[Python] 纯文本查看 复制代码 from lxml import etree
from time import sleep
from datetime import date
import requests
import os
class Picture():
#存放属性
def __init__(self) -> None:
# self.url='https://wallhaven.cc/search?q=id%3A1&categories=110&purity=100&atleast=3440x1440&sorting=random&order=desc&seed=pisTch&page='
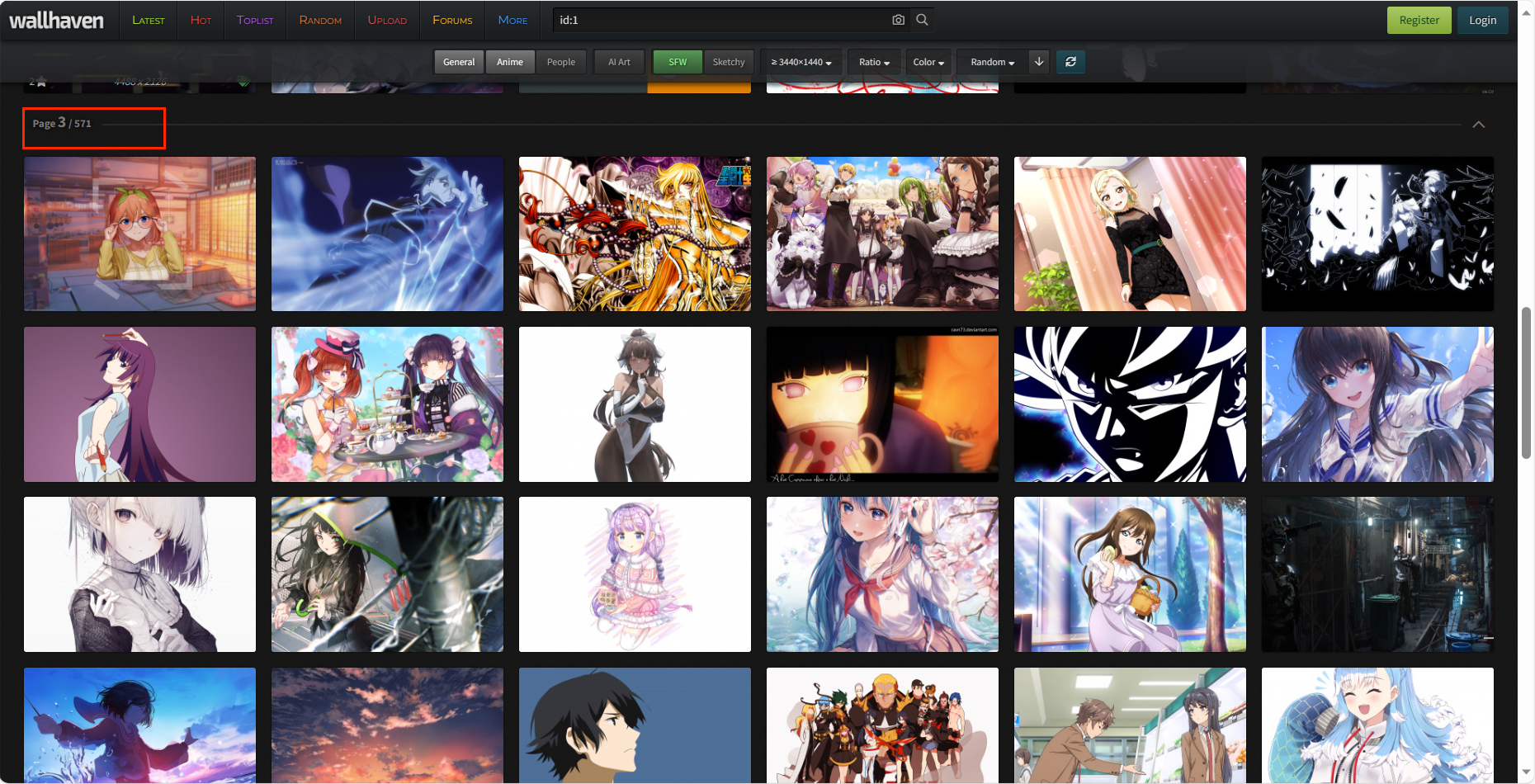
self.url='https://wallhaven.cc/search?categories=011&purity=110&sorting=date_added&order=desc&ai_art_filter=0&page=' #可根据需求更改
self.headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.57'}
#访问目标网站
def gets(self,url_page):
url=self.url+str(url_page) #构造每一页的网址
reponse=requests.get(url=url,headers=self.headers)
return reponse.content #返回响应内容
#解析存储数据
def download_data(self,data,page,date):
data=data.decode().replace("<!--","").replace('-->','')
html=etree.HTML(data)
el_list=html.xpath('//*[@id="thumbs"]/section/ul/li/figure/a/@href') #获取一页所有图片封面的链接,存放在列表中
data_list=[]
picture_num=0
for i in el_list:
picture_num+=1
image_reponse=requests.get(i).content #通过链接访问每张图片主页内容
image_reponse=image_reponse.decode().replace("<!--","").replace('-->','')
