简单聊聊旋转验证码攻防
旋转验证码:给定一张旋转后的图像,要求用户拖动滑块将其旋转状态复原,目前某度验证码就是用的这个。
搜了一下,好像没人写过这个方向的文章,我就来补个漏。
惯例先上本人写的开源仓库lumina37/rotate-captcha-crack,里面包含大名鼎鼎的d4nst/RotNet的PyTorch实现,还顺便用aiohttp写了个简单的http服务端。
一年过去再次更新:本人没有进厂,最后努力了几个月考上了清深,这个项目在复试的时候提供了不小的帮助。

bb之前再来点干货,列举一些目前有参考价值(可训练or使用已有模型提供脚本思路)的开源仓库,重点部分都有加粗
| 仓库名与链接 |
框架 |
主干 |
任务类型 |
最后更新时间 |
star |
备注 |
| d4nst/RotNet |
keras(2.3)+tensorflow(2.0) |
ResNet50 |
分类 |
2021.09 |
497 |
元始天尊 |
| rotate-captcha-crack |
torch(1.11+) |
RegNetY 3.2GFLOPs |
分类 |
2024.09 |
292 |
介绍过了,略 |
| RotateCaptchaBreak |
keras(2.3)+tensorflow(2.0) |
ResNet50 |
分类 |
2021.07 |
194 |
提供了一些验证码样本 |
| cnn_for_captcha |
tensorflow(2.9.1) |
ResNet50 |
回归 |
2023.05 |
111 |
魔改的RotNet,也使用均方误差做回归,收敛快但效果差 |
| simple_ocr |
keras(2.7)+tensorflow(2.7) |
ResNet50 |
分类 |
2022.11 |
95 |
实现了一个Django同步IO服务端并有在线demo |
| ZJCV/RotNet |
torch(1.7.1) |
MobileNet_v3_small |
分类 |
2021.04 |
20 |
代码质量不错但需要针对新版本torch做一定适配,而且数据集也要从Fs.-MNIST换成谷歌街景 |
| *aiduRotateCode |
keras(2.7)+tensorflow(2.7) |
ResNet50 |
分类 |
2022.01 |
2 |
有一些selenium脚本 |
攻法 - 旋转角判断
旋转角判断是旋转验证码破解流程的关键。
imghash
这个方法有点邪门。最早于2020年12月被提出,参考链接。建数据库的阶段要先把验证码图片的库脱了,然后手工逐个复原,最后在每个旋转角上计算一次图像的相似hash。
补充知识点:图像的相似hash被广泛应用于判断两张图像的相似性。imghash基于像素值,而文件hash基于原始字节流。几个字节/像素点的变化会在文件hash上引起剧烈变化,但只会在imghash上引起微小变化,这和人眼的直观感受是一致的。
在工作阶段,每接收到一个验证码图片就计算出它的imghash再到数据库比对,匹配出最近邻的那个hash就能知道旋转角了。
虽然说曾经的某度因为版权限制导致库很小,脱个库就能轻松解决问题,但现在他们的库不仅更大了还加了鬼影噪声,这个办法也就基本没用了。
CNN
卷积神经网络,2018年就有人开始研究这个方法,也就是上文提到的d4nst/RotNet,这也依然是目前最有效的攻法。
从守方角度来说,旋转验证码是一种相当廉价的验证码。那么对于攻方而言,用深度学习去破解它的成本也是极低的,因为对于其他训练任务而言最昂贵的数据集成本,在自监督(就是不需要人工标注)学习这里几乎为0。
RotNet的实现思路很简单,将旋转角预测视作一个360分类的任务,ResNet50提取出特征向量,然后全连接得到一个长度为360的分类编码,哪个位置值最大就取那个位置的下标作为旋转角。
补充知识点:ResNet50是一种网络结构;全连接就是在两个层的节点两两之间拉一根带权连接,后面的训练就是要训这个权重的大小。
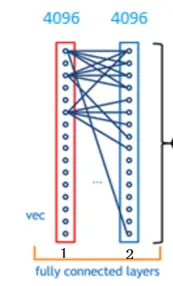
思路so easy,我们再来聊聊细节问题。
RotNet中的一些致命细节
小心旋转!
一旦涉及到仿射变换(旋转也是一种仿射变换),我们就不得不考虑插值导致的图像质量损失。在还原RotNet的过程中,有一个点很容易被遗漏,我也是今天早上技术交流的时候才发现。
这里直接引用一段d4nst所写的教程(DeepL机翻+微调):
在展示训练代码之前,我想指出我们数据生成方法中的一个具体问题。当旋转角度不是90、180或270度时,旋转操作涉及到像素内插。在低分辨率下,这可能会引入内插伪影,而这些伪影可能会被网络学习。如果发生这种情况,当这些伪影不存在时,网络将无法预测旋转角度,例如原始图像已经被旋转过或者是在更高的分辨率下被旋转过的情况。
简单来说,针对高分辨率图像我们应当先做旋转再做裁切缩放,以减少插值产生的相对噪声,尽管这种操作顺序会比先裁切缩放再旋转更昂贵。
改进RotNet
one-hot编码与交叉熵损失
one-hot,就是只有目标位置的那一个点取值为1(0就是不热,1就是热)。举个例子,旋转角为2°时对应的one-hot编码就是[0,0,1,0,0,0,0,...]。
one-hot编码搭配交叉熵损失就会导致一个问题,那就是1°和2°之间的距离和1°到180°之间的距离居然是一样的。而出于直觉,当预测角度逐渐接近目标值,度量距离也应当随之逐渐减小,进而使得回传梯度更平缓,模型可以稳定在优点。
对于这个问题,我翻看了一些旋转目标识别的论文,其中杨学博士的这篇文章Arbitrary-Oriented Object Detection with Circular Smooth Label (ECCV'20)比较深入地探讨了这个问题。他的解决方案是使用一个以目标位置为中心的正态分布来平滑one-hot编码。举个例子就是把[0,1,0,0]换成[0.1,0.8,0.1,0]。同时文章还指出分类数目过多过少都会导致效果不佳,因此我这里把RotNet中的360分类按照论文的实验结果减少到了128分类。
数据集解耦
RotNet对数据集的解耦不够充分,验证集测试集不分,更换数据集较为麻烦。
这纯属软件工程问题。数据集应当使用组合的方式形成一种管线式的结构,每个部分都可以通过接口抽象来自由替换具体实现。例如我这个数据集的上游可以来自StreetView,可以来自压缩文件,只要你自定义的数据源返回的是三通道浮点图像那么都可以用作我数据管线的上游,这也就是一种AOP。
全连接层破坏空间关系
旋转角判断相当依赖空间关系,而全连接层直接将通道展平,对这种空间关系会有一定的破坏作用,通俗来说就是分不清上下左右了。
是否可以考虑用全卷积网络?这个我暂时还没开始做。
改进回归损失
RotNet的回归损失函数完全没法用。因为他的损失函数是非凸的,画出来长这样

