Android so(ELF)文件解析
本帖最后由 windy_ll 于 2022-3-27 21:35 编辑# 一、前言
**    so文件是啥?so文件是elf文件,elf文件后缀名是`.so`,所以也被chang常称之为`so文件`,elf文件是linux底下二进制文件,可以理解为windows下的`PE文件`,在Android中可以比作`dll`,方便函数的移植,在常用于保护Android软件,增加逆向难度。解析elf文件有啥子用?最明显的两个用处就是:1、so加固;2、用于frida(xposed)的检测!**
**    本文使用c语言,编译器为vscode。如有错误,还请斧正!!!**
---
# 二、SO文件整体格式
**    so文件大体上可分为四部分,一般来说从上往下是`ELF头部->Pargarm头部->节区(Section)->节区头`,其中,除了`ELF头部`在文件位置固定不变外,其余三部分的位置都不固定。整体结构图可以参考非虫大佬的那张图,图片如下:**

**    解析语言之所以选择c语言,有两个原因:1、做so加固的时候可以需要用到,这里就干脆用c写成一个模板,哪里需要就哪里改,不像上次解析dex文件的时候用python写,结果后面写指令还原的时候需要用的时候在写一遍c版本代价太大了;2、在安卓源码中,有个`elf.h`文件,这个文件定义了我们解析时需要用到的所有数据结构,并且给出了参考注释,是很好的参考资料。`elf.h`文件路径如下:**
---
# 三、解析ELF头部
**    ELF头部数据格式在elf.h文件中已经给出,如下图所示:**
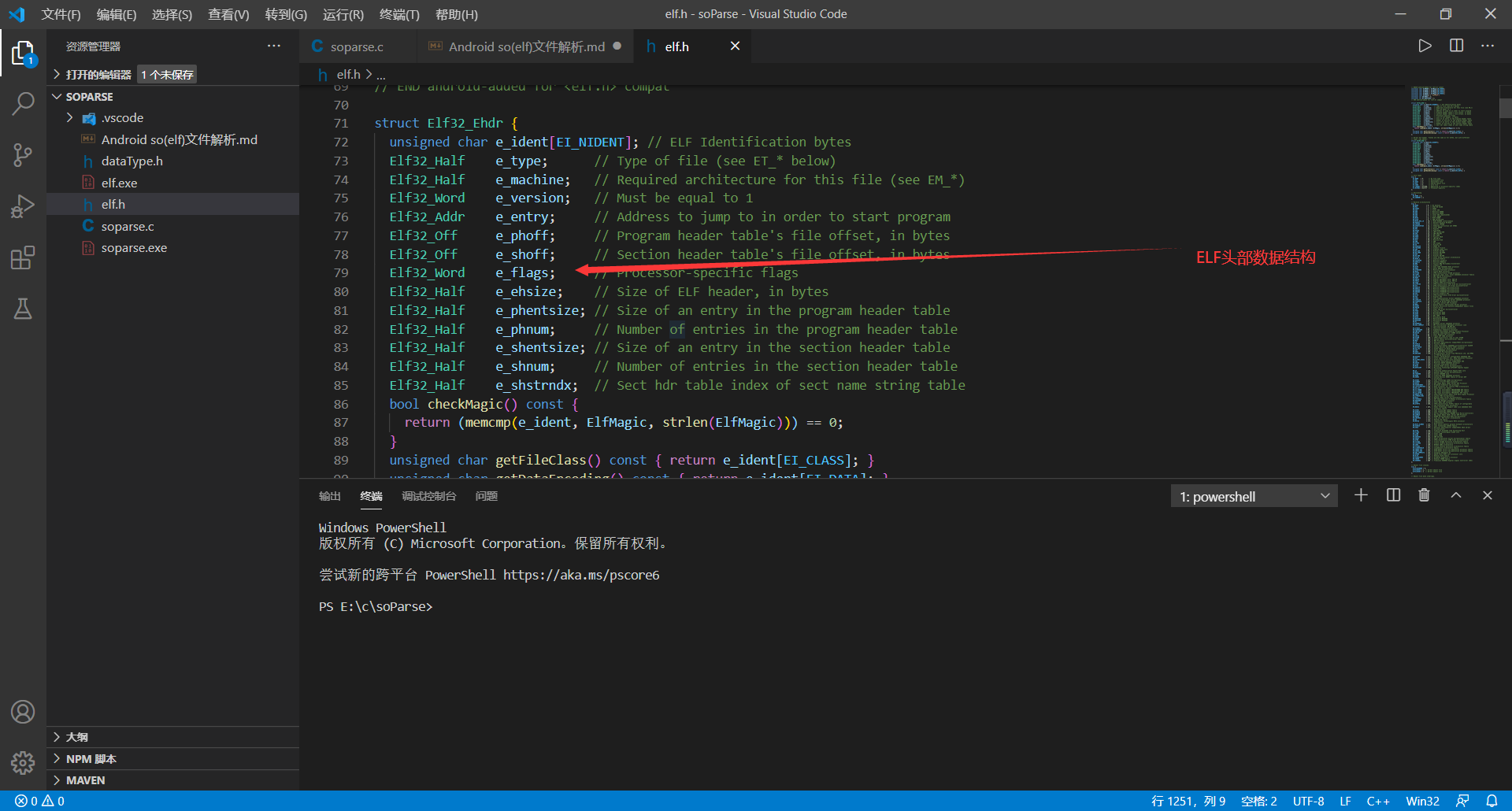
**  每个字段解释如下:**
    1、e_ident数组:前4个字节为`.ELF`,是elf标志头,第5个字节为该文件标志符,为1代表这是一个32位的elf文件,后面几个字节代表版本等信息。
    2、e_type字段:表示是可执行文件还是链接文件等,安卓上的so文件就是分享文件,一般该字段为3,详细请看下图。
    3、e_machine字段:该字段标志该文件运行在什么机器架构上,例如ARM。
    4、e_version字段:该字段表示当前so文件的版本信息,一般为1.
    5、e_entry字段:该字段是一个偏移地址,为程序启动的地址。
    6、e_phoff字段:该字段也是一个偏移地址,指向程序头(Pargram Header)的起始地址。
    7、e_shoff字段:该字段是一个偏移地址,指向节区头(Section Header)的起始地址。
    8、e_flags字段:该字段表示该文件的权限,常见的值有1、2、4,分别代表read、write、exec。
    9、e_ehsize字段:该字段表示elf文件头部大小,一般固定为52.
    10、e_phentsize字段:该字段表示程序头(Program Header)大小,一般固定为32.
    11、e_phnum字段:该字段表示文件中有几个程序头。
    12、e_shentsize:该字段表示节区头(Section Header)大小,一般固定为40.
