html2markdown&nodejsТІДЬРґЕАіжЈїјЗТ»ґОblogЗЁТЖЦБGhost
# јЗТ»ґОBlogЗЁТЖµЅGhostЦ®З°µДУГБЛHexoґоЅЁБЛBlogЈ¬І»№эУЙУЪДіґОµДІЩЧчК§ОуµјЦВHexo±ѕµШµДsourceФґОДјюИ«Ії¶ЄК§.БфПВµДЦ»УРНшТіµДHtmlОДјю,ЦЪЛщЦЬЦЄ,HexoКЗТ»ёц±ѕµШ±аТлІїКрАаРНµДBlogПµНі,ёцИЛёРѕхХвЦЦАаРНµДBlogМШ±рІ»ОИ¶Ё,Из№ы±ѕµШіцБЛТ»Р©ОКМвДЗГґПЯЙПѕНGGБЛ,µ±И»,К№УГgitКЗїЙТФ№ЬАнФґОДјю,µ«КЗФґОДјюАпУЦ°ьє¬єЬ¶аНјЖ¬µДЗйїцПВ,downloadєНuploadТ»ґОµДК±јдТІ»б±ИЅПі¤,ЛдИ»ЛµХвјёДк¶јБчРРХвЦЦАаРНµДBlog,µ«ёцИЛїґАґ»№КЗWEB±ИЅПКµФЪЎЈ
### BlogСЎРН
ЧФјє¶ФBlogТІНжБЛТ»Р©,І»ЛгМШ±р¶а,ЦчТЄКЗwordpress(php),ХвґОФЪїґBlogПµНіµДК±єт,µЪТ»К±јдїјВЗµДКЗwordpress,ЛµЖрАґµ±К±ТІКЗwordpress±ИЅПФзµДК№УГ»јХЯБЛ,wordpressµДА©Х№РФЗї,УИЖдКЗДїЗ°°ж±ѕµДwordpress,ЅбєПЦчМвОДјюєНЧФ¶ЁТеfunction,НкИ«їЙТФНжіцєЬ¶а»ЁСщ,ІўЗТЦ§іЦёчЦЦІејюbalabala,ЧоРВµД°ж±ѕ»№Ц§іЦREST-API,їЄ·ўЖрАґТІј«ОЄ·Ѕ±г,ДЗГґОЄКІГґОТГ»УРСЎУГwordpress?Ц®З°ЧцБЛТ»Р©wordpressµДСРѕї,·ўПЦФЪЅбєПДіР©ЦчМвµДК±єт,wordpress»бј«Вэ(php7.2,ssd,i7-7700hq,16gb),±ѕµШЕЬ¶јј«Вэ,µ±И»Хвёц№шwordpressїП¶ЁІ»±іµД,µ«КЗОТФЪЧФјєїЄ·ўЦчМвµДЗйїцПВ,РґБЛТ»ёцrest-api
```
/**
* №№ЅЁµјєЅ
* @Param $res ЛщУРµДnavµјєЅlist
* @param $hash іРФШµјєЅµДhash±н
*/
private function buildNav(&$res,&$hash){
//ЧйЧ°µјєЅ
foreach($hash as $i =>$value){
$id = $value->ID;
$b =$this->findAndDelete($res,$id);
$value->sub= $b;
// КЗ·сУРЧУДїВј
if(count($b)>0){
$this->buildNav($res,$value->sub);
}
}
}
public function getNav($request){
$menu_name = 'main-menu'; // »сИЎЦчµјєЅО»ЦГ
$locations = get_nav_menu_locations();
$menu_id = $locations[ $menu_name ] ;
$menu = wp_get_nav_menu_object($menu_id); //ёщѕЭlocations·ґІйmenu
$res = wp_get_nav_menu_items($menu->term_id);
// ЧйЧ°З¶МЧµДµјєЅ,
$hash = $this->findAndDelete($res,0);
$this->buildNav($res,$hash);
return rest_ensure_response( $hash );
}
}
```
ґъВл±ИЅПјтµҐ,»сИЎєуМЁµДЦчµјєЅ,С»·±йАъЧйЧ°іЙЗ¶МЧµДКэЧйЅб№№,ОТФЪєуМЁРВЅЁБЛ3ёцµјєЅ,Ѕб№ыµчУГХвёцAPI(PHP5.6)µДЗйїцРиТЄ»Ё·С500ms-1s,ФЪPHP7µДЗйїцРиТЄ»Ё·С200-500ms,ХвёцІЁ¶ЇМ«ґуБЛ,КэѕЭївБґЅУµШЦ·ТІУГБЛ127.0.0.1Ј¬ФЩјУЙПЧФјєІ»ФхГґ»бЕД»ЖЖ¬(CURDј¶±р¶шТС),ЛщТФЛдИ»°®µДЙоіБ,Чоєу»№КЗЖъУГБЛЎЈ
ДЗГґїЙСЎФсµД»№УРgoУпСФµДДЗїоєНghostБЛ,±ѕИЛЛдИ»єЬПлИҐС§GoУпСФ,ДОєОН··ўТСІ»¶а,»№КЗСЎФсБЛЧФјєКмП¤µДnode.jsК№УГБЛghost,ХвСщєуРшїЄ·ўЖрАґТІ±ИЅП·Ѕ±гЎЈ
### АПBlogµДhtml2markdown
ТтОЄЦ»УРhtmlОДјюБЛ,ДЗГґХвёцК±єтµГПл°м·Ё°СhtmlЧЄmarkdown,±ѕАґПлјтµҐµг,Лµ»°µД·ЅКЅ...їИїИ,КФУГБЛКРГжЙПµДhtml2markdown,ЛдИ»ФзЦЄІ»»бґпµЅАнПлµДР§№ы,µ±И»Ѕб№ыТІКЗІ»іцЛщБПµД,№КЦ»ДЬЧФјєёщѕЭОД±ѕ№жФтИҐРґТ»МЧЧЄ»»ЖчБЛ.
