现代 64 位操作系统开发(一):CMake 构建、UEFI 启动、frame buffer 文字绘制
本帖最后由 arttnba3 于 2024-9-30 23:41 编辑# 0x00.一切开始之前
很久以前在知乎上曾经有过一个“程序员的三大浪漫”的讲法:「编译原理」、「操作系统」、「图形学」——当然这个似乎是某些知名答主杜撰的并没有任何的由头神必说法,笔者自己也不认为所谓的“程序员的浪漫”就仅是这几个东西,但对于笔者而言,“自己动手编写一个可以正常运行的操作系统”确乎是一件**非常炫酷的事情**
笔者本科期间曾经跟着别人的书籍或是课程写过几个小的 32 位操作系统内核,大四那会又自己用 C 语言琢磨着搓了一个 64 位内核,但是最后的成品似乎都只是一个小玩具,只能在 QEMU 里看着黑框框跳动
因此趁着现在笔者的心尚未老去,笔者想要**真正地从零写一个可以在物理机上运行的 64 位操作系统内核**,算是满足自己多年来的一个梦想吧,名字的话笔者决定叫 `ClosureOS` ——这个名字的由来比较简单,笔者一直很难想出比较好听的名字,看了看市面上有各种操作系统都叫 `Open*` ,那笔者就叫 `Close` 好了,但是 `Close` 这个单词长得又不好看,于是笔者最终选择了 `Closure` 作为这个操作系统的名字——虽然似乎不是特别好听,但反正是否能写完都还是个未知数,所以也无所谓了(笑)
本项目代码开源在 (https://github.com/arttnba3/ClosureOS),因为这个系统完全从零开始设计,同时现实生活还有各种事情,所以 **更新速度可能会非常非常非常非常非常非常非常慢** ......
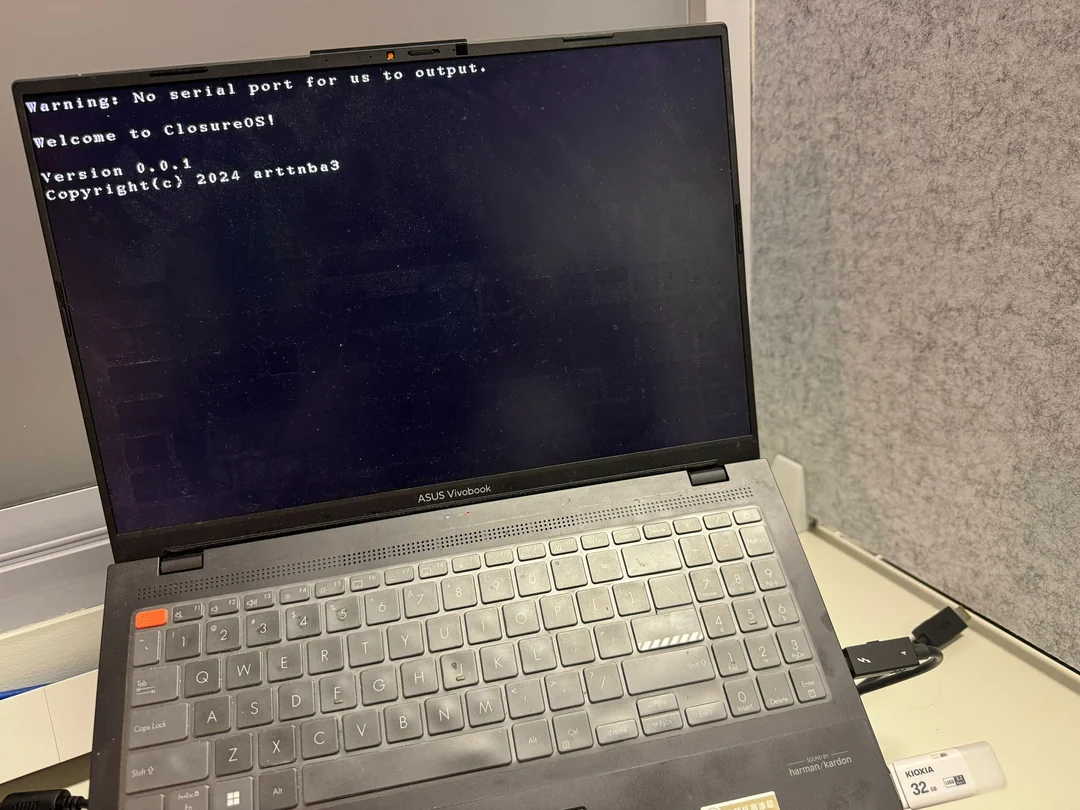
> 本章对应分支为 `chapter-01` ,本章代码在物理硬件上运行的效果如下图所示:
>
> 
# 0x01. Boot Firmware
现代计算机的上电过程比较复杂,不过对于操作系统开发而言我们其实只需要关注**当我们按下开机键之后所发生的事情**,实际上无论是古老的 Legacy BIOS 启动还是逐渐成为主流的 UEFI 启动而言,其不外乎都遵循以下三个大阶段:
- **ROM Stage**:经历了一些基本的初始化工作后 CPU 被重置,主核心被唤醒,指令指针寄存器指向 `reset vector`(固件入口点)并由此开始执行,此时尚未进行内存探测,需要直接在 ROM 上执行
- **RAM Stage**:内存探测完成,此时可以进行主板上各芯片组、CPU 等模块的初始化等工作
- **Boot Stage**:找到启动设备,完成启动设备前的依赖项的准备,将控制权移交给设备上的下一阶段的启动器
现有的固件通常分为两类:BIOS 与 UEFI
## Legacy BIOS
**基本输入输出系统**(**Basic Input/Output System**,BIOS)是用来为计算机提供初始化服务与运行时服务的一组固件,其被预装在主板的 ROM/FLASH 芯片上,不同的 BIOS 通常仅能在特定的主板型号上运行
当计算机启动后 BIOS 为第一个被运行的软件,此时计算机处于实模式下,仅能访问 1MB 内存的空间,其中物理内存 `0xF0000 ~ 0xFFFFF` 这 64KB 空间被映射到 BIOS ROM 当中,并以 `0xFFFF0` 处作为 BIOS 程序的入口点开始执行
> 对于支持且开启了 BIOS shadowing 特性的计算机而言,BIOS 会被先从固件当中拷贝到内存中,而非直接在 ROM 空间上执行
BIOS 会从南桥的 CMOS 芯片中读取 BIOS 程序的设置值、硬件参数侦测值等信息,在完成加电自检、设备测试等工作之后,会从启动设备中读取第一个扇区到物理内存 `0x7c00` 的位置,该扇区被称为**主引导记录**(**Master Boot Recode**,MBR),随后 BIOS 会跳转到 `0x7c00` 处继续执行,控制权转交给 MBR
MBR 的结构如下图所示,其中**不仅包含有 440 字节的第一阶段引导代码,同时还包含有磁盘的分区表信息**,MBR 以末尾的两个字符 `0x55, 0xaa` 作为其标识:
> 这里我们可以看到 MBR 分区表仅支持不超过四个主分区,多余的分区则需要依赖操作系统在其上建立虚拟分区,此外 MBR 也不支持管理硬盘 2TB 以外的存储空间,因此这种分区方式 _其实已经正在逐渐地被淘汰_
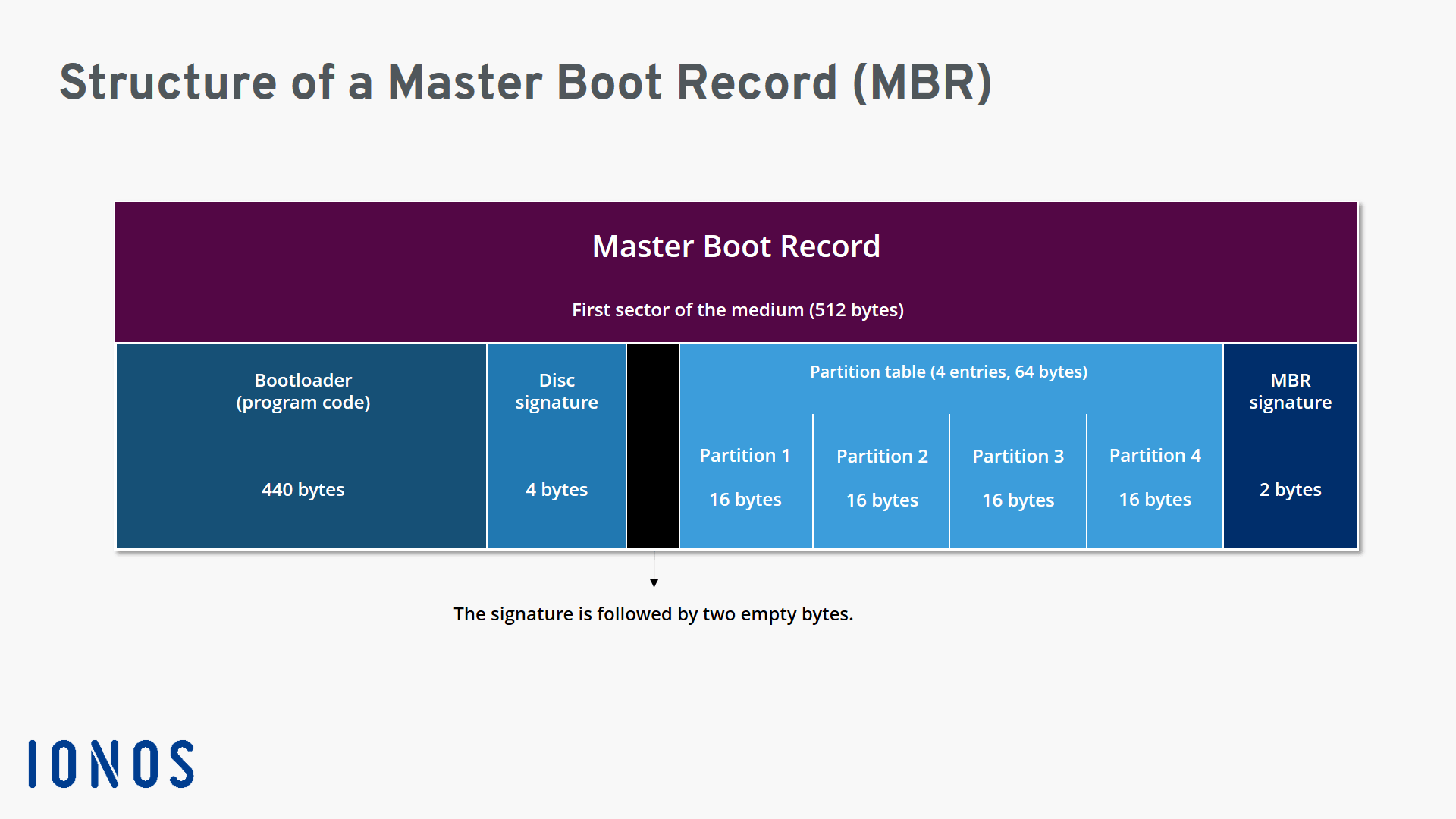
由于 MBR 仅有 512 字节,无法完成过多的任务,因此通常的设计是由 MBR 从硬盘上读取第二阶段的 boot loader,由其来完成后续的系统环境初始化、载入操作系统内核等工作
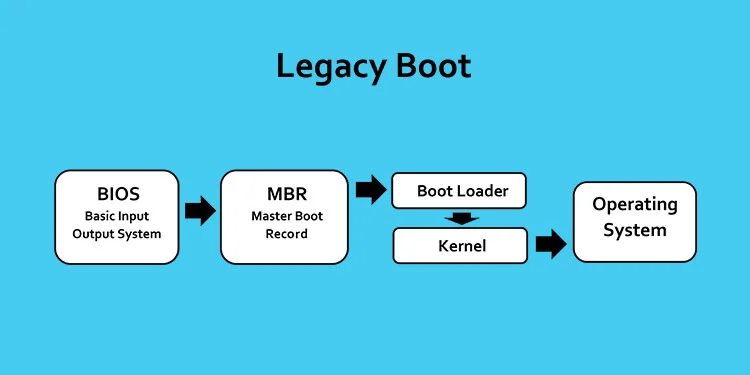
## Unified Extensible Firmware Interface
**统一可扩展固件接口**(**Unified Extensible Firmware Interface**,UEFI)为一套**固件接口规范,用以初始化硬件、引导操作系统,并向操作系统提供一套统一的功能接口,解决不同厂牌 BIOS 分裂的现状**,其最初起源于 Intel 开发的 EFI,在 2005 年由 Intel 交由 UEFI 论坛进行推广,**UEFI 固件本质上与 BIOS 固件没有区别**(都是封装在 ROM/FLASH 固件里的程序)
> 例如 BIOS 厂商 A 提供的某个功能接口的使用方式是 X,BIOS 厂商 B 提供的相似功能接口使用方式是 Y,那操作系统就得为不同厂商的不同功能编写多套代码
>
> 而有了 UEFI 规范,厂商 A、B 的 UEFI 固件都需要向上层提供统一的接口,从而使得操作系统可以用相同的方式调用某个功能,避免了代码分裂的情况
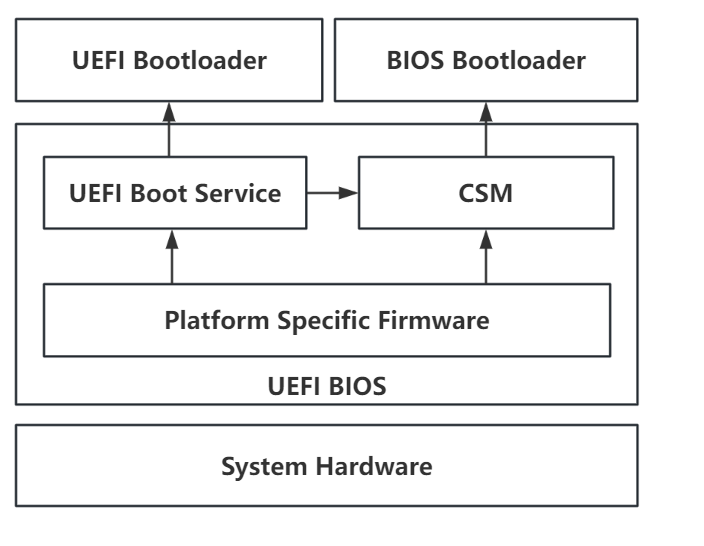
这里引用一张非常经典的图片简述 UEFI 启动的基本过程:
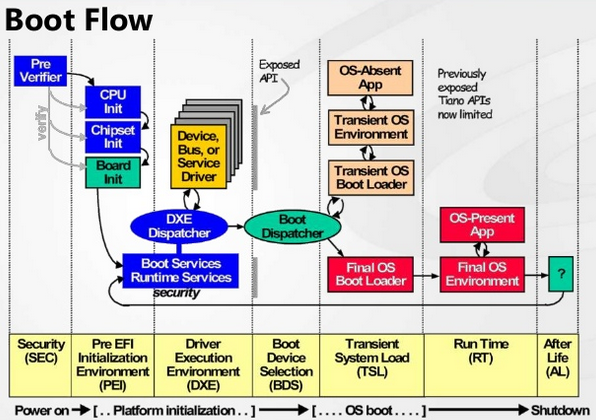
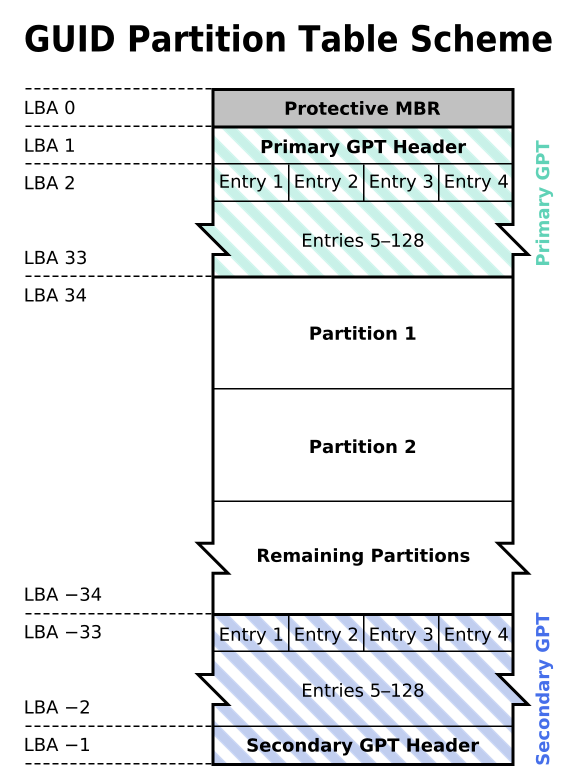
相应地,UEFI 启动不再使用老旧的 MBR 分区表,而是使用 **GUID Partion Table** (GPT 分区表),以 512 字节为单位作为一个**逻辑块**(Logic Block,相对应的区块地址便称为 LBA),前 34 个 LBA 用来记录分区信息,其中 LBA0 为了兼容性保留给 MBR 使用,LBA1 记录分区表自身的信息、备份用 GPT 分区(最后 34 个 LBA 的位置)、分区的 CRC 校验码等,LBA2 ~ LBA 33 则用来记录分区信息,每个 LBA 可以记录四个条目:
> #### 扩展阅读:兼容支持模块(Compatibility Support Module)