解决方法比较简单,改成SmoothL1Loss就行。
攻法 - js逆向
一搜一箩筐,某度并没有用上vmp所以还算简单。推荐一篇2023*度旋转验证码纯python逆向代码完结
守法 - 鬼影
鬼影就是在旋转图像上随机涂抹大块脏污,其中像素的明度色相饱和度都可能被改变。
说明图是偷的,知乎这个不是我。
用上鬼影之后imghash的攻法全挂,CNN还有一战之力。
攻法 - 适应鬼影
主要手段有两种。
- 数据增强,在输入图像上人为制造鬼影。某度的鬼影感觉就这两种组合——明度+饱和度以及色相+饱和度,因此我们随便挑一个区域去改就行了。
那么这个区域应该怎么生成,我这里给个简单的方法。从左上端点出发,每次步进都往右移动一个像素,过中点之前有75%概率往下移动25%概率往上移动,过中点之后又75%概率往上移动25%概率往下移动,这样就制造了一个能覆盖图像一侧的遮罩,根据这个遮罩去加鬼影就可以了。
- 训练一个可以消解鬼影的Attention Branch,它能观察全局信息并调整鬼影区域的参数,可以设计一个损失函数来最小化带鬼影输入和不带鬼影输入所得到的特征图的度量距离。

守法 - 双旋转
将图片分成内环外环,用户需要将两个环都旋转至正向来通过验证。
(它是如此稀奇以至于我找不到一张示意图)
为什么放到最后,因为目前双旋并没有几个厂会用,旋一次都够烦的更别说旋两次,放在日常接口上用户嫌烦,放在重要接口上强度又不够,上不去下不来就卡在那了,所以我这里只是顺便提一下。
攻法 - 双旋咬合
双旋转有必要研究的点只有如何将内外环咬合,咬合完毕之后就可以用单旋转的思路去完成剩余步骤。
现在涉及双旋转的开源仓库貌似只有ycq0125/rotate_captcha,其主要思路是比对内环外侧和外环内侧的像素色差来实现内外环咬合。
对于内外环切分半径较大的图像,我们还可以改进这种方法的效率。核心思路就是互相关函数。
将内环外侧的像素灰度值沿着圆环提取出来,得到一个长2π*radius的灰度值序列,将这个序列视作序列A;对外环内侧做类似处理,得到其灰度值序列,记作序列B。
由于内环可通过旋转操作与外环咬合,那么A也肯定可以通过平移变成B。而互相关函数corr(x)就是序列B相对序列A右移x距离后二者的相似度。我们直接调包求出互相关序列然后取最大值所在坐标,这个坐标就是待求的平移量。

 [复制链接]
[复制链接]
 发表于 2023-3-5 10:16
发表于 2023-3-5 10:16
 |
发表于 2023-3-5 19:10
|
发表于 2023-3-5 19:10



