从零开始搭建完整的全栈系统(一)——数据库设计及爬虫编写
本帖最后由 lovelilili 于 2020-10-25 09:27 编辑一不小心踩雷了,四篇文章全部被删除。仔细看了下论坛规则,论坛删除是基于可能隐藏广告的考虑。
纯技术分享,尽量避免出现违规关键词,如果还不允许存在,删除好了。保证不再发布!
这是一个系列文章:
从零开始搭建完整的全栈系统(一)——数据库设计及爬虫编写
从零开始搭建完整的全栈系统(二)——简单的WEB展示网站的搭建
从零开始搭建完整的全栈系统(三)——restfulApi的编写
从零开始搭建完整的全栈系统(四)——restfulApi用户的认证授权及用户注册
从零开始搭建完整的全栈系统(五)——WEB网站、Api以及爬虫的部署
从零开始搭建完整的全栈系统(六)——基于Flutter开发的App应用展示
前言:关于标题似乎有些浮夸,所谓的全栈系统主要包括数据的爬取,web网站展示,移动设备App,主要记录学习过程中知识点,以备忘。
**技术栈:
1,Scrapy爬虫框架:记录爬虫框架的工作流程,简单爬虫的编写
2,Yii框架:用于PC网站、移动网站以及RESTful Api(为什么不继续用python诸如django或者fastapi等框架?主要是目前还不熟悉)
3,Flutter移动:用于移动App搭建**
免责声明:该项目不会储存任何视资源到服务器,仅作为个人学习过程点滴积累。
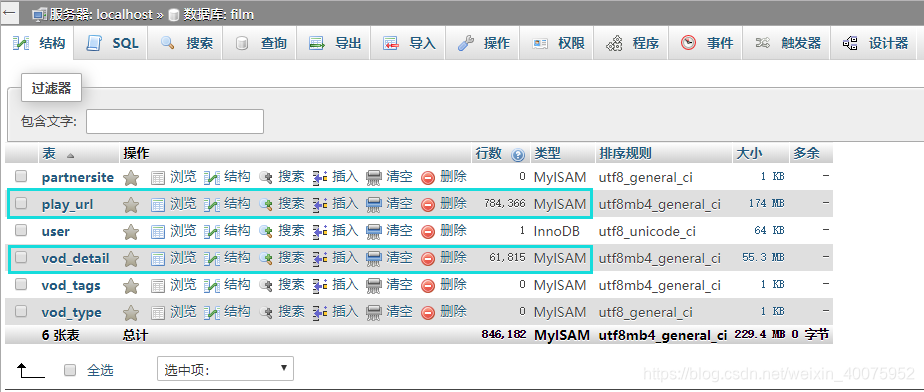
## 数据库结构:
vod_detail主要保存xx信息,play_url用于各个xx的播放地址。这里将xx信息和播放地址分开到不同的表中保存个人觉得更加合理,比如一个xxx之类的可以有多个剧集播放地址。各个字段说明见表结构。
**vod_detail:**
```powershell
-- phpMyAdmin SQL Dump
-- version 4.8.5
-- https://www.phpmyadmin.net/
--
-- 主机: localhost
-- 生成日期: 2020-09-09 10:33:32
-- 服务器版本: 5.7.26
-- PHP 版本: 7.3.4
SET SQL_MODE = "NO_AUTO_VALUE_ON_ZERO";
SET AUTOCOMMIT = 0;
START TRANSACTION;
SET time_zone = "+00:00";
--
-- 数据库: `film`
--
-- --------------------------------------------------------
--
-- 表的结构 `vod_detail`
--
CREATE TABLE `vod_detail` (
`id` int(11) NOT NULL,
`url` varchar(500) NOT NULL COMMENT '采集的url',
`url_id` varchar(100) NOT NULL COMMENT '采集的url经过加密生成的唯一字符串',
`vod_title` varchar(255) NOT NULL COMMENT 'xx名称',
`vod_sub_title` varchar(255) DEFAULT NULL COMMENT 'xx别名',
`vod_blurb` varchar(255) DEFAULT NULL COMMENT '简介',
`vod_content` longtext COMMENT '详细介绍',
`vod_status` int(11) DEFAULT '0' COMMENT '状态',
`vod_type` varchar(255) DEFAULT NULL COMMENT 'xx分类',
`vod_class` varchar(255) DEFAULT NULL COMMENT '扩展分类',
`vod_tag` varchar(255) DEFAULT NULL,
`vod_pic_url` varchar(255) DEFAULT NULL COMMENT '图片url',
`vod_pic_path` varchar(255) DEFAULT NULL COMMENT '图片下载保存路径',
`vod_pic_thumb` varchar(255) DEFAULT NULL,
`vod_actor` varchar(255) DEFAULT NULL COMMENT '演员',
`vod_director` varchar(255) DEFAULT NULL COMMENT '导演',
`vod_writer` varchar(255) DEFAULT NULL COMMENT '编剧',
`vod_remarks` varchar(255) DEFAULT NULL COMMENT 'xx版本',
`vod_pubdate` int(11) DEFAULT NULL,
`vod_area` varchar(255) DEFAULT NULL COMMENT '地区',
`vod_lang` varchar(255) DEFAULT NULL COMMENT '语言',
`vod_year` varchar(255) DEFAULT NULL COMMENT '年代',
`vod_hits` int(11) DEFAULT '0' COMMENT '总浏览数',
`vod_hits_day` int(11) DEFAULT '0' COMMENT '一天浏览数',
`vod_hits_week` int(11) DEFAULT '0' COMMENT '一周浏览数',
`vod_hits_month` int(11) DEFAULT '0' COMMENT '一月浏览数',
`vod_up` int(11) DEFAULT '0' COMMENT '顶数',
`vod_down` int(11) DEFAULT '0' COMMENT '踩数',
`vod_score` decimal(3,1) DEFAULT '0.0' COMMENT '总评分',
`vod_score_all` int(11) DEFAULT '0',
`vod_score_num` int(11) DEFAULT '0',
`vod_create_time` int(11) DEFAULT NULL COMMENT '创建时间',
`vod_update_time` int(11) DEFAULT NULL COMMENT '更新时间',
`vod_lately_hit_time` int(11) DEFAULT NULL COMMENT '最后浏览时间'
) ENGINE=MyISAM DEFAULT CHARSET=utf8mb4;
--
-- 转储表的索引
--
--
-- 表的索引 `vod_detail`
--
ALTER TABLE `vod_detail`
ADD PRIMARY KEY (`id`),
ADD UNIQUE KEY `url_id` (`url_id`) COMMENT '唯一 避免抓取过的网址重复采集';
--
-- 在导出的表使用AUTO_INCREMENT
--
--
-- 使用表AUTO_INCREMENT `vod_detail`
--
ALTER TABLE `vod_detail`