>
> 在 UEFI 逐渐替换掉计算机底层固件的风潮涌动之时,尚有大量的设备仍旧使用传统的 MBR 分区表,为了进行兼容,CSM 这一兼容支持模块会模拟传统 BIOS 的功能,为这些设备系统按照传统的 BIOS + MBR 方式进行引导,并提供传统 BIOS 的 0x10 等中断服务
>
> 
## _Coreboot_
**Coreboot** 起源于 **LinuxBIOS**,最初的思路是 _既然 Linux 有比较好的硬件支持,那计算机启动以后直接跳 Linux就完事了_, 于是 _使用 20 行汇编完成初始化并将 Flash 中的 Linux 拷贝至内存后直接跳过去_ 的 LinuxBIOS 诞生于 1999年,随后经过不断发展,引导 Linux 所用的程序越来越大,于是项目在 2008 年改名为 coreboot,项目结构变为 `coreboot + payload`,Linux 则成为了 _可选的一段 payload_ ,通过这样的模式,Coreboot 可以通过引入不同的 payload 来支持多种不同的启动规范,包括 Legacy BIOS 和 UEFI

> 目前市面上正在使用 Coreboot 的主流产品有 Google Chromebook 和 System76 旗下的笔记本等
# 0x02. 多重引导规范 & GNU GRUB
## Why GRUB?
现今的大部分所谓“教你自行编写操作系统”的无论是教程也好书籍也好,都存在着一个小小的问题:**对 Legacy BIOS 的内核引导阶段大书特书**——诚然,了解一台计算机从启动开始到内核真正运作这段期间的实现细节无疑是十分重要的一件事情,对于操作系统学习而言或许也有不小的帮助,但很容易让初学者陷入到与各种硬件博弈的苦战当中,同时对于实际的开发而言手动编写一个**仅适用于我们自己的内核**的客制化 `MBR + boot loader` 意义并不算特别大,且 MBR 启动已经逐渐开始过时了
而 UEFI 规范虽然给了我们更为方便地通过 UEFI 的各种接口实现不同的功能,但**UEFI 的大部分功能在 Runtime 阶段是不可用的**,同时这也少不了编写设备识别、文件系统解析等工作,再配上编写各种基础设施,一套写下来一个EFI 程序其实差不多就已经是一个完整的小内核了——当然, _直接用 EFI 程序作为操作系统内核不是不行,看着也确实像个样子_ ,**就是不太优雅,也不太现代**
因此,对于内核引导阶段,我们暂时选择**直接复用现有的成熟的方案**——例如「GNU GRUB」,其同时支持 Legacy BIOS 与 UEFI 引导,让我们不用在一开始就陷入到与各种存储设备斗争的泥潭当中
!(https://s2.loli.net/2022/09/07/eTCVOtlpE7PYFXq.png)
> 当然,如果说仅从「学习」的角度而言自己亲手写一个 `MBR + boot loader` / `EFI` 并亲身体会到其载入内核的整个过程其实是一件非常有益处的事情(笑)
>
> > 先挖个坑:我们将在操作系统内核开发完成之后的后续补充文章中**自行开发一个 EFI 程序以引导符合 multiboot2 规范的内核**
> 也有人会问:那为什么不用 (https://github.com/limine-bootloader/limine) 或是 (https://gitlab.com/bztsrc/bootboot) 这样更加现代的 boot loader 呢?一个原因就是因为 GRUB 相对有着更好的兼容性,能够在更多设备上运行,教程资料也比较多
## Multiboot2 规范
那么我们如何让 GNU GRUB 知道他该怎么引导一个什么样的内核呢?答案是通过[多重引导规范](https://www.gnu.org/software/grub/manual/multiboot/multiboot.html)(Multiboot Specification),该规范制定的目的是使得遵循该规范的操作系统可以被同样遵循该规范的 boot loader 引导,而无需编写特定于 OS 的 boot loader
GNU GRUB 第二版进行了完全的重写,多重引导规范也有个[第二版](https://www.gnu.org/software/grub/manual/multiboot2/multiboot.html),不过好在 GRUB2 同时支持两版引导规范——这里我们使用**第二版**的规范
> 然而 Linux kernel 使用的**并不是 multiboot规范**,而是其[自定义的协议](https://www.kernel.org/doc/Documentation/x86/boot.txt)
多重引导规范要求我们的内核映像的前 `32768` 字节中一个任意的 **64位对齐的位置** 必须要有一个 [`multiboot2 header`](https://www.gnu.org/software/grub/manual/multiboot2/multiboot.html#Header-layout) 来记录相应的信息,格式如下:
| Offset | Type | Field Name | Note |
| ------ | ---- | ------------- | -------- |
| 0 | u32| magic | required |
| 4 | u32| architecture| required |
| 8 | u32| header_length | required |
| 12 | u32| checksum | required |
| 16-XX| | tags | required |
- `magic`:multiboot2 header 的标识,必须为 `0xE85250D6`
- `architecture`:标识指令集架构,0 表示 32 位 i386 保护模式,4 表示 32 位 MIPS
- `header_length` :包含 tags 在内的整个 multiboot2 header 的大小
- `checksum`:该域与前三个域相加的和为无符号 0
- `tags`:补充域,其格式通常如下,以类似数组的形式跟在后边,**每个 tag 的起始地址8 字节对齐**,**整个 tag 数组以一个 type 为 0 及 size 为 8 的 tag 结尾**,关于不同类型的 tag 格式,参见[此处](https://www.gnu.org/software/grub/manual/multiboot2/multiboot.html#Header-tags):
```
+-------------------+
u16 | type |
u16 | flags |
u32 | size |
+-------------------+
```
