【原创源码】【Python】爬虫学习-Scrape Center闯关(spa4,spa5,spa6)
# 场景这次记录的是spa系列的4-6个,分别对应的技巧是智能分析,有翻页批量抓取,js逆向分析
# 关卡
## spa4
新闻网站索引,无反爬,数据通过 Ajax 加载,无页码翻页,适合 Ajax 分析和动态页面渲染抓取以及智能页面提取分析。
智能解析的知识点详情:[智能解析详解](https://blog.csdn.net/qq_37275405/article/details/103225099?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-1.no_search_link&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-1.no_search_link)
我在本次实验中使用的是newspaper库:(https://zhuanlan.zhihu.com/p/101679529)
使用智能解析方便快捷,结果的话抓取十个链接,可能出错的有2-3个,还可以接受的
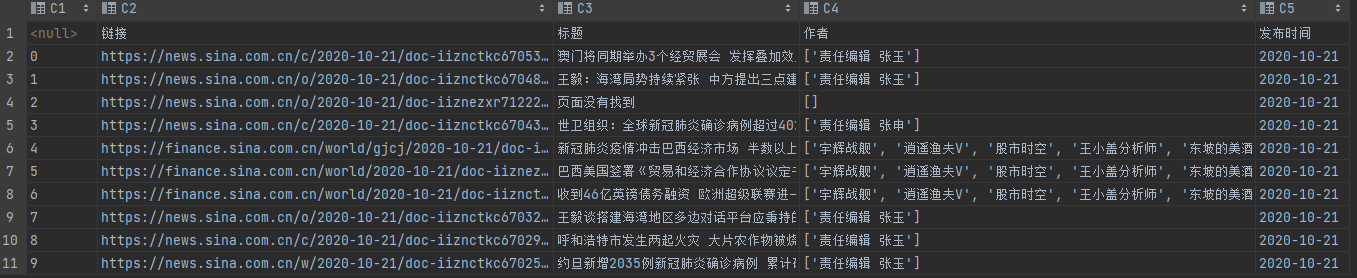
总代码:
```
import json
import pandas as pd
import requests
import urllib3
from newspaper import Article
urllib3.disable_warnings()#去除因为网页没有ssl证书出现的警告
title,url,authors,published = [],[],[],[]
headers ={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/87.0.4280.141 Safari/537.36'}
the_url = 'https://spa4.scrape.center/api/news/?limit=10&offset=0'
response=requests.get(the_url,headers=headers,verify=False)
data = json.loads(response.text)
for i in range(0,10):
url.append(data['results']['url'])
news = Article(url,language='zh')
news.download()#加载网页
news.parse() # 解析网页
title.append(news.title)
authors.append(news.authors)
published.append(news.publish_date)
bt = {
"链接":url,
"标题":title,
"作者":authors,
"发布时间":published
}
work = pd.DataFrame(bt)
work.to_csv('work.csv')
```
## spa5
图书网站,无反爬,数据通过 Ajax 加载,有翻页,适合大批量动态页面渲染抓取。
最后结果抓取:
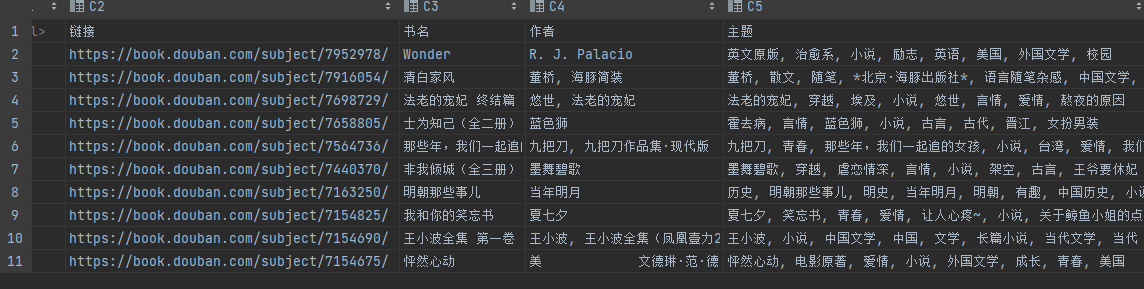
```
import json
import pandas as pd
import requests
import urllib3
name,authors,url,content,theme,id=[],[],[],[],[],[]
headers ={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/87.0.4280.141 Safari/537.36'}
urllib3.disable_warnings()#去除因为网页没有ssl证书出现的警告
the_url = 'https://spa5.scrape.center/api/book/?limit=10&offset=0'
response=requests.get(the_url,headers=headers,verify=False)
data = json.loads(response.text)
for i in range(0,10):
id.append(data['results']['id'])
name.append(data['results']['name'])
authors.append(str(data['results']['authors']).replace('[','').replace("\\n","").replace("'","").replace(']','').strip())