#### html·ЦОц
КЧПИАыУГ`http-server`±ѕµШґоЅЁЖрТ»МЧѕІМ¬·юОсЖч,ЅУЧЕ¶ФНшТіµДhtmlЅб№№ЅшРР·ЦОцЎЈ
КµПЦµДЧоЦХР§№ыИзПВ
ФОД

ЧЄ»»єу
ТіГжµДtitleКЗ`.article-title`ґЛclassµДОД±ѕ,ТіГжµДЛщУРДЪИЭµДwrapКЗ`.article-entry`,ЖдЦРРиТЄЧЄ»ЇµДmarkdownµДhtmlѕНКЗ`.article-entry >*`,µГЦЄБЛХвР©РЕПўєНЅб№№єуѕНїЄКјЧЕКЦРґЧЄ»Ї№жФтБЛ,±ИИз`h2 -> ## h2`;КЧПИЅЁБўruleБР±н,РґИліЈУГµД±кЗ©,ХвАпµД$КЗnodejsµДcheerio,elemКЗhtmlparse2ЧЄ»»іцАґµД,ЛщТФФЪдЇААЖчµДДіР©КфРФКЗГ»°м·ЁФЪnodejsїґµЅµД
```
const ruleFunc = {
h1: function ($, elem) {
return `# ${$(elem).text()} \r\n`;
},
img: function ($, elem) {
return `.attr('src')}) \r\n`;
},
....
}
```
µ±И»,ХвР©Ц»КЗіЈУГµД±кЗ©,№вХвР©±кЗ©»№І»№»,±ИИзУцµЅОД±ѕЅЪµгАаРН,ѕЩёцАэЧУ
```
<p>
ОТТЄ
<a href="/">ОТµД</a>
ЧМО¶
</p>
```
ДЗГґДгІ»ДЬµҐґїµД»сИЎp.text()¶шКЗТЄИҐ±йАъЖдДЪІї»№°ьє¬БЛДДР©±кЗ©,ІўЗТЧЄ»»іцАґ,±ИИзЙПКцµДАэЧУѕН°ьє¬БЛ
```
ОД±ѕЅЪµг(text)
a±кЗ©(a)
ОД±ѕЅЪµг(text)
```
¶ФУ¦ЧЄ»ЇіцАґµДmarkdownУ¦ёГКЗ
```
ОТТЄ
[ОТµД](/)
ЧМО¶
```
»№єГ,УЙmarkdownЙъіЙіцАґµДhtmlІ»ЛгМШ±рїУµщ,КІГґТвЛјДШ,І»»бp±кЗ©АпГжЗ¶МЧВТЖЯ°ЛФгµД¶«Оч(ЖдКµХвёъhexoЦчМвУР№Ш,»№єГОТУГµДЦчМв±ИЅПµр,ґъВлКІГґµД¶јєЬ№ж·¶),ДЗГґХвёцК±єтѕНТЄїЄКјЅЁБўp±кЗ©µД±йАъ№жФт
```
p: function ($, elem) {
let markdown = '';
const $subElem = $(elem).contents(); // »сИЎµ±З°p±кЗ©ПВµДЛщУРЧУЅЪµг
$subElem.each((index, subElem) => {
const type = subElem.type; // µ±З°ЧУЅЪµгµДtypeКЗ text »№КЗ tag
let name = subElem.name || type; // nameКфРФ===nodeName ТІѕНКЗµ±З°±кЗ©Гы
name = name.toLowerCase();
if (ruleFunc) { // КЗ·сФЪµ±З°ЅвОц№жФтХТµЅ
let res = ruleFunc($, subElem); // Из№ыХТµЅµД»°ФтµЭ№йЅвОц
if (name != 'br' || name != 'text') { // Из№ыµ±З°ЅЪµгІ»КЗbr»тХЯОД±ѕЅЪµг ¶ј°С\r\nёшИҐµф,ТЄІ»И»»біцПЦ±ѕАґТ»РРµДОД±ѕТтОЄЦРјдјУБЛДіР©ДЪИЭ»б»»РР
res = res.replace(/\r\n/gi, '');
}
markdown += res;
}
});
return markdown + '\r\n'; // \r\nОЄ»»РР·ы
},
```
ДЗГґp±кЗ©µДЅвОц№жФтРґНкєу,ТЄїЄКјїјВЗulєНolХвЦЦРтєЕАаРНБЛ,І»№эХвЦЦАаРНµДТІУРЗ¶МЧµД
```
- web
- - js
- - css
- - html
- backend
- - node.js
```
ПсХвЦЦЗ¶МЧАаРНµДТІРиТЄИҐУõݹ鴦АнТ»ПВ
```
ul: function ($, elem) {
const name = elem.name.toLowerCase();
return __list({$, elem, type: name})
},
ol: function ($, elem) {
const name = elem.name.toLowerCase();
return __list({$, elem, type: name})
},
/**
* @param splitStr Д¬ИПµДїЄКј·ыКЗ -
* @param {*} param0
*/