    13、e_shnum字段:该字段表示文件中有几个节区头。
    14、e_shstrndx字段:该字段是一个数字,这个表明了`.shstrtab节区(这个节区存储着所有节区的名字,例如.text)`的节区头是第几个。
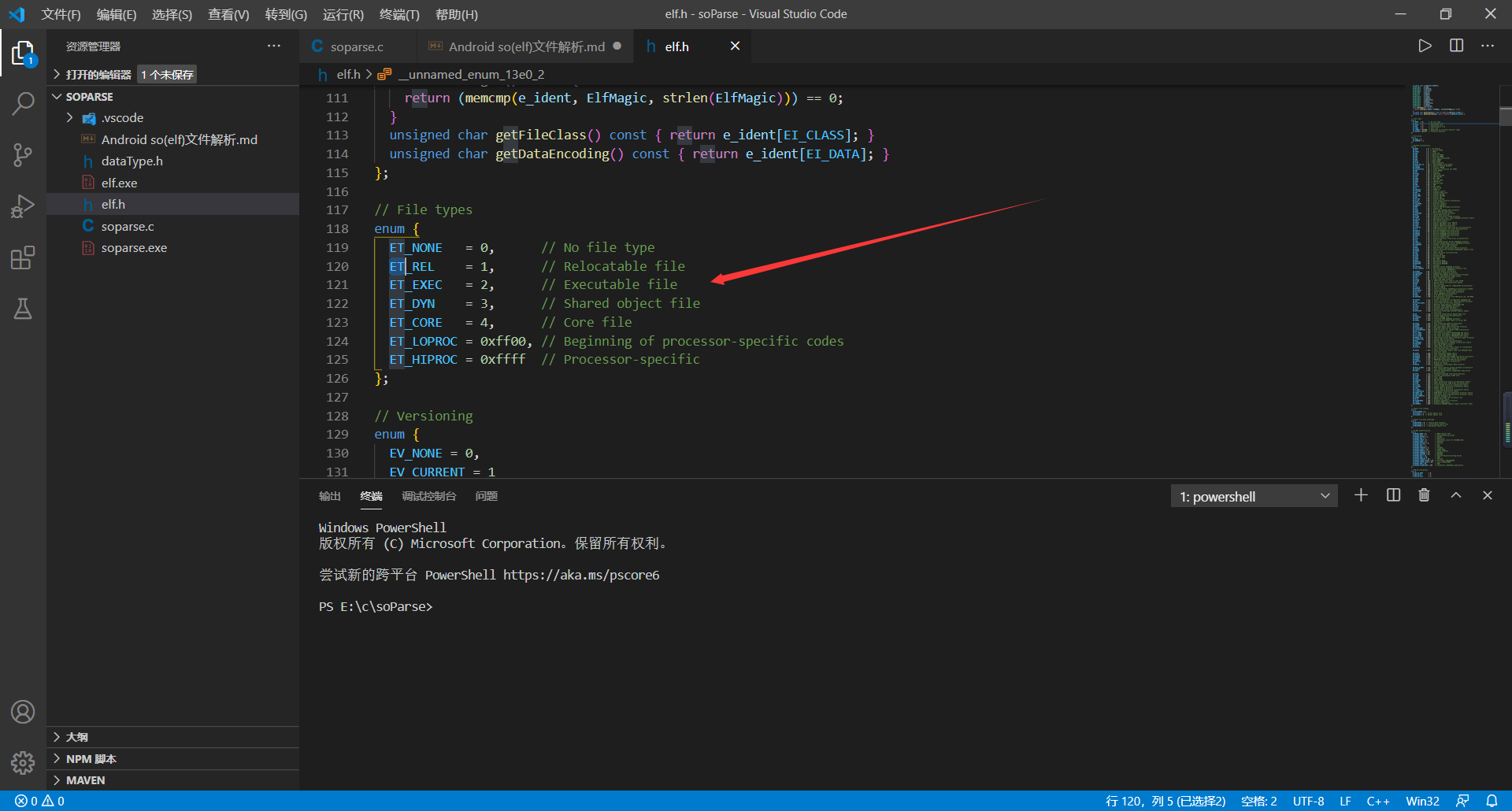
**  `e_type`具体值(相关值后面有英文注释,这里就不再添加中文注释了):**
**  解析代码如下:**
struct DataOffest parseSoHeader(FILE *fp,struct DataOffest off)
{
Elf32_Ehdr header;
int i = 0;
fseek(fp,0,SEEK_SET);
fread(&header,1,sizeof(header),fp);
printf("ELF Header:\n");
printf(" Header Magic: ");
for (i = 0; i < 16; i++)
{
printf("%02x ",header.e_ident);
}
printf("\n");
printf(" So File Type: 0x%02x",header.e_type);
switch (header.e_type)
{
case 0x00:
printf("(No file type)\n");
break;
case 0x01:
printf("(Relocatable file)\n");
break;
case 0x02:
printf("(Executable file)\n");
break;
case 0x03:
printf("(Shared object file)\n");
break;
case 0x04:
printf("(Core file)\n");
break;
case 0xff00:
printf("(Beginning of processor-specific codes)\n");
break;
case 0xffff:
printf("(Processor-specific)\n");
break;
default:
printf("\n");
break;
}
printf(" Required Architecture: 0x%04x",header.e_machine);
if (header.e_machine == 0x28)
{
printf("(ARM)\n");
}
else
{
printf("\n");
}
printf(" Version: 0x%02x\n",header.e_version);
printf(" Start Program Address: 0x%08x\n",header.e_entry);
printf(" Program Header Offest: 0x%08x\n",header.e_phoff);
off.programheadoffset = header.e_phoff;
printf(" Section Header Offest: 0x%08x\n",header.e_shoff);
off.sectionheadoffest = header.e_shoff;
printf(" Processor-specific Flags: 0x%08x\n",header.e_flags);