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT;
COMMIT;
```
**play_url:**
```powershell
-- phpMyAdmin SQL Dump
-- version 4.8.5
-- https://www.phpmyadmin.net/
--
-- 主机: localhost
-- 生成日期: 2020-09-09 10:34:59
-- 服务器版本: 5.7.26
-- PHP 版本: 7.3.4
SET SQL_MODE = "NO_AUTO_VALUE_ON_ZERO";
SET AUTOCOMMIT = 0;
START TRANSACTION;
SET time_zone = "+00:00";
--
-- 数据库: `film`
--
-- --------------------------------------------------------
--
-- 表的结构 `play_url`
--
CREATE TABLE `play_url` (
`id` int(11) NOT NULL,
`play_title` varchar(255) DEFAULT NULL,
`play_from` varchar(255) DEFAULT NULL,
`play_url` varchar(255) NOT NULL,
`play_url_aes` varchar(100) NOT NULL COMMENT '将url生成唯一字符串',
`url_id` varchar(100) NOT NULL COMMENT '关联vod_detail url_id',
`create_time` int(11) DEFAULT NULL,
`update_time` int(11) DEFAULT NULL
) ENGINE=MyISAM DEFAULT CHARSET=utf8mb4;
--
-- 转储表的索引
--
--
-- 表的索引 `play_url`
--
ALTER TABLE `play_url`
ADD PRIMARY KEY (`id`),
ADD UNIQUE KEY `play_url_aes` (`play_url_aes`);
--
-- 在导出的表使用AUTO_INCREMENT
--
--
-- 使用表AUTO_INCREMENT `play_url`
--
ALTER TABLE `play_url`
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT;
COMMIT;
```
## xx数据爬虫:
环境:python3.8
爬虫框架:scrapy
环境搭建配置略过。。。。
这里选择抓取的是一个xx资源站,特点就是它就是专门给别人爬取采集的,无反爬虫限制,结构简单,相应的爬虫就简单。
**(一)这里记录下安装Scrapy容易出错点及爬虫调试的配置:**
> python安装虚拟环境工具:
>
> pip install virtualenv
>
>
>
> 1,新建虚拟环境:
>
> 进入存放虚拟环境的文件夹
>
> virtualenv pachong
>
>2,Scarapy框架安装:
>
> 进入创建的虚拟环境(可以在cmd中或者pycharm命令控制台操作)
>
> 先安装Scarapy框架依赖:lxml、Twisted、pywin32 最好提前离线安装。
>
> 离线包下载地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/
>
>3,再安装scrapy
>
>4,新建Scrapy项目:进入虚拟环境 scrapy startproject MoviesSpider
>
>5, 新建一个okzy爬虫: scrapy genspider okzy okzy.co
>
> 6,如何在pychar中调试爬虫:
>
> 由于pycharm不能直接新建scrapy项目,所以可以在爬虫项目根目录新建main.py 代码如下:
>
> import os
>
> import sys
>
> from scrapy.cmdlineimport execute
>
> sys.path.append(os.path.dirname(os.path.abspath(__file__)))
>
> execute(['scrapy', 'crawl', 'cnblogs'])
**(二)爬虫目录结构:**
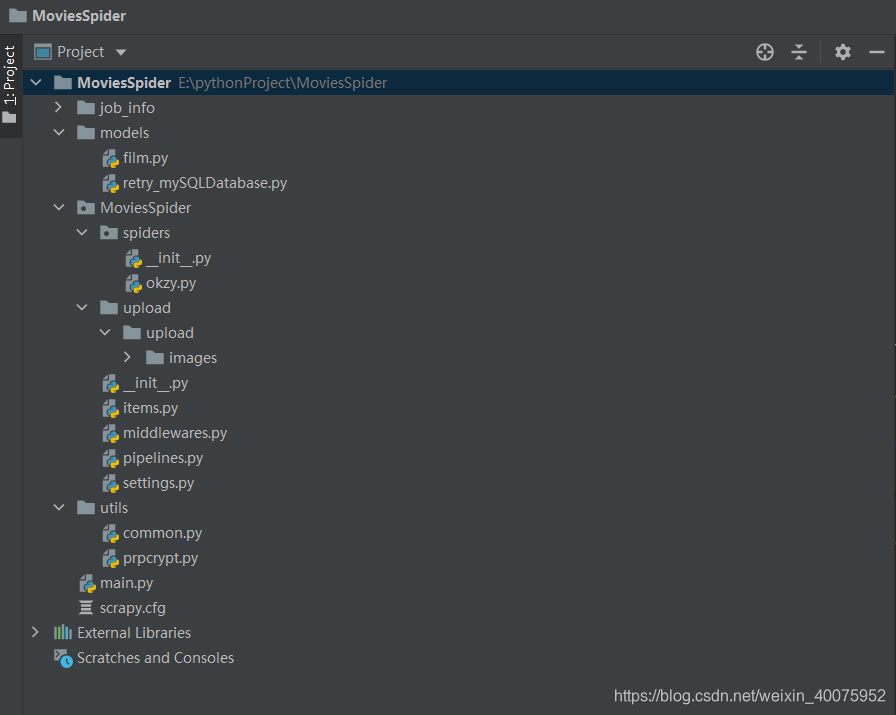
说明:scrapy基础知识工作流程这里不具体展开。
A, models目录中的film文件是使用peewee根据数据库生成的model类,关于peewee的主要作用既可以根据数据库生成model,也可以根据model类创建对应的表。peewee是一款轻量化的ORM框架,让我们更加面向对象的操作数据库。这样我们在爬取玩数据插入数据库的时候就可以不写那些麻烦又容易出错的原生SQL语句了。熟悉php yii的小伙伴可以类比yii自带的脚手架工具gii。peewee文档:(https://www.osgeo.cn/peewee/peewee/api.html)
models中的retry_mySQLDatabase文件是爬取到的数据存入Mysql时既使用连接池 又使用重连,防止连接时间过长插入数据可能出错。
**film.py代码:**
```python
from peewee import *
# database = MySQLDatabase('film', **{'charset': 'utf8', 'sql_mode': 'PIPES_AS_CONCAT', 'use_unicode': True, 'host': '127.0.0.1', 'port': 3306, 'user': 'root', 'password': 'root'})
from models.retry_mySQLDatabase import RetryMySQLDatabase
database = database = RetryMySQLDatabase.get_db_instance()
class UnknownField(object):
def __init__(self, *_, **__): pass
class BaseModel(Model):
class Meta:
database = database
class PlayUrl(BaseModel):
create_time = IntegerField(null=True)
play_from = CharField(null=True)
play_title = CharField(null=True)
play_url = CharField()
play_url_aes = CharField()
update_time = IntegerField(null=True)
url_id = CharField(unique=True)
class Meta:
table_name = 'play_url'
class VodDetail(BaseModel):
url = CharField()
url_id = CharField(unique=True)
