汇编一维数组
之前的笔记学习过了四种基本类型:char short int long的汇编表示形式
因为它们的数据宽度都小于等于32位,所以都可以只用一个通用寄存器来存储
接下来的数组显然就无法只用一个通用寄存器就可以存储了
在学习数组之前,再学习一个数据类型:long long(__int64),因为它也无法只用一个通用寄存器来存储
PS:本系列笔记目前针对的都是32位,先学好32位再说(●ˇ∀ˇ●)
long long(__int64)
其数据宽度为64位,所以也无法只用一个通用寄存器来存储,通过汇编来看看其存储形式
老规矩,先上代码:
#include "stdafx.h"
unsigned __int64 function(){
unsigned __int64 i=0x1234567812345678;
return i;
}
int main(int argc, char* argv[])
{
unsigned __int64 i=function();
printf( "%I64x\n", i );
return 0;
}
简单解释一下:
写了一个函数,函数直接返回一个unsigned __int64,无符号64位的数据
接收函数返回的数据以后输出
为什么要特地写一个函数来返回数据?
之前的返回数据默认都是保存在eax中的,此时64位的数据一个eax肯定无法存储下,观察此时的数据存储
运行结果:
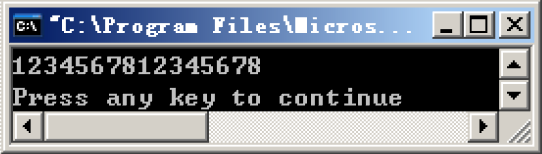
可以看到,能够正常地输出长度为64位的十六进制数
用汇编看看64位的数据是如何存储的
函数外部
16: unsigned __int64 i=function();
0040D708 call @ILT+5(function) (0040100a)
0040D70D mov dword ptr [ebp-8],eax
0040D710 mov dword ptr [ebp-4],edx
17: printf( "%I64x\n", i );
函数内部
7: unsigned __int64 function(){
00401010 push ebp
00401011 mov ebp,esp
00401013 sub esp,48h
00401016 push ebx
00401017 push esi
00401018 push edi
00401019 lea edi,[ebp-48h]
0040101C mov ecx,12h
00401021 mov eax,0CCCCCCCCh
00401026 rep stos dword ptr [edi]
8: unsigned __int64 i=0x1234567812345678;
00401028 mov dword ptr [ebp-8],12345678h
0040102F mov dword ptr [ebp-4],12345678h
9: return i;
00401036 mov eax,dword ptr [ebp-8]
00401039 mov edx,dword ptr [ebp-4]
10: }
0040103C pop edi
0040103D pop esi
0040103E pop ebx
0040103F mov esp,ebp
00401041 pop ebp
00401042 ret
分析
16: unsigned __int64 i=function();
0040D708 call @ILT+5(function) (0040100a)
直接调用函数
函数内部省略保护现场等代码,截取出核心代码:
8: unsigned __int64 i=0x1234567812345678;
00401028 mov dword ptr [ebp-8],12345678h
0040102F mov dword ptr [ebp-4],12345678h
9: return i;
00401036 mov eax,dword ptr [ebp-8]
00401039 mov edx,dword ptr [ebp-4]
10: }
可以发现,i 这个变量存储在了ebp-8 和 ebp-4 中
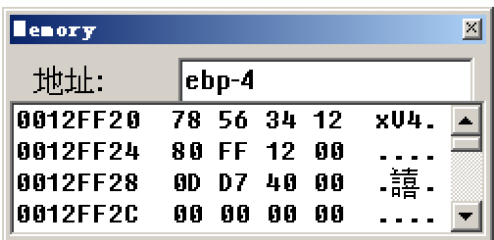
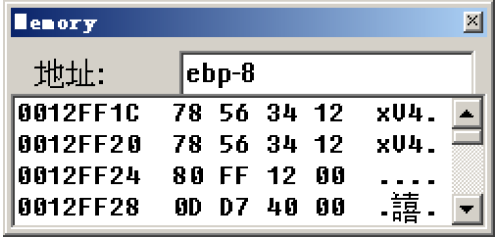
也就是从ebp-8开始连续存储了64位,这里对应的内存地址为12FF1C~12FF24
接着看返回值部分
不难发现返回值分别放在eax和edx两个寄存器中,而不再是原本的eax寄存器
0040D70D mov dword ptr [ebp-8],eax
0040D710 mov dword ptr [ebp-4],edx
17: printf( "%I64x\n", i );
返回后可以看到,就是通过eax和edx来作为参数传递的,验证完毕♪(^∇^*)
数组
研究数组前,先回顾一下之前基本类型的存储
在之前的逆向基础笔记十三 汇编C语言类型转换的小总结里,总结出了char实际上也会转变为int来进行计算(char实际占用的空间大小为4个字节)
为什么编译器要采取这种浪费空间的行为呢?
