Python实现百度贴吧自动签到
本帖最后由 Eureka8 于 2022-8-6 12:57 编辑## 背景
嘿嘿嘿,刷百度贴吧太爽了,但是等级太低在贴吧中发言貌似显得比较萌新,然而除了水贴之外升级最重要一个途径便是签到,关注了很多吧,每天一个一个点签到太麻烦了,怎么才能更方便快速地一次把关注的吧全签到了呢?
## 有了!
百度贴吧签到是POST请求,不如使用Python中的request模块,通过编写一键签到脚本来实现这个需求吧!
## 指定计划!
1. 在"关注的吧”页面中,使用BeautifulSoup模块解析页面,得到所有已经关注的贴吧
2. 通过抓包得到“签到”的请求地址,顺便获取请求头相关信息(User-Agent和Cookies)
3. 编写Python代码,大功告成!
## 开始行动!
### 1.分析得到贴吧“签到”的请求地址
直接到任意一个已经关注的贴吧的主页,打开F12,我使用的是谷歌的调试工具,打开“网络(Network)”标签,开始抓包!
[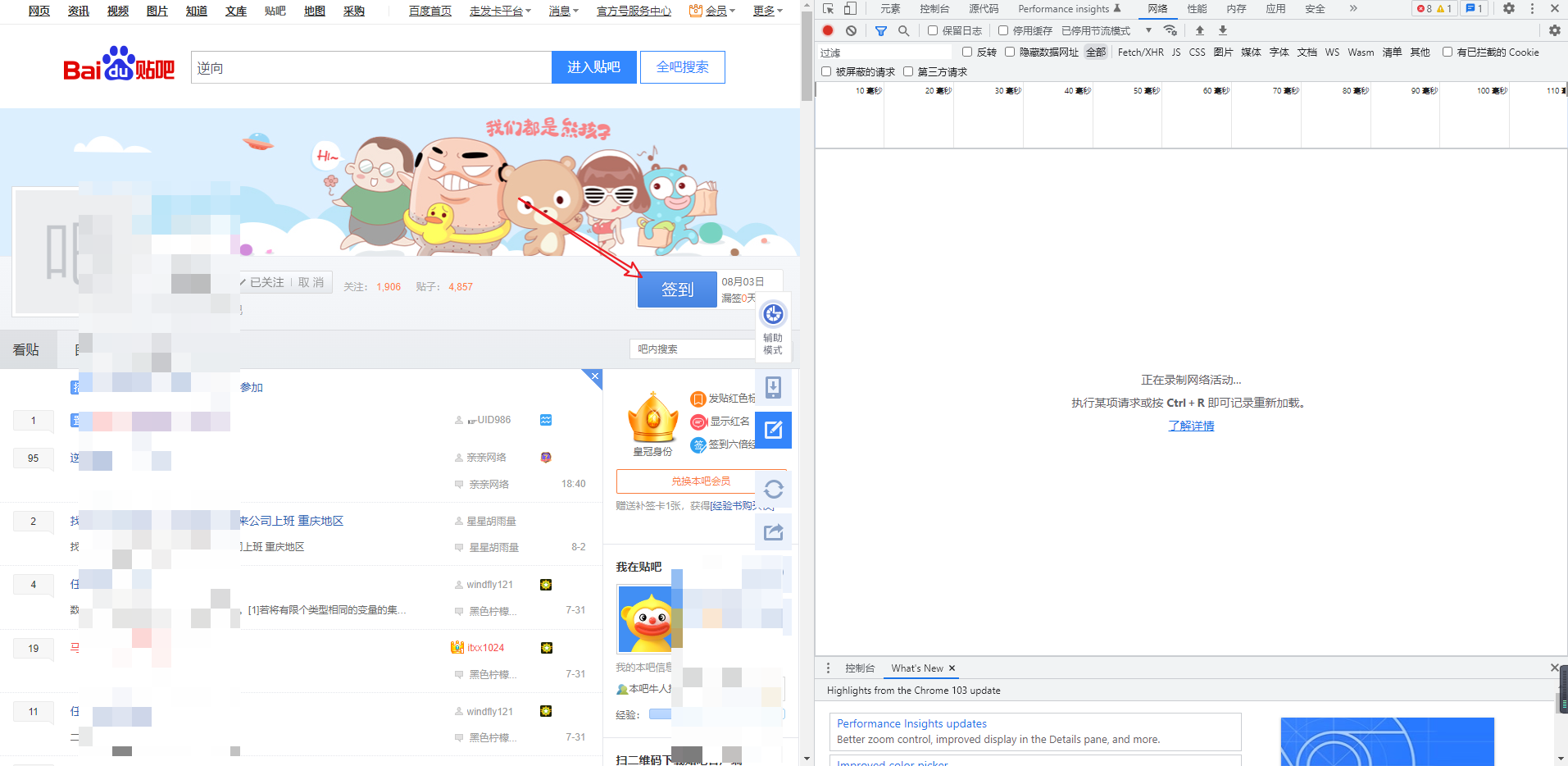](https://s2.loli.net/2022/08/03/kXGZWyH4YIbejDz.png)