vod_actor = CharField(null=True)
vod_area = CharField(null=True)
vod_blurb = CharField(null=True)
vod_class = CharField(null=True)
vod_content = TextField(null=True)
vod_create_time = IntegerField(null=True)
vod_director = CharField(null=True)
vod_down = IntegerField(constraints=, null=True)
vod_hits = IntegerField(constraints=, null=True)
vod_hits_day = IntegerField(constraints=, null=True)
vod_hits_month = IntegerField(constraints=, null=True)
vod_hits_week = IntegerField(constraints=, null=True)
vod_lang = CharField(null=True)
vod_lately_hit_time = IntegerField(null=True)
vod_pic_path = CharField(null=True)
vod_pic_thumb = CharField(null=True)
vod_pic_url = CharField(null=True)
vod_pubdate = IntegerField(null=True)
vod_remarks = CharField(null=True)
vod_score = DecimalField(constraints=, null=True)
vod_score_all = IntegerField(constraints=, null=True)
vod_score_num = IntegerField(constraints=, null=True)
vod_status = IntegerField(constraints=, null=True)
vod_sub_title = CharField(null=True)
vod_tag = CharField(null=True)
vod_title = CharField()
vod_type = CharField(null=True)
vod_up = IntegerField(constraints=, null=True)
vod_update_time = IntegerField(null=True)
vod_writer = CharField(null=True)
vod_year = CharField(null=True)
class Meta:
table_name = 'vod_detail'
class VodTags(BaseModel):
frequency = IntegerField(null=True)
name = CharField()
class Meta:
table_name = 'vod_tags'
class VodType(BaseModel):
type_des = CharField(constraints=, null=True)
type_en = CharField(constraints=, index=True, null=True)
type_extend = TextField(null=True)
type_jumpurl = CharField(constraints=, null=True)
type_key = CharField(constraints=, null=True)
type_logo = CharField(constraints=, null=True)
type_mid = IntegerField(constraints=, index=True, null=True)
type_name = CharField(constraints=, index=True)
type_pic = CharField(constraints=, null=True)
type_pid = IntegerField(constraints=, index=True, null=True)
type_sort = IntegerField(constraints=, index=True, null=True)
type_status = IntegerField(constraints=, null=True)
type_title = CharField(constraints=, null=True)
type_tpl = CharField(constraints=, null=True)
type_tpl_detail = CharField(constraints=, null=True)
type_tpl_down = CharField(constraints=, null=True)
type_tpl_list = CharField(constraints=, null=True)
type_tpl_play = CharField(constraints=, null=True)
type_union = CharField(constraints=, null=True)
class Meta:
table_name = 'vod_type'
```
**retry_mySQLDatabase.py代码:**
```python
from playhouse.pool import PooledMySQLDatabase
from playhouse.shortcuts import ReconnectMixin
"""
既使用连接池 又使用重连
"""
class RetryMySQLDatabase(ReconnectMixin, PooledMySQLDatabase):
_instance = None
@staticmethod
def get_db_instance():
if not RetryMySQLDatabase._instance:
RetryMySQLDatabase._instance = RetryMySQLDatabase(
'film',
**{'charset': 'utf8', 'sql_mode': 'PIPES_AS_CONCAT', 'use_unicode': True,
'host': '127.0.0.1', 'port': 3306, 'user': 'root', 'password': 'root'}
)
return RetryMySQLDatabase._instance
```
B,MoviesSpider目录是爬虫主体目录。spiders中是目标站okzy爬虫,upload中存放xx图片,items、middlewares、pipelines、settings等同学们自行熟悉Scrapy工作原理和各个文件作用。