printf(" ELF Header Size: 0x%04x\n",header.e_ehsize);
printf(" Size of an entry in the program header table: 0x%04x\n",header.e_phentsize);
printf(" Program Header Size: 0x%04x\n",header.e_phnum);
off.programsize = header.e_phnum;
printf(" Size of an entry in the section header table: 0x%04x\n",header.e_shentsize);
printf(" Section Header Size: 0x%04x\n",header.e_shnum);
off.sectionsize = header.e_shnum;
printf(" String Section Index: 0x%04x\n",header.e_shstrndx);
off.shstrtabindex = header.e_shstrndx;
return off;
}
---
# 四、程序头(Program Header)解析
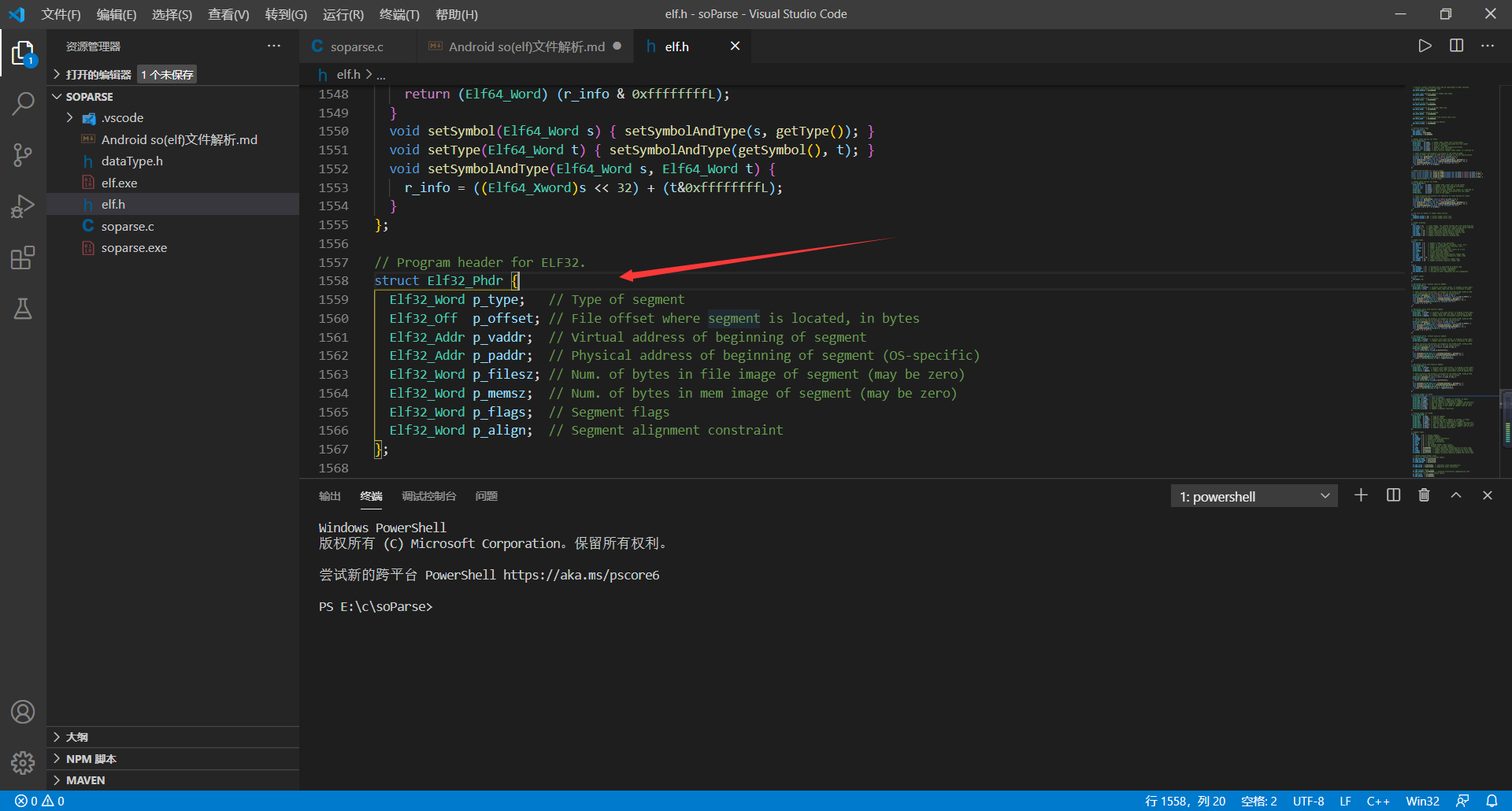
**    程序头在`elf.h`文件中的数据格式是`Elf32_Phdr`,如下图所示:**
**  每个字段解释如下:**
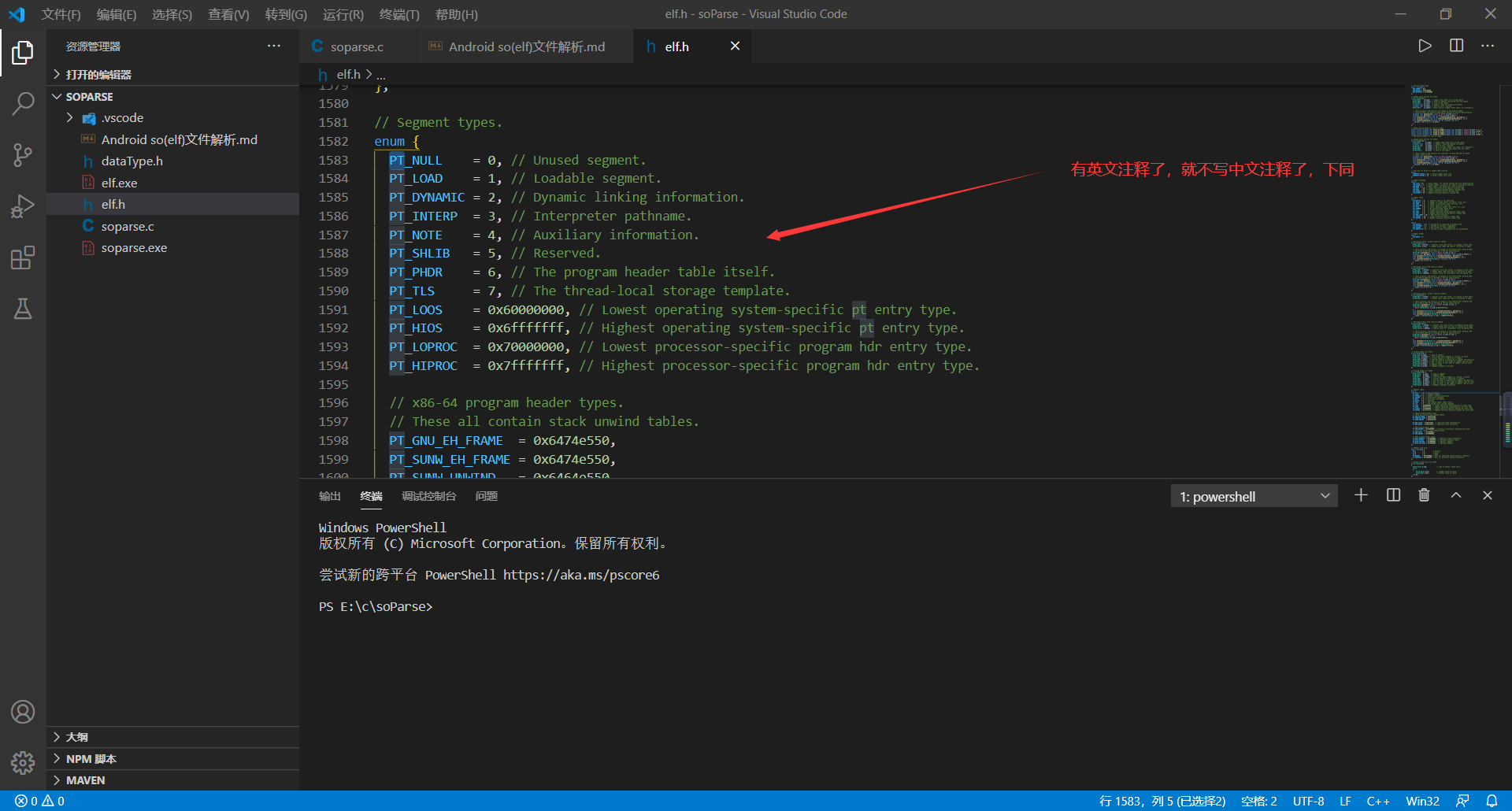
    1、p_type字段:该字段表明了段(Segment)类型,例如`PT_LOAD`类型,具体值看下图,实在有点多,没办法这里写完。
    2、p_offest字段:该字段表明了这个段在该so文件的起始地址。
    3、p_vaddr字段:该字段指明了加载进内存后的虚拟地址,我们静态解析时用不到该字段。
    4、p_paddr字段:该字段指明加载进内存后的实际物理地址,跟上面的那个字段一样,解析时用不到。
    5、p_filesz字段:该字段表明了这个段的大小,单位为字节。
    6、p_memsz字段:该字段表明了这个段加载到内存后使用的字节数。
    7、p_flags字段:该字段跟elf头部的e_flags一样,指明了该段的属性,是可读还是可写。
    8、p_align字段:该字段用来指明在内存中对齐字节数的。
**  `p_type`字段具体取值:**
**  解析代码:**
struct DataOffest parseSoPargramHeader(FILE *fp,struct DataOffest off)
{
Elf32_Half init;
Elf32_Half addr;
int i;
Elf32_Phdr programHeader;
init = off.programheadoffset;
for (i = 0; i < off.programsize; i++)
{
addr = init + (i * 0x20);
fseek(fp,addr,SEEK_SET);
fread(&programHeader,1,32,fp);
switch (programHeader.p_type)
{
case 2:
off.dynameicoff = programHeader.p_offset;
off.dynameicsize = programHeader.p_filesz;