内存对齐,这里不具体展开,换言之就是为了方便查找数据而选择多花费一些空间,是十分典型的以空间换时间的方法
有关内存对齐的内容可以前往:逆向基础笔记十八 汇编 结构体和内存对齐
数组的空间占用
那么如果是在数组中,char是否还会转变成int呢?
首先查看一个空函数默认分配的空间:
#include "stdafx.h"
void function(){
}
int main(int argc, char* argv[])
{
function();
return 0;
}
13: {
00401050 push ebp
00401051 mov ebp,esp
00401053 sub esp,40h
00401056 push ebx
00401057 push esi
00401058 push edi
00401059 lea edi,[ebp-40h]
0040105C mov ecx,10h
00401061 mov eax,0CCCCCCCCh
00401066 rep stos dword ptr [edi]
14: function();
00401068 call @ILT+5(function) (0040100a)
15: return 0;
0040106D xor eax,eax
16: }
0040106F pop edi
00401070 pop esi
00401071 pop ebx
00401072 add esp,40h
00401075 cmp ebp,esp
00401077 call __chkesp (00401090)
0040107C mov esp,ebp
0040107E pop ebp
0040107F ret
注意看第三行为:sub esp,40h
这里默认提升的堆栈空间为40h,暂且记下
接下来,查看char数组分配的空间
void function(){
char arr[4]={0};
}
00401023 sub esp,44h
可以计算一下:44-40=4,也就是为arr数组分配了4个字节,每个char对应1个字节,并没有按4个字节来占用空间
那么是否在数组中,就是单独为每个char分配一个字节呢?
换个问法:char arr[3]={1,2,3}与char arr[4]={1,2,3,4}哪个更节省空间?
将上面的arr[4]改为arr[3],再观察对应反汇编
void function(){
char arr[3]={0};
}
00401023 sub esp,44h
可以发现,并不是期望中的43h,依旧是44h,实际上不论是数组还是非数组,存储数据时都要考虑内存对齐,在32位的系统中,以4个字节(32位)(本机宽度)为单位,因为在数据宽度和本机宽度一致时,运行效率最高,这也是为什么先前的char会占用4个字节的原因
问题的答案也浮出水面:arr[3]和arr[4]所占用的内存空间是一样的
数组的存储
前面了解了long long(__int64)的存储,再来看看数组是如何存储的,将数组作为返回值传递涉及指针,暂时先略过
#include "stdafx.h"
void function(){
int arr[5]={1,2,3,4,5};
}
int main(int argc, char* argv[])
{
function();
return 0;
}
查看其反汇编
8: int arr[5]={1,2,3,4,5};
0040D498 mov dword ptr [ebp-14h],1
0040D49F mov dword ptr [ebp-10h],2
0040D4A6 mov dword ptr [ebp-0Ch],3
0040D4AD mov dword ptr [ebp-8],4
0040D4B4 mov dword ptr [ebp-4],5
9: }
可以看到存储的方式和前面的__int64相似,从某个地址开始连续存储
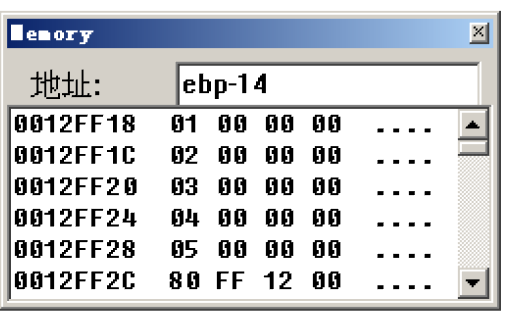
这里就是从ebp-14开始一直存储到ebp,对应内存地址为12FF18~12FF2C
数组的寻址
数组的存储并不复杂,接下来看看如何来找到数组的某个成员
#include "stdafx.h"
void function(){
int x=1;
int y=2;
int r=0;
int arr[5]={1,2,3,4,5};
r=arr[1];
r=arr[x];
r=arr[x+y];
r=arr[x*2+y];
}
int main(int argc, char* argv[])
{
function();
return 0;
}
查看反汇编代码:
8: int x=1;
0040D498 mov dword ptr [ebp-4],1
9: int y=2;
0040D49F mov dword ptr [ebp-8],2