function __list({$, elem, type = 'ul', splitStr = '-', index = 0}) {
let subNodeName = 'li'; // Д¬ИПµДЧУЅЪµгКЗli КµјКЙПol,ulµДЧУЅЪµг¶јКЗli
let markdown = ``;
splitStr += `\t`; // Д¬ИПµД·Цёф·ыКЗ ЦЖ±н·ы
if (type == 'ol') {
splitStr = `${index}.\t` // Из№ыКЗolАаРНµД ФтКЗґУ0їЄКјµДindex КµјКЙПХвТ»ІЅУРµг¶аУа,ФЪПВОДУРЧцЦШРВМж»»
}
$(elem).find(`> ${subNodeName}`).each((subIndex, subElem) => {
const $subList = $(subElem).find(type); //µ±З°ЧУЅЪµгПВГжКЗ·сУРul || ol ±кЗ©?
if ($subList.length <= 0) {
if (type == 'ol') {
splitStr = splitStr.replace(index, index + 1); // Из№ыКЗol±кЗ© ФтїЄКј·ыєЕОЄ 1. 2. 3. ХвЦЦАаРНµД
index++;
}
return markdown += `${splitStr} ${$(subElem).text()} \r\n`
} else {
// Из№ыґжФЪ ul || ol ФтЅшРР¶юґОµЭ№йґ¦Ан
let nextSplitStr = splitStr + '-';
if (type == 'ol') {
nextSplitStr = splitStr.replace(index, index + 1);
}
const res = __list({$, elem: $subList, type, splitStr: nextSplitStr, index: index + 1}); // µЭ№йґ¦Анµ±З°ДЪІїµДulЅЪµг
markdown += res;
}
});
return markdown;
}
```
ЅУЧЕґ¦АнґъВлАаРНµД,ХвАпТЄЧўТвµДѕНКЗЧЄТеєН»»РР,ТЄІ»И»ghostµДmarkdownІ»К¶±р
```
figure:function ($,elem) {
const $line = $(elem).find('.code pre .line');
let text = '';
$line.each((index,elem)=>{
text+=`${$(elem).text()} \r\n`;
});
return ` \`\`\` \r\n ${text} \`\`\` \r\n---`
},
```
ДЗГґЧцНкХвБЅІЅєу,»щ±ѕЙПЅвОц№жФтТСѕНкіЙБЛ80%,КІГґЈїДгЛµtableєНРтБРНјАаРНЈї...ХвёцїУѕНµИЧЕДгГЗАґМоАІ,ОТµДBlogєЬЙЩУГµЅХвБЅЦЦАаРНµДЎЈ
#### ЧҐИЎhtml
ЧҐИЎhtmlХвАпФтїЙТФК№УГrequest+cheerioАґґ¦Ан,ЧҐИЎОТBlogЦРµДЛщУРОДХВ,ІўЗТЅЁБўurlArray,И»єу±йАъЅвОцѕНРР
```
async function getUrl(url) {
let list = []
const options = {
uri: url,
transform: function (body) {
return cheerio.load(body);
}
};
console.info(`»сИЎURL:${url} done`);
const $ = await rp(options);
let $urlList = $('.archives-wrap .archive-article-title');
$urlList.each((index, elem) => {
list.push($(elem).attr('href'))
});
return list;
}
async function start() {
let list = [];
let url = `http://127.0.0.1:8080/archives/`;
list.push(...await getUrl(url));
for (let i = 2; i <=9; i++) {
let currentUrl = url +'page/'+ i;
list.push(...await getUrl(currentUrl));
}
console.log('ЛщУРТіГж»сИЎНк±П',list);
for(let i of list){
await html2Markdown({url:`http://127.0.0.1:8080${encodeURI(i)}`})
}
}
```