## 在 U 盘上安装 GRUB2
虽然很多操作系统编写教程都是在虚拟机当中运行的,毕竟 _对于操作系统初学者而言更重要的是了解整个操作系统的运行机理_ ,但是**在物理机上运行自己写的操作系统是非常令人感到愉悦的一件事情**,所以这里我们将会介绍如何在 U 盘上安装 GRUB 来引导自己的操作系统内核
> 如果你不想弄这一部分,也可以跳转到下一节,直接开始安全地使用 QEMU,我们后面的各种开发调试其实主要也是在 QEMU 上完成的 :)
- 如果你在物理机上使用 Linux 作业系统,请找到你的 U 盘对应的设备节点,通常情况下,如果你的计算机**仅**使用 `nvme m.2` 固态硬盘,则新插入的 U 盘 _通常_ 是 `/dev/sda` ,**如果你则计算机仍在使用 SATA 接口的硬盘,请注意自行确定设备路径**
- 如果你在物理机上使用 Windows 操作系统,出于易用性考虑我们并不使用 WSL,**而是在 Vmware 虚拟机中安装一个 Linux 操作系统**,并通过如下方式将 U 盘连接到虚拟机中(请先确定好你的 U 盘对应的设备名称),在你的虚拟机处在默认配置且不存在外部存储设备的情况下,U 盘对应的设备节点通常是 `/dev/sdb`:
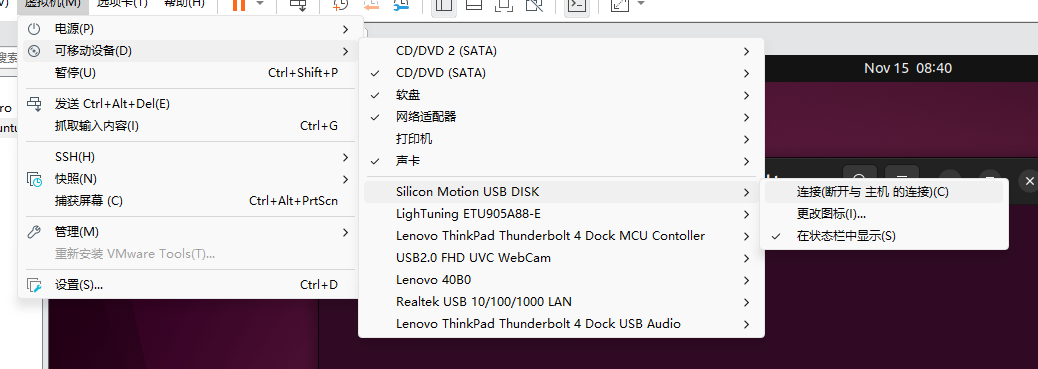
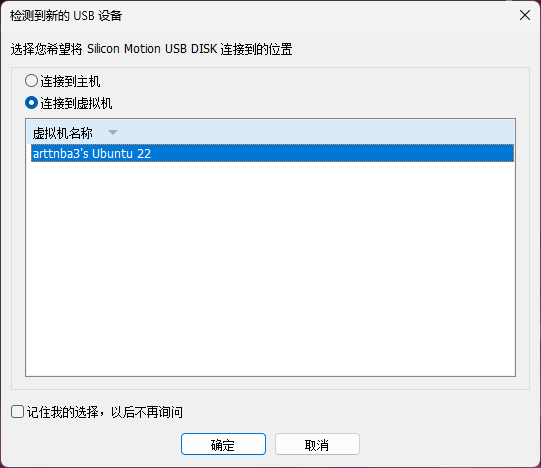
>也可以通过**物理重新拔插可移动设备**以让 Vmware 自行截获:
>
> 
>
> 如果你是其他情况,请自行进行判断 :)
首先安装一些你可能会需要的依赖:
```shell
$ sudo apt install -y dosfstools mtools gparted gcc cmake git bison libopts25 libselinux1-dev m4 help2man libopts25-dev flex libfont-freetype-perl automake make autotools-dev autopoint libfreetype6-dev texinfo python3 autogen autoconf libtool libfuse3-3 unifont gettext binutils pkg-config liblzma5 libdevmapper-dev
```
接下来我们对 U 盘进行分区,**请确保你已经将所有重要数据完成备份**,这里笔者选择使用 `GParted` 进行分区,我们首先通过 `Device→Create Partion Table...` 建立一个 GPT 分区表:
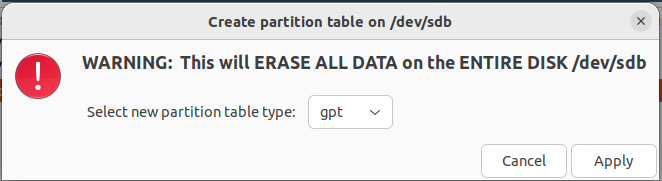
> 此时可能会提示无法重建分区表,这是因为操作系统可能偷偷帮你把分区挂载在 `/run/你的用户名` ,请使用 `umount` 卸载所有活动分区,之后重新启动 `GParted`
然后右键新建分区,这里笔者选择建立一个大小为 512MB 的 EFI 分区,注意**该分区必须为 fat32 格式**,剩余的空间作为一个文件系统分区, _我们将在后续开发文件系统时用到它_ ,划分好后点绿色的✅然后 `Apply`:
> 这里 GParted 会在 U 盘末尾留下 1MB 的空间,用来放 MBR 分区表,主要是出于兼容目的
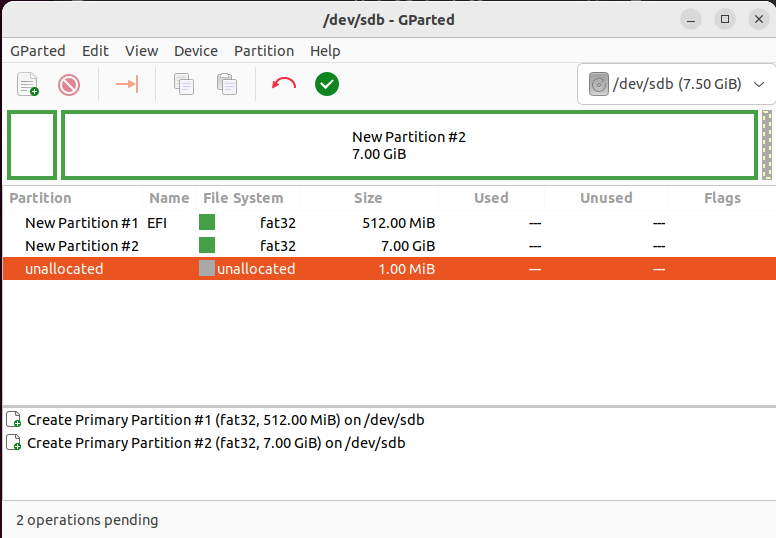
接下来我们从源码编译 GRUB,首先从 (https://ftp.gnu.org/gnu/grub/)进行下载源码,然后在单独的文件夹中进行编译,这里我们三种 GRUB 都编译上:
```shell
$ wget https://ftp.gnu.org/gnu/grub/grub-2.06.tar.xz
# 也可以从这里获取: git clone git://git.savannah.gnu.org/grub.git
$ tar -xf grub-2.06.tar.xz
$ cd grub-2.06/
$ mkdir EFI32 EFI64 BIOS
$ cd EFI64
$ ../configure --target=x86_64 --with-platform=efi && make -j$(nproc)
$ cd ../EFI32
$ ../configure --target=i386 --with-platform=efi && make -j$(nproc)
$ cd ../BIOS
$ ../configure --target=i386 --with-platform=pc --disable-nls && make -j$(nproc)
```
> 注:如果你使用的是 Arch/Fedora/openSUSE 这样更新比较快的系统,在编译的时候可能会出错(~~GCC 背大锅~~),那么这个时候可能就需要使用更新版本的源码,笔者物理机此前使用的是 Fedora Workstation 38,编译 2.06 时爆了莫名其妙的问题,所以后来笔者选择了 (https://git.savannah.gnu.org/cgit/grub.git/tag/?h=grub-2.12-rc1) 版本的 GRUB2
然后将 GRUB2 安装到 U 盘的 EFI 分区上:
```shell
$ sudo mount /dev/sdb1 /mnt # 注意替换成自己的 U 盘对应的设备节点
$ cd ../EFI64/grub-core
$ sudo ../grub-install -d $PWD --force --removable --no-floppy --target=x86_64-efi --boot-directory=/mnt/boot --efi-directory=/mnt
$ cd ../../EFI32/grub-core
$ sudo ../grub-install -d $PWD --force --removable --no-floppy --target=i386-efi --boot-directory=/mnt/boot --efi-directory=/mnt
$ cd ../../BIOS/grub-core
$ sudo ../grub-install -d $PWD --force --no-floppy --target=i386-pc --boot-directory=/mnt/boot /dev/sdb
```
> 这里直接用系统自带的 `grub-install` 也可以直接安装,但是笔者在 Fedora 系统上使用自带的 `grub2-install` 时出现了这样一个错误:
>
> ```
> grub2-install: error: this utility cannot be used for EFI platforms because it does not support UEFI Secure Boot.