10: int r=0;
0040D4A6 mov dword ptr [ebp-0Ch],0
11: int arr[5]={1,2,3,4,5};
0040D4AD mov dword ptr [ebp-20h],1
0040D4B4 mov dword ptr [ebp-1Ch],2
0040D4BB mov dword ptr [ebp-18h],3
0040D4C2 mov dword ptr [ebp-14h],4
0040D4C9 mov dword ptr [ebp-10h],5
12: r=arr[1];
0040D4D0 mov eax,dword ptr [ebp-1Ch]
0040D4D3 mov dword ptr [ebp-0Ch],eax
13: r=arr[x];
0040D4D6 mov ecx,dword ptr [ebp-4]
0040D4D9 mov edx,dword ptr [ebp+ecx*4-20h]
0040D4DD mov dword ptr [ebp-0Ch],edx
14: r=arr[x+y];
0040D4E0 mov eax,dword ptr [ebp-4]
0040D4E3 add eax,dword ptr [ebp-8]
0040D4E6 mov ecx,dword ptr [ebp+eax*4-20h]
0040D4EA mov dword ptr [ebp-0Ch],ecx
15: r=arr[x*2+y];
0040D4ED mov edx,dword ptr [ebp-4]
0040D4F0 mov eax,dword ptr [ebp-8]
0040D4F3 lea ecx,[eax+edx*2]
0040D4F6 mov edx,dword ptr [ebp+ecx*4-20h]
0040D4FA mov dword ptr [ebp-0Ch],edx
16:
17: }
变量
| 变量 |
变量值 |
变量地址 |
| x |
1 |
ebp-4 |
| y |
2 |
ebp-8 |
| r |
0 |
ebp-0Ch |
按顺序依次分析四种寻址方式
r=arr[1]
12: r=arr[1];
0040D4D0 mov eax,dword ptr [ebp-1Ch]
0040D4D3 mov dword ptr [ebp-0Ch],eax
当给定了指定的数组下标时,编译器能够直接通过下标定位到数组成员的位置,获取到数据
r=arr[x]
13: r=arr[x];
0040D4D6 mov ecx,dword ptr [ebp-4]
0040D4D9 mov edx,dword ptr [ebp+ecx*4-20h]
0040D4DD mov dword ptr [ebp-0Ch],edx
当给定的数组下标为变量时:
-
先将变量x赋值给ecx
-
然后通过ebp+ecx*4-20h定位到对应的数组成员,并赋值给edx
这里的4对应数组类型int的数据宽度,如果是short类型则为*2
先省去ecx不看,则为ebp-20h对应的是第一个数组成员
然后+ecx*4,就是加上偏移得到对应的数组成员
-
最后再把edx赋值给r
r=arr[x+y]
14: r=arr[x+y];
0040D4E0 mov eax,dword ptr [ebp-4]
0040D4E3 add eax,dword ptr [ebp-8]
0040D4E6 mov ecx,dword ptr [ebp+eax*4-20h]
0040D4EA mov dword ptr [ebp-0Ch],ecx
当给定的数组下标为变量的加法算式时:
先计算出算式的结果
0040D4E0 mov eax,dword ptr [ebp-4]
0040D4E3 add eax,dword ptr [ebp-8]
然后和上面一样,通过ebp+eax*4-20h定位数组成员
0040D4E6 mov ecx,dword ptr [ebp+eax*4-20h]
最后再把ecx赋值给r
0040D4EA mov dword ptr [ebp-0Ch],ecx
r=arr[x*2+y]
15: r=arr[x*2+y];
0040D4ED mov edx,dword ptr [ebp-4]
0040D4F0 mov eax,dword ptr [ebp-8]
0040D4F3 lea ecx,[eax+edx*2]
0040D4F6 mov edx,dword ptr [ebp+ecx*4-20h]
0040D4FA mov dword ptr [ebp-0Ch],edx
当给定的数组下标为变量的较复杂算式时:
依旧是先计算出算式的结果
0040D4ED mov edx,dword ptr [ebp-4]
0040D4F0 mov eax,dword ptr [ebp-8]
0040D4F3 lea ecx,[eax+edx*2]
