【笔记】字符串匹配基础入门
# BF 暴力匹配法**BF(Brute - Force) 暴力匹配算法**,是字符串匹配算法中最基础,也是最常用的算法。
>BF算法,即暴风(Brute Force)算法,是普通的模式匹配算法,BF算法的思想就是将目标串S的第一个字符与模式串T的第一个字符进行匹配,若相等,则继续比较S的第二个字符和 T的第二个字符;若不相等,则比较S的第二个字符和T的第一个字符,依次比较下去,直到得出最后的匹配结果。BF算法是一种蛮力算法.
在字符串匹配中,将源字符串称之为 **主串** ,需要匹配的子串称之为 **模式串** 。
例:在 source 字符串的子串中查找是否有 target 字符串一样的。 source 就是 **主串**,target 就是 **模式串**。
**而任意 m 大小的主串,只有 m-n+1 个大小为 n 的子串**。(注:这里的子串并非是指主串中的元素组合、而是指主串中连续的某一段)
参考代码
```java
// source 是主字符串、target 是要匹配的模式串
public boolean bruteForce(String source, String target) {
// BF 字符串暴力匹配算法,从源字符串的第 1 个字母开始和 target1 首字母比较,若相等则依次向后比较
// 不相等则再寻找下 1 相同字母索引
boolean result = false;
int len = source.length() - target.length()+1; // 最多需要比较的次数
int subStrLen = target.length();
for (int i = 0; i < len; i++) {
if (source.charAt(i) == target.charAt(0)) {
result = source.substring(i, i + subStrLen).contentEquals(target);
if (result == true)
return true; // 当出现相等模式串时返回 true
}
}
return false;
}
```
思路:遍历主串,在找到第 1 个与模式串首字母相同的字符时,开始匹配,若不一致,则在主串中寻找下一个匹配字符。
从算法的时间复杂度来看 **BF 暴力匹配算法** 的时间复杂度是 O( M*N ),M 为主串长度,N 为模式串长度。属于复杂度比较高的算法,但是因为写法简单,不宜出错,所以最为常用,后续的 **所有的字符串匹配算法其实就是对 BF 算法的优化**。
# RK 算法
RK 算法全名为:Rabin-Karp,由两位创始人的名字组成
思路:把主串中的 M-N+1 个子串生成哈希值,再让模式串生成哈希值,当子串和模式串生成的哈希值一致时,我们再比较子串和模式串是否一致(存在哈希冲突的可能性),一致则匹配成功,不一致则继续在子串中查找。
```java
public boolean RK(String source,String target) {
int len = source.length()-target.length()+1;
int tarLen= target.length();
int targetValue=hashValue(target);
String tempStr;
for(int i=0;i<len;i++)
{
tempStr=source.substring(i,i+tarLen);
// 注意字符串不能直接用 == 比较,因为 == 比较的是两个字符串是否引用同一对象
if(hashValue(tempStr)==targetValue&&tempStr.contentEquals(target))
return true;
}
return false;
}
public int hashValue(String str) { // 哈希函数
int value=0;
int len = str.length();
for(int i=0;i<len;i++)
{
value+=str.charAt(i)-'a'; // 假设所有的字符都是小写英文字母
}
return value;
}
```
总结,借助哈希算法的思想,RK 算法的时间复杂度大致为 O(M),M 为主串的长度。但是因为字符串可能为不同的类型(字符大小写、数值),这会增加哈希函数的复杂度,但是总体来说 **RK 算法** 的效率比 **BF 算法** 的效率更高。
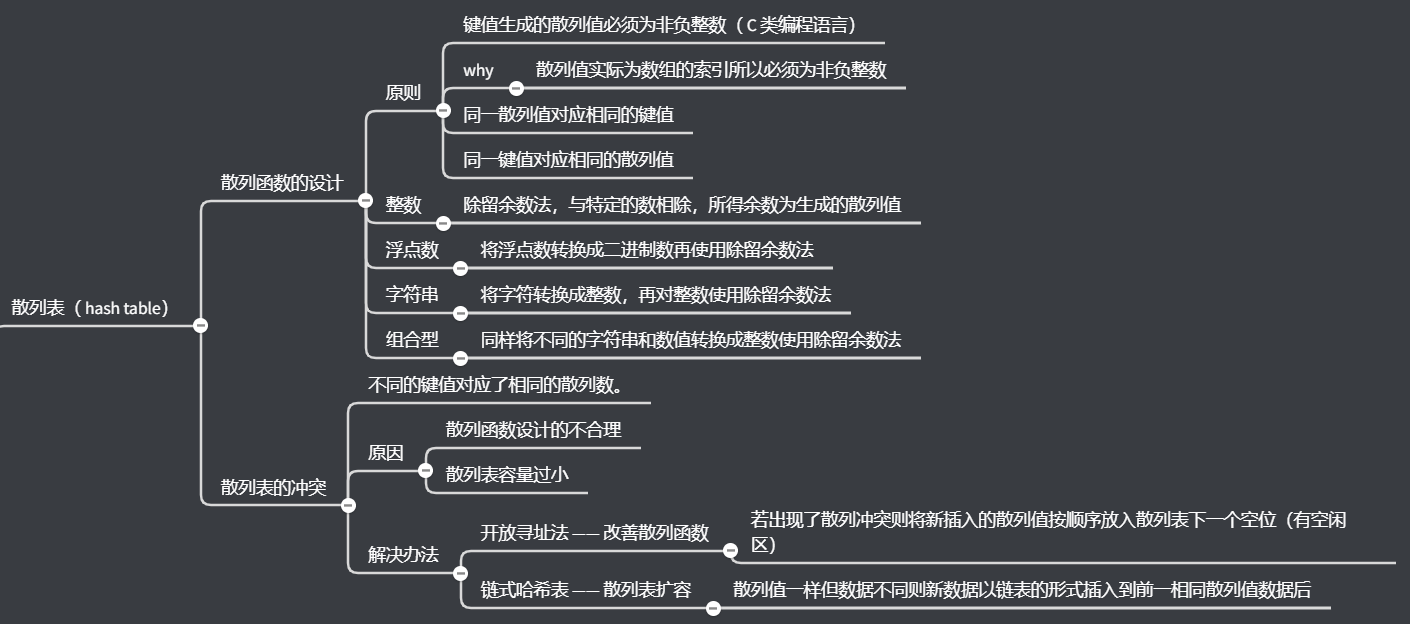
回顾一下散列表的知识点。哈希函数的设计主要还是采用了「除留余数法」,将各种类型先转换成整数再放入散列数组。
页:
[1]