> ```
>
> 网上也没有找到什么比较好的解决方案,笔者只好从源码进行编译
>
> > 但是 Ubuntu/openSUSE 自带的 `grub-install/grub2-install` 就能正常使用,怎么回事呢
接下来我们新建一个文件 `/mnt/boot/grub/grub.cfg` (假设你的 U 盘 EFI 分区和笔者一样挂载在 `/mnt` 下),其为 GRUB 的配置文件,编写内容如下:
```cfg
set timeout=10# waiting time befo automatic booting
set default=0 # default menu entry index
insmod all_video
menuentry "Boot ClosureOS v0.0.1" {
multiboot2 /boot/kernel.bin # use multiboot2 spec to boot
boot
}
if [ ${grub_platform} == "efi" ]; then
menuentry "UEFI Setting" {
fwsetup
}
fi
menuentry "System Reboot" --class=reboot {
reboot
}
menuentry "System Shutdown" --class=halt {
halt
}
```
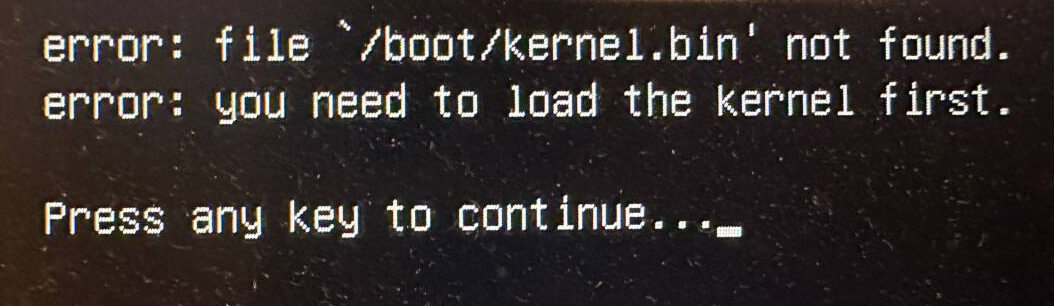
卸载 U 盘,重新启动计算机,进入你的 BIOS/UEFI 配置界面,关闭安全启动(`Secure Boot`),将 U 盘配置为第一个启动项(通常开头会有一个 `UEFI: ` 的标识),重新启动计算机,接下来——
**GNU GRUB,启动!!!**
当然,现在我们还没有开始编写操作系统内核,所以想要直接启动会报错,不过后面我们编写的内核直接放到 U 盘 EFI 分区的`boot/kernel.bin` 这个位置就可以直接启动了:
## 创建包含 GRUB2 的启动镜像文件并使用 QEMU UEFI 启动
首先安装一些可能需要的依赖:
```shell
$ sudo apt install -y qemu qemu-system-x86 ovmf xorriso
```
然后使用如下脚本在 QEMU 中从 U 盘启动 GRUB,注意替换成你自己的 U 盘设备节点路径:
```bash
#!/bin/sh
sudo qemu-system-x86_64 \
-bios /usr/share/ovmf/OVMF.fd \
-cpu kvm64,+smep,+smap \
-smp sockets=1,dies=1,cores=4,threads=2 \
-m 4G \
--machine q35 \
-drive file=/dev/sdb,format=raw,index=0,media=disk
-s
```
各参数说明如下:
- `-bios` :指定使用的启动固件,这里是 OVMF,源自于 (https://github.com/tianocore/edk2) 的 UEFI 固件
- `-cpu`:指定 CPU 类型及特性,`kvm64` 是一种常规的 CPU 类型,`+smep` 和 `+smap` 表示开启阻止内核空间执行/访问用户空间数据的保护
- `-smp`:指定 CPU 插槽数、单个插槽上 DIE 的数量、每个 DIE 的核心数、每个核心的线程数
- `-m`:内存大小
- `--machine` :机器设备类型,QEMU 支持两种设备,另外一种是比较老的 `i440fx`
- `-drive`:添加一个设备,这里添加了 `/dev/sdc` 设备
- `-s`:支持通过使用 gdb 连接 `0.0.0.0:1234` 进行调试
简单测试一下,成功进入 GRUB 界面:
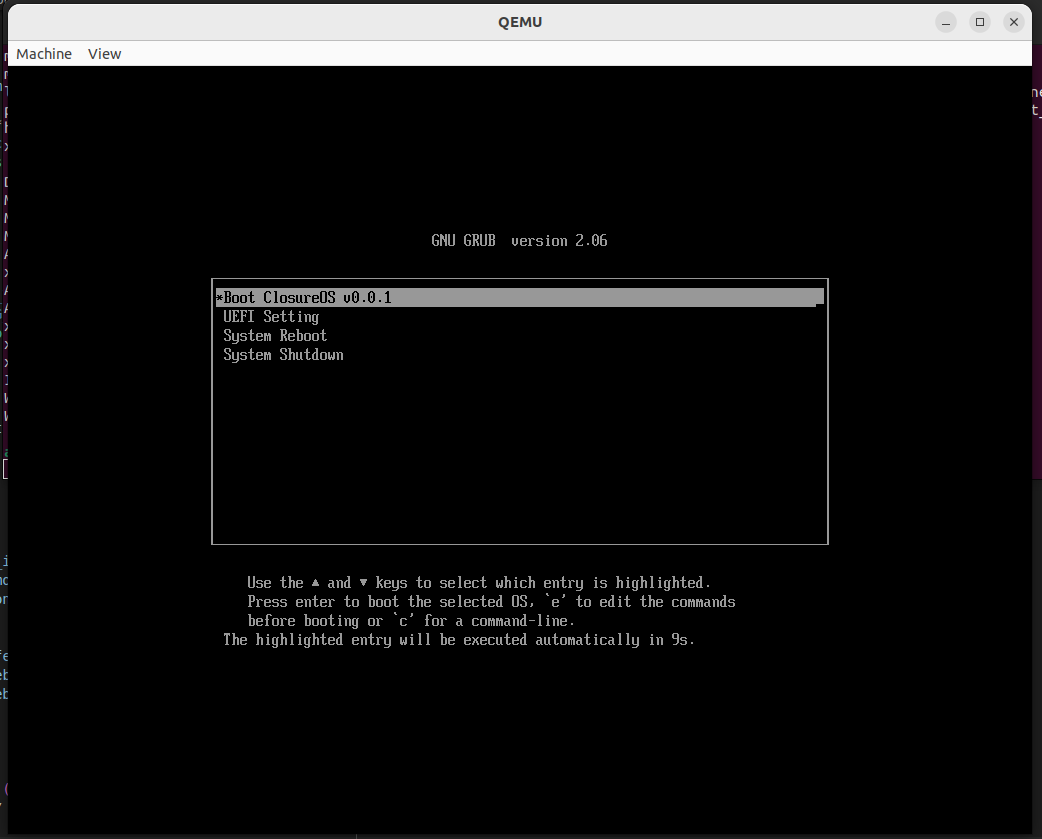
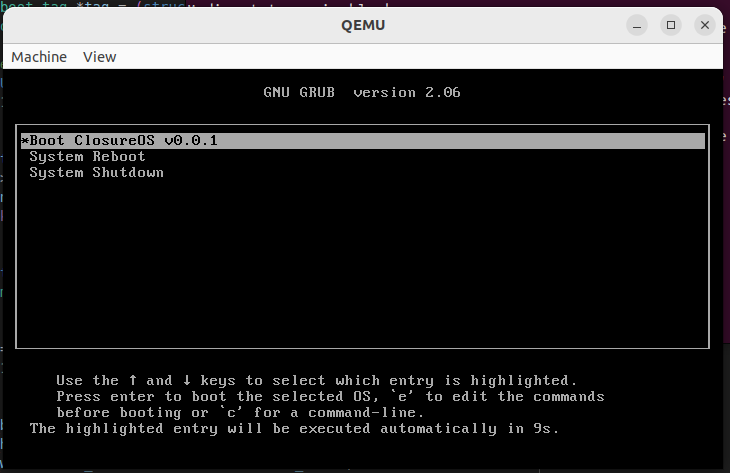
> 如果未指定 `-bios` 参数,则默认会使用 SeaBIOS 进行启动,此时便是传统的 BIOS + MBR 启动方式:
>
> 
不过可能也有同学手上暂时没有闲置的 U 盘或其他外部存储设备,此时我们也可以使用 `grub-mkrescue` 创建一个专门用来调试的镜像,首先创建如下目录结构:
```shell
$ tree target/
target/
└── x86_64
└── iso
└── boot
└── grub
└── grub.cfg
4 directories, 1 file
```
接下来使用`grub-mkrescue` 创建镜像:
> 在部分发行版上,这可能叫 `grub2-mkrescue` ,固件路径也可能不一样,请自行分辨
```shell
$ grub-mkrescue /usr/lib/grub/x86_64-efi -o kernel.iso target/x86_64/iso
```
把启动脚本中的设备节点路径改成文件路径即可成功启动:
```shell
#!/bin/sh
qemu-system-x86_64 \
-bios /usr/share/ovmf/OVMF.fd \
-cpu kvm64,+smep,+smap \
-smp sockets=1,dies=1,cores=4,threads=2 \
-m 4G \
--machine q35 \
-drive file=./kernel.iso,format=raw,index=0,media=disk
```
# 0x03. 启动一个空白内核
接下来我们终于要正式开始进行内核的编写了,过去绝大部分的操作系统内核都是用 `汇编 + C 语言` 编写的,不过最近也有使用 Rust 替换 C 语言的内核实现(例如国产操作系统 (https://dragonos.org/) ,**与绝大多数 Linux 系统调用兼容,目前已经完成了 musl-gcc 的移植** ),Rust 也在逐渐进入 Linux 内核,包括[计算机系统能力大赛](https://os.educg.net/#/) 主推的也是 Rust 内核
但是对于新手而言 Rust 终归是有些难以让人绷得住,在笔者看来**不能像 C 语言那样提供足够贴近于硬件底层的直接抽象**,同时笔者也非常喜欢 C++ 语言的各种特性,因此笔者这一次决定使用 C&C++ 进行内核主体的编写,再辅以一定的汇编代码
## 代码基本结构
最初的代码结构如下所示,包含一个空白内核:
```shell
$ tree .
.
├── LICENSE
├── README.md
├── src
│ ├── arch
│ │ ├── CMakeLists.txt
│ │ └── x86
│ │ ├── boot
│ │ │ ├── boot_font.o
│ │ │ ├── boot_main.c
│ │ │ ├── boot.S
│ │ │ ├── boot_tty.c
│ │ │ └── CMakeLists.txt
│ │ ├── CMakeLists.txt
│ │ ├── include
│ │ │ └── asm
│ │ │ ├── com.h
│ │ │ ├── cpu_types.h
│ │ │ ├── io.h
│ │ │ └── page_types.h
│ │ └── linker.lds
│ ├── CMakeLists.txt
│ ├── include
│ │ ├── boot
│ │ │ └── multiboot2.h
│ │ ├── closureos
│ │ │ └── types.h
│ │ └── graphics
│ │ └── tty
│ │ ├── default.h
│ │ └── font
│ │ └── psf.h
│ └── kernel
│ ├── CMakeLists.txt
│ └── main.c
├── targets
│ └── x86_64
│ └── iso
│ └── boot
│ └── grub
│ └── grub.cfg
└── tools
└── scripts
├── boot.sh
└── repack_iso.sh
21 directories, 24 files
```
我们使用 `CMake` 来进行项目管理,相比起传统的 `Makefile` ,这是一种更加方便、更加自动化、更加规范的现代编译工具
> 什么,你不知道如何编写 CMake?还不[赶快学!](https://cmake.org/cmake/help/latest/index.html)
根目录的 `CMakeLists.txt` 编写如下,主要作用就是准备统一的编译参数、进入不同文件夹进行 make、链接所有的目标文件,这里我们去掉了标准库支持、去掉了调试段、指定了静态编译......因为在裸金属环境下能依赖的只有我们自己:)
```cmake
cmake_minimum_required(VERSION 3.16)
project(ClosureOS)
# for debugging only
#set(CMAKE_VERBOSE_MAKEFILE ON)
# languages we will use
enable_language(C)
enable_language(ASM)
# check for current compiler environment, temporarily support linux only
if (NOT CMAKE_HOST_SYSTEM_NAME STREQUAL "Linux")
message(FATAL_ERROR "Unsatisfied compilation environment, only support Linux now")
endif()
# global link script
if (CMAKE_HOST_SYSTEM_PROCESSOR STREQUAL "x86_64")
set(CMAKE_EXE_LINKER_FLAGS "${CMAKE_EXE_LINKER_FLAGS} -T ${CMAKE_SOURCE_DIR}/arch/x86/linker.lds")
else()
message(FATAL_ERROR "Only support x86_64 now")
endif()
# compile and link as bare bone project
add_compile_options(-pipe -ffreestanding -nostdlib -fno-pie -fno-stack-protector -mcmodel=large -fno-asynchronous-unwind-tables)
set(CMAKE_EXE_LINKER_FLAGS "${CMAKE_EXE_LINKER_FLAGS} -nostdlib -z max-page-size=0x1000 -Wl,--build-id=none -static")
# general include dirs
include_directories(${PROJECT_SOURCE_DIR}/include)
# seperate module
add_subdirectory(arch)
add_subdirectory(kernel)
# we create an empty file for add_executable(), as it must need at least one file to work
file(WRITE "${CMAKE_CURRENT_BINARY_DIR}/internal_empty_file_for_occupation_only.cpp" "")
add_executable(kernel.bin "${CMAKE_CURRENT_BINARY_DIR}/internal_empty_file_for_occupation_only.cpp")
# final output
target_link_libraries(kernel.bin
PRIVATE
Arch
Kernel
)
```
`include` 目录下是用于各个子系统的各种头文件,与 multiboot2 规范相关的一些定义放在 `include/boot/multiboot2.h` 中,该头文件来自于(https://www.gnu.org/software/grub/manual/multiboot2/html_node/multiboot2_002eh.html),比较长,这里就不贴出来了
内核主体放在 `kernel` 目录下,其中 `kernel/CMakeLists.txt` 编写如下,目前暂时就只是添加当前文件夹下文件链接为 `Kernel` :
```cmake
set(TARGET_NAME Kernel)
set(SOURCE_FILE)
file(GLOB SOURCE_FILE "${CMAKE_CURRENT_SOURCE_DIR}/*.cpp"
"${CMAKE_CURRENT_SOURCE_DIR}/*.c")
if(SOURCE_FILE)
add_library(${TARGET_NAME} "")
target_sources(${TARGET_NAME} PUBLIC ${SOURCE_FILE})
else()
add_library(${TARGET_NAME} INTERFACE)
endif()
```
`kernel/main.c` 暂时就先放一个空的函数, _本篇博客暂时还用不到这块_ :
```c
void main(void)
{
// do nothing
}
```
`arch` 目录下是与架构相关的代码,目前暂时还是只支持 x86,不过后续如果有机会的话笔者希望能够让他在更多架构上跑起来,所以这里设计了一个通用的 `CMakeLists.txt`:
```cmake
set(TARGET_NAME Arch)
add_library(${TARGET_NAME} INTERFACE)
# check for current architecture
if (CMAKE_HOST_SYSTEM_PROCESSOR STREQUAL "x86_64")
add_subdirectory(x86)
target_link_libraries(${TARGET_NAME}
INTERFACE
X86)
else()
message(FATAL_ERROR "Only support x86_64 now")
endif()
```
`arch/x86/CMakeLists.txt` 主要就是编译汇编和 C 文件以及启动阶段临时用的字体文件放到 `out/arch` 目录下,这里我们将启动阶段所需的代码都放在 `arch/x86/boot` 目录下:
```cmake
set(TARGET_NAME X86)
set(SOURCE_FILE)
include_directories(include)
add_subdirectory(boot)
file(GLOB SOURCE_FILE "${CMAKE_CURRENT_SOURCE_DIR}/*.cpp"
"${CMAKE_CURRENT_SOURCE_DIR}/*.c")
if(SOURCE_FILE)
add_library(${TARGET_NAME} "")
target_sources(${TARGET_NAME} PUBLIC ${SOURCE_FILE})
target_link_libraries(${TARGET_NAME} PUBLIC Boot)
else()
add_library(${TARGET_NAME} INTERFACE)
target_link_libraries(${TARGET_NAME} INTERFACE Boot)
endif()
```
`arch/x86/boot/CMakeLists.txt` 则就只是简单地编译当前目录的代码:
```cmake
set(TARGET_NAME Boot)
set(SOURCE_FILE)
file(GLOB SOURCE_FILE "${CMAKE_CURRENT_SOURCE_DIR}/*.S"
"${CMAKE_CURRENT_SOURCE_DIR}/*.c"
"${CMAKE_CURRENT_SOURCE_DIR}/boot_font.o")
if(SOURCE_FILE)
add_library(${TARGET_NAME} ${SOURCE_FILE})
else()
message(FATAL_ERROR "no source files provided for boot")
endif()
```
## linker.lds:链接脚本
> 什么,你不知道什么事链接脚本?还不[赶快学](https://ftp.gnu.org/old-gnu/Manuals/ld-2.9.1/html_chapter/ld_3.html)!
