手动实现数字验证码识别
本文首发于我的博客 (https://blog.dreace.top/2020/Use-Python-to-Manually-Realize-Mumeral-Verification-Code-Recognition/)。
本人维护的一个项目 [中北信息](https://github.com/Dreace/NUC-Information) 小程序需要模拟登录来获取信息,这就需要在后台识别验证码。需要识别的验证码比较简单且为纯数字,有简单到可以忽略不计的变形,像下面这个样子。
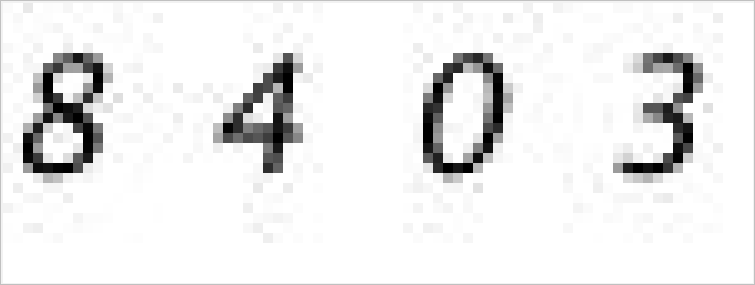
可以看到稍微有一点噪点,应该是压缩解压过程造成的((https://zh.wikipedia.org/zh-cn/JPEG) 是有损压缩)。
这是近乎标准印刷体的四位数字,只是有稍微倾斜,最开始想到的办法是 OCR 。
最初使用 (https://github.com/tesseract-ocr/tesseract) 进行本地 OCR 。效果不是很理想,重要问题是 Tesseract 是通用 OCR,他会识别所有的英文字符和标点,这就造成大量的识别不准确。而且 Tesseract 是一个神经网络,在本地运行相当耗费资源。在平时可以应付大部分情况,但在访问高峰时会消耗大量时间在多个识别线程中切换,甚至直接造成服务器宕机。 在没有新的解决方案之前使用了接近一年,只能说勉强能用。
前不久,发现百度云的 OCR 提供每天 5 万次的免费调用,测试发现可以使用且效果不错。使用一段时间后发现一些问题,异步的调用方式造成的延迟不可忽略,尤其是网络延迟。测试发现这个解决方案每个验证码识别有将近 1s 的网络延迟,这使得后台响应时间被延长,影响用户体验。虽然百度云不会将数字识别成其他字符,但经常出现只识别出两位数字的情况造成大量重试,更加影响性能。
两度更换解决方案后,还是没能找到令人满意的方案。决定自己实现验证码的识别,这里不需要训练神经网络,直接通过规则匹配能得到很好的性能与效果,最终单个验证码识别时间为 4-5ms,正确率 100%。
识别步骤如下:
1.灰度化
2.二值化
3.切割为单个数字
4.和字库对比
## 导入需要用到库
```python
import math
import time
from io import BytesIO
import numpy as np
from PIL import Image
import data
```
最后一行导入的是字库,后面会写到。
## 灰度化
从之前的例子可以看到图像有一些噪点,为了不让其干扰识别需要进行降噪处理,第一步是将图片灰度化。所谓灰度化是将 RGB 色彩空间中三个量合并成一个量 L,这样原本的彩色图像变成灰度图了。每个像素的取值也由 $256^{3}$(16777216)个减少到 256 个,能够减少后继的计算量。将上面的图片灰度化之后变成下面的样子。
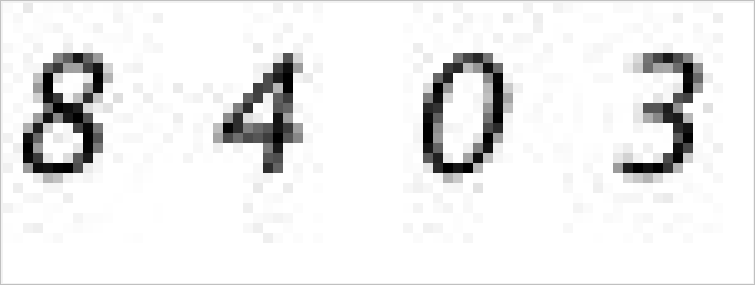
处理代码:
```python
# 灰度处理并创建二维矩阵
img_matrix = np.array(Image.open(BytesIO(image_bytes)).convert("L"))
```
其中 `Image.open(BytesIO(image_bytes)).convert("L")` 是从 `image_bytes` 中创建图像并转为灰度图, `image_bytes`可以是从网络加载或从本地文件读入的字节数据。然后根据灰度图创建一个 (https://numpy.org/) 矩阵方便后面的运算。
灰度化之后与原图好像没有区别是因为原图本身是黑白的,如果原图是彩色的话能够很明显地看出区别。
## 二值化
二值化是将图像的像素与某个阈值比较,若大于这个阈值则设置为灰度最大值(这里是 1,白色),小于某个值则设为灰度最小值(这里是 0,黑色)。这样上一步的灰度图就转化为二值图,便于接下来的图像分割。选择合适的阈值还可以去除图像噪点。
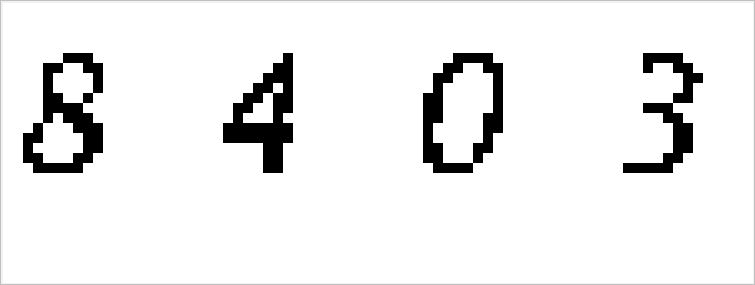
二值化后噪点已经完全消失,数字的边界更加锐利。
处理代码:
```python
# 获取矩阵(图像)的长宽
rows, cols = img_matrix.shape
for i in range(rows):
for j in range(cols):
# 与阈值比较
if img_matrix <= 128:
# 设为灰度最小值
img_matrix = 0
else:
# 设为灰度最大值
img_matrix = 1
```
## 切割为单个数字
二值化后可以看到图像中有大量的空白,这对于识别会造成一些影响,并且对比多个验证码发现数字的垂直位置并非固定,也就是上下边距是浮动的。因此要将空白部分删掉只保留有图像的部分 。 先看实现:
```python
# 每行最小值
row_min = np.min(img_matrix, axis=1)
# 找到第一个有图像的行
row_start = np.argmin(row_min)