break;
default:
break;
}
printf("\n\nSegment Header %d:\n",(i + 1));
printf(" Type of segment: 0x%08x\n",programHeader.p_type);
printf(" Segment Offset: 0x%08x\n",programHeader.p_offset);
printf(" Virtual address of beginning of segment: 0x%08x\n",programHeader.p_vaddr);
printf(" Physical address of beginning of segment: 0x%08x\n",programHeader.p_paddr);
printf(" Num. of bytes in file image of segment: 0x%08x\n",programHeader.p_filesz);
printf(" Num. of bytes in mem image of segment (may be zero): 0x%08x\n",programHeader.p_memsz);
printf(" Segment flags: 0x%08x\n",programHeader.p_flags);
printf(" Segment alignment constraint: 0x%08x\n",programHeader.p_align);
}
return off;
}
---
# 五、节区头(Section Header)解析
**    节区头在elf.h文件中的数据结构为`Elf32_Shdr`,如下图所示:**
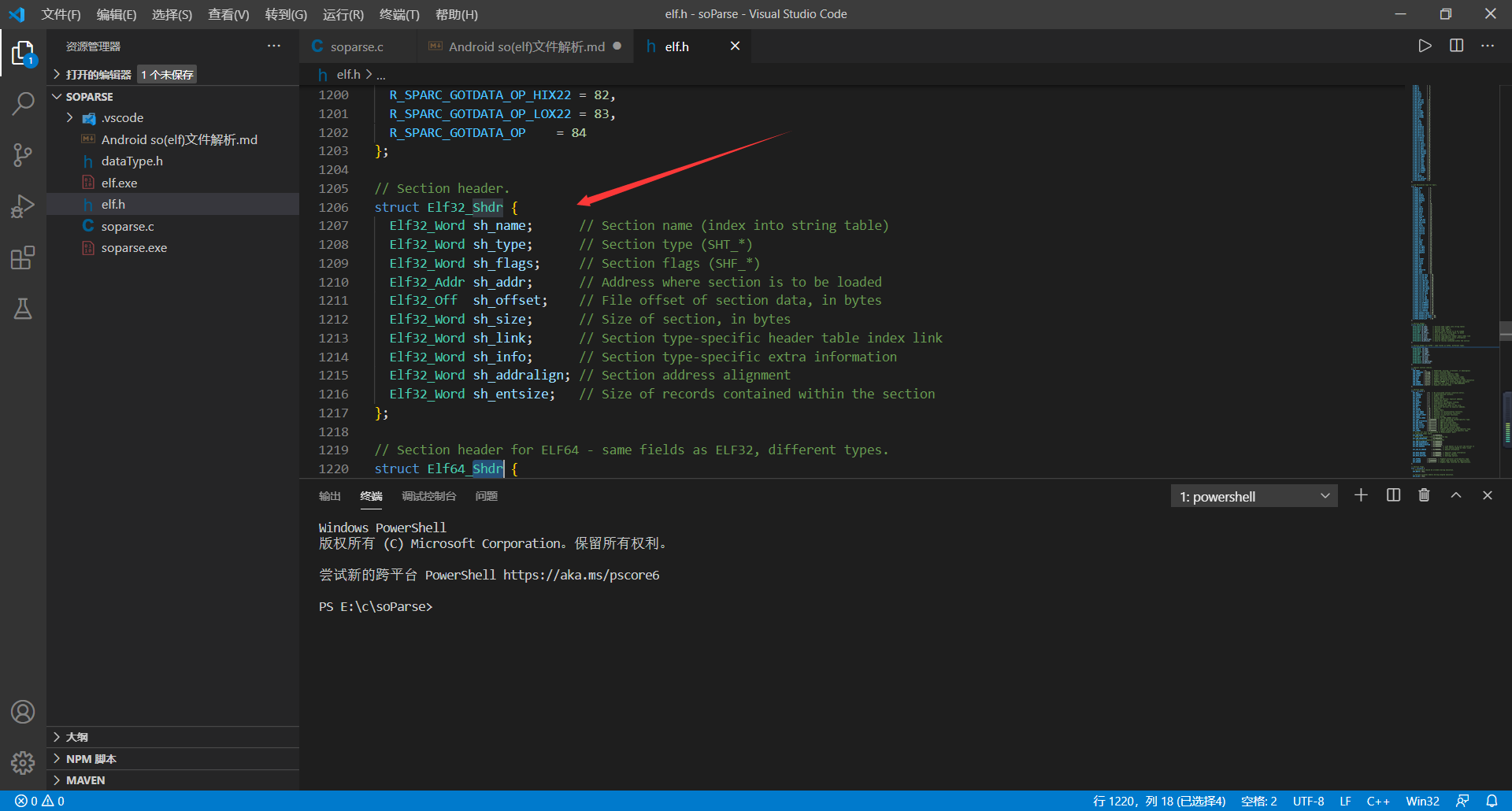
**  每个字段解释如下:**
    1、sh_name字段:该字段是一个索引值,是`.shstrtab`表(节区名字字符串表)的索引,指明了该节区的名字。
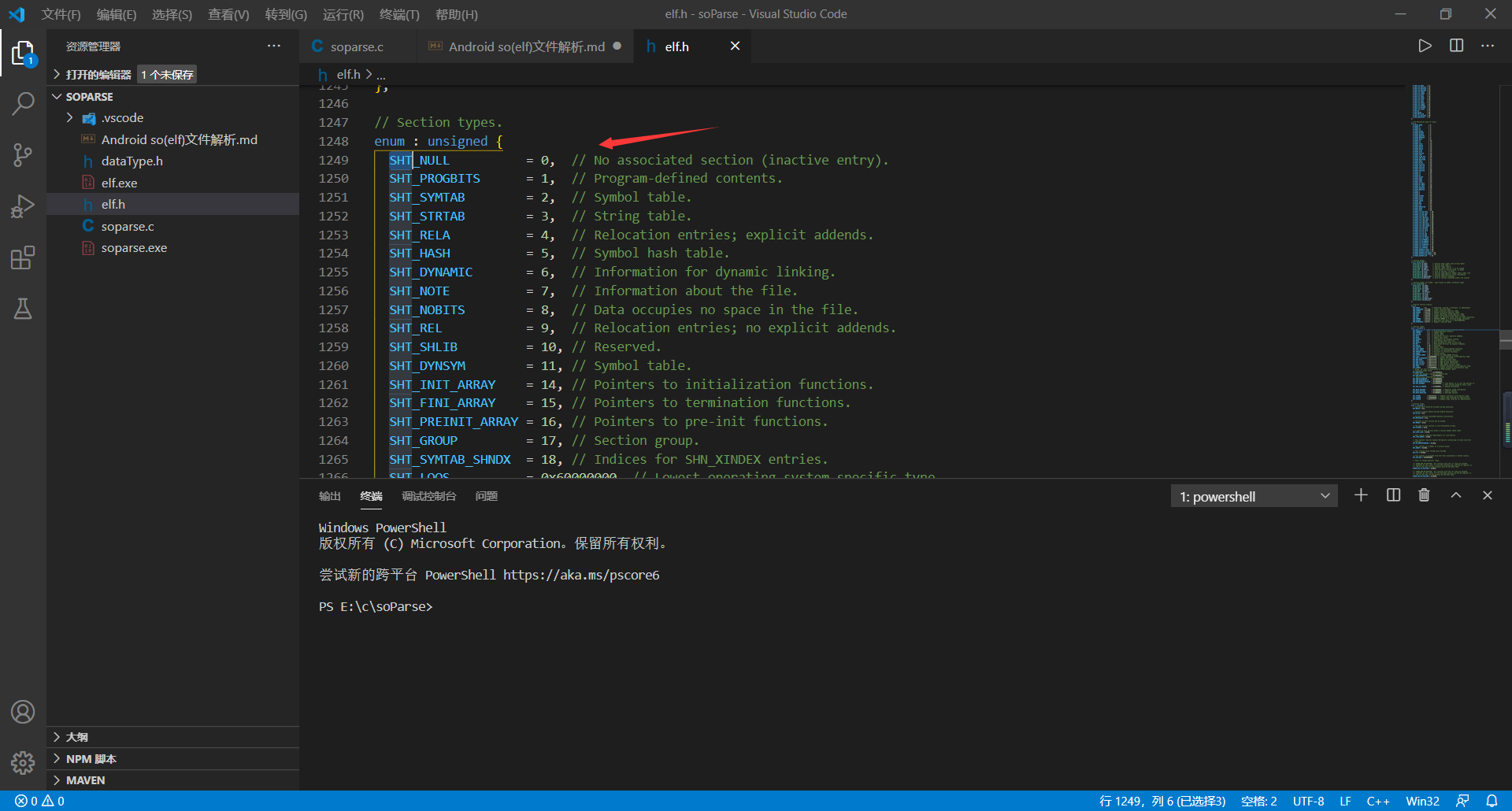
    2、sh_type字段:该字段表明该节区的类型,例如值为`SHT_PROGBITS`,则该节区可能是`.text`或者`.rodata`,至于具体怎么区分,当然看sh_name字段。具体取值看下图。
    3、sh_flags字段:跟上面的一样,就不再细说了。
    4、sh_addr字段:该字段是一个地址,是该节区加载进内存后的地址。
    5、sh_offset字段:该字段也是一个地址,是该节区在该so文件中的偏移地址。
    6、sh_size字段:该字段表明了该节区的大小,单位是字节。
    7、sh_link和sh_info字段:这两个字段只适用于少数节区,我们这里解析用不到,感兴趣的可以去看官方文档。
    8、sh_addralign字段:该字段指明在内存中的对齐字节。
    9、sh_entsize字段:该字段指明了该节区中每个项占用的字节数。
**  `sh_type`取值:**
**  解析代码:**
struct DataOffest parseSoSectionHeader(FILE *fp,struct DataOffest off,struct ShstrtabTable StrList)
{
Elf32_Half init;