链接脚本用来指示我们的内核可执行文件各个段的布局,例如不同的段的加载地址,在操作系统开发中有个不成文的约定就是将内核加载到物理内存 1M 起始,因此我们需要在链接脚本中将我们的引导部分放到这个位置,同时作为一个不成文的规范,**内核应当被装载到高地址处**,那么我们的内核应当分为如下两大部分:
- boot:由 GRUB 引导,负责进行页表重映射、内存管理初始化等预备工作,完成后跳转至内核
- kernel:实际的内核主体,位于虚拟地址的高地址处
笔者选择将 boot 阶段的所有代码全都放在开头为 `.boot` 的段当中,将 kernel 的 `.text` 等段重新从高地址处计算起始地址,因此链接脚本如下:
```ld
OUTPUT_FORMAT("elf64-x86-64")
OUTPUT_ARCH(i386:x86-64)
ENTRY(_start)
SECTIONS
{
/* boot loader will load the kernel there */
. = 1M;
__boot_start = .;
/* ASM boot-state kernel */
.boot.loader :
{
KEEP(*(.boot.header))
*(.boot.*)
arch/x86/boot/libBoot.a
}
. = ALIGN(4096);
/* C boot-state kernel */
.boot.text ALIGN(4096) :
{
arch/x86/boot/libBoot.a(.text)
}
. = ALIGN(4096);
.boot.rodata ALIGN(4096) :
{
arch/x86/boot/libBoot.a(.rodata)
}
. = ALIGN(4096);
.boot.data ALIGN(4096) :
{
arch/x86/boot/libBoot.a(.data)
arch/x86/boot/libBoot.a(.*)
}
. = ALIGN(4096);
__boot_end = .;
/* now we come to the REAL kernel */
KERM_VADDR = 0xffffffff81000000;
. = KERM_VADDR;
/* we use AT() there to make it loaded on phys correctly */
.text ALIGN(4096) : AT (ADDR (.text) - KERM_VADDR + __boot_end)
{
*(.text)
}
. = ALIGN(4096);
.rodata ALIGN(4096) : AT (ADDR (.rodata) - KERM_VADDR + __boot_end)
{
*(.rodata)
}
. = ALIGN(4096);
__roseg_end = .;
.data ALIGN(4096) : AT (ADDR (.data) - KERM_VADDR + __boot_end)
{
*(.data)
}
. = ALIGN(4096);
.bss ALIGN(4096) : AT (ADDR (.bss) - KERM_VADDR + __boot_end)
{
*(COMMON)
*(.bss)
}
. = ALIGN(4096);
__kernel_end = .;
}
```
## boot.S:BIOS & UEFI 兼容 32 位汇编入口,跳转进入 64 位 C 语言
`arch/x86/boot.S` 中则是我们实际的内核入口点,因为对于实现 multiboot 规范的内核而言 **没必要在汇编下进行绝大部分系统功能的实现** ,所以这个文件的核心功能就 **仅是完成部分必须的准备工作并快速进入 C 语言部分**
我们的 multiboot2 header 也可以放在这个地方,这里除了最基本的结构以外笔者还引入了一个指示入口点的 tag,以及一个指示让 GRUB 帮我们设置好指定大小的 frame buffer 的 tag,GRUB2 会根据这个 tag 自动帮我们设置显示模式:
```assembly
#define ASM_FILE 1
#include <boot/multiboot2.h>
#include <asm/cpu_types.h>
#include <asm/page_types.h>
#define GRUB_MULTIBOOT_ARCHITECTURE_I386 (0)
#define MULTIBOOT2_HEADER_LEN (multiboot_header_end - multiboot_header)
#define MULTIBOOT2_HEADER_CHECKSUM \
-(MULTIBOOT2_HEADER_MAGIC \
+ GRUB_MULTIBOOT_ARCHITECTURE_I386 \
+ MULTIBOOT2_HEADER_LEN)
.section .boot.loader.header
.align 8
multiboot_header:
.long MULTIBOOT2_HEADER_MAGIC
.long GRUB_MULTIBOOT_ARCHITECTURE_I386
.long MULTIBOOT2_HEADER_LEN
.long MULTIBOOT2_HEADER_CHECKSUM
tag_entry:
.align 8
.short MULTIBOOT_HEADER_TAG_ENTRY_ADDRESS
.short 0
.long 12
.long _start
tag_frame_buffer:
.align 8
.short MULTIBOOT_HEADER_TAG_FRAMEBUFFER
.short 0
.long 20
.long 1024
.long 768
.long 32
tags_end:
.align 8
.shortMULTIBOOT_HEADER_TAG_END
.short0
.long 8
multiboot_header_end:
```
ELF 文件默认的入口点是 `_start` 函数,因此我们在这里声明一个 `_start` 函数并导出该符号,从而使得 GRUB 在完成内核的装载之后会从此处开始执行,不过我们也可以通过在 header 中添加一个 `entry address tag` 来为 GRUB 指定我们的内核入口点:
不过在正式开始之前,我们首先看看当前的机器状态,这里笔者打算**同时兼容 Legacy BIOS 启动与 UEFI 启动**,因此这两种机器状态我们都得看看如何处理
### ① Legacy BIOS 启动
当我们使用 Legay BIOS 启动遵循 Multiboot2 规范的 32 位内核时,在进入内核时机器应当有如下[状态](https://www.gnu.org/software/grub/manual/multiboot2/multiboot.html#Machine-state):
- `eax`:必定为 Magic Number `0x36d76289`,该值的存在表明其为符合 multiboot2 标准的引导程序加载的
- `ebx`:必定为引导加载程序提供的 Multiboot2 信息结构的 32 位物理地址(参见[这里](https://www.gnu.org/software/grub/manual/multiboot2/multiboot.html#Boot-information-format))
- `cs`:权限为 `读|执行`,偏移为 `0`,界限为 `0xFFFFFFFF`
- `ds、es、fs、gs、ss`:权限为 `读|写`,偏移为 `0`,界限为 `0xFFFFFFFF`
- `A20 gate`:已开启
- `cr0`:分页(PG)关闭,保护模式(PE)开启
- `eflags`:VM、IF 两个位清空
剩下的工作都需要我们的内核自行完成,包括段描述符表的设置、堆栈、中断描述符表的设置等
### ② UEFI 启动
当我们使用 UEFI 启动遵循 Multiboot2 规范的 32 位内核时,在进入内核时机器应当有如下[状态](https://www.gnu.org/software/grub/manual/multiboot2/multiboot.html#Machine-state):
- `eax`:必定为 Magic Number `0x36d76289`,该值的存在表明其为符合 multiboot2 标准的引导程序加载的
- `ebx`:必定为引导加载程序提供的 Multiboot2 信息结构的 32 位物理地址
根据 (https://uefi.org/sites/default/files/resources/UEFI%20Spec%202_6.pdf) 第 2.3.2 节,此时机器有如下状态:
- 单处理器模式(Uniprocessor,仅有一个核心被唤醒,参见 (https://www.intel.com/content/www/us/en/developer/articles/technical/intel-sdm.html) 卷 3)
- 处在保护模式下
- **可能**开启了分页,若是,则 UEFI 内存映射定义的任何内存空间都是恒等映射的(虚拟地址等于物理地址),对其他区域的映射是未定义的,可能因实现而异
