[教程向]python爬取吾爱破解热门帖子题目地址,无正则
本帖最后由 Ldfd 于 2020-7-22 08:57 编辑主要是小白实践实践,天天爬小说都烂大街了(本身都是一样的)
吾爱上恕我直言,没有正了八经的小白爬虫
(我认为不用正则也就requests+bs 或 selenium,利用selector好像不怎么灵活,xpath没用过)
# 准备
## 软件准备
1.python 3.x
2.pycharm——最强IDE?
## python库准备
1.requests 干啥啥必备,指名道姓urllib你个辣鸡
[官方文档](https://requests.readthedocs.io/zh_CN/latest/)
2.bs4 注:虽然库是Beautiful Soup ,但是鬼知道官方整个bs4还得from import干什么
[官方文档](https://beautifulsoup.readthedocs.io/zh_CN/latest/)
3.lxml 虽说python内置的解析器已经凑合能用了,但这是优良传统
注:这是一个神奇的库,只需安装,不需引用
~~4.用不到的selenium(js动态加载必备)~~
5.tqdm 用于显示进度条,美化用
```python
pip install requests
pip install bs4
pip install lxml
```
当然还可以用pycharm的库管理器安装,记得提前换个清华/阿里源
ps:官方文档会让你迷茫的时候,看不懂一帮憨憨讲什么的时候,恍然大悟
# 知识
感觉没什么说的
```
url——域名
<xxx></xxx>——标签
<xxx>看我</xxx>——看我是元素
<example shuxing="shuxing"></example>——shuxing="shuxing"便是属性,用于爬虫确定标签位置,毕竟谁也不可能就那么一个标签
```
论坛的“ < ”“>显示好像不太好
某些网站会用些实体字符就是形如 &example这种
w3school提供手册[](https://www.w3school.com.cn/tags/html_ref_entities.html)
查查更健康
# 实践
## 下载网页
这个比较简单,只需要requests就可以实现
比如先爬一下https://www.52pojie.cn/的首页
网站还是比较友好的,没有对新手太过苛刻,但是呢,爬虫也是一样,没事别老整什么多发线程
你以为你cc攻击呐,鸡眼了,有你好果子吃
```python
import requests
html = requests.get('https://www.52pojie.cn')
print(html.text)
```
这里注意print时html后面需要加.text输出源码,不加会输出什么呢?可以试一试
(~~不加是状态码小声BB~~)
然后,你就得到了一大堆,有什么用呢,没什么用
这时一个舒服的筛选工具就很必要了
## 筛选
由于上面52pojie.cn的首页四块class都相同,不便于区分,不爬了快跑(不到啊)
https://www.52pojie.cn/forum.php?mod=guide&view=hot这看起来是个软柿子
F12看结构
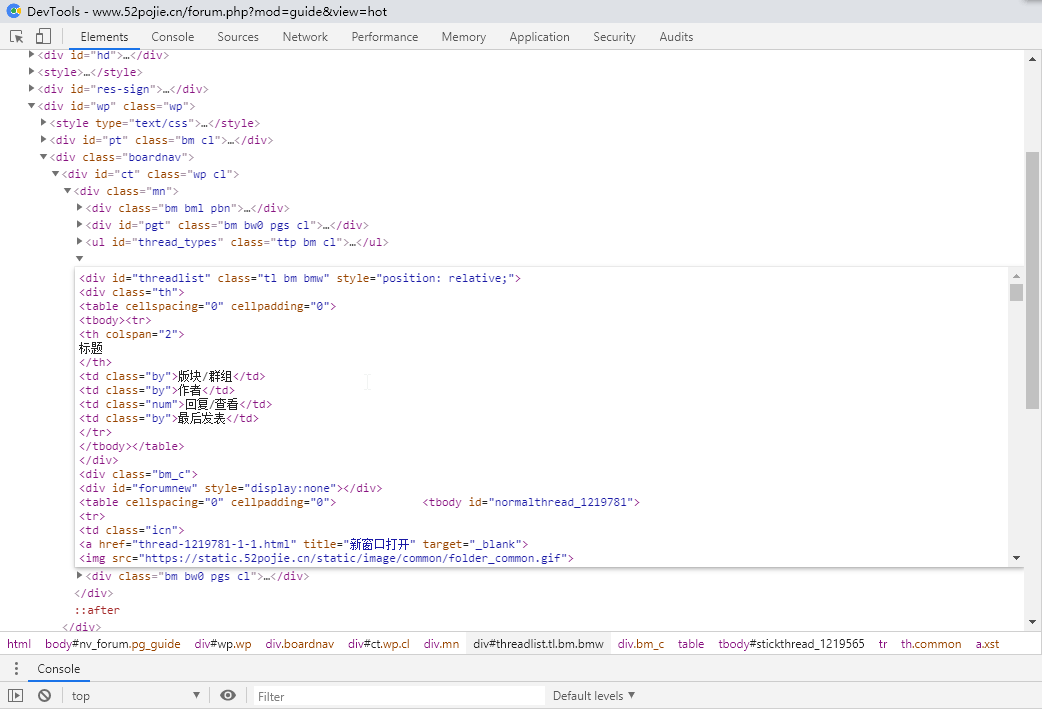
以下是我个人经验
1.必须找到你所要内容的上一级利用find
2.然后find_all你所找的标签
3.用 元素.string 得到元素
用 元素.get('属性')得到属性
打个比方:
比如你想知道法外狂徒张三所住小区的所有门上的猫眼长什么样
你必须先找到小区
然后再筛选出小区中的单元门
然后再get到猫眼
(糟糕的比喻)
根据以上方法
0.网页下载
```python
import requests
from bs4 import BeautifulSoup
html = requests.get('https://www.52pojie.cn/forum.php?mod=guide&view=hot')