Elf32_Half addr;
Elf32_Shdr sectionHeader;
int i,id,n;
char ch;
int k = 0;
init = off.sectionheadoffest;
for (i = 0; i < off.sectionsize; i++)
{
addr = init + (i * 0x28);
fseek(fp,addr,SEEK_SET);
fread(§ionHeader,1,40,fp);
switch (sectionHeader.sh_type)
{
case 2:
off.symtaboff = sectionHeader.sh_offset;
off.symtabsize = sectionHeader.sh_size;
break;
case 3:
if(k == 0)
{
off.stroffset = sectionHeader.sh_offset;
off.strsize = sectionHeader.sh_size;
k++;
}
else if (k == 1)
{
off.str1offset = sectionHeader.sh_offset;
off.str1size = sectionHeader.sh_size;
k++;
}
else
{
off.str2offset = sectionHeader.sh_offset;
off.str2size = sectionHeader.sh_size;
k++;
}
break;
default:
break;
}
id = sectionHeader.sh_name;
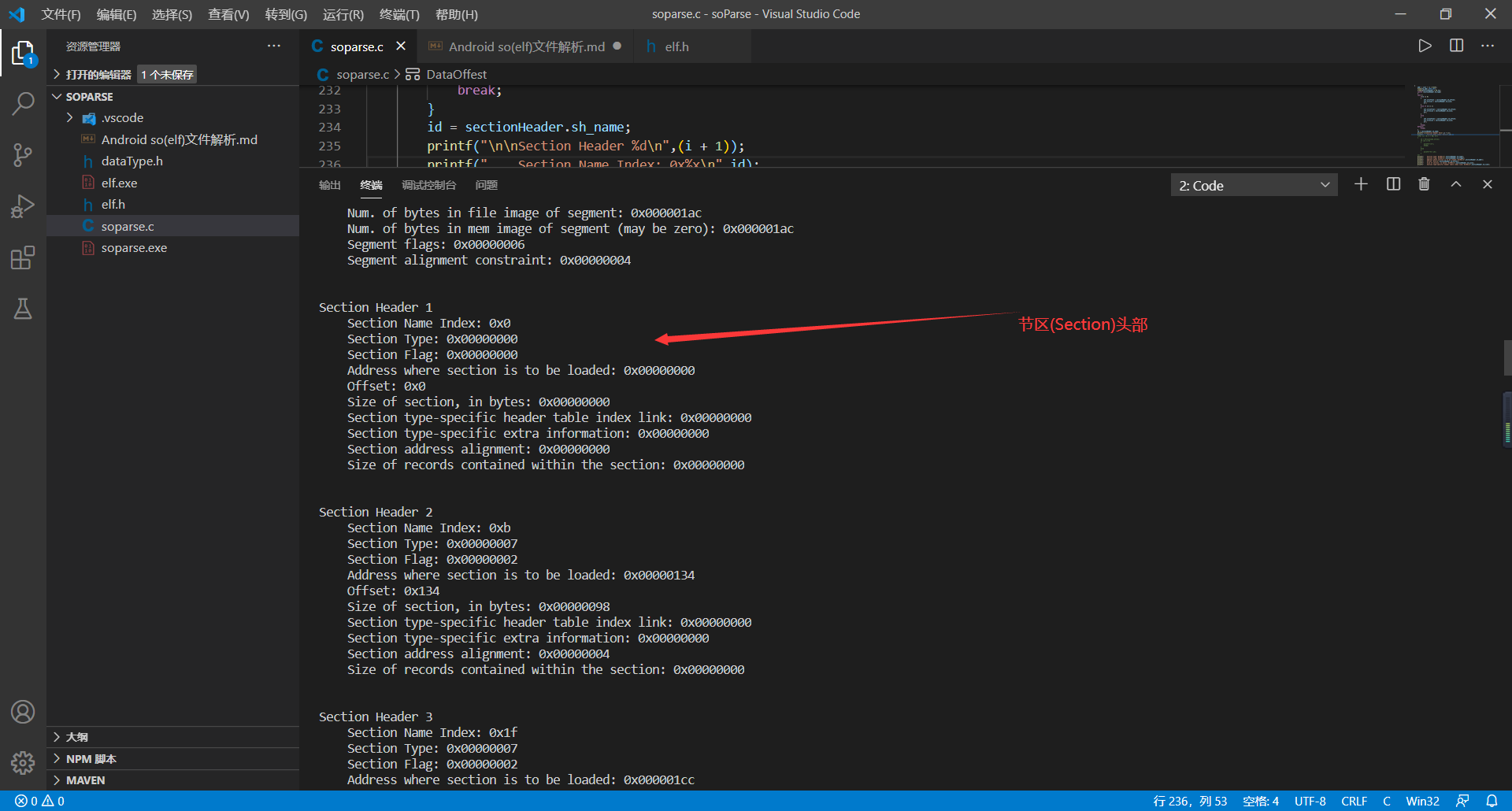
printf("\n\nSection Header %d\n",(i + 1));
printf(" Section Name: ");
for (n = 0; n < 50; n++)
{
ch = StrList.str;
if (ch == 0)
{
printf("\n");
break;
}
else
{
printf("%c",ch);
}
}
printf(" Section Type: 0x%08x\n",sectionHeader.sh_type);
printf(" Section Flag: 0x%08x\n",sectionHeader.sh_flags);
printf(" Address where section is to be loaded: 0x%08x\n",sectionHeader.sh_addr);
printf(" Offset: 0x%x\n",sectionHeader.sh_offset);
printf(" Size of section, in bytes: 0x%08x\n",sectionHeader.sh_size);
printf(" Section type-specific header table index link: 0x%08x\n",sectionHeader.sh_link);
printf(" Section type-specific extra information: 0x%08x\n",sectionHeader.sh_info);
printf(" Section address alignment: 0x%08x\n",sectionHeader.sh_addralign);
