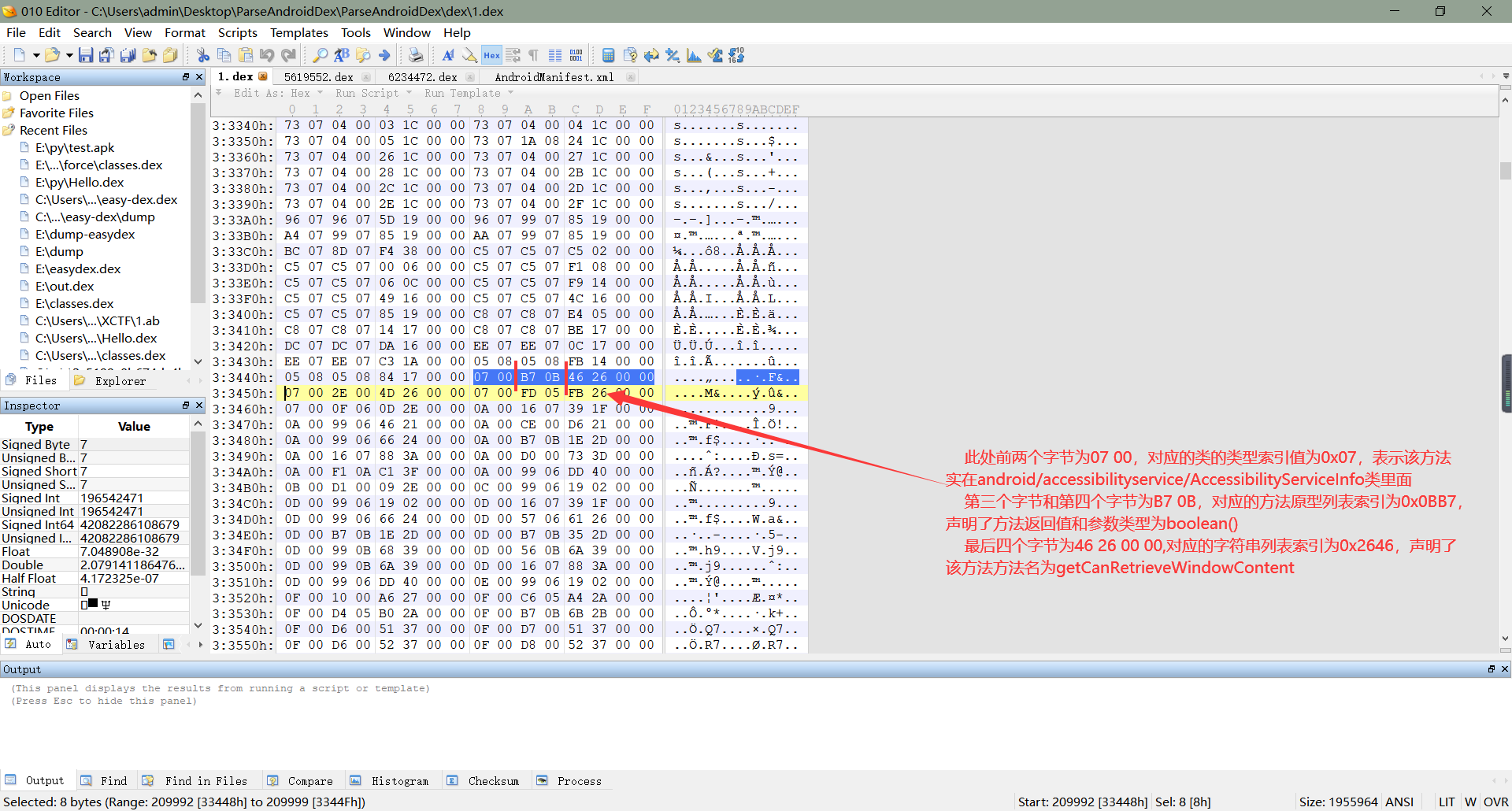
**    2、在上面的一步以及找到了方法定义的起始地址,跟字段类似的,一个方法定义也需要八个字节。其中,在前两个字节,以小端序存储着解析出来的类的类型列表的索引,表示该方法属于哪个类;第三个字节和第四个字节,以小端序存储这解析出来的方法原型列表的索引,通过该索引值找到的方法原型声明了该方法的返回值类型和参数类型;最后四个字节则以小端序存储着前面解析出来的字符串列表的索引,声明了该方法的方法名。如下图所示:**
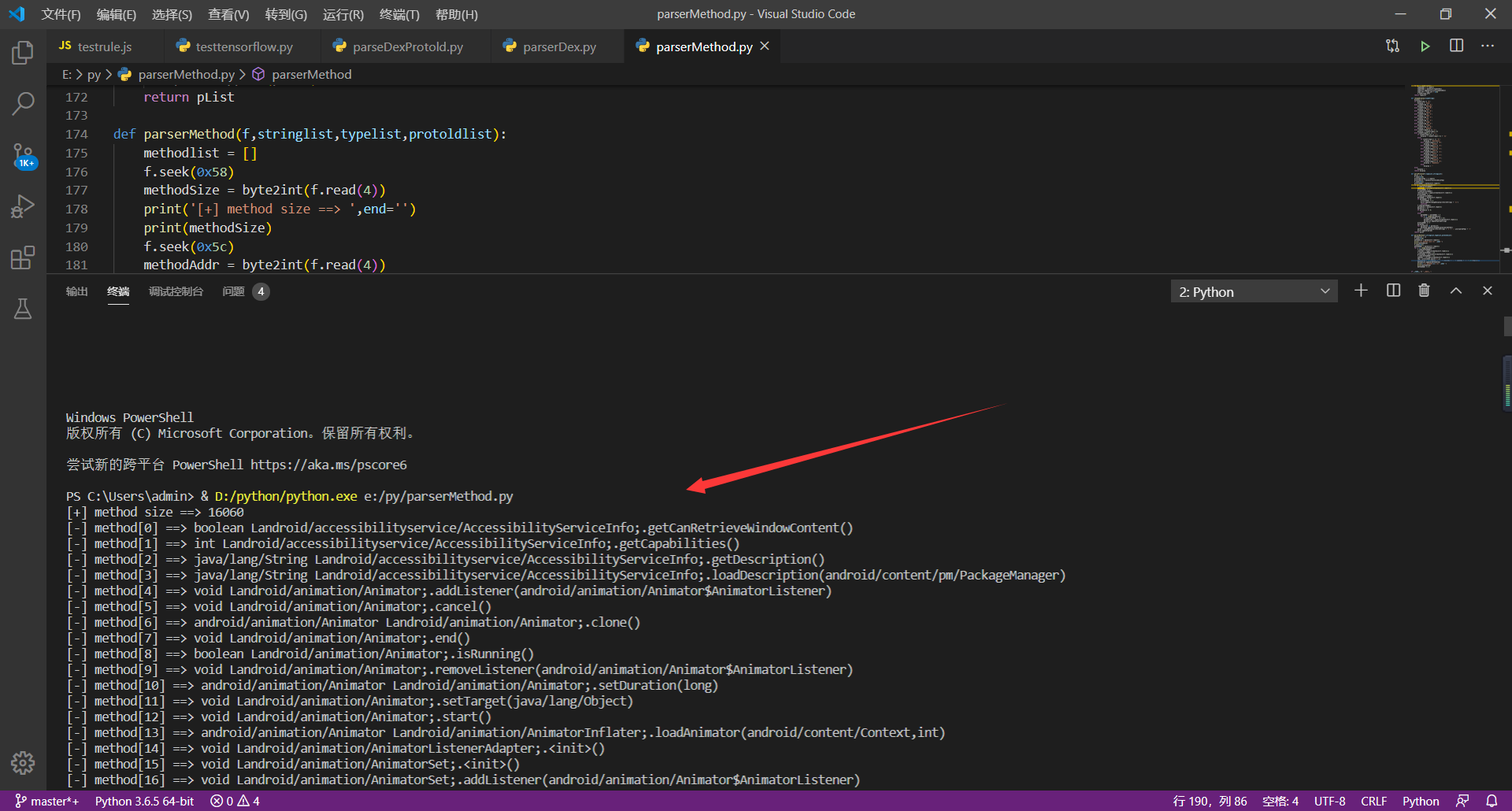
**解析代码运行截图:**
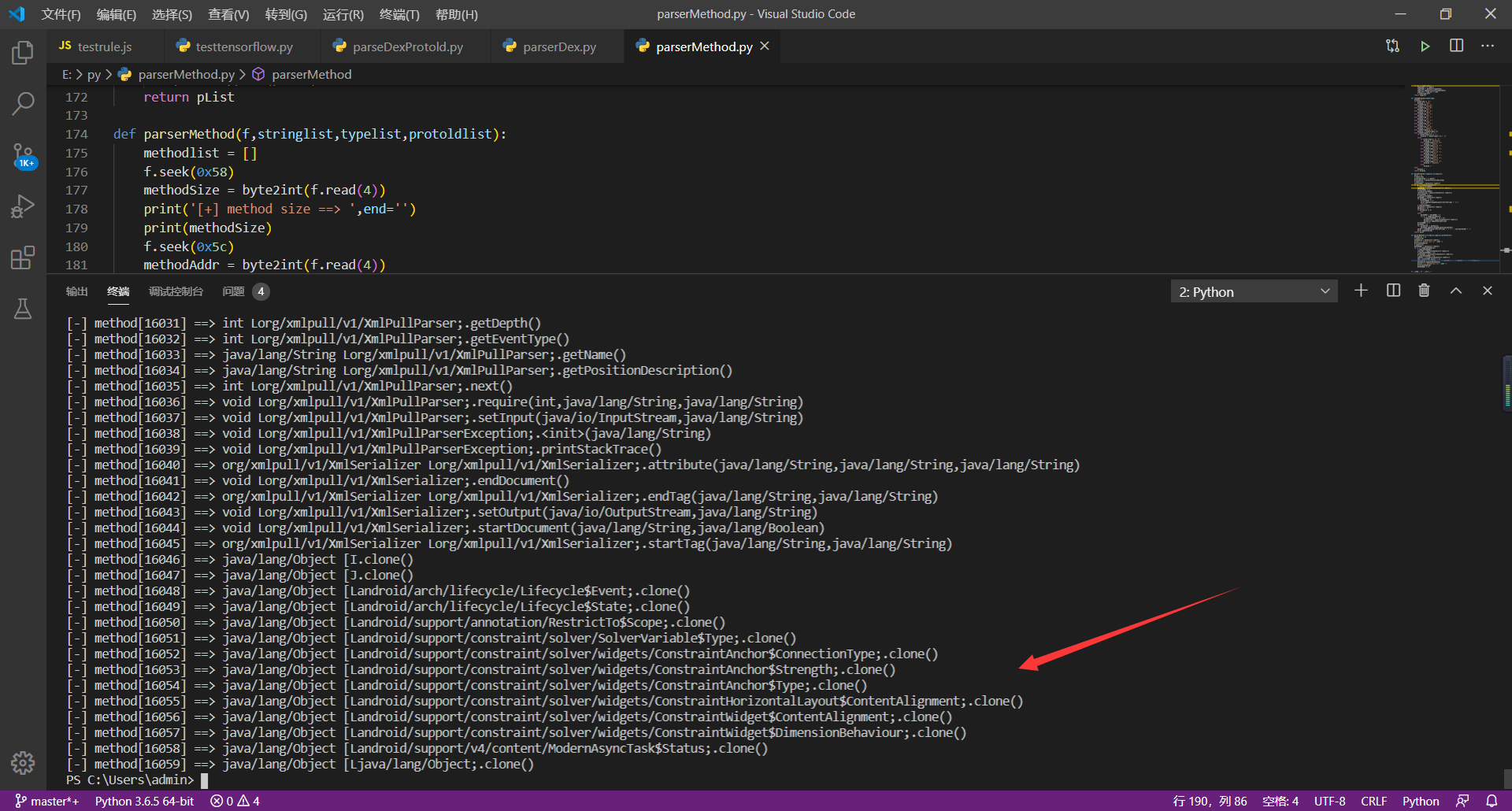
**解析代码:**
import binascii
import os
import sys
def byte2int(bs):
tmp = bytearray(bs)
tmp.reverse()
rl = bytes(tmp)
rl = str(binascii.b2a_hex(rl),encoding='UTF-8')
rl = int(rl,16)
return rl
def getStringsCount(f):
f.seek(0x38)
stringsId = f.read(4)
count = byte2int(stringsId)
return count
def getStringByteArr(f,addr):
byteArr = bytearray()
f.seek(addr + 1)
b = f.read(1)
b = str(binascii.b2a_hex(b),encoding='UTF-8')
b = int(b,16)
index = 2
while b != 0:
byteArr.append(b)
f.seek(addr + index)
b = f.read(1)
b = str(binascii.b2a_hex(b),encoding='UTF-8')
b = int(b,16)
index = index + 1
return byteArr
def BytesToString(byteArr):
try:
bs = bytes(byteArr)
stringItem = str(bs,encoding='UTF-8')
return stringItem
except:
pass
def getAddress(addr):
address = bytearray(addr)
address.reverse()
address = bytes(address)
address = str(binascii.b2a_hex(address),encoding='UTF-8')
address = int(address,16)
return address