```
0.5使用bs解析
```python
soup = BeautifulSoup(html.text, 'lxml')
```
### 1.div标签 确定
属性 有 id 和 class 可以二选一,也可以都使用
注意:BeautifulSoup中class为class_ 说是为了避免重复,咱也不知道啊
```python
import requests
from bs4 import BeautifulSoup
html = requests.get('https://www.52pojie.cn/forum.php?mod=guide&view=hot')
sever = 'https://www.52pojie.cn/'
soup = BeautifulSoup(html.text, 'lxml')
get = soup.find('div', class_='tl bm bmw')
```
### 2.获取a标签
```
import requests
from bs4 import BeautifulSoup
html = requests.get('https://www.52pojie.cn/forum.php?mod=guide&view=hot')
sever = 'https://www.52pojie.cn/'
soup = BeautifulSoup(html.text, 'lxml')
get = soup.find('div', class_='tl bm bmw')
geta = get.find_all('a', class_='xst')
```
### 3.获取元素及href属性
这里明确一件事情
.find找到的默认是第一个,是一个整体,所以要做到唯一
.find_all找到的是所有匹配的,是一个list,所以我们应用for循环,逐个输出
```
for x in geta:
print(x.string)
print(sever+x.get('href'))
```
注:这里的sever就是https://www.52pojie.cn/
原因是因为站内href都是去头的,就是个本地访问,可是服务器又不在我们电脑,补全是必须的
这里便是输出结果
```
电视盒子tv版本ktv软件无需会员
https://www.52pojie.cn/thread-1220759-1-1.html
WPS Office v12.7.1直装高级版
https://www.52pojie.cn/thread-1220940-1-1.html
玩转Github各种插件和脚本【效率提升200%】
https://www.52pojie.cn/thread-1221353-1-1.html
某盒子破解,仅分析破解思路
https://www.52pojie.cn/thread-1218307-1-1.html
【CN911】编码手册 v1.0自定义手册
https://www.52pojie.cn/thread-1218755-1-1.html
【转】洛雪音乐助手 v1.0.0 beta 3 音乐下载神器Windows+Mac+Linux
https://www.52pojie.cn/thread-1219799-1-1.html
【steam价值¥280新游】《牧场物语:重聚矿石镇》中文免安装版
https://www.52pojie.cn/thread-1219718-1-1.html
发个某包买的会会(带素材教程和模板)
https://www.52pojie.cn/thread-1220974-1-1.html
【度盘】彩虹岛7月单机版,双刀技改、宝石之心、副本修复等
https://www.52pojie.cn/thread-1219292-1-1.html
【极限竞速:地平线4v1.42.799.2】【免安装绿色中文版】【整合700辆车存档】网盘
https://www.52pojie.cn/thread-1219604-1-1.html