ЙПКцТЄЧўТвµДѕНКЗ,ЧҐИЎµЅµДhrefИз№ыКЗЦРОДµД»°,КЗІ»»бurl±аВлµД,ЛщТФФЪ·ўЖрЗлЗуµДК±єтЧоєГ¶оН⴦АнТ»ПВ,ТтОЄКмП¤ЧФјєµДBlog,ЛщТФУРР©КэЦµ¶јРґЛААІ~
### ghostµДґоЅЁ
(https://github.com/TryGhost/Ghost)
ХвАпОТТЄµҐ¶АЛµТ»ПВ,ghostµДґоЅЁКЗ¶сРДµЅОТБЛ,ЛдИ»ДЬ№»їмЛЩґоЅЁЖрАґ,µ«КЗИз№ыПлјтјтµҐµҐµДПЯЙПК№УГ,ДЗѕНКЗНјСщНјЙЖЖБЛ,ТтОЄРиТЄ¶оНвµДЕдЦГ,
°ІЧ°
```
npm install ghost-cli -g // ghost№ЬАнcli
ghost install local // ХэКЅ°ІЧ°
```
ФЛРР
```
ghost start
```
µЪТ»ґОФЛРРіЙ№¦єуПИ±рј±ЧЕґтїЄwebМоРЕПў,ПИИҐЕдЦГТ»ПВmysqlДЈКЅ,sqlitєуЖЪА©Х№РФМ«ІоБЛЎЈ
ХТµЅghost°ІЧ°ДїВјПВЙъіЙµД`config.development.json`ЕдЦГ
```
"database": {
"client": "mysql",
"connection": {
"host": "127.0.0.1",
"port": 3306,
"user": "root",
"password": "123456",
"database": "testghost"
}
},
------
"url": "https://relsoul.com/",
```
°СdatabaseМж»»ОЄЙПКцµДmysqlЕдЦГ,И»єу°СurlМж»»ОЄПЯЙПurl,ЅУЧЕЦґРР`ghost restart`јґїЙ
### NGINX+SSL
ХвАпАыУГhttps://letsencrypt.org Аґ»сИЎГв·СµДSSLЦ¤Кй ЅбєПNGINXАґЕдЦГ(·юОсЖчОЄcentos7)
КЧПИРиТЄЙкЗлБЅёцЦ¤Кй Т»ёцКЗ*.relsoul.com Т»ёцКЗ relsoul.com
**°ІЧ°**
```
yum install -y epel-release
wget https://dl.eff.org/certbot-auto --no-check-certificate
chmod +x ./certbot-auto
```
ЙкЗлНЁЕд·ы
[ІОїјґЛОДХВЅшРРНЁЕд·ыЙкЗл](https://www.jianshu.com/p/c5c9d071e395)
```
./certbot-auto certonly-d *.relsoul.com --manual --preferred-challenges dns --server https://acme-v02.api.letsencrypt.org/directory
```
ЙкЗ뵥ёцЦ¤Кй
[ІОїјґЛЖЄОДХВЅшРРµҐёцЙкЗл](https://blog.fazero.me/2017/09/16/letencrypt/)
```
./certbot-auto certonly --manual --email relsoul@outlook.com --agree-tos --no-eff-email -w /home/wwwroot/challenges/ -d relsoul.com
```
ЧўТвµДКЗТ»¶ЁТЄјУЙП--manual,І»ЦЄµАОЄЙ¶Из№ыІ»УГКЦ¶ЇДЈКЅ,ЧФ¶ЇµД»°І»»бЙъіЙСйЦ¤ОДјюµЅОТµДёщДїВј,°ґХХГьБоРРµДЅ»»ҐМбКѕКЦ¶ЇМнјУСйЦ¤ОДјюµЅНшХѕДїВјЎЈ
**ЕдЦГ**
ХвАпЦ±ЅУёшіцnginxµДЕдЦГ,»щ±ѕЙП±ИЅПјтµҐ,80¶ЛїЪ·ГОКД¬ИПМшЧЄ443¶ЛїЪѕНРР
```
server {
listen 80;
server_name www.relsoul.com relsoul.com;
location ^~ /.well-known/acme-challenge/ {
alias /home/wwwroot/challenges/; # ХвТ»ІЅєЬЦШТЄ,СйЦ¤ОДјюµДДїВј·ЕЦГµД
try_files $uri =404;
}
# enforce https
location / {
return 301 https://www.relsoul.com$request_uri;
}
}
server {
listen 443ssl http2;
#listen [::]:80;
server_name relsoul.com;
ssl_certificate /etc/letsencrypt/live/relsoul.com-0001/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/relsoul.com-0001/privkey.pem;