点击“签到”按钮,得到POST请求地址和参数
[](https://s2.loli.net/2022/08/03/HGCRbncqNsZhJO9.jpg)
[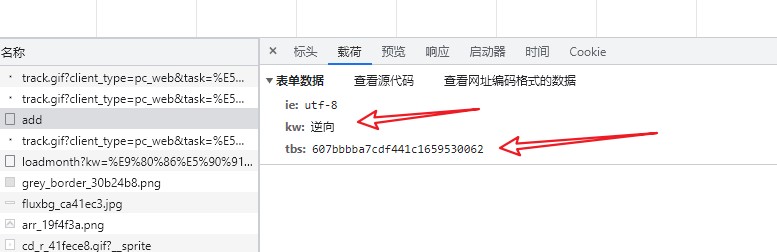](https://s2.loli.net/2022/08/03/bGzuivF8Z5xlmBh.jpg)
有三个参数,“ie”指的就是编码,默认即可,“tw”经过测试发现指的就是贴吧名字,需要添加变量,而这个“tbs”是什么呢?经过测试发现每次都在变,所以先在页面Ctrl+U得到HTML代码,搜索试试!
[](https://s2.loli.net/2022/08/03/SZ1qYOABFGDx4Ct.jpg)
喔,果然搜到了,看来还需要使用一些操作得到这串字符啊!
没关系,交给正则表达式来解决!
[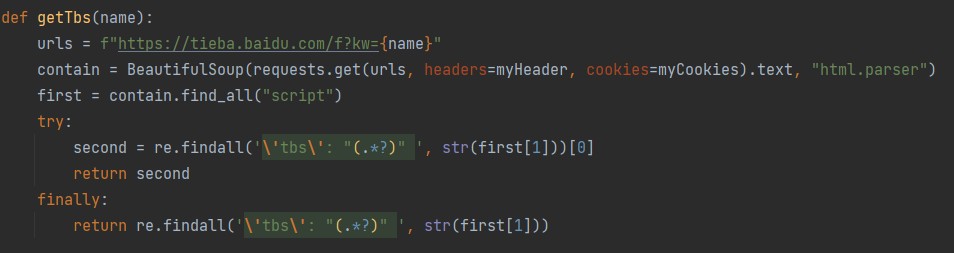](https://s2.loli.net/2022/08/03/RoXlE5S4bKdCZ7M.jpg)
