【数据结构与算法】【笔记】简单了解哈希表
# 什么是哈希表**哈希表** 是 **Hash Table** 一词的中文翻译,算法书里通常称这种数据结构为「散列表」。之所以称之为 **散列表** 和这种数据结构的存储方式有关,每个按序进入的数据经过 **散列函数** 的计算后会无序的分布在哈希表不同的位置,这是与数组、链表等有序结构所不同的。
***哈希表实际上是数组的一种扩展***。在哈希表中通过 **哈希函数** 我们可以将数字、字符串等数据中比较有代表性的数据作为 **键值** 转换成数组的 **索引**,在数组中存储 **键值** 代表的数据。而通过 **哈希函数** 转化的数组索引我们称之为 **散列值**(也称哈希值),键值与哈希值转换的过程我们称之为 **散列函数**(即 **哈希函数**)。
**哈希表的优点**
- 可以像数组一样通过下标随机访问。
-弥补了数组只能通过整数索引访问的缺陷。
**哈希表的缺点**
- 每次存取数据之前要通过散列函数计算对应的散列值,消耗了更多内存。
**装载因子** 是散列表性能的衡量标准之一。因为散列表实际上还是数组,所以能承载的数据是有限的,当哈希表存储的数据超过数组索引的长度时则必然会出现散列冲突。
装载因子的计算公式:
> 装载因子 = 散列表元素个数 / 散列表长度。
通常,当装载因子大于 0.75 时,我们需要扩容我们的散列表重新计算散列值。
## 应用场景
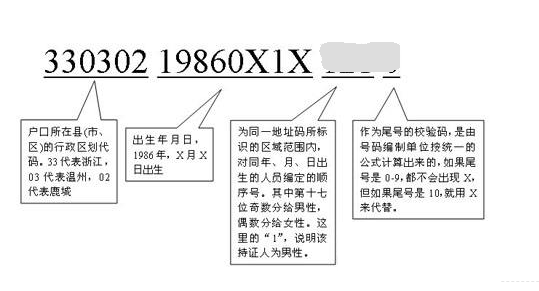
**在 13 亿人中,公安系统快速的查找某一身份证(通常为 18 位数字)信息** 可以通过哈希表的来处理。首先根据身份证的前 6 位找到对应的省份区县信息(可以是哈希表,可以是数组),再根据剩下 13 位信息制作哈希表,合理的选定计算散列值的数,可以以身份证后 8 位来生成(前 8 位出生日期容易重复易形成 **散列冲突**)散列值。因为身份证是整数形式的(X 代表 10),我们假设 1 个区县的人数在 100 万人以内则 100 万对应的就是散列表的长度。散列函数我们可以用身份证后 8 位除以 100 0000 来生成对应的索引,而散列表中可以存放指向公民身份信息的指针。
而查找每一个身份证号所对应的信息时只要将输入身份证号就可以通过下标在散列表中快速找到公民信息。
在这个案例中采用的就是常见的散列函数生成法 **除留余数法**。常用于整数类型的键值生成特定的散列值。
参考代码(划区县因代码长度没有写出)
```java
import java.util.*;
class Test {
public static void main(String[] args) {
HashTest people = new HashTest();
Scanner in = new Scanner(System.in);
for (int i = 0; i < 3; i++) // 输入个人信息,3 个测试数据
{
String identity = in.next();
String name = in.next();
int age = Integer.parseInt(in.next());
ChinesePerson person = new ChinesePerson(identity, name, age);
people.put(identity, person);// 以身份证为键,person 类为值
}
System.out.print("输入你想要查找的身份证号: ");
String id =in.next();
if (people.containsKey(id) == false)
System.out.println("你要查找的信息不存在");
else {
ChinesePerson result = people.get(id);
System.out.println(
"查找成功," + "居民身份证为:" + result.getIdCard() + ",姓名为:" + result.getName() + ",年龄为:" + result.getAge());
}
}
}
class HashTest {
private ChinesePerson[] hashTable;
private int count;
public HashTest() // 初始化散列表
{
hashTable = new ChinesePerson;
count = 0;
}
private int HashCode(String identity) // 散列函数,除留余数法
{
int key = Integer.valueOf(identity.substring(9, 17)) / 10000;
return key;
}
public void put(String identity, ChinesePerson person) { // 增加键和值,测试案例不做溢出判断
int k = HashCode(identity);
hashTable = person;
count++;
}
public boolean containsKey(String key) { // 判断键值是否存在
int index = HashCode(key);
if (index < 0 || index >= 10000 || count == 0 || hashTable == null)
return false;
return true;
}
public ChinesePerson get(String key) { // 获取键对应的值
if (containsKey(key) == false)
throw new NullPointerException(); // 若不存在则抛出异常
return hashTable;
}
public int size() { // 获取散列表对应的元素个数
return count;
}
}
class ChinesePerson { // 定义类存储身份信息
private String idCard;
private String name;
private int age;
public ChinesePerson(String identity, String name, int age) {
this.idCard = identity;
this.name = name;
this.age = age;
}
public String getIdCard() {
return this.idCard;
}
public void setIdCard(String identity) {
this.idCard = identity;
}
public String getName() {
return this.name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return this.age;
}
public void setAge(int age) {
this.age = age;
}
}
```
**对于非整数类型的键值,通常将其转换成大整数,再采用整数的除留余数法。**
## Java 中的散列函数设计原则
- **键值生成的散列值必须为非负整数**
因为散列值实际为数组的索引所以必须为非负整数
- **同一散列值对应相同的键值**
- **同一键值对应相同的散列值**
## 散列表的冲突
表现:**不同的键值生成了相同的散列值**。
**产生的原因**:
- 散列函数设计的不合理。
- 散列表的容量有限
解决方法:
>对散列表扩容。在装载因子达到一定比例(通常设置为 0.75)时,对散列函数动态扩容,则对应的散列函数也应修改。
>开放寻址法。当出现散列冲突时,新的数据放入散列表中空闲块。可以通过 **线性探测**(按顺序向后遍历空闲区)、**二次探测**、**双重散列** 等方法实现。
>拉链法。以链表的形式存储冲突的散列表,散列表只记录指向链表的指针,链表中只存放冲突但不重复的元素。 而去 发表于 2019-3-31 12:01
有一点疑问:
“每次存取数据之前要通过散列函数计算对应的散列值,消耗了更多内存。”
通常会让键值的计算简单化,例如:除留余数法。转换成散列表索引后再取值,同比正常的数组存储肯定是消耗了更多的内存。
所以每一种特殊数据结构都有一定的应用场景,数组属于通用类型。
这句话更多的是我主观认识,表述不太准确,感谢指出问题。 有一点疑问:
“每次存取数据之前要通过散列函数计算对应的散列值,消耗了更多内存。”
哈希表消耗内存不是因为在创建表的时候就会需要大量的内存吗?
而每次查找key对应的value计算散列值增加的是计算量,查找耗时,而且在数据量大的时候,这个增加的耗时一般比其他数据结构遍历查找要短的多。 讲得很清楚,以前学哈希看不懂,网上百度搜的内容也是一头雾水,这个讲的很明白,例子也很好理解 收藏学习了 正好在学习数据结构收藏一一波感谢楼主 隔行如隔山,看了后有收益。 Bflgh 发表于 2019-3-26 20:56
讲得很清楚,以前学哈希看不懂,网上百度搜的内容也是一头雾水,这个讲的很明白,例子也很好理解
明白哈希表和数组之间的关系就很好理解了 感谢楼主分享 收藏学习了,感谢楼主分享
页:
[1]
2