# Example SSL/TLS configuration. Please read into the manual of NGINX before applying these.
ssl_session_timeout 5m;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
ssl_prefer_server_ciphers on;
keepalive_timeout 70;
ssl_stapling on;
ssl_stapling_verify on;
index index.html index.htm index.php default.html default.htm default.php;
# root /home/wwwroot/ghost;
location / {
proxy_pass http://127.0.0.1:9891; # ghostєуМЁ¶ЛїЪ
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Host $server_name;
proxy_read_timeout 1200s;
# used for view/edit office file via Office Online Server
client_max_body_size 0;
}
#error_page 404 /404.html;
# location ~ .*\.(gif|jpg|jpeg|png|bmp|swf)$ {
# expires 30d;
# }
# location ~ .*\.(js|css)?$ {
# expires 12h;
# }
include none.conf;
access_log off;
}
server {
listen 443ssl http2;
#listen [::]:80;
server_namewww.relsoul.com;
ssl_certificate /etc/letsencrypt/live/relsoul.com/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/relsoul.com/privkey.pem;
# Example SSL/TLS configuration. Please read into the manual of NGINX before applying these.
ssl_session_timeout 5m;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
ssl_prefer_server_ciphers on;
keepalive_timeout 70;
ssl_stapling on;
ssl_stapling_verify on;