万兴全能格式转换器 v12.0.1.2 免激活绿色版
https://www.52pojie.cn/thread-1220924-1-1.html
红色警戒:尤里的复仇 经典战争游戏PC移植版 【手机版】 推荐喜欢的朋友试试
https://www.52pojie.cn/thread-1218271-1-1.html
还记得诺顿吗?Norton Utilities Premium(诺顿系统优化软件)官方中文版V17.0.3.658
https://www.52pojie.cn/thread-1219632-1-1.html
国家计算机考试题库软件
https://www.52pojie.cn/thread-1215779-1-1.html
【小男孩证件照制作】支持500多个证件照免费制作,一键换背景色自动排版自动美颜
https://www.52pojie.cn/thread-1219295-1-1.html
虚拟机VM15最高版本+win7 vm文件 小白安装打开即可
https://www.52pojie.cn/thread-1218813-1-1.html
百度链接免登陆高速下载!
https://www.52pojie.cn/thread-1214687-1-1.html
微信PC版 v2.9.5.53 无限多开&消息防撤回绿色版(带撤回提示)(7.16更新)
https://www.52pojie.cn/thread-1220826-1-1.html
木马程序借助“游民星空”等下载站再次大肆传播可云控投放恶意模块
https://www.52pojie.cn/thread-1216391-1-1.html
蚂蚁远程 1.1.0.0
https://www.52pojie.cn/thread-1219781-1-1.html
usb3.0驱动及nvme补丁注入工具(6代及以上iu装win7的解决方式)
https://www.52pojie.cn/thread-1220690-1-1.html
Office Tab Enterprise v14.00.0
https://www.52pojie.cn/thread-1220396-1-1.html
M3U8批量下载器 V1.4.5【7月9日更新】
https://www.52pojie.cn/thread-1216473-1-1.html
桌面整理软件DeskGo_2_9_20254_127_lite独立提取版
https://www.52pojie.cn/thread-1216677-1-1.html
【IDM神操作】你要的无损Music资源这样搞定!【2020.7.13 更新】
https://www.52pojie.cn/thread-1217156-1-1.html
端口查看器
https://www.52pojie.cn/thread-1219565-1-1.html
深度一键软件安装器2020.07.10
https://www.52pojie.cn/thread-1217401-1-1.html
【开放注册公告】吾爱破解论坛2020年7月21日暑假开放注册公告
https://www.52pojie.cn/thread-1216734-1-1.html
百度链接IDM小工具V1.7(附带源码)
https://www.52pojie.cn/thread-1216514-1-1.html
WinRAR 5.91简体中文 德国官网版 新鲜出炉~
https://www.52pojie.cn/thread-1214424-1-1.html
鉴于篇幅,省略一大堆
```
是不是有点儿感觉了?
## 多页爬取+保存为txt
单页爬取已经会了,多页还会远吗?不过是整合代码罢了
https://www.52pojie.cn/forum.php?mod=guide&view=hot&page=2
网站还是很适合练手的
明晃晃的page=2
一共就四页,所以从一加到四就好啦
自己想就好啦
然后是保存了
python的文件读写特别唬人,叫什么IO编程???