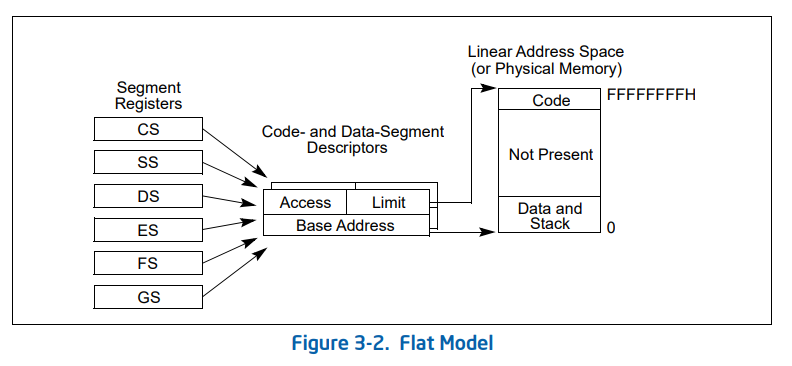
- 选择子(selector)设为“平坦模式”(flat model)或未使用
- 中断开启,不过仅支持 UEFI 引导服务计时器(所有加载的设备驱动都通过“轮询”进行同步服务)
- EFLAGS 中的方向标志位被清除
- 其他通用标志寄存器未定义
- 128 KB 或更多的可用栈空间
- 栈为 16 字节对齐,可能在页表中被标记为不可执行
- `floating-point control word` 被初始化为 `0x027F`(all exceptions masked, double-extended-precision, round-to-nearest)
- `Multimedia-extensions control word` 被初始化为 `0x1F80` (all exceptions masked, roundto-nearest, flush to zero for masked underflow)
- `CR0.EM == 0`
- `CR0.TS == 0`
> 选择子的平坦模式示意如下:
>
> 
### ③ 初始化栈与临时页表
我们不难看出 BIOS 启动与 UEFI 启动后的机器状态在 32 位下差别并不大,大家都在保护模式下,只是 UEFI 启动**可能**会额外多一个栈和页表的配置,不过我们完全可以 _抛弃 UEFI 帮我们预设好的页表与栈,自己从头开始初始化一个_
首先是页表的初始化,由于现在尚未完成内存管理器的构建,因此笔者选择仅构建一个临时的页表,待到进入 64 位长模式完成内存探测与内存分配器的建立之后再重新建立一个正式的新页表,64 位模式下所用的通常是四级页表,虚拟地址有效长度为 48 位,在控制寄存器组(control registers)中的 CR3 寄存器中存放顶层页表的地址:
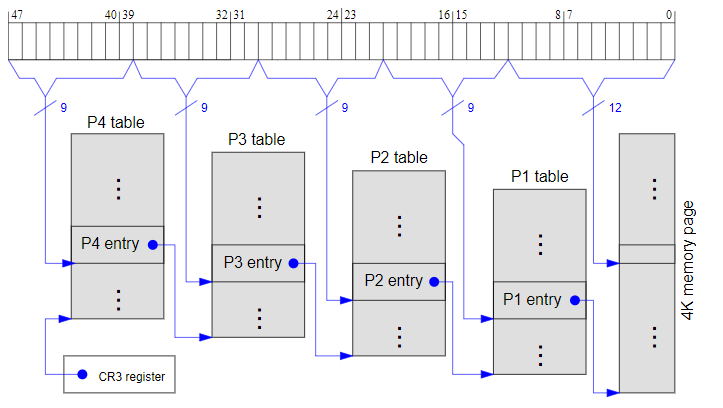
> 页表所使用的模式由 CR4 寄存器决定,具体可以参见 Intel SDM 的 3102 页 4.1.1 Four Paging Modes
不过启动阶段若是我们的临时页表也采用 4 级页表的结构的话,或许会需要占用过多的内存空间来保证对所有内存的映射,因为这个页表只是在内存管理器建立起来之前临时一用,因此这里我们使用 **1GB 的大页**,这样只需要两张页面组成的二级页表便能撑起我们初期所需的所有的内存空间,**待到完成最基本的内存管理器的初始化之后再重新进行页表的动态初始化**
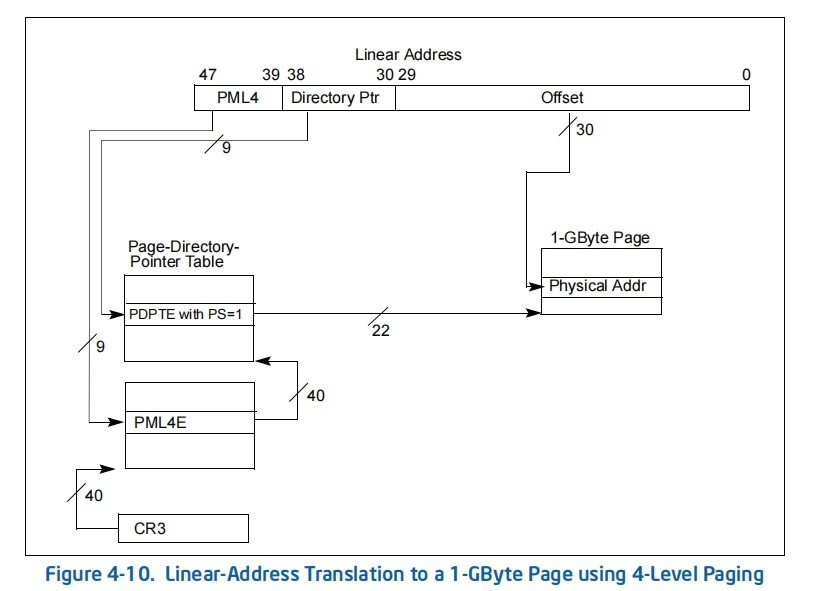
1 GB 大页的开启需要我们进入 64 位,并在页表项中设置 `PS` 位,此外,进入 64 位模式要求我们启用**物理地址扩展**(Physical Address Extension),这项特性将页表项从 4 字节扩展为 8 字节,我们需要在进入 64 位之前通过设置 CR4 寄存器的 PAE 位来启用该特性,并在提前在预先准备好的二级页表中设置 `PS` 位
```assembly
.section .boot.loader.text32:
.code32
.align 0x1000
.extern boot_main
.globl _start
_start:
# turn off the interrupt temporarily,
# and we should turn it on after our own IDT has been built.
cli
# check for multiboot2 header
cmp $MULTIBOOT2_BOOTLOADER_MAGIC, %eax
jne .loop
# temporary stack
mov $boot_stack_top, %esp
# set the boot information as parameters for boot_main()
mov %eax, %edi
mov %ebx, %esi
# clear eflags
pushl $0
popf
# disable paging (UEFI may turn it on)
mov %cr0, %eax
mov $CR0_PG, %ebx
not %ebx
and %ebx, %eax
mov %eax, %cr0
# set up page table for booting stage
# it's okay to write only 32bit here :)
mov $boot_pud, %eax
or $(PAGE_ATTR_P | PAGE_ATTR_RW), %eax
mov %eax, boot_pgd
xor %eax, %eax
or $(PAGE_ATTR_P | PAGE_ATTR_RW | PAGE_ATTR_PS), %eax
movl %eax, boot_pud
xor %eax, %eax
mov %eax, (boot_pgd + 4)
mov %eax, (boot_pud + 4)
# load page table
mov $boot_pgd, %eax
mov %eax, %cr3
#......
.section .boot.loader.data
.align 0x1000
.globl boot_stack, boot_stack_top
#
# When the system is booted under legacy BIOS, there's no stack
# So we reserve a page there as a temporary stack for booting
#
boot_stack:
.space 0x1000
boot_stack_top:
boot_pgd:
.space 0x1000
boot_pud:
.space 0x1000
```
### ④ 进入 64 位模式
64 位运行模式(Intel 称为 `IA-32e mode`,AMD 称为 `long mode`)是进入 64 位时代后 x64 处理器引入的**新的运行模式**,其有着两个子模式:
- 兼容模式(Compatibility mode):传统的 16/32 位应用程序仍能正常运行,类似于 32 位保护模式,其使用 16/32 位地址与操作数,仅能访问线性地址空间的前 4 GB,通过 PAE 可以访问更多的物理内存
- 纯 64 位模式(64-bit mode):该模式下可以访问 64 位线性地址空间, _通常_ 不再使用分段,通用寄存器与 SIMD 扩展寄存器从 8 个扩展至 16 个,通用寄存器扩展至 64 位,默认地址大小为 64 位,默认操作数大小为 32 位,新增的 opcode 前缀 `REX` 用以进行 64 位下的扩展访问
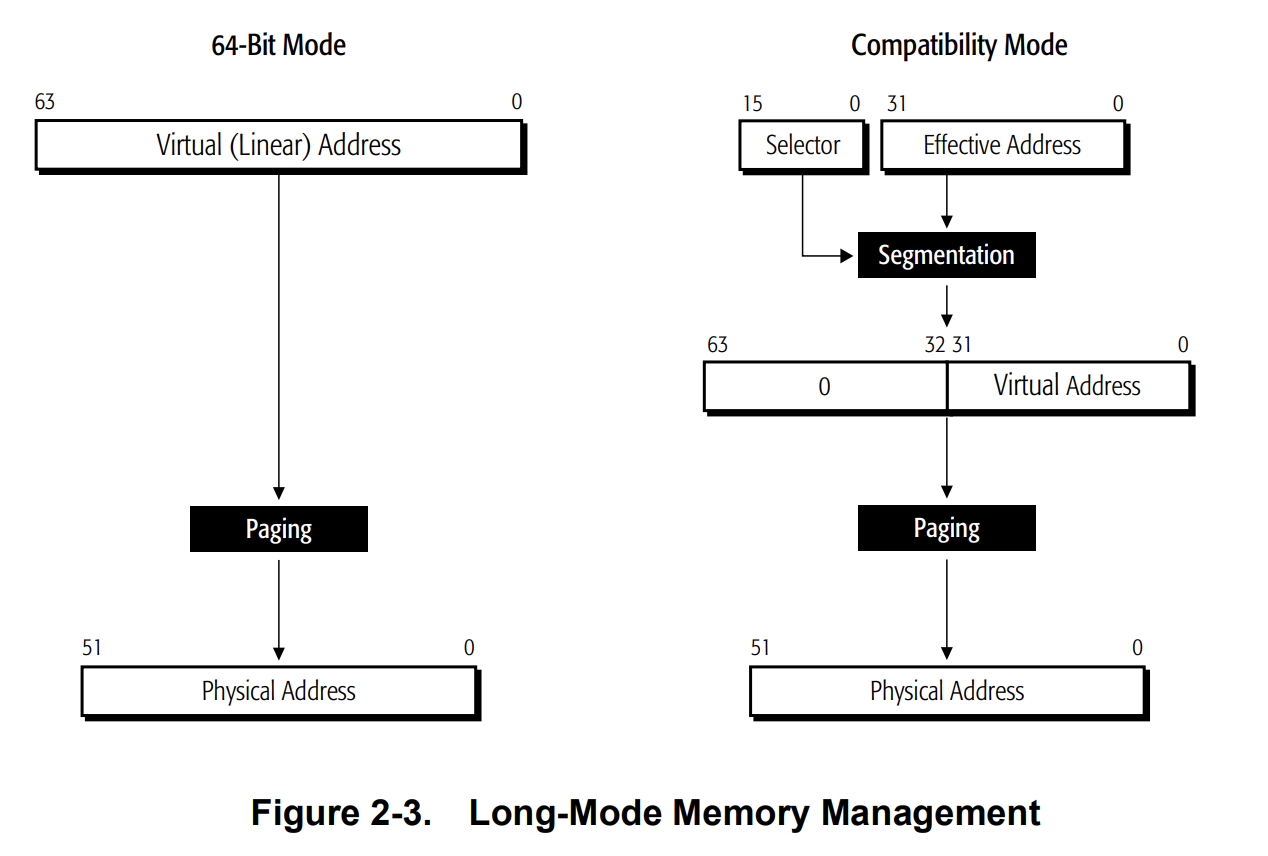
> 参见 Intel SDM 卷 1 Chapter 3、卷 3A Chapter 2 与 AMD64 PM 卷 1 Chapter 2、卷 2 Chapter 1
>
简而言之就是进入 64 位模式之后正常运行 64 位应用就在纯 64 位模式,但也可以通过兼容模式来像 32 位保护模式那样运行以前的 32 位应用,这两种子模式间的切换**通过 CS 段选择子对应的段描述符的 L 位决定**:
!(https://cdn.jsdelivr.net/gh/rat3bant/BlogPic@master/20231129171602.png)
我们的 64 位操作系统自然是运行在纯 64 位这一子模式下的,而 GRUB 引导进入我们的内核时我们仍处于 32 位模式下,因此我们需要编写 32 位汇编来将处理器切换到 64 位模式,具体需要进行如下工作:
- 将 **Model Specific Register **这一寄存器组中的 **Extended Feature Enable Register** 寄存器的 LME 位置为 1(参见 Intel SDM 卷 3 A Chapter 2 的 2.2.1 节,Table 2-1)
- 配置好相应的全局段描述符表,并将 CS 段选择子对应的段描述符的 L 位置为 1
- 开启控制寄存器组中 CR4 寄存器的 **物理地址扩展**(Physical Address Extension)
- 开启控制寄存器组中 CR0 寄存器的 **分页**(Paging),这要求我们预先装载一份页表
```assembly
# enable PAE and PGE
mov %cr4, %eax
or $(CR4_PAE | CR4_PGE), %eax
mov %eax, %cr4
# enter long mode by enabling EFER.LME
mov $0xC0000080, %ecx
rdmsr
or $(1 << 8), %eax
wrmsr
# enable paging
mov %cr0, %eax
or $CR0_PG, %eax
mov %eax, %cr0
# set up GDT
mov $gdt64_ptr, %eax
lgdt 0(%eax)
#......