index index.html index.htm index.php default.html default.htm default.php;
# root /home/wwwroot/ghost;
location / {
proxy_pass http://127.0.0.1:9891; # ghostєуМЁ¶ЛїЪ,ЅшРР·ґПтґъ{№э}{ВЛ}Ан
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Host $server_name;
proxy_read_timeout 1200s;
# used for view/edit office file via Office Online Server
client_max_body_size 0;
}
#error_page 404 /404.html;
# location ~ .*\.(gif|jpg|jpeg|png|bmp|swf)$ {
# expires 30d;
# }
# location ~ .*\.(js|css)?$ {
# expires 12h;
# }
include none.conf;
access_log off;
}
```
ЧцНкЙПГжјёІЅєуѕНїЙТФ·ГОКНшХѕЅшРРЙиЦГБЛ,Д¬ИПµДЙиЦГµШЦ·ОЄ`http://relsoul.com/ghost`
### µјИлОДХВЦБghost
ghostµДAPIКЗУРµгµ°МЫµД,КЧПИghostУРБЅЦЦAPI,Т»ЦЦКЗ(https://docs.ghost.org/api/content/),Т»ЦЦКЗ(https://api.ghost.org/)
PublicApiДїЗ°Ц»Ц§іЦ¶Б,ТІѕНКЗGet,І»Ц§іЦPOST,¶шAdminApiФтКЗґ¦УЪёД°жµДЅЧ¶О,І»№э»№КЗДЬУГµД,№Щ·ЅТІГ»ѕЯМеЛµКІГґК±єт·Піэ,ХвАпЦ»Хл¶ФAdminApiЅшРРЛµГч,ТтОЄPublicApiµДµчУГМ«јтµҐБЛ,ОДµµТІ±ИЅПИ«,AdminApiѕНµ°МЫБЛ
#### »сИЎСйЦ¤Token
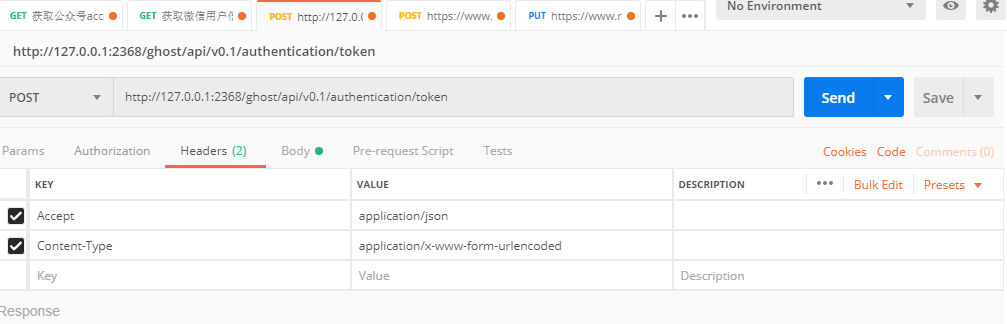
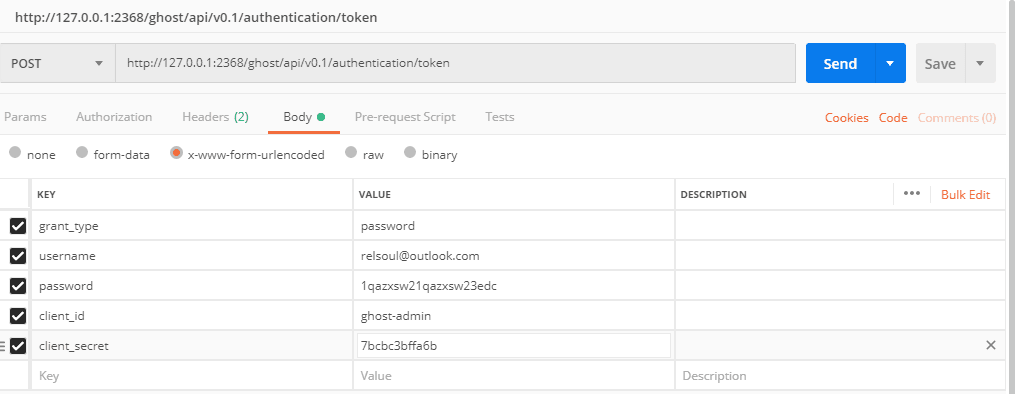
ПИёшіцСйЦ¤µДPOST,
ХвАпТЄЧўТвµДТ»µгѕНКЗ`client_secret`ХвёцЧЦ¶ОЈЎЈЎЈЎХжµДєЬ¶сРД,ТтОЄДг»щ±ѕЙПФЪєуМЁКЗХТІ»µЅµД,ТтОЄ№Щ·ЅТІЛµБЛAdminApiЖдКµДїЗ°КЗЛЅУРµД,ЛщТФДгРиТЄФЪКэѕЭївХТ ѕЯМеµД±нїґПВНј