大功告成,模拟签到部分的代码我们就已经编辑好了,只需要知道贴吧名字即可,我们把他封装成函数,变量为贴吧名字,代码如下:
[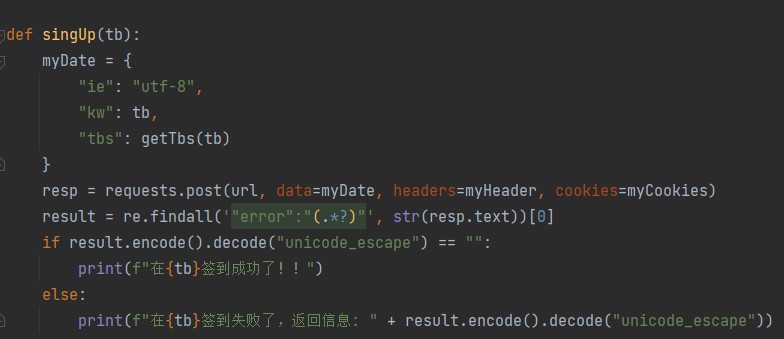](https://s2.loli.net/2022/08/03/WgpLncNajdEIRzY.jpg)
### 2.得到账号下关注的吧,遍历,签到
感谢@百度贴吧官方,为我们提供了 “https://tieba.baidu.com/f/like/mylike” 从而让我们方便地就能看到账户下已经关注的贴吧
[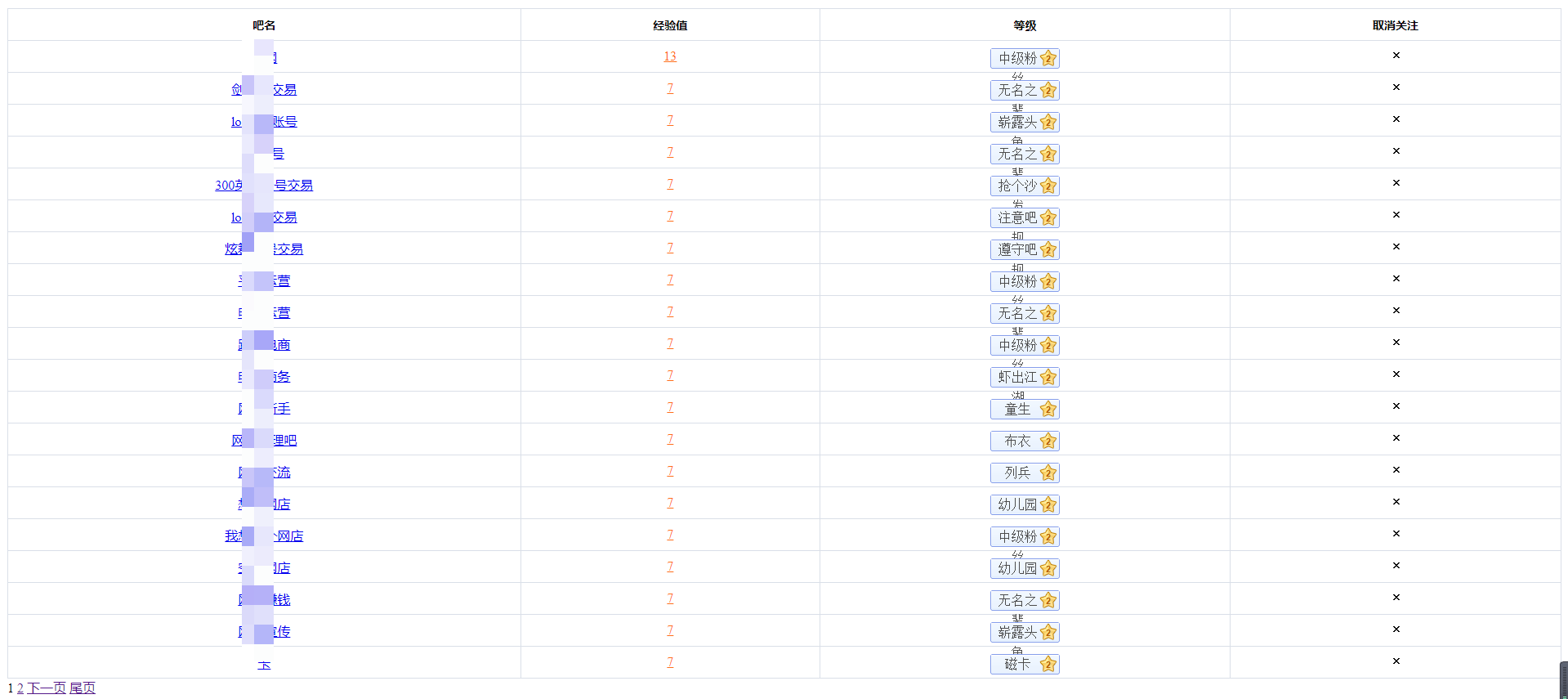](https://s2.loli.net/2022/08/03/L4kJNesjbX9rBG2.png)
F12稍微分析,好家伙,太方便了,直接就是一个列表,一堆\<tr>:
[](https://s2.loli.net/2022/08/03/LlJkmc5DeE1pnPQ.jpg)
此时我们的函数就写出来了(得到关注的吧的名字),我们选择直接遍历,得到名字之后直接签到,这样省时又省力啊!