items.py文件:OkzyMoviesDetailspiderItem和OkzyMoviesspiderPlayurlItem分别对应xx详情和xx播放地址,都定义了个save_into_sql方法配合peewee生成的model类插入爬取到的数据到mysql。MoviesItemLoader是重写ItemLoader主要是防止目标网站有些数据不存在的出错问题和数据清洗。关于input_processor和output_processor如何处理爬取到的数据,及与之类似作用的优先级问题可以参考:(https://www.cnblogs.com/python-dd/p/9550433.html)
```python
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
from itemloaders.processors import TakeFirst, MapCompose, Identity
from scrapy.loader import ItemLoader
from scrapy.loader.common import wrap_loader_context
from scrapy.utils.misc import arg_to_iter
from models.film import VodDetail, PlayUrl
from utils.common import date_convert
def MergeDict(dict1, dict2):
return dict2.update(dict1)
pass
class MapComposeCustom(MapCompose):
# 自定义MapCompose,当value没元素时传入" "
def __call__(self, value, loader_context=None):
if not value:
value.append(" ")
values = arg_to_iter(value)
if loader_context:
context = MergeDict(loader_context, self.default_loader_context)
else:
context = self.default_loader_context
wrapped_funcs =
for func in wrapped_funcs:
next_values = []
for v in values:
next_values += arg_to_iter(func(v))
values = next_values
return values
class TakeFirstCustom(TakeFirst):
"""
处理采集的元素不存在问题
"""
def __call__(self, values):
for value in values:
if value is not None and value != '':
return value.strip() if isinstance(value, str) else value
"""
重写ItemLoader,默认取第一个元素并处理不存在的元素
"""
class MoviesItemLoader(ItemLoader):
default_output_processor = TakeFirstCustom()
default_input_processor = MapComposeCustom()
class MoviesspiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
class OkzyMoviesDetailspiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
url = scrapy.Field()
url_id = scrapy.Field()
vod_title = scrapy.Field()
vod_sub_title = scrapy.Field()
vod_blurb = scrapy.Field()
vod_content = scrapy.Field()
vod_status = scrapy.Field()
vod_type = scrapy.Field()
vod_class = scrapy.Field()
vod_tag = scrapy.Field()
vod_pic_url = scrapy.Field(
output_processor=Identity())# 优先级高于default_output_processor,因为scrapy要求下载图片、文件,不能是字符串,所以默认处理
vod_pic_path = scrapy.Field()# 下载的图片保存路径
vod_pic_thumb = scrapy.Field()
vod_actor = scrapy.Field()
vod_director = scrapy.Field()
vod_writer = scrapy.Field()
vod_remarks = scrapy.Field()
vod_pubdate = scrapy.Field()
vod_area = scrapy.Field()
vod_lang = scrapy.Field()
vod_year = scrapy.Field()
vod_hits = scrapy.Field()
vod_hits_day = scrapy.Field()
vod_hits_week = scrapy.Field()
vod_hits_month = scrapy.Field()
vod_up = scrapy.Field()
vod_down = scrapy.Field()
vod_score = scrapy.Field()
vod_score_all = scrapy.Field()
vod_score_num = scrapy.Field()
vod_create_time = scrapy.Field(input_processor=MapCompose(date_convert))
vod_update_time = scrapy.Field(input_processor=MapCompose(date_convert))
vod_lately_hit_time = scrapy.Field()
pass
def save_into_sql(self):
if not VodDetail.table_exists():
VodDetail.create_table()
vod_detail = VodDetail.get_or_none(VodDetail.url_id == self['url_id'])
if vod_detail is not None:
data = vod_detail
else:
data = VodDetail()
try:
data.url = self['url']
data.url_id = self['url_id']
data.vod_title = self['vod_title']
data.vod_sub_title = self['vod_sub_title']
# data.vod_blurb = self['vod_blurb']
data.vod_content = self['vod_content']
