【opencv】Haar分类器及Adaboost算法人脸识别
# 引言提到opencv,就不得不提其图像识别能力,最近旷世开源的(https://github.com/Megvii-BaseDetection/YOLOX)兴起,作为目前Yolo系列中的最强者,本人对其也很感兴趣,但是完全没用机器学习和计算机视觉的基础,知其然,不知其所以然,于是想稍稍入坑一下opencv图像识别,了解一下相关算法,(说不定以后毕设会用到呢)。了解之后选取了人脸识别中Haar特征和Adaboost分类器作为学习对象。以此记录自己的学习成果。
# 一、opencv识别基本流程
[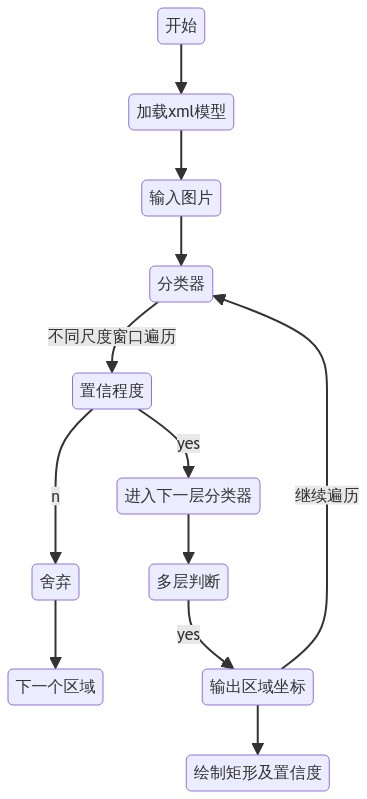](https://mermaid-js.github.io/mermaid-live-editor/edit##eyJjb2RlIjoiZ3JhcGggVERcbkFbQ2hyaXN0bWFzXSAtLT58R2V0IG1vbmV5fCBCKEdvIHNob3BwaW5nKVxuQiAtLT4gQ3tMZXQgbWUgdGhpbmt9XG5DIC0tPnxPbmV8IERbTGFwdG9wXVxuQyAtLT58VHdvfCBFW2lQaG9uZV1cbkMgLS0-fFRocmVlfCBGW2ZhOmZhLWNhciBDYXJdXG4iLCJtZXJtYWlkIjoie1xuICBcInRoZW1lXCI6IFwiZGVmYXVsdFwiXG59IiwidXBkYXRlRWRpdG9yIjpmYWxzZSwiYXV0b1N5bmMiOnRydWUsInVwZGF0ZURpYWdyYW0iOnRydWV9)
## 1.1 XML模型调用
从opencv路径中找到自带的训练好的分类器`haarcascade_eye.xml`、`haarcascade_frontalface_alt_tree.xml`
```python
import cv2 as cv
def face_detection(image):
gray = cv.cvtColor(image, cv.COLOR_BGR2GRAY)# 图像灰度化
face_detector = cv.CascadeClassifier("haarcascade_frontalface_alt_tree.xml")# 调用分类器加载脸部模型
eyes_detector = cv.CascadeClassifier("haarcascade_eye.xml")# 调用分类器加载眼部模型
faces = face_detector.detectMultiScale(gray, 1.01, 5)# 扫描图片,返回结果坐标
"""
detectMultiScale(self, image, scaleFactor=None, minNeighbors=None, minSize=None, maxSize=None)
image:输入的图像
scaleFactor:比例因子,图像尺寸每次减少的比例,要大于1,需自己调整
minNeighbors:最小附近像素值
"""
for x, y, w, h in faces:
img = cv.rectangle(image, (x, y), (x + w, y + h), (0, 0, 255), 2)# 在面部画矩形
roi_gray = gray# 获取面部区域灰度矩阵
roi_color = img
eyes = eyes_detector.detectMultiScale(roi_gray, 1.3, 5)# 继续检测眼部
for ex, ey, ew, eh in eyes:
cv.rectangle(roi_color, (ex, ey), (ex + ew, ey + ey), (0, 255, 0), 2)# 在眼部画矩形
cv.imshow("result", image)# 显示
def main():
src = cv.imread("test.jpg")
cv.namedWindow("input image", cv.WINDOW_AUTOSIZE)
cv.imshow("input image", src)
face_detection(src)
cv.waitKey(0)
cv.destroyAllWindows()# 关闭所有窗口