[](https://s2.loli.net/2022/08/03/DHJSqV4omaxFANM.jpg)
### 大功告成,签到成功!舒服了~
全部代码如下:
```python
import requests
from bs4 import BeautifulSoup
import re
myHeader = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36",
}
myCookies = {
"Cookie": "###"
}
url = "https://tieba.baidu.com/sign/add"
def getTblikes():
i = 0
url = "https://tieba.baidu.com/f/like/mylike"
contain1 = BeautifulSoup(requests.get(url=url, cookies=myCookies, headers=myHeader).text, "html.parser")
pageNum = len(contain1.find("div", attrs={"class": "pagination"}).findAll("a"))
a = 1
while a < pageNum:
urlLike = f"https://tieba.baidu.com/f/like/mylike?&pn={a}"
contain = BeautifulSoup(requests.get(url=urlLike, cookies=myCookies, headers=myHeader).text, "html.parser")
first = contain.find_all("tr")
for result in first:
second = result.find_next("td")
name = second.find_next("a")['title']
singUp(name)
time.sleep(5)
i += 1
a += 1
print(f"签到完毕!总共签到完成{i}个贴吧")
def getTbs(name):
urls = f"https://tieba.baidu.com/f?kw={name}"
contain = BeautifulSoup(requests.get(urls, headers=myHeader, cookies=myCookies).text, "html.parser")
first = contain.find_all("script")
try:
second = re.findall('\'tbs\': "(.*?)" ', str(first))
return second
finally:
return re.findall('\'tbs\': "(.*?)" ', str(first))
def singUp(tb):
myDate = {
"ie": "utf-8",
"kw": tb,
"tbs": getTbs(tb)
}
resp = requests.post(url, data=myDate, headers=myHeader, cookies=myCookies)
result = re.findall('"error":"(.*?)"', str(resp.text))
if result.encode().decode("unicode_escape") == "":
print(f"在{tb}签到成功了!!")
else:
print(f"在{tb}签到失败了,返回信息: " + result.encode().decode("unicode_escape"))
getTblikes()
```
(有部分坛友反馈看不懂,不知道怎么用,有很多人这样吗?到时我看下上传个详细教程或者传一份编译后的exe版本) 本帖最后由 涛之雨 于 2022-8-9 19:42 编辑
牛,看着没执行通 我就给完善了一下
import requests
from bs4 import BeautifulSoup
import re
import time
myHeader = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36",
}
myCookies = {
"Cookie": 'xxxxx'
}
url = "https://tieba.baidu.com/sign/add"
def getTblikes():
i = 0
url = "https://tieba.baidu.com/f/like/mylike"
contain1 = BeautifulSoup(requests.get(url=url, cookies=myCookies, headers=myHeader).text, "html.parser")
if contain1.find("div", attrs={"class": "pagination"}):
pageNum = len(contain1.find("div", attrs={"class": "pagination"}).findAll("a"))
else:
pageNum = 2
a = 1
while a < pageNum:
urlLike = f"https://tieba.baidu.com/f/like/mylike?&pn={a}"
contain = BeautifulSoup(requests.get(url=urlLike, cookies=myCookies, headers=myHeader).text, "html.parser")
first = contain.find_all("tr")
for result in first:
second = result.find_next("td")
name = second.find_next("a")['title']
singUp(name)
time.sleep(5)
i += 1
a += 1
print(f"签到完毕!总共签到完成{i}个贴吧")
def getTbs(name):
urls = f"https://tieba.baidu.com/f?kw={name}"
contain = BeautifulSoup(requests.get(urls, headers=myHeader, cookies=myCookies).text, "html.parser")
first = contain.find_all("script")
try:
second = re.findall('\'tbs\': "(.*?)" ', str(first))
return second
finally:
return re.findall('\'tbs\': "(.*?)" ', str(first))
def singUp(tb):
myDate = {
"ie": "utf-8",
"kw": tb,
"tbs": getTbs(tb)
}
resp = requests.post(url, data=myDate, headers=myHeader, cookies=myCookies)
result = re.findall('"error":"(.*?)"', str(resp.text))
if result.encode().decode("unicode_escape") == "":
print(f"在{tb}签到成功了!!")