名字劝退啊
我们只需要记住这一行就能糊弄过去
```python
with open('文件名.txt', 'a',encoding='UTF-8') as 随便瞎起个名:
```
详细地自行学习python的io吧
然后既然我们能print,我们就也能write
直接一键剪切就完事
```python
import requests
from bs4 import BeautifulSoup
i = 1
add = 'page=' + str(i)
while i <= 4:
i = i +1
html = requests.get('https://www.52pojie.cn/forum.php?mod=guide&view=hot'+add)
sever = 'https://www.52pojie.cn/'
soup = BeautifulSoup(html.text, 'lxml')
get = soup.find('div', class_='tl bm bmw')
geta = get.find_all('a', class_='xst')
for x in geta:
with open('热门.txt','a',encoding='UTF-8') as file:
file.write(x.string)
file.write('\n')
file.write(sever+x.get('href'))
file.write('\n')
```
'\n'这个是换行符吧~~~~,要不然会挤成一行
来自菜鸟教程的对open模式的解析
| 模式 | 描述 |
| ---- | ------------------------------------------------------------ |
| t | 文本模式 \(默认\)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| \+ | 打开一个文件进行更新\(可读可写\)。 |
| U | 通用换行模式(不推荐)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r\+| 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb\+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w\+| 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb\+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a\+| 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab\+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
| 模式 | r | r\+| w | w\+| a | a\+|
| ---------- | ---- | ---- | ---- | ---- | ---- | ---- |
| 读 | \+ | \+ | | \+ | | \+ |
| 写 | | \+ | \+ | \+ | \+ | \+ |
| 创建 | | | \+ | \+ | \+ | \+ |
| 覆盖 | | | \+ | \+ | | |
| 指针在开始 | \+ | \+ | \+ | \+ | | |
| 指针在结尾 | | | | | \+ | \+ |
## 加个进度条
看它在那儿运行鬼知道跑成什么样了
tqdm搞起来
```
from tqdm import tqdm
```
tqdm用于哪里呢?
好像用于for的迭代循环
所以前面的while好像就不香了,改吧改吧就能用了
```python
import requests
from bs4 import BeautifulSoup
from tqdm import tqdm
for i in tqdm(range(1,5)):
add = '&page=' + str(i)
html = requests.get('https://www.52pojie.cn/forum.php?mod=guide&view=hot'+add)
sever = 'https://www.52pojie.cn/'
soup = BeautifulSoup(html.text, 'lxml')
get = soup.find('div', class_='tl bm bmw')
geta = get.find_all('a', class_='xst')
for x in geta:
with open('热门.txt','a',encoding='UTF-8') as file:
file.write(x.string)
file.write('\n')
file.write(sever+x.get('href'))
file.write('\n')
```
在目录下生成 热门.txt 目的达到
全文终
MY原文 P810mg 发表于 2020-7-18 16:37
爬一页就报错,
AttributeError: ResultSet object has no attribute 'text'. You're probably treating a ...
证明你没好好读,文中说明过find 和 find_all的区别,find_all爬的是list,当然没有.text Ldfd 发表于 2020-7-18 11:44
现学现卖,怕忘,感觉你这几天失踪了
咋看出来的。。{:1_896:}
我应该跟论坛很多人一样了,潜水,不过有人回复我我还是会很快答复的(这是个例外,刚才在吃西瓜哈哈,好久没吃了,太甜了) {:1_896:}大佬还会爬虫呀 alittlebear 发表于 2020-7-18 11:40
大佬还会爬虫呀
现学现卖,怕忘,感觉你这几天失踪了 厉害厉害,学习了 大一学过 厉害啊
我也想学
alittlebear 发表于 2020-7-18 12:29
咋看出来的。。
我应该跟论坛很多人一样了,潜水,不过有人回复我我还是会很快答复的(这是 ...
西瓜冻冻更好吃哈哈 kingbackgo 发表于 2020-7-18 12:27
厉害啊
我也想学
照着写一遍就会呃 Ldfd 发表于 2020-7-18 12:42
西瓜冻冻更好吃哈哈
当然哈哈:Dweeqw
页:
[1]
2