# 找到最后一个有图像的行
row_end = np.argmin(np.flip(row_min))
# 只取有图像的行
img_matrix = img_matrix
```

`row_min` 的值为
```python
```
其中 1 表示该行最小值为 1 ,在本例中表示这一行都是 1 ,即没有黑色像素。0 则表示这一行有 0 的存在,即存在黑色像素,也就是这一行有图像,需要保留。`np.argmin()` 在 `row_min` 中查找最小值第一次出现的位置,即为图像开始行。将 `row_min` 反转之后再次查找最小值下标就得到了结束下标,这个下标的是从右向左计数的。 得到 `row_start` 和 `row_end` 后对矩阵进行切片,`row_end` 要取负值表示表示从右开始计数。
接下来将数字切片成单个:
```python
codes = * 4
for i in range(4):
# 切片
imag_matrix_spited = img_matrix[:, 19 * i:19 * (i + 1)]
col_min = np.min(imag_matrix_spited, axis=0)
col_start = np.argmin(col_min)
col_end = np.argmin(np.flip(col_min))
# 图像宽度
width = col_min.shape - (col_start + col_end)
# 宽度扩宽到 9 像素
width_rest = 9 - width
# 左边界
col_start -= int(math.ceil(width_rest / 2.0))
# 右边界
col_end -= int(math.floor(width_rest / 2.0))
# 裁剪为 9 像素宽的图像
imag_matrix_spited = imag_matrix_spited[:, col_start:-col_end]
```
先粗略裁剪为每个数字 20 像素,然后再判断左边界和右边界,同之前一样的算法。但是这里不能直接使用得到的边界,每个数字的宽度不一样,直接切片会导致矩阵大小不一样,会影响之后的计算。因此要将将宽度统一为 9 像素,即为最宽的数字宽度。




## 和字库对比
```python
res = * 10
# 展开成一维
x = imag_matrix_spited.flatten()
for j in range(10):
# 一次取字库中标准数据
y = data.array_map
# 通过异或计算不同元素的数量
res = np.sum(x ^ y)
# 取差异最小的下标
codes = str(np.argmin(res))
```
首先将原先的二维矩阵展开为一维,再与字库中的数据对比找到差异最小的那个既是最终结果,这样整个验证码就识别出来了。字库则需要将展开后的矩阵按照顺序整理一下得到。
下面是针对这种验证码的字库(0~9):
```python
import numpy as np
array_map = * 10
array_map = np.array(
[1, 1, 1, 1, 1, 0, 0, 0, 1, 1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1,
0, 1, 1, 1, 1, 1, 0, 1, 0, 0, 1, 1, 1, 1, 1, 0, 1, 0, 0, 1, 1, 1, 1, 0, 0, 1, 0, 0, 1, 1, 1, 1, 0, 0, 1, 0, 1, 1,
1, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1, 0, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1])
array_map = np.array(
[1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1,
1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1,
0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 1])
array_map = np.array(
[1, 1, 1, 1, 0, 0, 0, 1, 1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1,
1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 0, 0,
1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1])
array_map = np.array(
[1, 1, 1, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1,