data.vod_status = 1
data.vod_type = self['vod_type']
data.vod_class = self['vod_class']
# data.vod_tag=self['vod_tag']
data.vod_pic_url = self['vod_pic_url']
data.vod_pic_path = self['vod_pic_path']
# data.vod_pic_thumb=self['vod_pic_thumb']
data.vod_actor = self['vod_actor']
data.vod_director = self['vod_director']
# data.vod_writer=self['vod_writer']
data.vod_remarks = self['vod_remarks']
# data.vod_pubdate=self['vod_pubdate']
data.vod_area = self['vod_area']
data.vod_lang = self['vod_lang']
data.vod_year = self['vod_year']
# data.vod_hits=self['vod_hits']
# data.vod_hits_day=self['vod_hits_day']
# data.vod_hits_week=self['vod_hits_week']
# data.vod_hits_month=self['vod_hits_month']
# data.vod_up=self['vod_up']
# data.vod_down=self['vod_down']
data.vod_score = self['vod_score']
data.vod_score_all = self['vod_score_all']
data.vod_score_num = self['vod_score_num']
data.vod_create_time = self['vod_create_time']
data.vod_update_time = self['vod_update_time']
# data.vod_lately_hit_time = self['vod_lately_hit_time']
row = data.save()
except Exception as e:
print(e)
pass
class OkzyMoviesspiderPlayurlItem(scrapy.Item):
play_title = scrapy.Field()
play_from = scrapy.Field()
play_url = scrapy.Field()
play_url_aes = scrapy.Field()
url_id = scrapy.Field()
create_time = scrapy.Field(input_processor=MapCompose(date_convert))
update_time = scrapy.Field(input_processor=MapCompose(date_convert))
def save_into_sql(self):
if not PlayUrl.table_exists():
PlayUrl.create_table()
play_url = PlayUrl.get_or_none(PlayUrl.play_url_aes == self['play_url_aes'])
if play_url is not None:
data = play_url
else:
data = PlayUrl()
try:
data.play_title = self['play_title']
data.play_from = self['play_from']
data.play_url = self['play_url']
data.play_url_aes = self['play_url_aes']
data.url_id = self['url_id']
data.create_time = self['create_time']
data.update_time = self['update_time']
row = data.save()
except Exception as e:
print(e)
pass
pass
```
pipelines.py文件:MovieImagesPipeline类重写scrapy.pipelines.images.ImagesPipeline 获取图片下载地址 给items,MysqlPipeline类是插入爬取的数据存入mysql。
```python
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import re
from scrapy import Request
# useful for handling different item types with a single interface
from scrapy.pipelines.images import ImagesPipeline
from utils.common import pinyin
class MoviesspiderPipeline:
def process_item(self, item, spider):
return item
# 重写scrapy.pipelines.images.ImagesPipeline 获取图片下载地址 给items
class MovieImagesPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
if "vod_pic_url" in item:
for vod_pic_url in item['vod_pic_url']:
yield Request(url=vod_pic_url, meta={'item': item})# 添加meta是为了下面重命名文件名使用
def file_path(self, request, response=None, info=None):
item = request.meta['item']
movietitle = item['vod_title']
#去除特殊字符,只保留汉子,字母、数字
sub_str = re.sub(u"([^\u4e00-\u9fa5\u0030-\u0039\u0041-\u005a\u0061-\u007a])", "", movietitle)
img_guid = request.url.split('/')[-1]# 得到图片名和后缀
filename = '/upload/images/{0}/{1}'.format(pinyin(sub_str), img_guid)
return filename