.section .boot.loader.data
#......
# global segment descriptor table
.align 0x1000 # it should be aligned to page
.globl gdt64, gdt64_ptr
gdt64:
.quad 0 # first one must be zero
gdt64_code_segment:
.quad 0x00209A0000000000 # exec/read
gdt64_data_segment:
.quad 0x0000920000000000 # read/write
gdt64_ptr:
.short gdt64_ptr - gdt64 - 1 # GDT limit
.long gdt64 # GDT Addr
```
此时我们便来到了 64 位**兼容模式**,而要进入纯 64 位模式,则需要我们**手动更新 CS 段选择子**,这里笔者通过一个远跳转 `jmp` 指令**手动指定段选择子的方式来刷新 CS 段选择子**
> 以及别忘了刷新数据段选择子和其他段选择子,这些选择子可以直接通过寄存器进行重新赋值,**但是 CS 段选择子必须通过指令进行刷新**
从 `boot_main()` 开始我们就可以进入 C 语言的世界了:)
```assembly
# reload all the segment registers
mov $(2 << SELECTOR_INDEX), %ax
mov %ax, %ds
mov %ax, %ss
mov %ax, %es
mov %ax, %fs
mov %ax, %gs
# enter the 64-bit world within a long jmp
jmp $(1 << SELECTOR_INDEX), $boot_main
# we shouldn't get here...
.loop:
hlt
jmp .loop
```
> 注:除了通过 `jmp 选择子:目标地址` 的方式以外,我们也可以通过 `lretq` 指令刷新 CS 段选择子:
>
> ```assembly
> .code64
> pushq $(1 << SELECTOR_INDEX)
> pushq $boot_main
> lretq
> ```
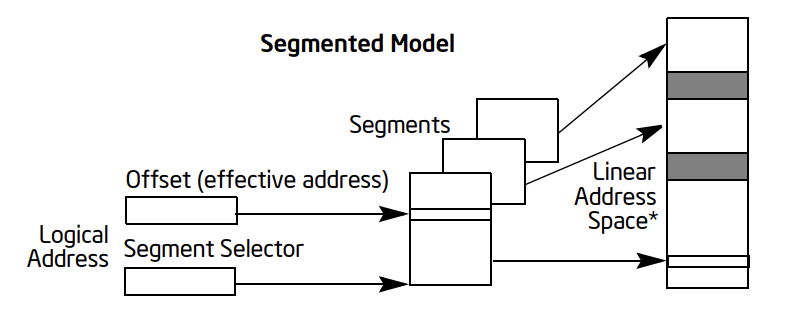
> #### Extra. 分段内存简介
>
> 在古老的 16 位与 32 位运行模式下,x86 有一种管理内存的办法叫做**分段**(Segment),一个段便是一段连续内存,相应地有 cs、ds 等段寄存器用来指示不同用途的段,经过分段映射的地址称为逻辑地址(logical address)
>
> 16 位下段寄存器中直接存放段基址与段界限信息,32 位下段描述符扩展为 8 字节,存放在内存中一个名为段描述符表的结构中,GDTR 寄存器用来存放全局段描述符表的地址,相应地段寄存器中存放的变为段选择子(segment selector),指示了该段寄存器对应的段在段描述符表中的索引、权限等信息
>
> 
>
> !(https://cdn.jsdelivr.net/gh/rat3bant/BlogPic@master/20231129184644.png)
>
> 不过分段内存模式过于鸡肋,现代操作系统通常会选择把所有段都初始化为整个内存,因此 CPU 厂商更改了设计,在 64 位下默认不使用分段特性,不过 _也不是完全弃用分段这一特性_ (尾大不掉属于是)
>
> !(https://cdn.jsdelivr.net/gh/rat3bant/BlogPic@master/20231129184734.png)
## boot\_tty.c:读写 frame buffer 进行文字输出
熟悉各类操作系统开发教程的小伙伴肯定知道非常经典的读写 `0xB8000` 这块内存便能在屏幕上进行字体输出, **但是在 UEFI 启动下这个方法已经不在可用** ,那么我们该怎么进行字体输出呢?最简单的办法自然是——**把像素点直接画在屏幕上**
### ① Frame Buffer
**帧缓冲区** ( **frame buffer** )为内存/显存中的一块自定义区域,可以简单理解为屏幕上所显示内容的缓存,显卡会定期从这块区域搬运数据到显示设备上,因此我们可以通过读写 frame buffer 的方式来在显示器的指定位置显示指定的像素点
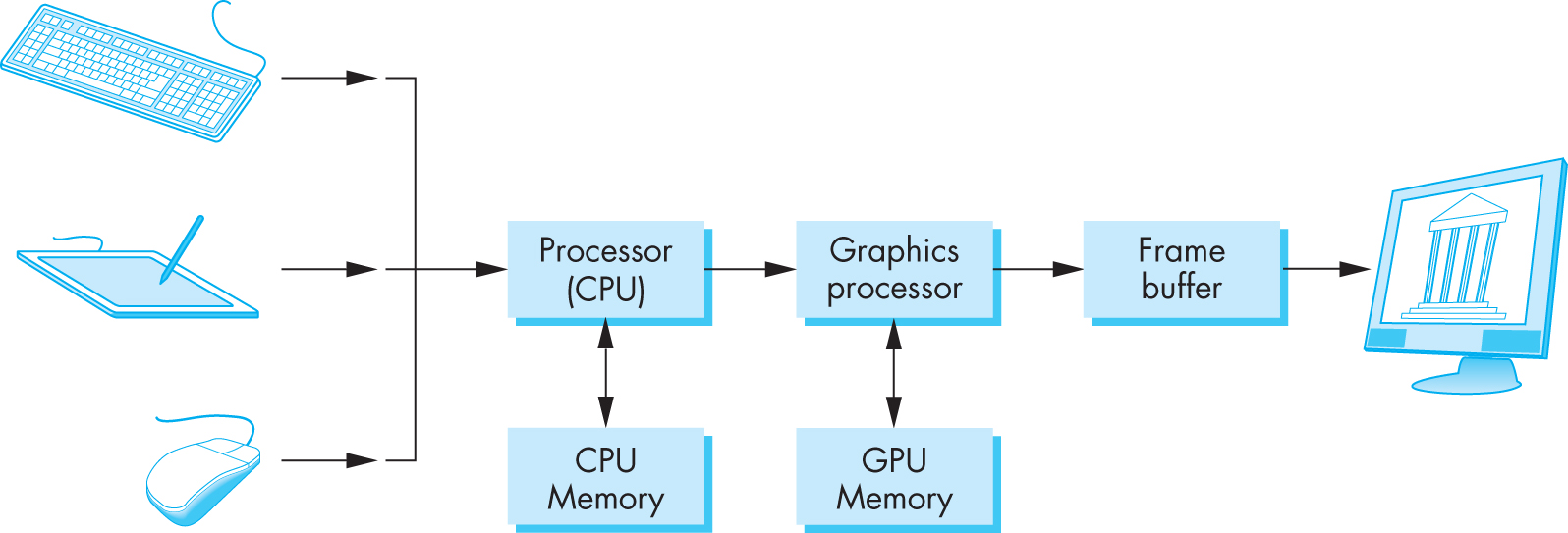
有了 Multiboot2 规范,我们可以指示 GRUB2 帮我们准备 Frame buffer 的相关信息并传递给我们的内核,接下来我们便能通过直接读写 frame buffer 对应内存的方式来直接在屏幕上进行显示:
```c
/* frame buffer info */
static uint32_t *framebuffer_base; /* 32 bit color */
static uint32_t framebuffer_width;
static uint32_t framebuffer_height;
static void boot_clear_screen_internal_fb(void)
{
for (uint32_t y = 0; y < framebuffer_height; y++) {
for (uint32_t x = 0; x < framebuffer_width; x++) {
framebuffer_base = 0;
}
}
}
static int boot_get_frame_buffer(multiboot_uint8_t *mbi)
{
struct multiboot_tag_framebuffer *fb_info = NULL;
struct multiboot_tag *tag = (struct multiboot_tag *) (mbi + 8);
/* find framebuffer tag */
if (tag == NULL) {
return -1;
}
while (tag->type != MULTIBOOT_TAG_TYPE_END) {
if (tag->type == MULTIBOOT_TAG_TYPE_FRAMEBUFFER) {
fb_info = (struct multiboot_tag_framebuffer*) tag;
break;
}
tag = (struct multiboot_tag *) \
((multiboot_uint8_t *) tag + ((tag->size + 7) & ~7));
}
if (fb_info == NULL) {
return -1;
}
framebuffer_base = (uint32_t*) fb_info->common.framebuffer_addr;
framebuffer_height = fb_info->common.framebuffer_height;
framebuffer_width = fb_info->common.framebuffer_width;
return 0;
}
```
### ② 字体解析绘制
虽然我们现在可以通过直接操作 Frame buffer 来绘制图形,但是每个字体都要从零开始绘制的话未免就太麻烦了一点,因此我们选择载入现有的 **PC Screen Font** 格式的字体文件,从中读取相应的字体信息进行绘制
> 这里字体笔者选择了 (https://github.com/talamus/solarize-12x29-psf/),clone 到本地后将 `Solarize.12x29.psf` 拷贝为 `arch/x86/boot/font.psf` 即可
由于我们还没建立文件系统,因此我们需要将字体文件直接链接到内核当中,这里可以使用 `objcopy` 这一工具来将字体文件转换为可链接文件:
> 需要注意的是,**objcopy 会非常 sb 地把路径名也放进去**,因此比较可行的解决方案就是**提前将字体文件转换为 .o 文件**
```shell
$ objcopy -O elf64-x86-64 -B i386 -I binary font.psf boot_font.o
$ objdump -t boot_font.o
boot_font.o: file format elf64-x86-64
SYMBOL TABLE:
0000000000000000 g .data0000000000000000 _binary_font_psf_start
0000000000007420 g .data0000000000000000 _binary_font_psf_end
0000000000007420 g *ABS*0000000000000000 _binary_font_psf_size
```
现在我们来看如何解析这一格式的字体,PSF 有两版规范,由一个 header 来指示字体基本信息, header 之后便是字体的位图信息:
```c
#define PSF1_FONT_MAGIC 0x0436
struct psf1_header {
uint16_t magic; /* magic number for identification */
uint8_t font_mode;/* PSF font mode */
uint8_t char_size;/* PSF char size */
};
#define PSF2_FONT_MAGIC 0x864ab572
struct psf2_header {
uint32_t magic; /* magic number for PSF */
uint32_t version; /* zero */
uint32_t header_size; /* offset of bitmaps in file, 32 */
uint32_t flags; /* 0 if there's no unicode table */
uint32_t glyph_nr; /* number of glyphs */
uint32_t bytes_per_glyph; /* size of each glyph */
uint32_t height; /* height in pixels */
uint32_t width; /* width in pixels */
};
```
字体位图有着其固定的宽度与高度,虽然字体的宽度并不一定对齐到 8 bit,但是存储空间需要对齐到 8 bit 也就是 1 字节,因此**位图数据中会有空数据填充段**,以一个 12x12 的 PSF 位图为示例:
```
padding
Font data |
+----------+ +--+
000001100000 0000
000011110000 0000
000110011000 0000
001100001100 0000
011000000110 0000
110000000011 0000
111111111111 0000
111111111111 0000
110000000011 0000
110000000011 0000
110000000011 0000
110000000011 0000
```
由此我们可以通过如下代码来解析字体文件并在屏幕上显示文字(二代规范):
```c
extern char _binary_font_psf_start[];
extern char _binary_font_psf_end[];
/* char output info */
static uint32_t fb_cursor_x, fb_cursor_y; /* count by chars */
static uint32_t max_ch_nr_x, max_ch_nr_y;
/* font info */
static struct psf2_header *boot_font;
static uint32_t font_width, font_height;
static uint32_t font_width_bytes;
static uint8_t *glyph_table;
static uint32_t bytes_per_glyph, glyph_nr;
static void boot_putchar_fb_new_line(uint32_t bg)
{
fb_cursor_x = 0;
fb_cursor_y++;
/* we may need to scroll up */
if (fb_cursor_y >= max_ch_nr_y) {
for (uint32_t y = 0; y < ((max_ch_nr_y - 1) * font_height); y++) {
for (uint32_t x = 0; x < framebuffer_width; x++) {
framebuffer_base =
framebuffer_base;
}
}
for (uint32_t y = 0; y < font_height; y++) {
for (uint32_t x = 0; x < framebuffer_width; x++) {
size_t lines = (y + (max_ch_nr_y - 1) * font_height);
size_t loc = lines * framebuffer_width + x;
framebuffer_base = bg;
}
}
fb_cursor_y--;
}
}
static void boot_putchar_fb(uint16_t ch, uint32_t fg, uint32_t bg)
{
uint8_t *glyph = glyph_table;