然后和上面一样,通过ebp+ecx*4-20h定位数组成员
0040D4F6 mov edx,dword ptr [ebp+ecx*4-20h]
最后再把edx赋值给r
0040D4FA mov dword ptr [ebp-0Ch],edx
数组越界的应用
先写一个普通的越界程序
#include "stdafx.h"
void function(){
int arr[5]={1,2,3,4,5};
arr[6]=0x12345678;
}
int main(int argc, char* argv[])
{
function();
return 0;
}
运行结果:
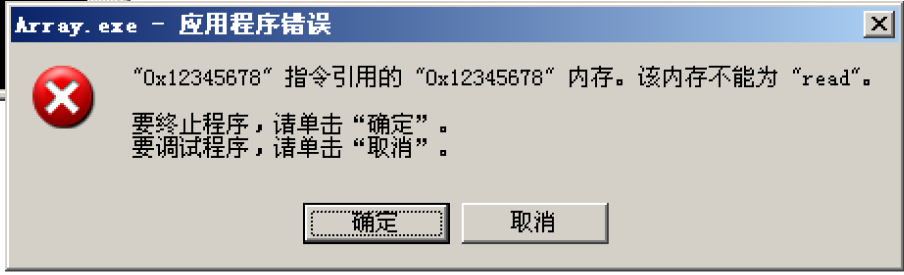
不出意料,程序报错了,同时可以发现,程序出错的原因是访问了不能访问的内存0x12345678,也就是我们给arr[6]赋值的内容,接下来从汇编的角度观察出错的原因:
函数外部
17: function();
00401068 call @ILT+5(function) (0040100a)
18: return 0;
0040106D xor eax,eax
19: }
0040106F pop edi
00401070 pop esi
00401071 pop ebx
00401072 add esp,40h
00401075 cmp ebp,esp
00401077 call __chkesp (00401090)
0040107C mov esp,ebp
0040107E pop ebp
0040107F ret
函数内部
7: void function(){
0040D480 push ebp
0040D481 mov ebp,esp
0040D483 sub esp,54h
0040D486 push ebx
0040D487 push esi
0040D488 push edi
0040D489 lea edi,[ebp-54h]
0040D48C mov ecx,15h
0040D491 mov eax,0CCCCCCCCh
0040D496 rep stos dword ptr [edi]
8: int arr[5]={1,2,3,4,5};
0040D498 mov dword ptr [ebp-14h],1
0040D49F mov dword ptr [ebp-10h],2
0040D4A6 mov dword ptr [ebp-0Ch],3
0040D4AD mov dword ptr [ebp-8],4
0040D4B4 mov dword ptr [ebp-4],5
9: arr[6]=0x12345678;
0040D4BB mov dword ptr [ebp+4],12345678h
10:
11: }
0040D4C2 pop edi
0040D4C3 pop esi
0040D4C4 pop ebx
0040D4C5 mov esp,ebp
0040D4C7 pop ebp
0040D4C8 ret
可以看到越界的那部分语句对应为:
9: arr[6]=0x12345678;
0040D4BB mov dword ptr [ebp+4],12345678h
那么ebp+4存储的内容是什么?
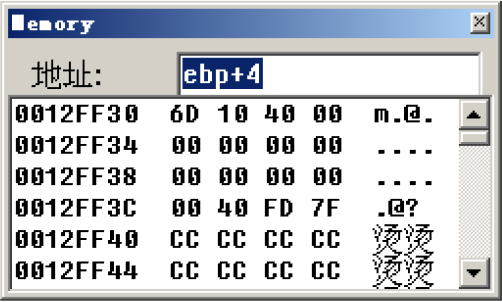
ebp+4存储的内容为一个地址0040106D
这个地址对应为:
17: function();
00401068 call @ILT+5(function) (0040100a)
18: return 0;
0040106D xor eax,eax
19: }
就是call调用结束后的返回地址
分析可知,越界语句将函数的返回地址给覆盖成了0x12345678,导致无法正常返回,因此引发了错误
看到这里,发现通过数组越界可以覆盖返回地址后,便可以来搞搞事情了
通过数组越界向函数内插入其它函数
#include "stdafx.h"
int addr;
void HelloWorld(){
printf("Hello World!\n");
__asm{
mov eax,addr
mov dword ptr [ebp+4],eax
}
}
void function(){
int arr[5]={1,2,3,4,5};
__asm{
mov eax,dword ptr [ebp+4]
mov addr,eax
}
arr[6]=(int)HelloWorld;
}
int main(int argc, char* argv[])
{
function();
__asm{
sub esp,4
}
return 0;
}
运行结果:
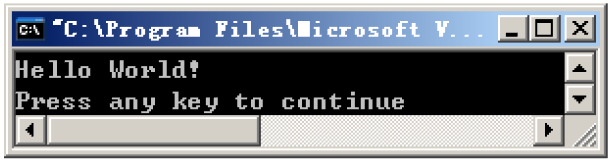
发现程序能够正常运行,并且输出了Hello World!