if __name__ == '__main__':
main()
```
## 1.2 运行结果:
!(https://i.loli.net/2021/09/04/wqos5CHO41rW3kX.png)
面部和眼部都识别出来,效果不错。
# 二、XML模型训练
## 2.1 需要解决的问题
> 1、如何准确判断识别目标 ——> Haar-like特征
>
> 2、如何训练出可以识别的网络 ——> Adaboost级联分类器
## 2.2 Haar-like特征
Haar特征是用黑色和白色矩形组成的矩形,用于代表面部某个区域的明暗情况,其分为三类:边缘特征、线性特征、中心特征和对角线特征,组合成特征。
特征值计算方式为:白色矩形像素和减去黑色矩形像素和。
基础特征有:
!(https://i.loli.net/2021/09/04/aHohg7xkmrPCv9K.png)
Haar特征使用举例:
!(https://i.loli.net/2021/09/04/3ecAdjLWPy9pUOM.png)
其中中间一幅表示眼睛区域的颜色比脸颊区域的颜色深,右边一幅表示鼻梁两侧比鼻梁的颜色要深。
矩形特征可位于图像任意位置,大小也可以任意改变,所以矩形特征值是矩形模版类别、矩形位置和矩形大小这三个因素的函数。因此很小的图像区域可以算出极大量的特征值,这对于计算机是个很大的负荷,于是需要使用积分图来降低运算难度。
## 2.3 积分图计算
积分图的目标是将一幅图所有从原点到目标点的矩形的像素和的值保存在内存中,需要计算矩形像素和时只需要简单加减法就能得到结果,速度稳定,可以大大提高运算效率。其计算方法是遍历出每个点到原点的矩形的像素和,或通过递推快速计算。
积分图是一个二维矩阵,令其为S。
初始化:
令p(-1,j)=0,其中p为该整列的像素和;
令S(-1,j)=0;
递推关系:
S(i,j)=S(i-1,j)+p(i,j);
p(i,j)=p(i,j-1)+f(i,j);
其中f(i,j)为该位置的像素值;
最终得到一个矩阵S用于计算。
例:对于该特征,计算其特征值,坐标分别为a、b、c、d、e、f。
!(https://i.loli.net/2021/09/04/kj4cuwCzB6agmrG.png)
公式:
Sum=S(e)+S(a)-S(b)-S(d)-S(f)-S(b)+S(e)+S(c)
因此,特征值的计算速度几乎是恒定的。
## 2.4 Adaboost级联分类器
Boost分类器原理:
> Boosting算法的工作机制是首先从训练集用初始权重D(1)训练出一个弱学习器1,根据弱学习的学习误差率表现来更新训练样本的权重,使得之前弱学习器1学习误差率高的训练样本点的权重变高,使得这些误差率高的点在后面的弱学习器2中得到更多的重视。然后基于调整权重后的训练集来训练弱学习器2.,如此重复进行,直到弱学习器数达到事先指定的数目T,最终将这T个弱学习器通过集合策略进行整合,得到最终的强学习器。
Adaboost基本模型:
[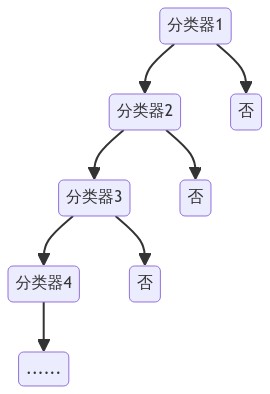](https://mermaid-js.github.io/mermaid-live-editor/edit##eyJjb2RlIjoiXG5ncmFwaCBUQlxuXHRpZDEo5YiG57G75ZmoMSktLT5pZDIo5YiG57G75ZmoMilcblx0aWQxKOWIhuexu-WZqDEpLS0-bm8xKOWQpilcblx0aWQyKOWIhuexu-WZqDIpLS0-aWQzKOWIhuexu-WZqDMpXG5cdGlkMijliIbnsbvlmagyKS0tPm5vMijlkKYpXG5cdGlkMyjliIbnsbvlmagzKS0tPmlkNCjliIbnsbvlmag0KVxuXHRpZDMo5YiG57G75ZmoMyktLT5ubzMo5ZCmKVxuXHRpZDQo5YiG57G75ZmoNCktLT5nbyguLi4uLi4pIiwibWVybWFpZCI6IntcbiAgXCJ0aGVtZVwiOiBcImRlZmF1bHRcIlxufSIsInVwZGF0ZUVkaXRvciI6ZmFsc2UsImF1dG9TeW5jIjp0cnVlLCJ1cGRhdGVEaWFncmFtIjpmYWxzZX0)