printf(" Size of records contained within the section: 0x%08x\n",sectionHeader.sh_entsize);
}
return off;
}
---
# 六、字符串节区解析
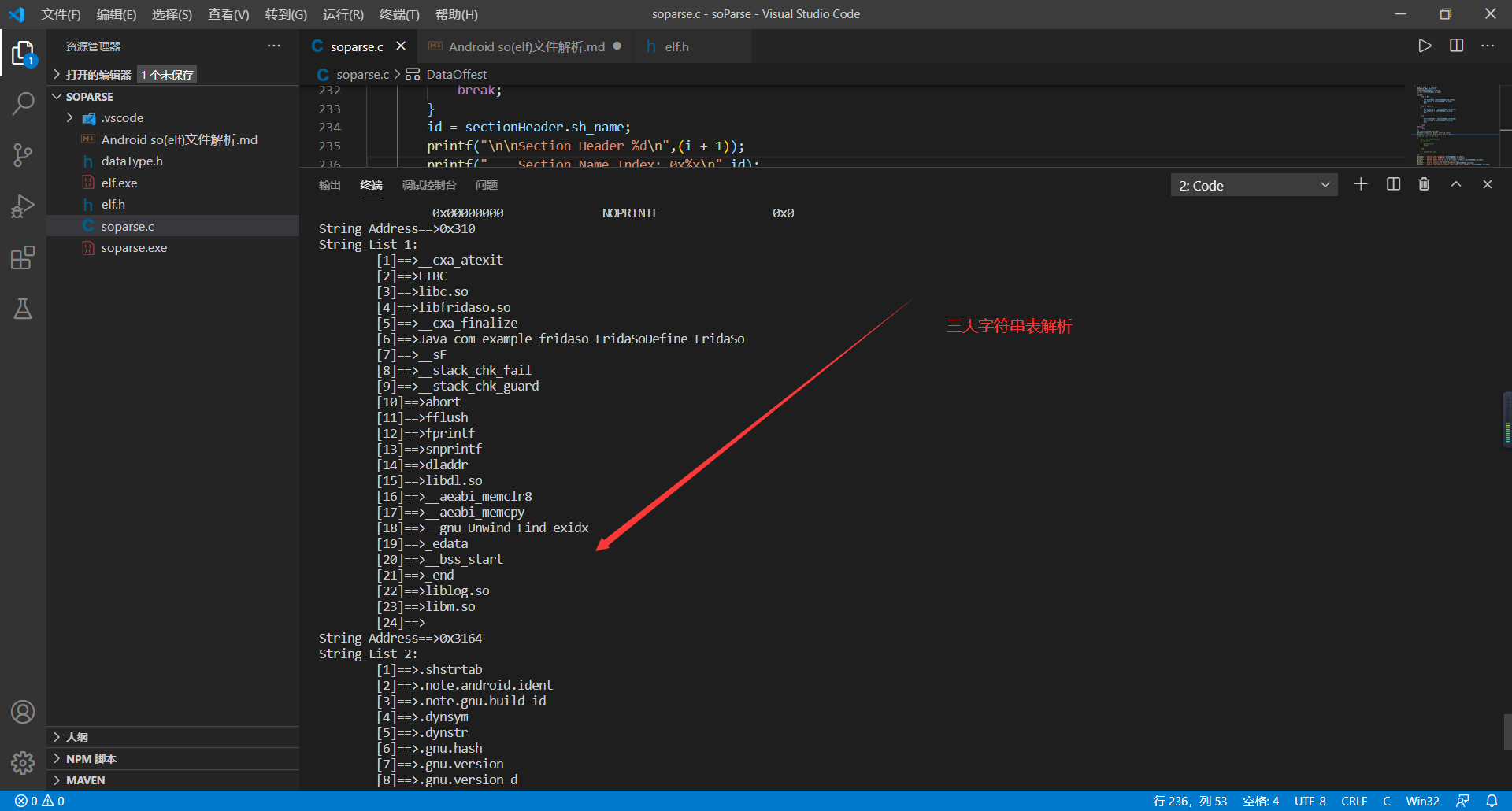
**    PS:从这里开始网上的参考资料很少了,特别是参考代码,所以有错误的地方还请斧正;因为以后的so加固等只涉及到几个节区,所以只解析了`.shstrtab`、`.strtab`、`.dynstr`、`.text`、`.symtab`、`.dynamic`节区!!!**
**    在elf头部中有个`e_shstrndx`字段,该字段指明了`.shstrtab`节区头部是文件中第几个节区头部,我们可以根据这找到`.shstrtab`节区的偏移地址,然后读取出来,就可以为每个节区名字赋值了,然后就可以顺着锁定剩下的两个字符串节区。**
**    在elf文件中,字符串表示方式如下:字符串的头部和尾部用标示字节`00`标志,同时上一个字符串尾部标识符`00`作为下一个字符串头部标识符。例如我有两个紧邻的字符串分别是`a`和`b`,那么他们在elf文件中16进制为`00 97 00 98 00`。**
**  解析代码如下(PS:因为编码问题,第一次打印字符串表没问题,但填充进sh_name就乱码,所以这里只放上解析`.shstrtab`的代码,但剩下两个节区节区代码一样):**
void parseStrSection(FILE *fp,struct DataOffest off,int flag)
{
int total = 0;
int i;
int ch;
int mark;
Elf32_Off init;
Elf32_Off addr;
Elf32_Word count;
mark = 1;
if (flag == 1)
{
count = off.strsize;
init = off.stroffset;
}
else if (flag == 2)
{
count = off.str1size;
init = off.str1offset;
}
else
{
count = off.str2size;
init = off.str2offset;
}
printf("String Address==>0x%x\n",init);
printf("String List %d:\n\t==>",flag);
for (i = 0; i < count; i++)
{
addr = init + (i * 1);
fseek(fp,addr,SEEK_SET);
fread(&ch,1,1,fp);
if (i == 0 && ch == 0)
{
continue;
}
else if (ch != 0)
{
printf("%c",ch);
}
else if (ch == 0 && i !=0)
{
printf("\n\t[%d]==>",(++mark));
}
}
printf("\n");
}
---
# 七、.dynamic解析
**    `.dynamic`在`elf.h`文件中的数据结构是`Elf32-Dyn`,如下图所示:**
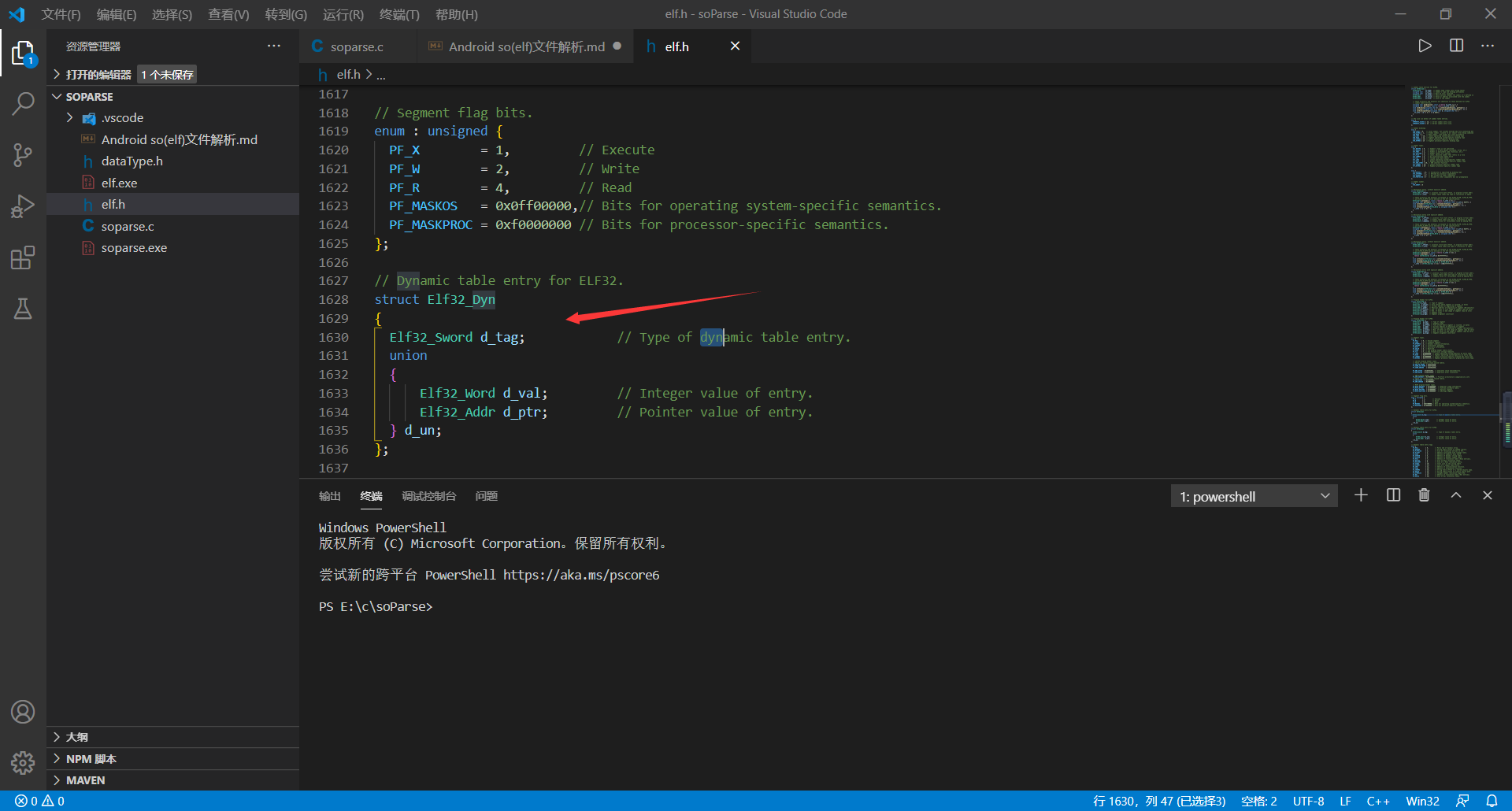