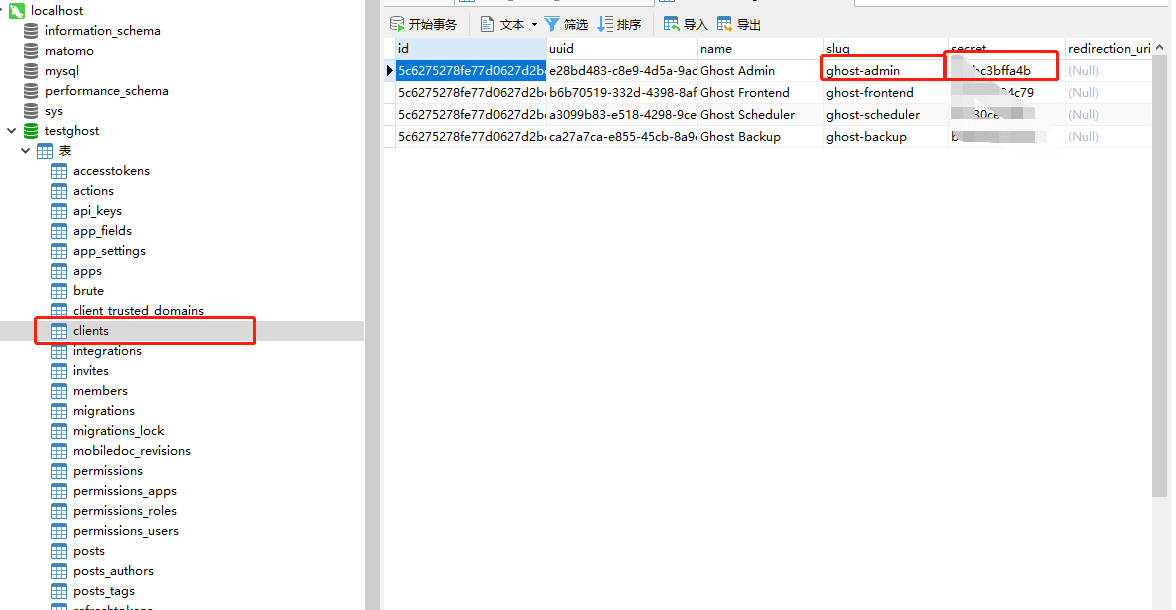
ДГµЅХвёцЦµєуѕНїЙТФЗлЗу»сИЎaccessTokenБЛ
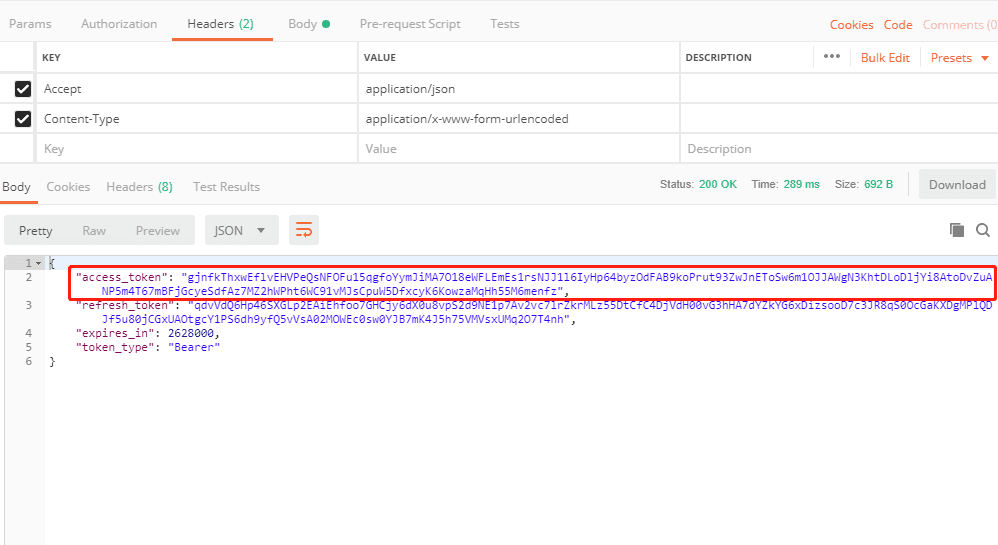
ДГµЅХ⴮ֵєуФтїЙТФїЄКјµчУГPOSTЅУїЪБЛ
#### POSTОДХВ
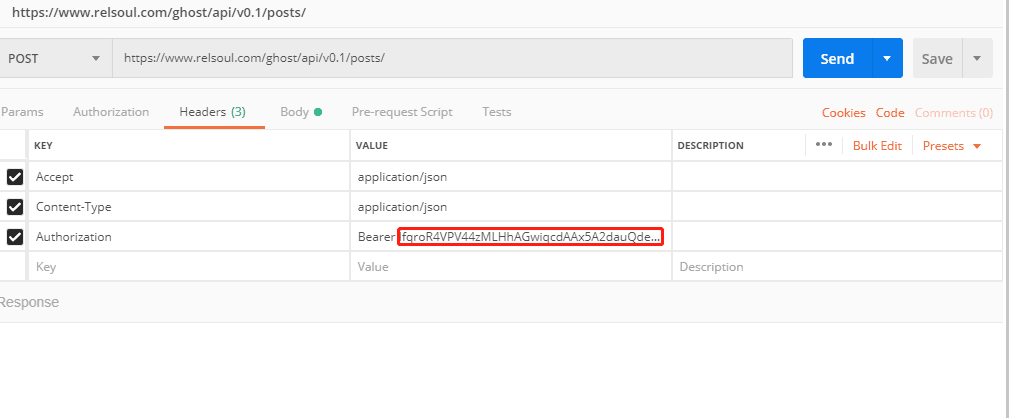
`Authorization`ЧЦ¶ОХвАпµД»°З°ГжµДЧЦ·ыґ®КЗ№М¶ЁµД`Bearer <access-token>`,ЅУЧЕїґBODYХвПо
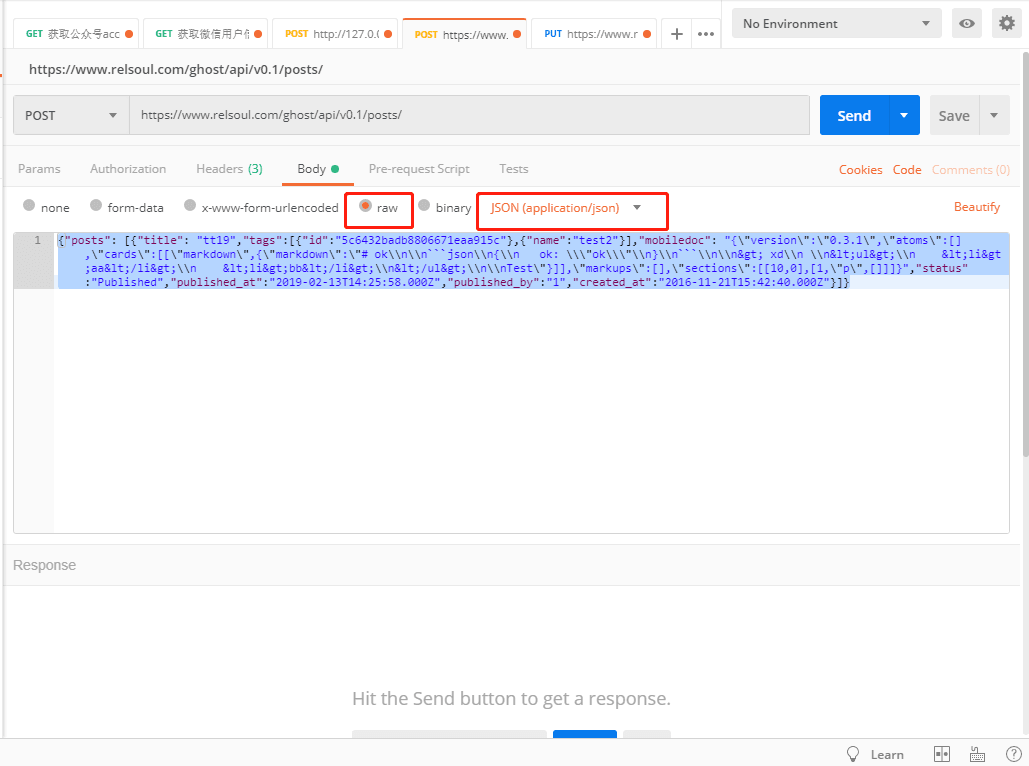
ОТ°СJSONµҐ¶АДГіцАґЛµБЛ
```
{
"posts":[
{
"title":"tt19", // ОДХВµДtitle
"tags":[ // tags±ШРлОЄґЛёсКЅ,їЙТФКЗѕЯМеtagµДid,ТІїЙТФКЗОґґжФЪtagµДname,»бЧФ¶ЇёшДгРВЅЁµД,ОТНЖјцУГ{name:xxx} АґЧцЙПґ«
{
"id":"5c6432badb8806671eaa915c"
},
{
"name":"test2"
}
],
"mobiledoc":"{"version":"0.3.1","atoms":[],"cards":[["markdown",{"markdown":"# ok\n\n```json\n{\n ok: \"ok\"\n}\n```\n\n> xd\n \n<ul>\n <li>aa</li>\n <li>bb</li>\n</ul>\n\nTest"}]],"markups":[],"sections":[,]]}",
"status":"published", // ЙиЦГЧґМ¬ОЄ·ўІј
"published_at":"2019-02-13T14:25:58.000Z", // ·ўІјК±јд
"published_by":"1", // Д¬ИПОЄ1ѕНРР
"created_at":"2016-11-21T15:42:40.000Z" // ґґЅЁК±јд
}
]
}
```
µЅБЛХвАп»№УРТ»ёц±ИЅПЦШТЄµДЧЦ¶ОѕНКЗ`mobiledoc`,¶Ф,МбЅ»І»КЗmarkdown,ТІІ»КЗhtml,¶шКЗТЄ·ыєП(https://github.com/bustle/mobiledoc-kit)№ж·¶µД,ОТТ»їЄКјТІгВ±ЖБЛ,ТФОЄРиТЄОТµчУГґЛїв°СmarkdownФЩЧЄТ»ґО,єуАґ·ўПЦКЗОТПлёґФУБЛ,ЖдКµЦ»РиТЄ
```
{
"version": "0.3.1",
"atoms": [],