其中,只有图片通过了所有的检测才能输出,否则舍弃,这样做的好处是可以在某一阶段放弃计算错误数据,转而进行下一次计算,节省了相当多的时间。
## 2.5 级联分类器的训练
关于级联分类器的概率论与数理统计原理,由于本人还没有完全搞懂,暂且不表,详细算法见参考文献。
这里介绍一下opencv训练xml文件的流程。
所需文件:
> 正样本:识别目标的样本图片n份
>
> 负样本:完全不包含目标的样本3n份
opencv提供了训练用的源代码:(https://github.com/opencv/opencv/blob/master/apps/traincascade/traincascade.cpp)
traincascade详细参数、使用说明见[官网文档](https://docs.opencv.org/2.4/doc/user_guide/ug_traincascade.html)
生成训练样本代码:(https://github.com/opencv/opencv/blob/master/apps/createsamples/createsamples.cpp)将样本封装为训练用数据集
如果是下载源代码后编译的opencv,文件夹中会自动生成相应的可执行文件。
训练流程:
[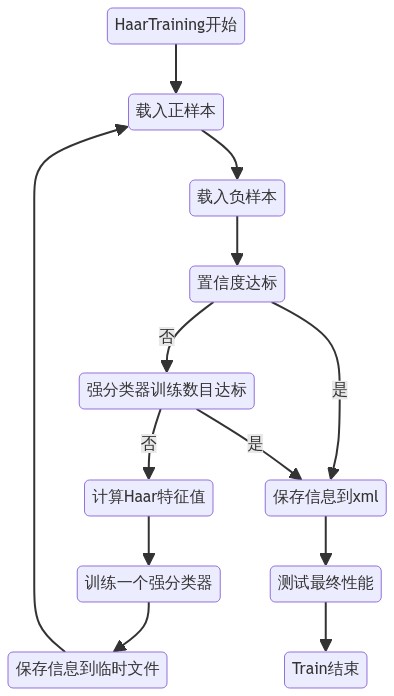](https://mermaid-js.github.io/mermaid-live-editor/edit##eyJjb2RlIjoiZ3JhcGggVEJcblx0aWQxKOWIhuexu-WZqDEpLS0-aWQyKOWIhuexu-WZqDIpXG5cdGlkMSjliIbnsbvlmagxKS0tPm5vMSjlkKYpXG5cdGlkMijliIbnsbvlmagyKS0tPmlkMyjliIbnsbvlmagzKVxuXHRpZDIo5YiG57G75ZmoMiktLT5ubzIo5ZCmKVxuXHRpZDMo5YiG57G75ZmoMyktLT5pZDQo5YiG57G75ZmoNClcblx0aWQzKOWIhuexu-WZqDMpLS0-bm8zKOWQpilcblx0aWQ0KOWIhuexu-WZqDQpLS0-Z28oLi4uLi4uKSIsIm1lcm1haWQiOiJ7XG4gIFwidGhlbWVcIjogXCJkZWZhdWx0XCJcbn0iLCJ1cGRhdGVFZGl0b3IiOmZhbHNlLCJhdXRvU3luYyI6dHJ1ZSwidXBkYXRlRGlhZ3JhbSI6ZmFsc2V9)
# 三、参考文献
(https://github.com/Megvii-BaseDetection/YOLOX)
(https://github.com/opencv/opencv/blob/master)
(https://docs.opencv.org/2.4/doc/user_guide/ug_traincascade)
(https://blog.csdn.net/sazass/article/details/89150468)
(https://www.cnblogs.com/zyly/p/9416263.html)
(https://www.cnblogs.com/zyly/p/9410563.html)
.软件,2021,42(04):45-47](https://kns.cnki.net/kcms/detail/detail.aspx?dbcode=CJFD&dbname=CJFDLAST2021&filename=RJZZ202104015&uniplatform=NZKPT&v=MdE1zV8IK9T34cG5iD%25mmd2FEDHb4ccs%25mmd2BUB2WFvrU3IyHP%25mmd2FlWwXyI7gpz%25mmd2Fmv1u1kgkS6S) 希望继续更新! 以前写论文的时候用这个技术来做车牌定位,效果不错,呵呵 plauger 发表于 2021-9-4 10:59
以前写论文的时候用这个技术来做车牌定位,效果不错,呵呵
以前用Yolov3部署过车牌识别,这回想深入了解下图像识别原理了{:301_986:} 技术文章厉害了 深入浅出{:1_893:} 不错 一直对深度识别感兴趣 到时研究研究
页:
[1]