**    第一个字段表明了类型,占4个字节;第二个字段是一个共用体,也占四个字节,描述了具体的项信息。解析代码如下:**
void parseSoDynamicSection(FILE *fp,struct DataOffest off)
{
int dynamicnum;
Elf32_Off init;
Elf32_Off addr;
Elf32_Dyn dynamicData;
int i;
init = off.dynameicoff;
dynamicnum = (off.dynameicsize / 8);
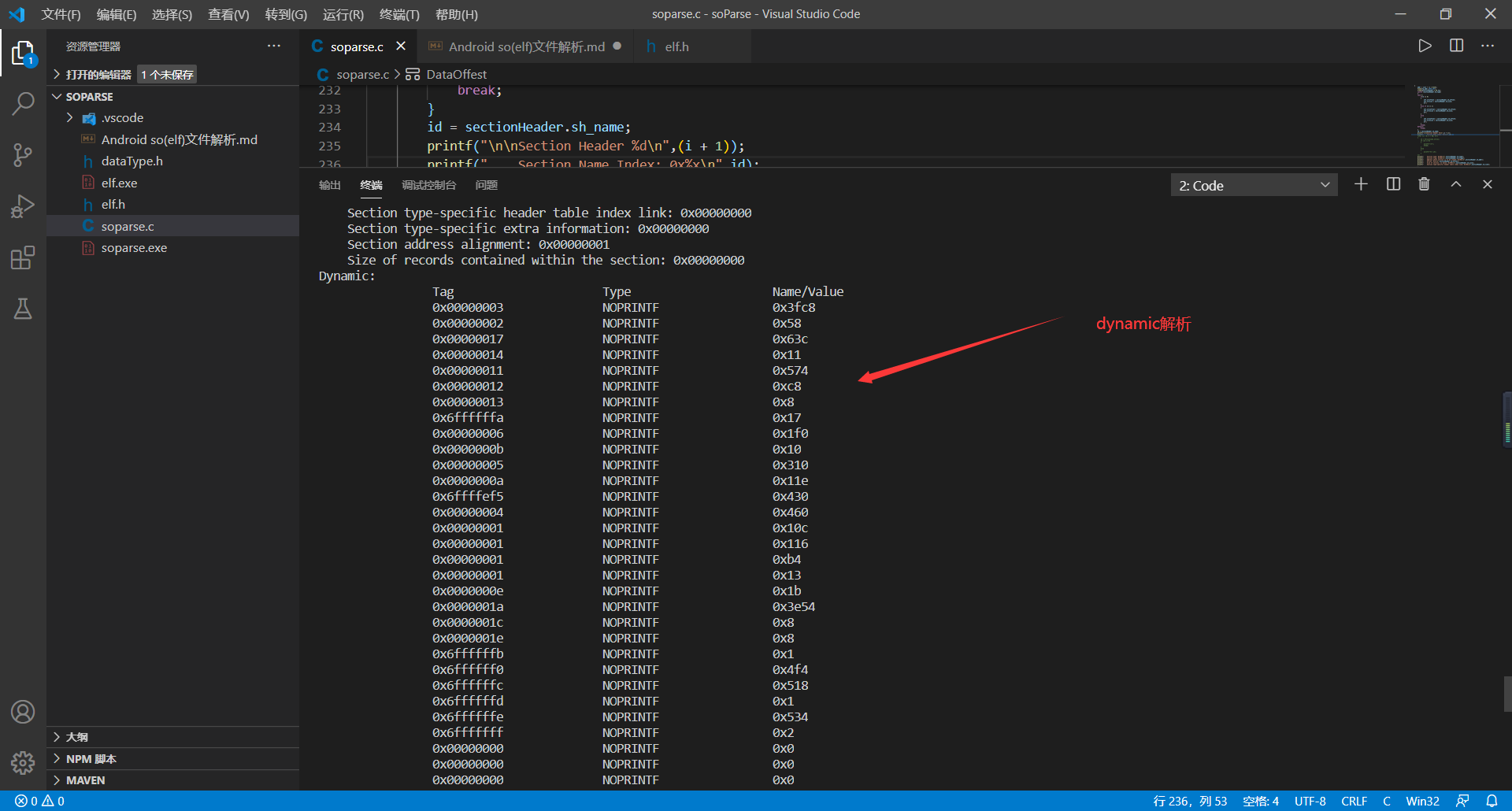
printf("Dynamic:\n");
printf("\t\tTag\t\t\tType\t\t\tName/Value\n");
for (i = 0; i < dynamicnum; i++)
{
addr = init + (i * 8);
fseek(fp,addr,SEEK_SET);
fread(&dynamicData,1,8,fp);
printf("\t\t0x%08x\t\tNOPRINTF\t\t0x%x\n",dynamicData.d_tag,dynamicData.d_un);
}
}
---
# 八、.symtab解析
**    该节区是该so文件的符号表,它在`elf.h`文件中的数据结构是`Elf32_Sym`,如下所示:**
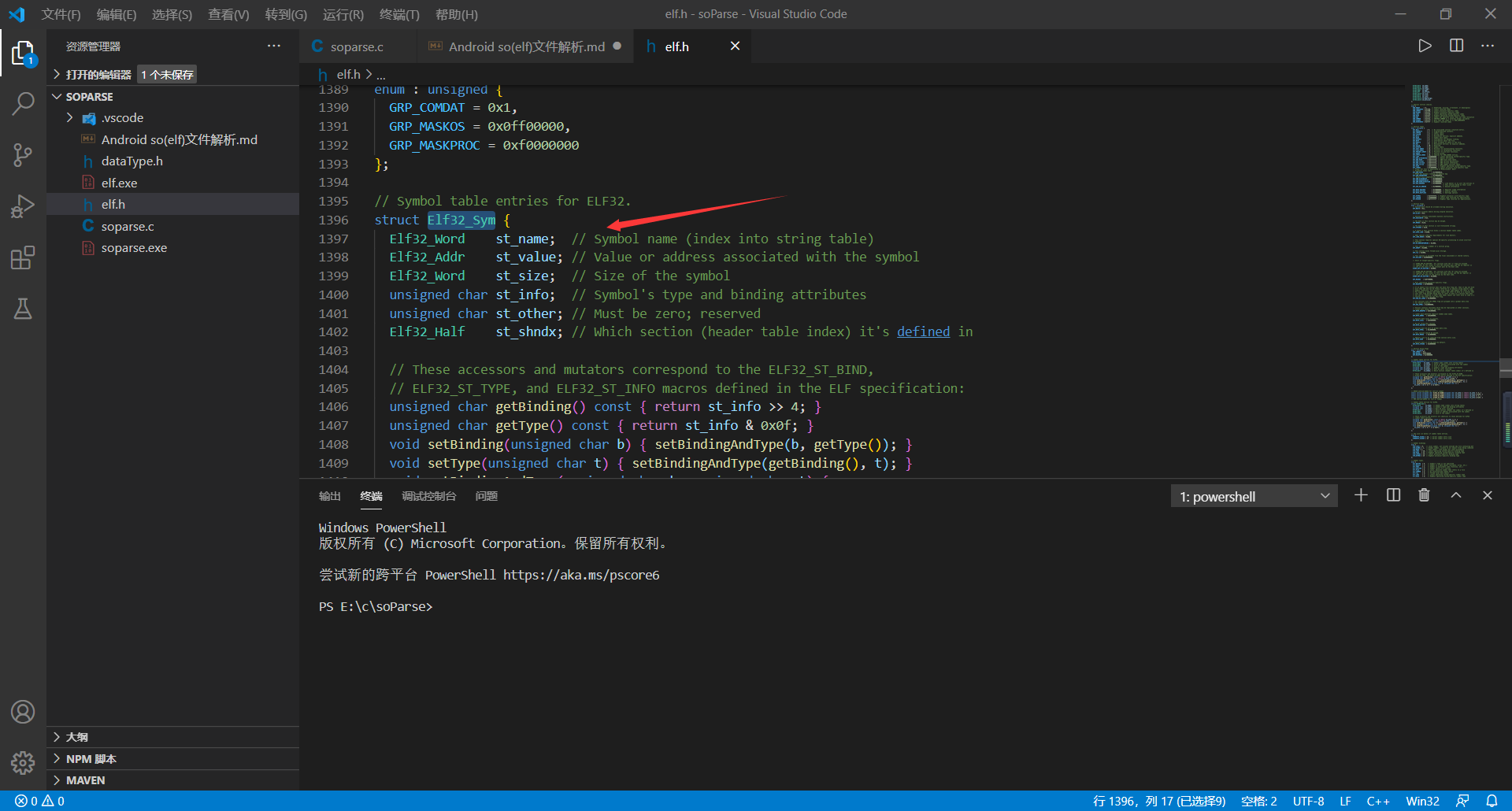
**  每个字段解释如下:**
    1、st_name字段:该字段是一个索引值,指明了该项的名字。
    2、st_value字段:该字段表明了相关联符号的取值。
    3、stz-size字段:该字段指明了每个项所占用的字节数。
    4、st_info和st_other字段:这两个字段指明了符号的类型。
    5、st_shndx字段:相关索引。
**  解析代码如下(PS:由于乱码问题,索引手动固定了地址测试,有兴趣的挨个解析字符应该可以解决乱码问题):**
```
void parseSoDynamicSection(FILE *fp,struct DataOffest off)
{
int dynamicnum;
Elf32_Off init;
Elf32_Off addr;
Elf32_Dyn dynamicData;
int i;
init = off.dynameicoff;
dynamicnum = (off.dynameicsize / 8);
printf("Dynamic:\n");
printf("\t\tTag\t\t\tType\t\t\tName/Value\n");
for (i = 0; i < dynamicnum; i++)
{
addr = init + (i * 8);
fseek(fp,addr,SEEK_SET);
fread(&dynamicData,1,8,fp);
printf("\t\t0x%08x\t\tNOPRINTF\t\t0x%x\n",dynamicData.d_tag,dynamicData.d_un);
}
}
void parseSymtabSection(FILE *fp,struct DataOffest off)
{
Elf32_Off init;
Elf32_Off addr;
Elf32_Word count;
Elf32_Sym symtabSection;