def getStrings(f,stringAmount):
stringsList = []
f.seek(0x3c)
stringOff = f.read(4)
Off = getAddress(stringOff)
f.seek(Off)
for i in range(stringAmount):
addr = f.read(4)
address = getAddress(addr)
byteArr = getStringByteArr(f,address)
stringItem = BytesToString(byteArr)
stringsList.append(stringItem)
Off = Off + 4
f.seek(Off)
return stringsList
def getTypeAmount(f):
f.seek(0x40)
stringsId = f.read(4)
count = byte2int(stringsId)
return count
def getTypeItem(f,count,strLists):
typeList = []
f.seek(0x44)
type_ids_off = f.read(4)
type_off = byte2int(type_ids_off)
f.seek(type_off)
for i in range(count):
typeIndex = f.read(4)
typeIndex = byte2int(typeIndex)
typeList.append(strLists)
type_off = type_off + 0x04
f.seek(type_off)
return typeList
def changeDisplay(viewString):
display = ''
if viewString == 'V':
display = 'void'
elif viewString == 'Z':
display = 'boolean'
elif viewString == 'B':
display = 'byte'
elif viewString == 'S':
display = 'short'
elif viewString == 'C':
display = 'char'
elif viewString == 'I':
display = 'int'
elif viewString == 'J':
display = 'long'
elif viewString == 'F':
display = 'float'
elif viewString == 'D':
display = 'double'
elif viewString == 'L':
display = viewString
elif viewString == '[':
if viewString == 'L':
display = viewString + '[]'