size_t loc;
/* if char out of range, output null */
if (ch < glyph_nr) {
glyph += ch * bytes_per_glyph;
}
loc =fb_cursor_y * font_height * framebuffer_width;
loc += fb_cursor_x * font_width;
/* output the font to frame buffer */
for (uint32_t ch_y = 0; ch_y < font_height; ch_y++) {
uint8_t mask = 1 << 7;
for (uint32_t ch_x = 0; ch_x < font_width; ch_x++) {
if ((*(glyph + ch_x / 8) & mask) != 0) {
framebuffer_base = fg;
} else {
framebuffer_base = bg;
}
mask >>= 1;
if (ch_x % 8 == 0) {
mask = 1 << 7;
}
}
glyph += font_width_bytes;
}
/* move cursor */
fb_cursor_x++;
/* we may need to move to new line */
if (fb_cursor_x >= max_ch_nr_x) {
boot_putchar_fb_new_line(bg);
}
}
static void boot_init_font(void)
{
boot_font = (struct psf2_header*) _binary_font_psf_start;
font_width_bytes = (boot_font->width + 7) / 8;
font_width = font_width_bytes * 8;
font_height = boot_font->height;
glyph_table = (uint8_t*)_binary_font_psf_start+boot_font->header_size;
glyph_nr = boot_font->glyph_nr;
bytes_per_glyph = boot_font->bytes_per_glyph;
fb_cursor_x = fb_cursor_y = 0;
max_ch_nr_x = framebuffer_width / font_width;
max_ch_nr_y = framebuffer_height / font_height;
}
```
### _Extra: 串口输出初探_
> 注,因为我们目前处在 boot 部分,因此笔者仅会实现一个最简陋的串口输出代码,在后续的 real kernel 部分的代码中我们会重新实现一个更加完备的串口驱动
串口输出是以前老 IBM 机喜欢用的方法,包括 Linux kernel 也支持串口输出功能(当你使用 qemu 运行时若添加了 `-nographic` 参数 QEMU 会将虚拟机的串口 0 的输出重定向到当前终端,也可以直接在 qemu 的图形界面切换到 `serial 0`),目前这个输出方式已经很少被使用了, ~~毕竟都什么年代了还在抽传统香烟?~~ 不过在一些特殊场景这个方法还是偶尔会被用到的(例如 headless console),因此这一节我们简单讲讲如何通过串口进行字符输出
**串行通讯端口** (Serial Port,aka COM)通常由 _通用异步收发传输器_ (Universal Asynchronous Receiver/Transmitter, UART)进行控制,其内部时钟波特率通常是 115200,目前比较常用的是 (https://gunkies.org/wiki/EIA_RS-232_serial_line_interface) 标准,针脚数通常是 25 针或 9 针(后者用的比较多)
!(https://s2.loli.net/2024/06/12/jUkhowJWRO67bHg.png)
> 更多的微机原理知识这里不再赘叙,我们接下来简单讲讲串口如何使用
单个串口的 _寄存器组_ 会被映射到指定的 IO port 起始的区域,我们通过访问串口的不同寄存器进行相应的操作,通常情况下串口映射到端口的**基地址**如下:
> 需要注意的是 _仅有前两个串口的端口地址是固定不变的,其余串口的端口地址未必如下表所示_
>
> 对于守旧的 BIOS 用户,(https://www.cs.yale.edu/flint/feng/cos/resources/BIOS/Resources/biosdata.htm) 可以帮助你获取包括 COM 地址在内的各种信息
>
> 对于 ~~不抽传统香烟的~~ 现代 UEFI 用户,
| COM Port | IO Port Base |
| -------- | ------------ |
| COM1 | 0x3F8 |
| COM2 | 0x2F8 |
| COM3 | 0x3E8 |
| COM4 | 0x2E8 |
| COM5 | 0x5F8 |
| COM6 | 0x4F8 |
| COM7 | 0x5E8 |
| COM8 | 0x4E8 |
不同偏移的寄存器含义如下(来自 (https://wiki.osdev.org/Serial_Ports)):
| IO Port Offset | Setting of DLAB | I/O Access | Register mapped to this port |
| -------------- | --------------- | ---------- | ------------------------------------------------------------ |
| +0 | 0 | Read | Receive buffer. |
| +0 | 0 | Write | Transmit buffer. |
| +1 | 0 | Read/Write | Interrupt Enable Register. |
| +0 | 1 | Read/Write | With DLAB set to 1, this is the least significant byte of the divisor value for setting the baud rate. |
| +1 | 1 | Read/Write | With DLAB set to 1, this is the most significant byte of the divisor value. |
| +2 | - | Read | Interrupt Identification |
| +2 | - | Write | FIFO control registers |
| +3 | - | Read/Write | Line Control Register. The most significant bit of this register is the DLAB. |
| +4 | - | Read/Write | Modem Control Register. |
| +5 | - | Read | Line Status Register. |
| +6 | - | Read | Modem Status Register. |
| +7 | - | Read/Write | Scratch Register. |
方便起见,在启动阶段我们就不编写太过于复杂的串口驱动了,简单来说,要通过串口进行字符输出,我们首先需要往一部分寄存器中写入特定数据进行串口初始化:
```c
int boot_init_com_internal(size_t base_port)
{
/* disable all interrupts */
outb(base_port + COM_REG_IER, 0x00);
/* enable DLAB to set bound rate divisor */
outb(base_port + COM_REG_LCR, 0x80);
/* set divisor to 38400 baud */
outb(base_port + COM_REG_DLL, 0x03);
outb(base_port + COM_REG_DLM, 0x00);
/* 8 data bits, parity off, 1 stop bit, DLAB latch off */
outb(base_port + COM_REG_LCR, 0x03);
/* enable FIFO */
outb(base_port + COM_REG_FCR, 0xC7);
/* enable IRQs, set RTS/DSR */
outb(base_port + COM_REG_MCR, 0x0B);
/* set in loopback mode and test serial chip */
outb(base_port + COM_REG_MCR, 0x1E);
/* write a byte to test serial chip */
outb(base_port + COM_REG_TX, "arttnba3");
/* check if serial is faulty */
if (inb(base_port + COM_REG_RX) != "arttnba3") {
return -1;
}
/* set in normal mode */
outb(base_port + COM_REG_MCR, 0x0F);
return 0;
}
```
之后直接往串口里 `outb()` 即可输出字符:
```c
static void boot_putchar_com(uint16_t ch)
{
uint8_t res;
/* wait for the port to be ready */
do {
res = inb(com_base + COM_REG_LSR);
res &= 0x20;
} while (res == 0);
outb(com_base, ch);
}
```
这里我们为 QEMU 附加 `-nographic` 的参数进行测试,可以看到串口输出的数据一切正常:
> `Ctrl + A` 后再 `C` 进入 QEMU 调试台,`q` 退出
## 真机启动
接下来我们使用 `make` 命令编译代码,将 `out` 目录下的 `kernel.bin` 文件放到 U 盘 EFI 分区中的 `boot` 目录下,重启计算机并选择 U 盘启动,接下来——
**ClosureOS,启动——!!!**
我们成功制作完成了一个**能够在真机上运行的操作系统,而并非大部分教科书上的那些只能在虚拟机里跑的小玩具**,虽然目前仅有最基本的雏形 :)
> 我们将在后续文章当中逐步完善这个操作系统(🕊🕊🕊)
# 0xFE. What's more...
本项目代码开源在 (https://github.com/arttnba3/ClosureOS),如果不嫌弃的话还请多来点 star ? :)
# 0xFF. Reference
(https://elixir.bootlin.com/linux/latest/source)
(https://www.gnu.org/software/grub/manual/multiboot2/multiboot.html)
(https://wiki.osdev.org/Main_Page) ← 非常好维基,使我OS运行,爱来自瓷器❤
(https://zhuanlan.zhihu.com/UEFIBlog)
(https://wiki.osdev.org/PC_Screen_Font)
(https://os.phil-opp.com/)
(https://pendrivelinux.com/install-grub2-on-usb-from-ubuntu-linux/)
[用grub2制作多重引导的WinPE&Linux启动U盘](https://oscarcx.com/tech/usb-boot-winpe-and-linux-via-grub2.html)
(https://gunkies.org/wiki/Main_Page)
(https://wiki.osdev.org/Serial_Ports)
(https://www.scs.stanford.edu/09wi-cs140/pintos/specs/pc16550d.pdf)
(https://www.keil.com/dd/vtr/3880/9788.htm)
(https://www.lookrs232.com/rs232/lcr.htm) mmshm 发表于 2024-10-8 14:47
大佬太6了,果然还是科班的人nb,我们学其他专业后来改行计算机的佩服的不行,感觉自学CS永远有学不完的东 ...
我同样感叹钦佩作者,同时需要告诉你抛开科班偏见。没有想鼓励你的意思,而是实事求是,我科班出生,到大四依旧有很多同学不会c语言,这点即使在清北也是一样的,也有少数人最后无奈转专业。中国大学天生自带课堂学不到有用知识的光环,所有大佬全都是自学的。事实就如你所说的CS永远有学不完的东西,所以最终大家都是拼命自学而不会因为是科班而更有优势。作者能手搓操作系统,但不一定精通加密技术、图形学、视频流、互联网服务器、游戏设计、算法开发等各种方面,你不一定在某个领域比作者差,CS就是这样的。:lol 这功底需要多久才能学到? 大佬太牛了,从头打造window,给个赞 虽然看不懂,但是大佬NB{:1_921:} 大佬牛逼,手撸操作系统 不明觉厉,大佬很强 大佬很强,加油 如此之NB,简直不要太帅 厉害了,坐等大佬更新,瑞思拜! 长见识了