else:
print(f"在{tb}签到失败了,返回信息: " + result.encode().decode("unicode_escape"))
getTblikes() bulia 发表于 2022-8-9 13:44
牛,看着没执行通 我就给完善了一下
import requests
from bs4 import Beautif ...
大兄嘚,你cookie都敢乱放啊。。。我给你编辑掉了 谢谢分享,楼主这是要帮百度贴吧做接口自动化测试吗,哈哈哈 #在楼主基础上修改过了获取tbs和签到(验证码)时候的风控,并加入了PUSH推送到微信
import requests
from bs4 import BeautifulSoup
import re
import time
import ddddocr
def getTblikes():
i = 1
url = "https://tieba.baidu.com/f/like/mylike"
try:
contain1 = requests.get(
url=url, cookies=myCookies, headers=myHeader).text
except requests.exceptions.RequestException as e:
print("网络请求失败:", e)
send("ck失效,请重新获取")
return
pattern = r'<a href="/f/like/mylike\?&pn=(\d+)">尾页</a>'
match = re.search(pattern, contain1)
pageNum = 0
if match:
# print(match.group(1))
pageNum = int(match.group(1))
else:
print('not match')
send("ck失效,请重新获取")
return
print(f"总共有{pageNum}页的贴吧列表")
a = 1
while a <= pageNum:
urlLike = f"https://tieba.baidu.com/f/like/mylike?&pn={a}"
print(f"正在获取第{a}页的贴吧列表")
try:
contain = BeautifulSoup(requests.get(
url=urlLike, cookies=myCookies, headers=myHeader).text, "html.parser")
except requests.exceptions.RequestException as e:
print("网络请求失败:", e)
return
first = contain.find_all("tr")
for result in first:
second = result.find_next("td")
name = second.find_next("a")['title']
print(f"正在签到{name}吧")
singUp(name)
time.sleep(5)
i += 1
a += 1
# 签到成功吧的个数
succeed_qian_num = str(i-len(failList))
# 失败八名
send(f"签到完毕!{succeed_qian_num}/{i}")
print(f"签到完毕!总共签到完成{i}个贴吧")
# 清空列表
failList.clear()
succeedlist.clear()