# return super().file_path(request, response, info)
# def thumb_path(self, request, thumb_id, response=None, info=None):
# item = request.meta['item']
# movietitle = pinyin(item['vod_title'])
# img_guid = request.url.split('/')[-1]# 得到图片名和后缀
# filename = '/images/{0}/thumbs/{1}/{2}'.format(movietitle, thumb_id, img_guid)
# return filename
def item_completed(self, results, item, info):
image_file_path = ""
if "vod_pic_url" in item:
for ok, value in results:
image_file_path = value["path"]
item["vod_pic_path"] = image_file_path
return item
class MysqlPipeline(object):
def process_item(self, item, spider):
"""
每个item中都实现save_into_sql()方法,就可以用同一个MysqlPipeline去处理
:param item:
:param spider:
:return:
"""
item.save_into_sql()
return item
```
settings.py主要设置了图片下载item及路径。
```python
# Scrapy settings for MoviesSpider project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
import os
current_dir = os.path.dirname(os.path.abspath(__file__))
BOT_NAME = 'MoviesSpider'
SPIDER_MODULES = ['MoviesSpider.spiders']
NEWSPIDER_MODULE = 'MoviesSpider.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
# USER_AGENT = 'MoviesSpider (+http://www.yourdomain.com)'
# Obey robots.txt rules
# ROBOTSTXT_OBEY = True
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
# CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
# DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
# CONCURRENT_REQUESTS_PER_DOMAIN = 16
# CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
# COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
# TELNETCONSOLE_ENABLED = False
# Override the default request headers:
# DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
# }
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
# SPIDER_MIDDLEWARES = {
# 'MoviesSpider.middlewares.MoviesspiderSpiderMiddleware': 543,
# }
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# DOWNLOADER_MIDDLEWARES = {
# 'MoviesSpider.middlewares.MoviesspiderDownloaderMiddleware': 543,
# }
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
# EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
# }
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'MoviesSpider.pipelines.MoviesspiderPipeline': 300,
# 重写scrapy.pipelines.images.ImagesPipeline 获取图片下载地址 给items
'MoviesSpider.pipelines.MovieImagesPipeline': 1,
'MoviesSpider.pipelines.MysqlPipeline': 20,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
# AUTOTHROTTLE_ENABLED = True
# The initial download delay
# AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
# AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
# AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
# AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
# HTTPCACHE_ENABLED = True
# HTTPCACHE_EXPIRATION_SECS = 0
# HTTPCACHE_DIR = 'httpcache'
# HTTPCACHE_IGNORE_HTTP_CODES = []
# HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
# 图片下载路径配置
IMAGES_STORE = os.path.join(current_dir, 'upload')
# 配置要下载的item
IMAGES_URLS_FIELD = "vod_pic_url"
# 生成图片缩略图,添加设置
# IMAGES_THUMBS = {
# 'small': (80, 80),
# 'big': (200, 200),
# }
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36'
# RANDOMIZE_DOWNLOAD_DELAY = True
# DOWNLOAD_DELAY = 2
```
关于scrapy图片、文件下载配置自行参考文档。值得注意的一点,因为scrapy要求下载图片、文件,不能是字符串,所以item中使用默认处理vod_pic_url = scrapy.Field( output_processor=Identity())。