for a in id:
the_url = 'https://spa5.scrape.center/api/book/'+a+'/'
response=requests.get(the_url,headers=headers,verify=False)
data = json.loads(response.text)
url.append(data['url'])
theme.append(str(data['tags']).replace('[','').replace("'","").replace(']','').strip())
bt= {
"链接":url,
"书名":name,
"作者":authors,
"主题":theme,
}
work = pd.DataFrame(bt)
work.to_csv('work.csv')
```
## spa6
电影数据网站,数据通过 Ajax 加载,数据接口参数加密且有时间限制,源码经过混淆,适合 JavaScript 逆向分析。
### 分析网站主页token产生的js
先进行分析,在开始的地方和我前面的文章spa2一样,可以参考一下
(https://www.52pojie.cn/thread-1539359-1-1.html)
这就是token加密的代码块
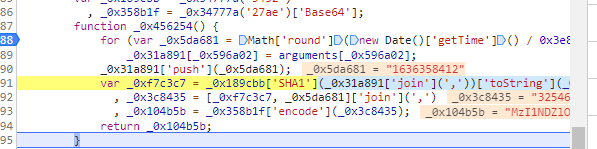
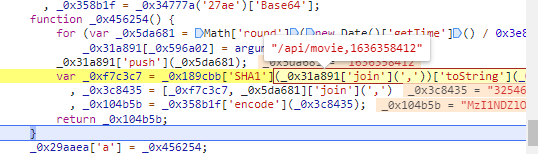
我们可以看到先sha1加密这样的一组数据
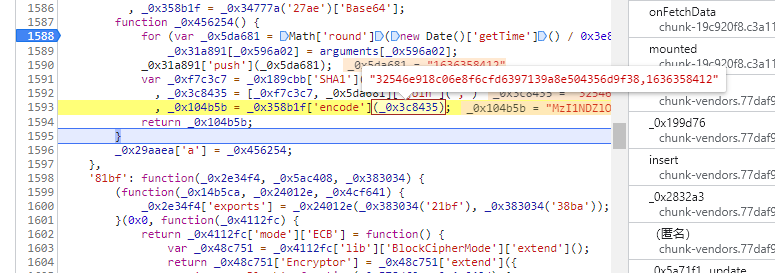
然后将经过SHA1加密的字符串继续与时间戳结合进行encode加密,对encode加密进行分析

追溯到这一步,整了大半天,原来
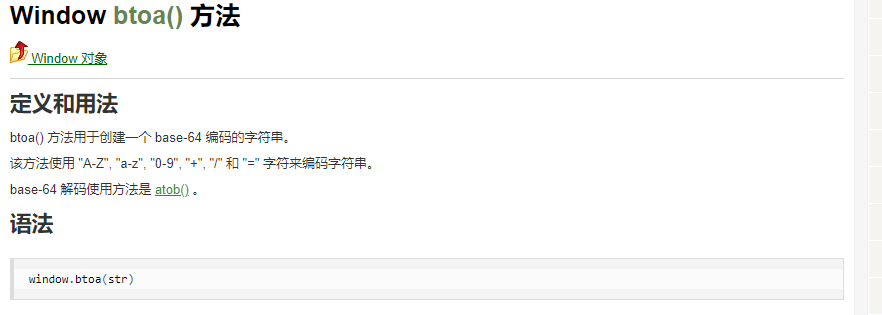
找了半天发现没直接使用base64的加密
这样,token的加密方式就已经解出来了,步骤为:
o=sha1(url,时间戳)=>c=Base64(o,时间戳)=> token=c
转换为代码为:
SHA1加密
```
t = int(time.time()) #获取10位整数的时间戳
s1 = f'/api/movie,{t}'
o = hashlib.sha1(s1.encode('utf-8')).hexdigest() #进行SHA1加密
```
Base64加密:
```
str_str = str(f"{o},{t}")
bytesStr = str_str.encode(encoding='utf-8')
b64str = base64.b64encode(bytesStr) #最后的base64加密
b64str = b64str.decode('utf-8') # 将字节转换为str
```
b64str就是最后的token的值了,在这个过程中需要注意的是两次加密,共用的是同一个时间戳,并不是一次加密获取一个
### 分析网站电影详情页的url中的加密
和前面的一样,先进行分析,在开始的地方和我前面的文章spa2一样,可以参考一下
(https://blog.csdn.net/Destiny_one/article/details/121136061)
找到代码块,然后单步进入

找到熟悉的代码块,这就是刚才分析的token的产生方式,所以我们发现这两个是一样的

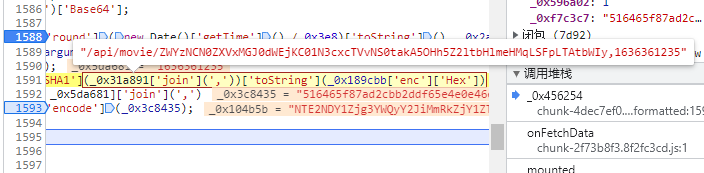
就这一步的url需要加上生成加密字符串再加密,下来的基本都和上面的一样了
然后分析前面的加密字符串
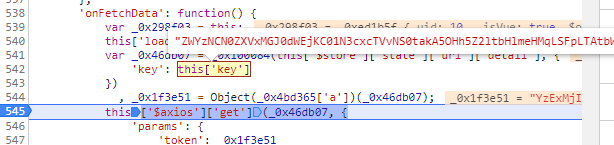
可以发现在token产生之前,这串字符串就已经产生,指向的是一个key的值,我们直接全局搜索key值
找到key产生的代码块
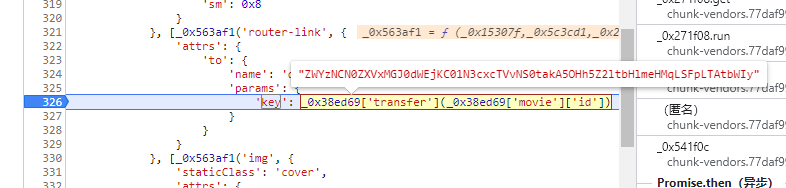
单步调试,熟悉的代码块,和spa3中一样的写死的一串字符经过加密转换后产生
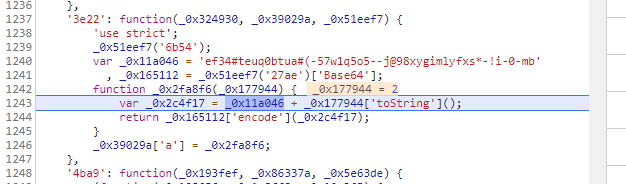
经过分析是将下图中这个字符串同样经过encode加密,也就是上面分析得base64加密

所以加密的方式为:
Base64(ef34#teuq0btua#(-57w1q5o5–j@98xygimlyfxs*-!i-0-mb+第几部电影的数值)
这部分代码的加密和上面的类似,就不再单独写
最后,所有的加密方式以及对应的代码都已经分析好了
```
import base64
import json
import time
import urllib3
import requests