接下来解释一下代码的几处地方:
void function(){
int arr[5]={1,2,3,4,5};
__asm{
mov eax,dword ptr [ebp+4]
mov addr,eax
}
arr[6]=(int)HelloWorld;
}
首先是function函数,这个函数中,首先将ebp+4的地址保存到addr里,也就是将原本的返回地址备份
下面的arr[6]=(int)HelloWolrd则是将函数的返回地址修改为了自己写的HelloWorld函数
让代码去执行HelloWorld函数的内容
接着看HelloWorld函数
void HelloWorld(){
printf("Hello World!\n");
__asm{
mov eax,addr
mov dword ptr [ebp+4],eax
}
}
输出Hello Wolrd后,将先前备份的函数地址赋给ebp+4,让函数能够返回到原本的地址
最后是main函数
int main(int argc, char* argv[])
{
function();
__asm{
sub esp,4
}
return 0;
}
main函数在调用完function函数后,要加上sub esp,4来自行平衡堆栈,因为先前的通过数组越界来调用其它函数使得堆栈不平衡,需要手动修正平衡,否则main函数里的__chkesp会报错
36: function();
0040D4D8 call @ILT+5(function) (0040100a)
37: __asm{
38: sub esp,4
0040D4DD sub esp,4
39: }
40: return 0;
0040D4E0 xor eax,eax
41: }
0040D4E2 pop edi
0040D4E3 pop esi
0040D4E4 pop ebx
0040D4E5 add esp,40h
0040D4E8 cmp ebp,esp
0040D4EA call __chkesp (00401090) 这里会检查堆栈是否平衡
0040D4EF mov esp,ebp
0040D4F1 pop ebp
0040D4F2 ret
如不修正,会报错:
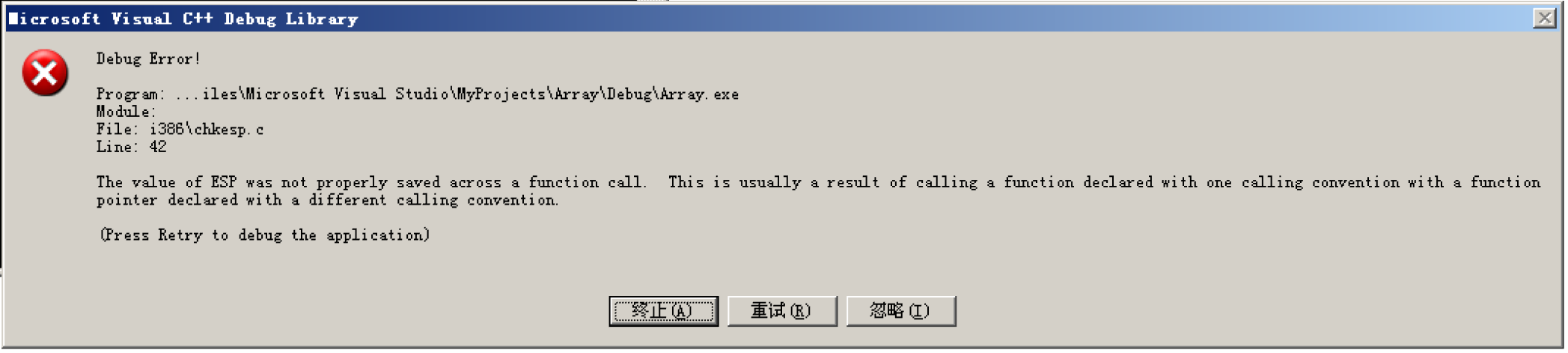
总结
数组的存储在内存中是连续存放的
无论是数组还是基本类型的存储都需要以内存对齐的方式来存储
数组的寻址方式大体可分为两种:
- 直接通过下标找到对应的数组成员
- 间接通过变量来找到数组成员:先找到数组的第一个成员,然后加上变量 × 数据宽度得到数组成员
数组越界可以覆盖函数原本的返回地址,以此来向函数中插入其它函数,但注意要平衡堆栈

 [复制链接]
[复制链接]
 发表于 2021-3-4 16:06
发表于 2021-3-4 16:06



 应该是:将变量x赋值给ecx
应该是:将变量x赋值给ecx