1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1,
1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 1, 1, 1])
array_map = np.array(
[1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 0, 0, 1, 0, 1, 1, 1,
1, 0, 0, 1, 0, 0, 1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1, 0, 1, 1, 1, 0, 1, 1, 1, 0, 0, 0, 1, 0, 0, 0, 1, 1, 0, 0, 0,
0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1])
array_map = np.array(
[1, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1,
0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1,
1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 1, 1, 1])
array_map = np.array(
[1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 1, 1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1,
0, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 1, 0, 0, 1, 1, 1, 1, 0, 0, 1, 0, 1, 1,
1, 1, 1, 0, 0, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 0, 0, 1, 1, 1, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 1, 1])
array_map = np.array(
[1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1,
1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0,
1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1])
array_map = np.array(
[1, 1, 1, 1, 1, 0, 0, 0, 1, 1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 1,
1, 0, 0, 1, 1, 0, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 1, 0, 1, 0, 0, 0, 1, 1, 1, 0, 1, 1, 1, 0, 0, 0, 1, 0, 0, 1,
1, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1, 0, 0, 1, 1, 1, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 1, 1])
array_map = np.array(
[1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1,
0, 1, 1, 1, 1, 1, 0, 1, 1, 0, 1, 1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 0, 1, 1, 1, 0, 0, 0, 1, 0, 0, 1, 1, 1, 1,
1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 1, 1, 1])
```
至此验证码识别成功。
## 最后
完整的代码和一百个测试验证码可以在 (https://github.com/Dreace/IVC) 找到。
要求环境为 Python 3+,运行前请先安装 `requirements.txt` 中的依赖。 xinhan2012 发表于 2020-7-28 17:06
字库?稍微模糊点,识别率极速下降
同一个系统的验证码清晰度是一样的,这种写法也只针对一个系统的验证码 caipei 发表于 2020-8-7 14:14
可以做成个软件,方便小白用呢
这是针对某一类验证码设计的一个方案,可以作为参考,但是本身不具备通用性。 不错的文章,受教了,代码识别验证码是一个难题 看不懂,路过 虽然没懂,但看起来好厉害的样子 不错,谢谢分享 不错,以后可能有用 嗯~完全看不懂,感谢分享了 还不错,用着很顺手 感谢楼主分享 厉害,学习了