else:
if viewString == 'Z':
display = 'boolean[]'
elif viewString == 'B':
display = 'byte[]'
elif viewString == 'S':
display = 'short[]'
elif viewString == 'C':
display = 'char[]'
elif viewString == 'I':
display = 'int[]'
elif viewString == 'J':
display = 'long[]'
elif viewString == 'F':
display = 'float[]'
elif viewString == 'D':
display = 'double[]'
else:
display = ''
else:
display = ''
return display
def parseProtold(f,typeList,stringList):
pList = []
f.seek(0x48)
protoldSizeTmp = f.read(4)
protoldSize = byte2int(protoldSizeTmp)
f.seek(0x4c)
protoldAddr = byte2int(f.read(4))
for i in range(protoldSize):
f.seek(protoldAddr)
AllString = stringList
protoldAddr += 4
f.seek(protoldAddr)
returnString = typeList
protoldAddr += 4
f.seek(protoldAddr)
paramAddr = byte2int(f.read(4))
if paramAddr == 0:
protoldAddr += 4
pList.append(changeDisplay(returnString) + '()')
continue
f.seek(paramAddr)
paramSize = byte2int(f.read(4))
paramList = []
if paramSize == 0:
pass
else:
paramAddr = paramAddr + 4
for k in range(paramSize):
f.seek(paramAddr + (k * 2))
paramString = typeList
paramList.append(paramString)
protoldAddr += 4
paramTmp = []
for paramItem in paramList:
paramTmp.append(changeDisplay(paramItem))
param = changeDisplay(returnString) + '(' + ','.join(paramTmp) + ')'