import pandas as pd
import hashlib
urllib3.disable_warnings()#去除因为网页没有ssl证书出现的警告
url,title,theme,score,content = [],[],[],[],[]
headers ={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/87.0.4280.141 Safari/537.36'}
global url_list,title_list,theme_list,score_list,content_list,t
def token1():
t = int(time.time())# 获取10位整数的时间戳
s1 = f'/api/movie,{t}'
o = hashlib.sha1(s1.encode('utf-8')).hexdigest() #进行SHA1加密
str_str = str(f"{o},{t}")
bytesStr = str_str.encode(encoding='utf-8')
b64str = base64.b64encode(bytesStr) #最后的base64加密
b64str_all = b64str.decode('utf-8') # 将字节转换为str
return b64str_all
def token2():
a = 'ef34#teuq0btua#(-57w1q5o5--j@98xygimlyfxs*-!i-0-mb' + str(y)
bytesStr = a.encode(encoding='utf-8')
b64str = base64.b64encode(bytesStr).decode('utf-8')
return b64str
def decode2(b64str):
t = int(time.time())# 获取10位整数的时间戳
s1 = f'/api/movie/{b64str},{t}'
o = hashlib.sha1(s1.encode('utf-8')).hexdigest()# 进行SHA1加密
str_str =(f"{o},{t}")
bytesStr = str_str.encode(encoding='utf-8')
b64str = base64.b64encode(bytesStr)# 最后的base64加密
b64str_all = b64str.decode('utf-8')# 将字节转换为str
return b64str_all
for i in range(0,10):
the_url = "https://spa6.scrape.center/api/movie/?limit=10&offset="+str(i*10)+"&token="+token1()
index=requests.get(the_url,headers=headers,verify=False)
dict_data = json.loads(index.text) #将响应的内容转化为json
for x in range(0,10):
title.append(dict_data['results']['name']+dict_data['results']['alias'])
theme.append(str(dict_data['results']['categories']).replace('[','').replace(']','').replace("'",''))
score.append(dict_data['results']['score'])
for y in range(i*10+1,i*10+11):
the_url = "https://spa6.scrape.center/api/movie/" + token2() + '/?token=' + decode2(token2())
response = requests.get(the_url, headers=headers, verify=False)
dict_data_1 = json.loads(response.text)
content.append(dict_data_1['drama'])
bt = {
'标题':title,
'主题':theme,
'评分':score,
'剧情介绍':content
}
work = pd.DataFrame(bt)
work.to_csv('work.csv')
``` 可以可以,我要学习一下,多谢分享 我要是也会就好了 虽然顶着混淆也可以搞
不过反混淆一下看起来能省力很多,不然跳来跳去一会儿就容易忘了 借鉴学习,谢谢分享
页:
[1]