C,spiders目录中的okzy文件是爬虫。由于目标站结构简单所以爬虫就相对简单。parse方法是解析xx列表获取详情页地址,parse_detail是解析详情页获得xx详情及播放地址。
```python
from urllib import parse
import scrapy
from scrapy import Request
from MoviesSpider.items import OkzyMoviesDetailspiderItem, OkzyMoviesspiderPlayurlItem, MoviesItemLoader
from utils import common
class OkzySpider(scrapy.Spider):
name = 'okzy'
allowed_domains = ['okzy.co']
start_urls = ['https://okzy.co/?m=vod-index-pg-1.html']
# start_urls = ['https://okzy.co/?m=vod-type-id-22-pg-1.html']
def parse(self, response):
all_urls = response.css(".xing_vb4 a::attr(href)").extract()
for url in all_urls:
yield Request(url=parse.urljoin(response.url, url), callback=self.parse_detail)
list_urls = list(range(1, 3))
list_urls.reverse()
# for i in list_urls:
# url = 'https://okzy.co/?m=vod-index-pg-{0}.html'.format(i)
# yield Request(url=url, callback=self.parse)
def parse_detail(self, response):
voddetail_item_loader = MoviesItemLoader(item=OkzyMoviesDetailspiderItem(), response=response)
voddetail_item_loader.add_value('url', response.url)
voddetail_item_loader.add_value("url_id", common.get_md5(response.url))
voddetail_item_loader.add_css('vod_title', 'h2::text')
voddetail_item_loader.add_css('vod_sub_title',
'.vodinfobox > ul:nth-child(1) > li:nth-child(1) > span:nth-child(1)::text')
# voddetail_item_loader.add_xpath('vod_blurb', '//h2/text()')
voddetail_item_loader.add_css('vod_content', 'div.ibox:nth-child(2) > div:nth-child(2)::text')
# voddetail_item_loader.add_xpath('vod_status', '//h2/text()')
voddetail_item_loader.add_css('vod_type',
'.vodinfobox > ul:nth-child(1) > li:nth-child(4) > span:nth-child(1)::text')
voddetail_item_loader.add_xpath('vod_class',
'/html/body/div/div/div/div/div/div/ul/li/span/a/text()')
# voddetail_item_loader.add_xpath('tag', '//h2/text()'
voddetail_item_loader.add_css('vod_pic_url', '.lazy::attr(src)')
# voddetail_item_loader.add_xpath('vod_pic_thumb', '//h2/text()')
voddetail_item_loader.add_css('vod_actor',
'.vodinfobox > ul:nth-child(1) > li:nth-child(3) > span:nth-child(1)::text')
voddetail_item_loader.add_css('vod_director',
'.vodinfobox > ul:nth-child(1) > li:nth-child(2) > span:nth-child(1)::text')
# voddetail_item_loader.add_xpath('vod_writer', '//h2/text()')
voddetail_item_loader.add_css('vod_remarks', '.vodh > span:nth-child(2)::text')
# voddetail_item_loader.add_xpath('vod_pubdate', '//h2/text()')
voddetail_item_loader.add_css('vod_area', 'li.sm:nth-child(5) > span:nth-child(1)::text')
voddetail_item_loader.add_css('vod_lang', 'li.sm:nth-child(6) > span:nth-child(1)::text')
voddetail_item_loader.add_css('vod_year', 'li.sm:nth-child(7) > span:nth-child(1)::text')
# voddetail_item_loader.add_xpath('vod_hits', '//h2/text()')
# voddetail_item_loader.add_xpath('vod_hits_day', '//h2/text()')
# voddetail_item_loader.add_xpath('vod_hits_week', '//h2/text()')
# voddetail_item_loader.add_xpath('vod_hits_month', '//h2/text()')
# voddetail_item_loader.add_xpath('vod_up', '//h2/text()')
# voddetail_item_loader.add_xpath('vod_down', '//h2/text()')
voddetail_item_loader.add_css('vod_score', '.vodh > label:nth-child(3)::text')
voddetail_item_loader.add_css('vod_score_all', 'li.sm:nth-child(12) > span:nth-child(1)::text')