pList.append(param)
return pList
def parserMethod(f,stringlist,typelist,protoldlist):
methodlist = []
f.seek(0x58)
methodSize = byte2int(f.read(4))
print('[+] method size ==> ',end='')
print(methodSize)
f.seek(0x5c)
methodAddr = byte2int(f.read(4))
for i in range(methodSize):
f.seek(methodAddr)
classIdx = typelist
f.seek(methodAddr + 2)
protoldIdx = protoldlist
f.seek(methodAddr + 4)
nameIdx = stringlist
tmp = protoldIdx.split('(',1)
methodItem = str(tmp) + ' ' + classIdx + '.' + nameIdx + '(' + str(tmp)
methodlist.append(methodItem)
print(f'[-] method[{i}] ==> ',end='')
print(methodItem)
methodAddr += 8
if __name__ == '__main__':
filename = str(os.path.join(sys.path)) + '\\1.dex'
f = open(filename,'rb',True)
stringsCount = getStringsCount(f)
strList = getStrings(f,stringsCount)
typeCount = getTypeAmount(f)
typeList = getTypeItem(f,typeCount,strList)
protoldList = parseProtold(f,typeList,strList)
parserMethod(f,strList,typeList,protoldList)
f.close()
---
# 四、样本及代码下载链接和一些总结
**  1、没什么好总结的,需要说明的是上面所有代码我电脑运行环境为python3.6。**
**  2、下载链接:**
**    百度网盘链接:(https://pan.baidu.com/s/1qBgyy5b6Kw2GOmEY9idKqQ),提取码:u2ux** 居然没人回复,帮暖 谢谢楼主分享! 学习了,感谢楼主 学习了 感谢分享 windy_ll师傅是图床炸了吗?{:301_997:} 正己 发表于 2022-4-1 22:51
windy_ll师傅是图床炸了吗?
图床炸了,刚迁完图床
页:
[1]