批量爬取wallhaven壁纸
# 批量爬取wallhaven壁纸1、导入需要用到的模块
```python
import requests
from bs4 import BeautifulSoup
```
2、获取网页内容
```python
link = 'https://wallhaven.cc/toplist'
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
res=requests.get(url=link,headers=headers).text
print(res)
```
大概是这样的
3、使用浏览器元素抓取 获得图片元素所在位置

4、解析数据,获取图片链接;从上图可知class id=preview
```python
# 解析数据
soup = BeautifulSoup(res,'html.parser')
items=soup.find(class_='preview')['href']
print(items)
```
控制台打印
结果如下:
```powershell
C:\Users\w\AppData\Local\Programs\Python\Python37\python.exe D:\PY\catchVideos\test.py
https://wallhaven.cc/w/zygeko
```
5、拿到的地址为图片预览页面,还需要再次解析才能获得图片的真实路径;同上
```python
resUel=requests.get(url=items,headers=headers).text
soup1 = BeautifulSoup(resUel, 'html.parser').find('img', id='wallpaper')['src']
print(soup1)
```
得到最终图片链接,点击可以打开图片
**(https://w.wallhaven.cc/full/zy/wallhaven-zygeko.jpg)**
6、获取图片的二进制内容并保存到本地,根据链接可知为jpg格式的图片
```python
ts_content = requests.get(url=soup1, headers=headers).content
# 保存图片
soup1_content = requests.get(url=soup1, headers=headers).content
with open('e:\\' + soup1[-20:-4] + '.jpg', mode='ab') as f:
f.write(soup1_content)
```

> 这样只是获取了一张图片,下面改成批量获取,改造步骤4
```python
# 解析数据
soup = BeautifulSoup(res.text,'html.parser')
items=soup.find_all(class_='preview')
for item in items:
link=item['href']
resUel=requests.get(url=link,headers=headers).text
soup1 = BeautifulSoup(resUel, 'html.parser').find('img', id='wallpaper')['src']
soup1_content = requests.get(url=soup1, headers=headers).content
with open('e:\\img\\' + soup1[-20:-4] + '.jpg', mode='ab') as f:
f.write(soup1_content)
```
>这里使用find_all获取所有符合条件的元素,得到一个包含很多链接的数组;循环步骤5、6,即可实现批量保存
>上面只会获取一页的图片,下面再次改造,把这些方法定义为函数,页数和链接作为参数,批量爬取多页的图片;
```python
import requests
from bs4 import BeautifulSoup
# 循环爬取壁纸网站图片
def catchImg(url,page):
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
res=requests.get(url=url+'?page='+page,headers=headers)
# 解析数据
soup = BeautifulSoup(res.text,'html.parser')
items=soup.find_all(class_='preview')
for item in items:
link=item['href']
resUel=requests.get(url=link,headers=headers).text
soup1 = BeautifulSoup(resUel, 'html.parser').find('img', id='wallpaper')['src']
soup1_content = requests.get(url=soup1, headers=headers).content
with open('e:\\img\\' + soup1[-20:-4] + '.jpg', mode='ab') as f:
f.write(soup1_content)
print(soup1)
for i in range(10):
page=2
link = 'https://wallhaven.cc/toplist'
catchImg(link, str(page))
page += 1
```
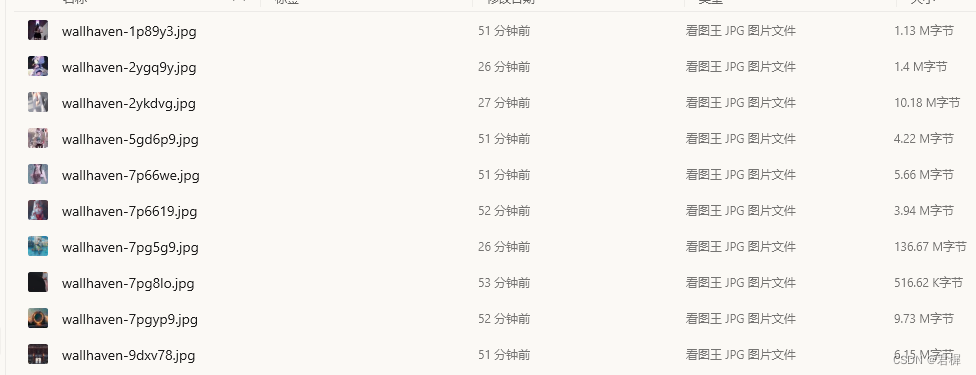
>这里我们看一下图片的大小,不是缩略图
>这个网站比较简单一些,不过壁纸是真的nice! 巧了,上个星期我也写了个,专门针对收藏夹的,图片太大了,爬起来很慢我这宽带下行最高才10兆https://s1.ax1x.com/2022/11/15/zEeEZV.png
https://s1.ax1x.com/2022/11/15/zEZYgs.png YSJohnson 发表于 2022-11-14 08:53
只获取了24张就没了怎么办
把for i in range的范围改成了30后,链接有获取新的和重复的,但 ...
应该是有限制,topList应该只能抓到48张,换个链接试试,https://wallhaven.cc/hot
我原来手动把这个网站4k以上的壁纸扒完了,其它有几个网站也扒完了, 不错,我也去试试 多谢分享,我去试试! 多谢分享,正需要:lol 多谢分享,我去试试! 看了看 学了学 没学会 {:301_999:} 好东西,看会了,一学就废{:1_925:} 可以跟着搞一搞 正好需要壁纸,试试