int k,i;
init = off.symtaboff;
count = off.symtabsize;
printf("SymTable:\n");
for (i = 0; i < count; i++)
{
addr = init + (i * 16);
fseek(fp,addr,SEEK_SET);
fread(&symtabSection,1,16,fp);
printf("Symbol Name Index: 0x%x\n",symtabSection.st_name);
printf("Value or address associated with the symbol: 0x%08x\n",symtabSection.st_value);
printf("Size of the symbol: 0x%x\n",symtabSection.st_size);
printf("Symbol's type and binding attributes: %c\n",symtabSection.st_info);
printf("Must be zero; reserved: 0x%x\n",symtabSection.st_other);
printf("Which section (header table index) it's defined in: 0x%x\n",symtabSection.st_shndx);
}
}
```
---
# 九、.text解析
**    PS:这部分没代码了,只简单解析一下,因为解析arm指令太麻烦了,估计得写个半年都不一定能搞定,后续写了会同步更新在github!!!**
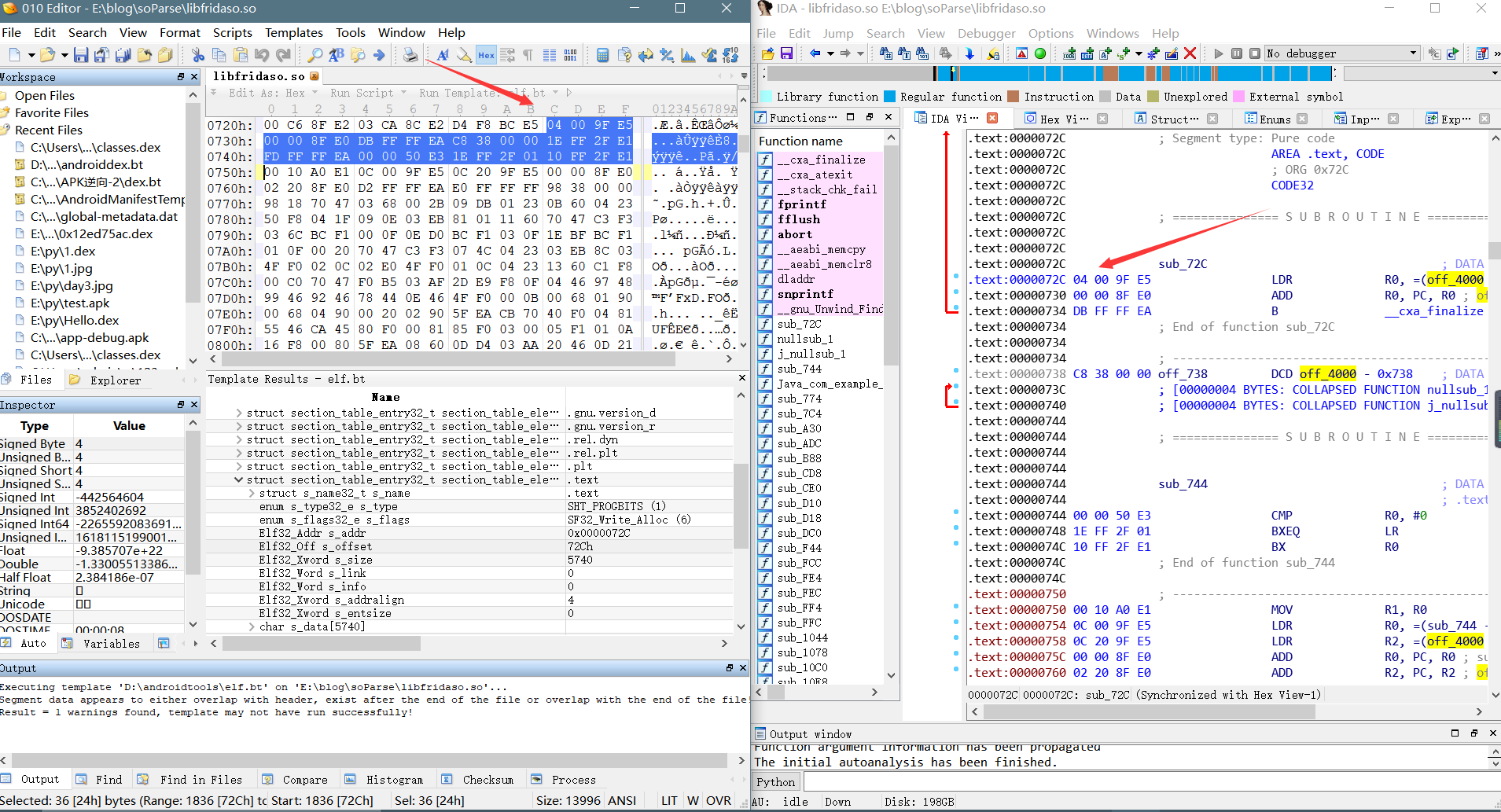
**    `.text`节区存储着可执行指令,我们可以通过节区头部的名字锁定`.text`的偏移地址和大小,找到该节区后,我们会发现这个节区存储的就是arm机器码,直接照着指令集翻译即可,没有其他的结构。通过ida验证如下:**
---
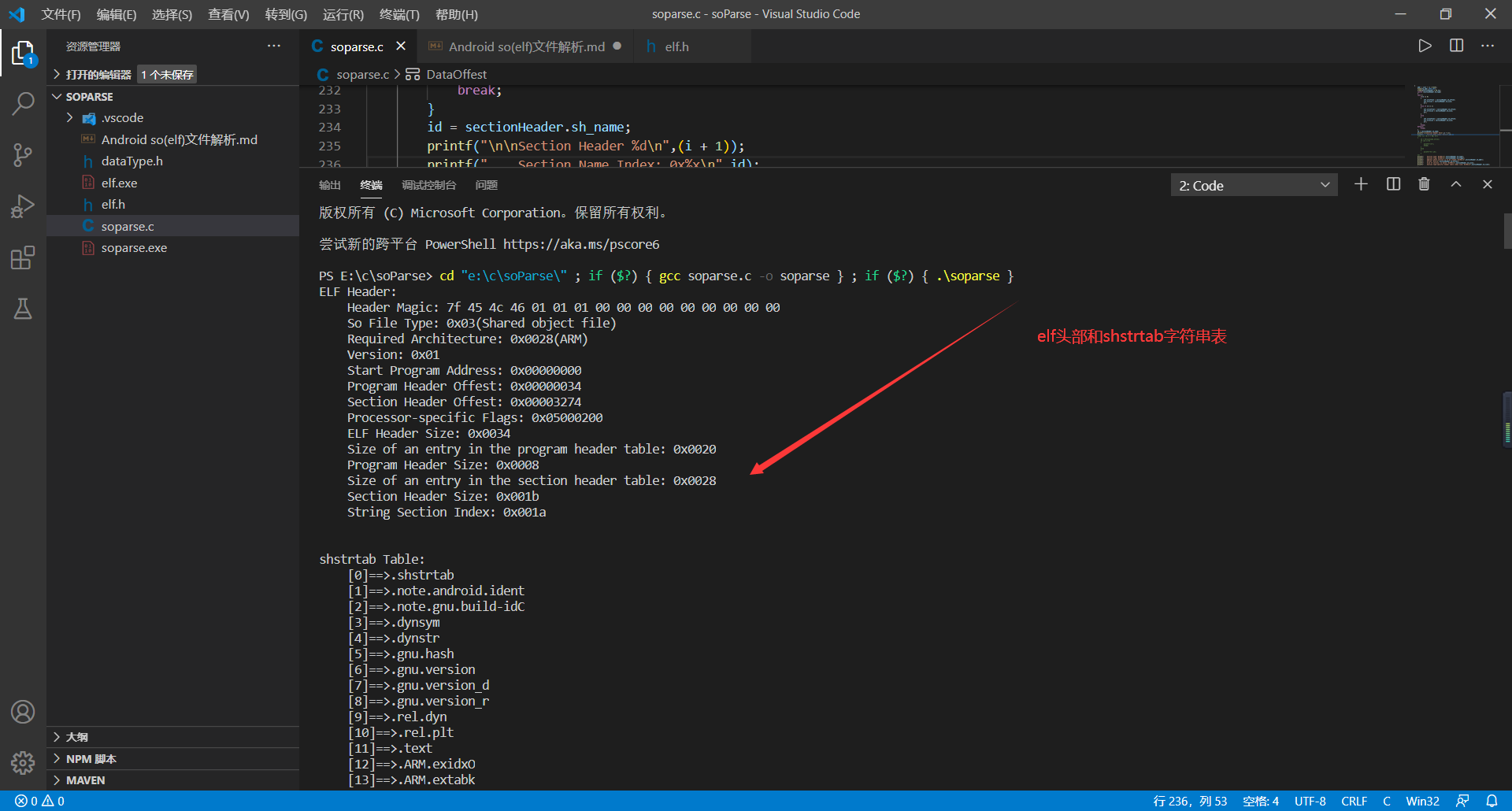
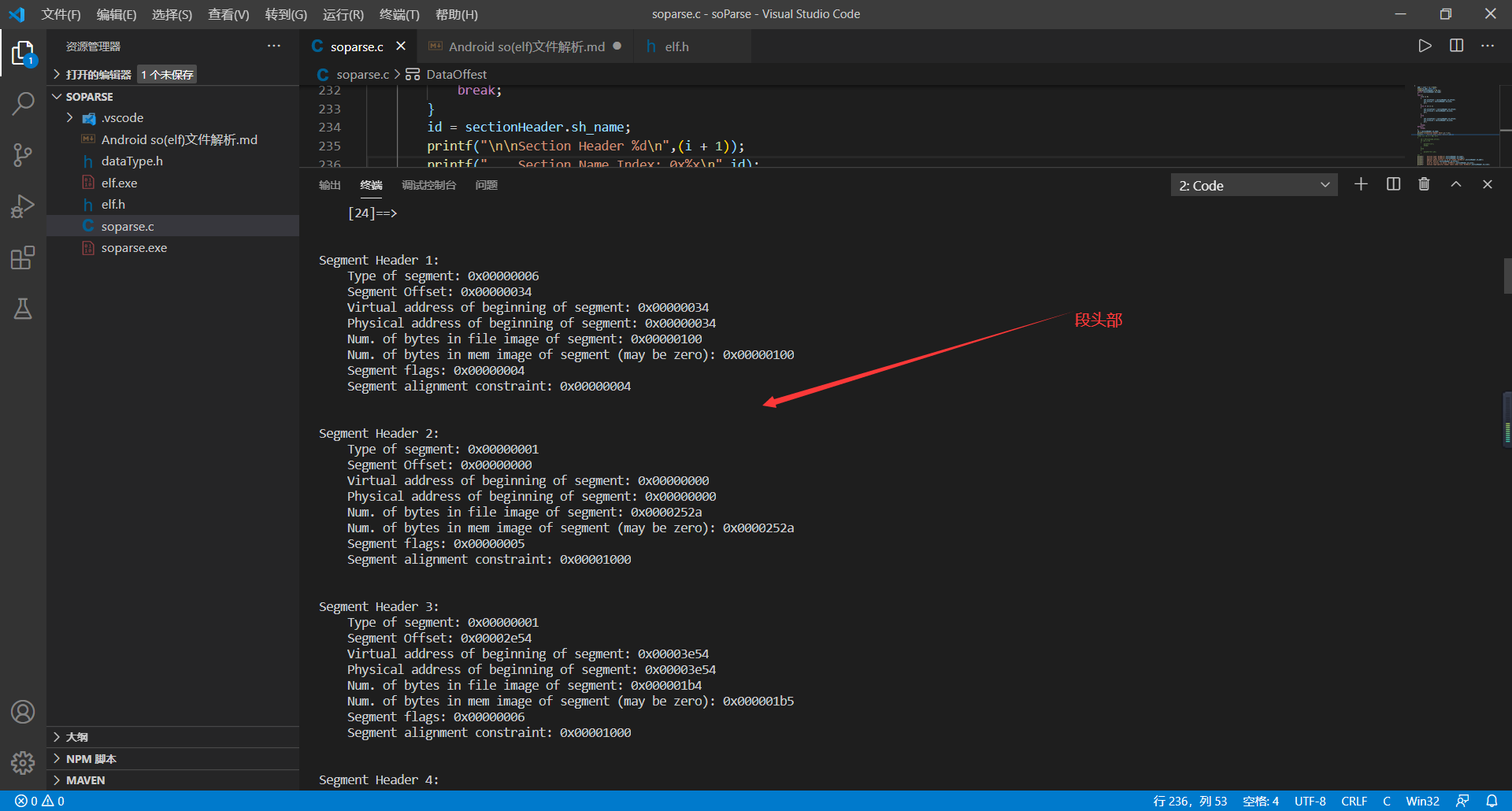
# 十、代码测试相关截图
---
# 十一、frida反调试和后序
**    frida反调试最简单的就是检查端口,检查进程名,检查so文件等,但最准确以及最复杂的是检查汇编指令,我们知道frida是通过一个大调整实现hook,而跳转的指令就那么几条,我们是否可以通过检查每个函数第一条指令来判断是否有frida了!!!(ps:简单写一下原理,拉开写就太多了,这里感谢某大佬和我讨论的这个话题!!!)**
**    本来因为这个so文件解析要写到明年去了,没想到看起来代码量大,但实际要用到的地方代码量很少。。。**
**    源码github链接:(https://github.com/windy-purple/parseso/)** 感谢分享,写的很详细 虽然知道楼主说的东西,但一下子还不是全明白,及如何使用,所以请问楼主,如何才能不被检测到是否装了xposed框架或别的shell操作软件,需要修改哪里? 正好在找so的资料 膜拜大神 不晓得啥时候我才能全看懂 感谢分享,学习了 老大,牛逼,受教了,多谢 也难怪so逆向困难~ 这学习了。 厉害了,做个标记,后面学习 写的不错,赞一个! 很详细的样子