voddetail_item_loader.add_css('vod_score_num', 'li.sm:nth-child(13) > span:nth-child(1)::text')
voddetail_item_loader.add_css('vod_create_time', 'li.sm:nth-child(9) > span:nth-child(1)::text')
voddetail_item_loader.add_css('vod_update_time', 'li.sm:nth-child(9) > span:nth-child(1)::text')
# voddetail_item_loader.add_xpath('vod_lately_hit_time', '//h2/text()')
okzyMoviesspiderItem = voddetail_item_loader.load_item()
# 解析m3u8格式播放地址
ckm3u8playurlList = response.xpath('//*[@id="2"]/ul/li/text()').extract()
for ckm3u8playurlInfo in ckm3u8playurlList:
m3u8playurlInfoList = ckm3u8playurlInfo.split('$')
vodm3u8playurl_item_loader = MoviesItemLoader(item=OkzyMoviesspiderPlayurlItem(), response=response)
vodm3u8playurl_item_loader.add_value('play_title', m3u8playurlInfoList)
vodm3u8playurl_item_loader.add_value('play_url', m3u8playurlInfoList)
vodm3u8playurl_item_loader.add_value('play_url_aes', common.get_md5(m3u8playurlInfoList))
vodm3u8playurl_item_loader.add_xpath('play_from', '//*[@id="2"]/h3/span/text()')
vodm3u8playurl_item_loader.add_value("url_id", common.get_md5(response.url))
vodm3u8playurl_item_loader.add_css('create_time', 'li.sm:nth-child(9) > span:nth-child(1)::text')
vodm3u8playurl_item_loader.add_css('update_time', 'li.sm:nth-child(9) > span:nth-child(1)::text')
okzyMoviesm3u8PlayurlspiderItem = vodm3u8playurl_item_loader.load_item()
yield okzyMoviesm3u8PlayurlspiderItem
# 解析mp4格式播放地址
mp4playurlList = response.xpath('//*[@id="down_1"]/ul/li/text()').extract()
for mp4playurlInfo in mp4playurlList:
mp4playurlInfoList = mp4playurlInfo.split('$')
vodmp4playurl_item_loader = MoviesItemLoader(item=OkzyMoviesspiderPlayurlItem(), response=response)
vodmp4playurl_item_loader.add_value('play_title', mp4playurlInfoList)
vodmp4playurl_item_loader.add_value('play_url', mp4playurlInfoList)
vodmp4playurl_item_loader.add_value('play_url_aes', common.get_md5(mp4playurlInfoList))
vodmp4playurl_item_loader.add_xpath('play_from', '//*[@id="down_1"]/h3/span/text()')
vodmp4playurl_item_loader.add_value("url_id", common.get_md5(response.url))
vodmp4playurl_item_loader.add_css('create_time', 'li.sm:nth-child(9) > span:nth-child(1)::text')
vodmp4playurl_item_loader.add_css('update_time', 'li.sm:nth-child(9) > span:nth-child(1)::text')
okzyMoviesmp4PlayurlspiderItem = vodmp4playurl_item_loader.load_item()
yield okzyMoviesmp4PlayurlspiderItem
yield okzyMoviesspiderItem
```
本机测试爬取了6W多条xx详情和78W条xx播放地址,下载6W多张xx图片半天时间足够了。
下节预告:将使用yii框架快速搭建xx展示的WEB网站和编写符合restful风格的Api。
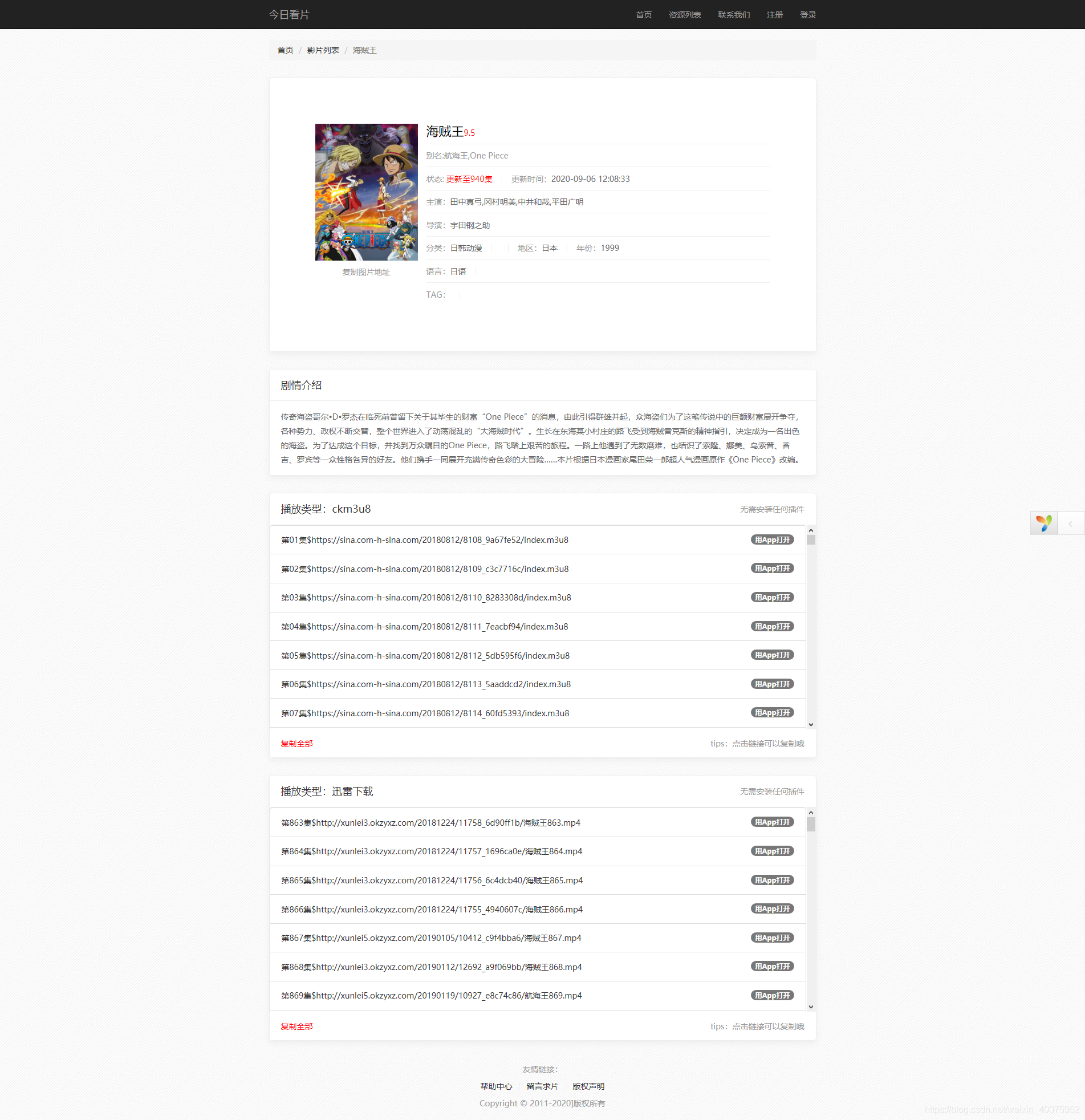
WEB网站展示:
!(https://img-blog.csdnimg.cn/20200909123510895.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MDA3NTk1Mg==,size_16,color_FFFFFF,t_70#pic_center)
 论坛管理也是有问题,人家辛辛苦苦弄出来的教程发出来,还得把所有版权去掉,呵呵 非法菜鸟 发表于 2020-10-14 22:22
博主 好厉害 怎么爬去资源站更新后的内容 不能每次都全站都重新爬一遍吧? 求解惑
list_urls = list(range(1, 3))
list_urls.reverse()
# for i in list_urls:
# url = 'https://okzy.co/?m=vod-index-pg-{0}.html'.format(i)
# yield Request(url=url, callback=self.parse)
注意看这段代码,我解决的方案很简单,整站爬完后可以设置爬取列表的前三页,再配合计划任务每隔多长时间去爬取前三页列表就行了 先收藏了 期待楼主更多的教程,关注一波 不错的教程,关注中 教程有用 楼主有博客不?? 在这里竟然能看到技术文章,赞赞赞! 教程不错,收藏了 感谢楼主付出,更希望楼主能整合成一个PDF文档。 楼主牛逼 不太看不懂。