# 这种方法会被百度风控,所以不用了
# def getTbs(name):
# """
# This function gets the tbs value for a given Tieba forum.
# """
# urls = f"https://tieba.baidu.com/f?kw={name}"
# try:
# contain = BeautifulSoup(requests.get(urls, headers=myHeader, cookies=myCookies).text, "html.parser")
# except requests.exceptions.RequestException as e:
# print("网络请求失败:", e)
# return None
# first = contain.find_all("script")
# try:
# return re.findall('\'tbs\': "(.*?)" ', str(first))
# finally:
# return re.findall('\'tbs\': "(.*?)" ', str(first))
# 绕开风控的方法获取tbs,这里获取tbs不需要贴吧名
def getTbs2():
return requests.get("https://tieba.baidu.com/dc/common/imgtbs").json()['data']["tbs"]
# 过签到验证码
def SingUpCode(tb, captcha_vcode_str):
print("正在尝试绕过验证码")
# 需要验证的时候
try:
myDate_yan = {
"ie": "utf-8",
"kw": tb,
"captcha_input_str": getCode(captcha_vcode_str),
"captcha_vcode_str": captcha_vcode_str
}
resp = requests.post(url, data=myDate_yan,
headers=myHeader, cookies=myCookies)
except requests.exceptions.RequestException as e:
print("网络请求失败:, 请尝试更换ck后再经行签到", e)
send("ck失效,请重新获取")
return
if re.findall('"error":"(.*?)"', str(resp.text)) == "need vcode":
print("验证码错误")
print("重新获取验证码")
SingUpCode(tb, resp.json()['data']['captcha_vcode_str'])
return re.findall('"error":"(.*?)"', str(resp.text))
def singUp(tb):
"""
登录函数
"""
# 不需要验证的时候
myDate = {
"ie": "utf-8",
"kw": tb,
"tbs": getTbs2()
}
try:
resp = requests.post(
url, data=myDate, headers=myHeader, cookies=myCookies)
except requests.exceptions.RequestException as e:
print("网络请求失败:", e)
return
result = re.findall('"error":"(.*?)"', str(resp.text))
if result == "need vcode":
print("需要验证码")
result = SingUpCode(tb, resp.json()['data']['captcha_vcode_str'])
if result.encode().decode("unicode_escape") == "":
print(f"在{tb}签到成功了!!")
succeedlist.append(tb)
elif result.encode().decode("unicode_escape").find("签过了") != -1:
succeedlist.append(tb)
print(f"在{tb}签到失败了,返回信息: 请不要重复签到")
else:
failList.append(tb)
print(f"在{tb}签到失败了,返回信息: " + result.encode().decode("unicode_escape"))
def send(msg):
# 使用PUSHPLUS发送消息
if token == "":
return
url = f"http://www.pushplus.plus/send/{token}?title=百度贴吧签到&content={msg}"
requests.get(url=url)
pass
# 识别验证码
def getCode(captcha_vcode_str):
# 先下载验证码图片
code_url = "https://tieba.baidu.com/cgi-bin/genimg?"+captcha_vcode_str
print("验证码地址:"+code_url)
content = requests.get(url=code_url, headers=myHeader,
cookies=myCookies).content
with open("vcode.png", "wb") as f:
f.write(content)
orc = ddddocr.DdddOcr()
with open('vcode.png', 'rb+') as fp:
img_bytes = fp.read()
res = orc.classification(img_bytes)
# print("验证码识别结果:"+res)
return res
# 签到失败的吧
# PUSH的token
if __name__ == '__main__':
# 你的PUSHPLUS的token,,https://www.pushplus.plus/登录获取,微信一对一推送,不需要可以留空
token = ""
# 你的ck(可以多账号),https://tieba.baidu.com/,登陆后F12,在headers中获取,必填
ck = ""
myHeader = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36",
}
myCookies = {
"Cookie": ck,
}
# 用于签到时候的url
url = "https://tieba.baidu.com/sign/add"
# 签到失败列表
failList = []
# 签到成功列表
succeedlist = []
getTblikes()
zhai0122 发表于 2022-8-14 10:19
cookies该怎么获取呢?
已知晓f12获取,有没有简单方法
F12抓包工具是最简单的了,可以看我的主题帖,里面有打包成exe的版本 Eureka8 发表于 2022-8-16 09:18
这个百度可以看一下,有人详细分析过这个,百度这个Cookie无限接近于静态加密字符码,你不动账号信息BDUS ...
这个我倒知道 BDUSS 信息 之前在用 百度云盘类的加速工具的时候 我就注意到了 这个好啊,签到省事{:301_997:}
百度系统挖坟用我12年的回帖,给我封永久。。。。 这个优秀了 不错不错,来学习一下 谢谢分享!虽然论坛里有个贴吧云签到来的 学习一下啊,谢谢 感谢分享 好久没用贴吧了,之前沉迷于签到,签了很多个吧。 可以可以, 写完是不是很有成就感