html_=etree.HTML(image_reponse)
url_image=html_.xpath('//*[@id="wallpaper"]/@src') #获取图片的真实地址
sleep(0.3) #延时防止频繁访问造成服务器反应失败
image=requests.get(url=url_image[0],headers=self.headers) #通过图片地址获取图片数据
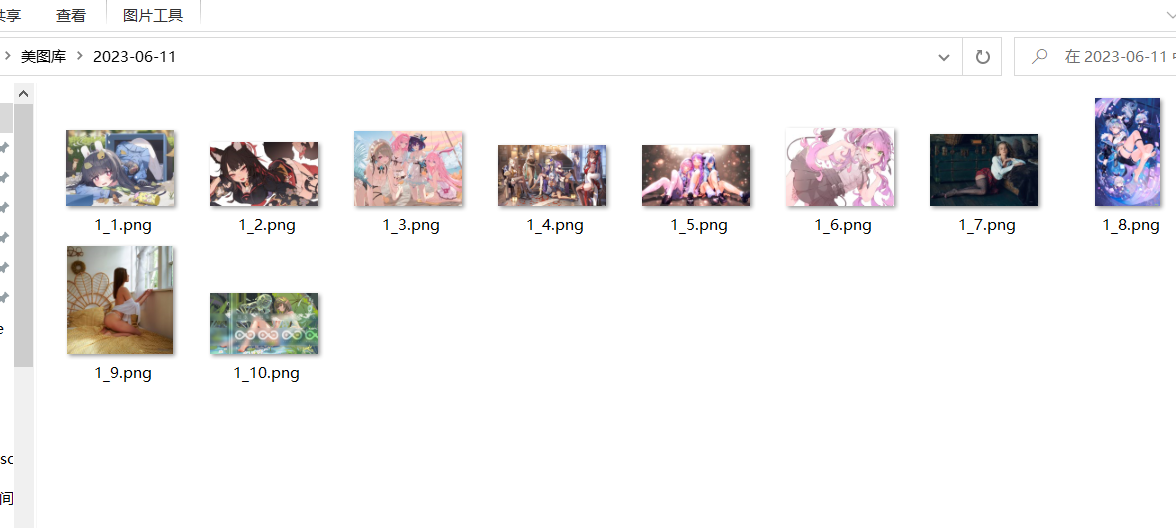
with open(f'.\美图库\{date}\{page}_{picture_num}.png','wb+')as f: #以1_2的形式命名并存储图片
f.write(image.content)
#主程序
def main(self):
first_page=int(input('输入起始页:')) #要获取图片的首页页数
last_page=int(input('输入结束页:')) #要获取图片的最后一页
print('玩命爬取中。。。。。。。')
page=first_page
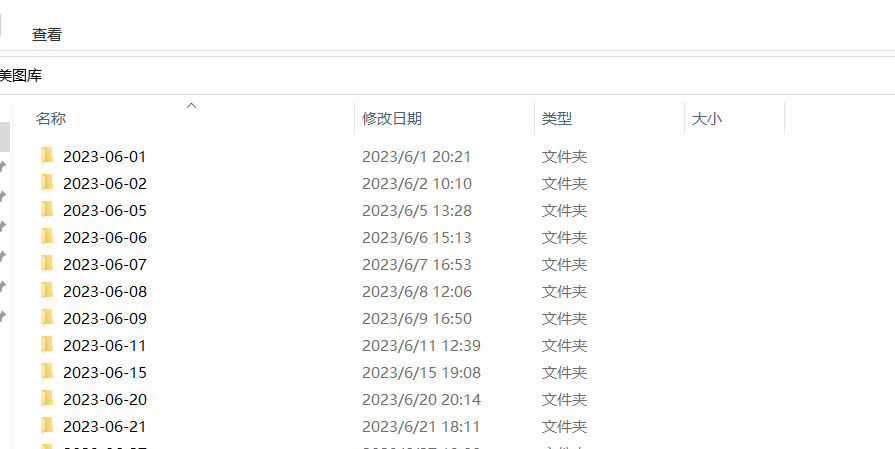
today = date.today() #获取时间,按获取日期给图片分组
user=os.path.expanduser('~')
path_save=os.path.join(user,'Desktop')
os.chdir(path_save) #将存储路径定位在桌面上
try: #生成文件夹
os.makedirs(f'美图库\{today}')
except:
pass
try: #循环获取每一页图片
while page<=last_page:
data=self.gets(page)
self.download_data(data,page,today)
page+=1
except:
print('出现了一些小问题,请检查网络连接和输入内容')
else:
print('任务已完成') #输出运行结果
#创建对象
p1=Picture()
#运行主程序
p1.main() | 
 [复制链接]
[复制链接]
 发表于 2023-6-27 14:21
发表于 2023-6-27 14:21
 |
发表于 2023-6-27 14:43
|
发表于 2023-6-27 14:43





 期待楼主更新代码
期待楼主更新代码