"cards": [["markdown", {"markdown": markdown}]],
"markups": [],
"sections": [, ]]
};
```
°ґХХХвЦЦёсКЅЖґЧ°Т»ПВ,±дБї`markdown`КЗЧЄ»»іцАґµДmarkdown,ЖґЅУєГєу**ЗРјЗ**ЧЄОЄJSONЧЦ·ыґ®`JSON.stringify(mobiledoc)`,ДЗГґБЛЅвБЛМбЅ»ёсКЅµИ,ЅУПВАґѕНїЙТФїЄКјРґґъВлБЛ
#### NODEJSМбЅ»ОДХВ
```
async function postBlog({markdown, title, tags, time}) {
const mobiledoc =
{
"version": "0.3.1",
"atoms": [],
"cards": [["markdown", {"markdown": markdown}]],
"markups": [],
"sections": [, ]]
};
var options = {
method: 'POST',
uri: 'https://www.relsoul.com/ghost/api/v0.1/posts/',
body: {
"posts": [{
"title": title,
"mobiledoc": JSON.stringify(mobiledoc),
"status": "published",
"published_at": time,
"published_by": "1",
tags: tags,
"created_at": time,
"created_by": time
}]
},
headers: {
Accept: "application/json",
"Content-Type": "application/json",
Authorization: "Bearer token"
},
json: true // Automatically stringifies the body to JSON
};
const res = await rp(options);
if (res['posts']) {
console.log('ІеИліЙ№¦', title)
} else {
console.error('ІеИлК§°Ь', res);
}
}
```
# ЅбОІ
[ЧоЦХіЙ№ыІОїјBlog](http://relsoul.com)
[ФґґъВлGitHub](https://github.com/Relsoul/migrate-blog) :lol лл°жЦчґуґу, ±ѕИЛЧоЅьґтЛгЧцТ»ПµБРХл¶ФУЪjs/nodejs/webПµБРµДКµХЅЅМіМ,ПЈНыДЬ№»ФЪЅсДк°СХвёцflagёшІ№ЙП 2333
Ті:
[1]