[Python] 纯文本查看 复制代码
import requests
from bs4 import BeautifulSoup
import re
import time
import ddddocr
def getTblikes():
i = 1
url = "https://tieba.baidu.com/f/like/mylike"
try:
contain1 = requests.get(
url=url, cookies=myCookies, headers=myHeader).text
except requests.exceptions.RequestException as e:
print("网络请求失败:", e)
send("ck失效,请重新获取")
return
pattern = r'<a href="/f/like/mylike\?&pn=(\d+)">尾页</a>'
match = re.search(pattern, contain1)
pageNum = 0
if match:
# print(match.group(1))
pageNum = int(match.group(1))
else:
print('not match')
send("ck失效,请重新获取")
return
print(f"总共有{pageNum}页的贴吧列表")
a = 1
while a <= pageNum:
urlLike = f"https://tieba.baidu.com/f/like/mylike?&pn={a}"
print(f"正在获取第{a}页的贴吧列表")
try:
contain = BeautifulSoup(requests.get(
url=urlLike, cookies=myCookies, headers=myHeader).text, "html.parser")
except requests.exceptions.RequestException as e:
print("网络请求失败:", e)
return
first = contain.find_all("tr")
for result in first[1:]:
second = result.find_next("td")
name = second.find_next("a")['title']
print(f"正在签到{name}吧")
singUp(name)
time.sleep(5)
i += 1
a += 1
# 签到成功吧的个数
succeed_qian_num = str(i-len(failList))
# 失败八名
send(f"签到完毕!{succeed_qian_num}/{i}")
print(f"签到完毕!总共签到完成{i}个贴吧")
# 清空列表
failList.clear()
succeedlist.clear()
# 这种方法会被百度风控,所以不用了
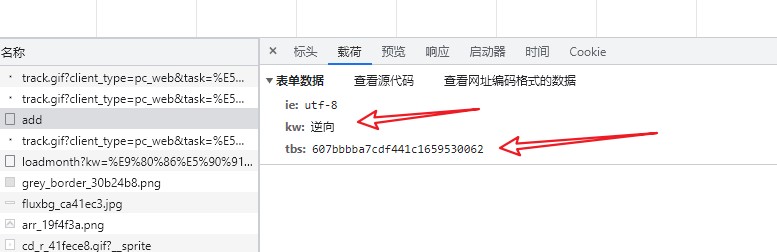
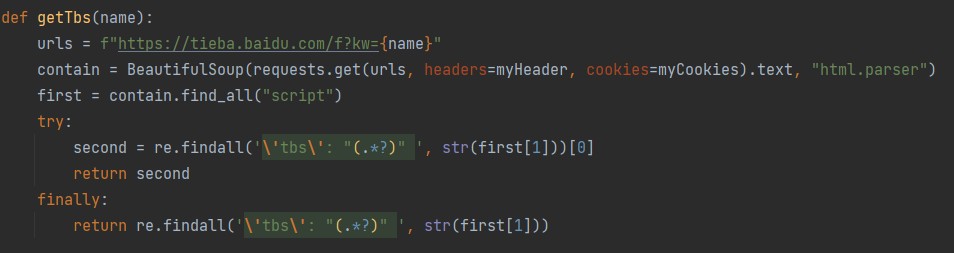
# def getTbs(name):
# """
# This function gets the tbs value for a given Tieba forum.
# """
# urls = f"https://tieba.baidu.com/f?kw={name}"
# try:
# contain = BeautifulSoup(requests.get(urls, headers=myHeader, cookies=myCookies).text, "html.parser")
# except requests.exceptions.RequestException as e:
# print("网络请求失败:", e)
# return None
# first = contain.find_all("script")
# try:
# return re.findall('\'tbs\': "(.*?)" ', str(first[1]))[0]
# finally:
# return re.findall('\'tbs\': "(.*?)" ', str(first[1]))
# 绕开风控的方法获取tbs,这里获取tbs不需要贴吧名
def getTbs2():
return requests.get("https://tieba.baidu.com/dc/common/imgtbs").json()['data']["tbs"]
# 过签到验证码
def SingUpCode(tb, captcha_vcode_str):
print("正在尝试绕过验证码")
# 需要验证的时候
try:
myDate_yan = {
"ie": "utf-8",
"kw": tb,
"captcha_input_str": getCode(captcha_vcode_str),
"captcha_vcode_str": captcha_vcode_str
}
resp = requests.post(url, data=myDate_yan,
headers=myHeader, cookies=myCookies)
except requests.exceptions.RequestException as e:
print("网络请求失败:, 请尝试更换ck后再经行签到", e)
send("ck失效,请重新获取")
return
if re.findall('"error":"(.*?)"', str(resp.text))[0] == "need vcode":
print("验证码错误")
print("重新获取验证码")
SingUpCode(tb, resp.json()['data']['captcha_vcode_str'])
return re.findall('"error":"(.*?)"', str(resp.text))[0]
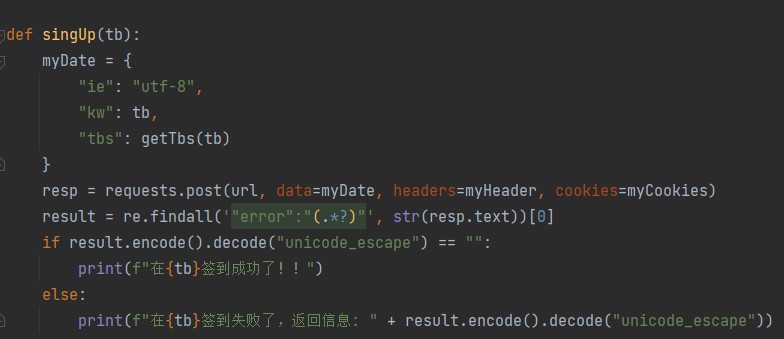
def singUp(tb):
"""
登录函数
"""
# 不需要验证的时候
myDate = {
"ie": "utf-8",
"kw": tb,
"tbs": getTbs2()
}
try:
resp = requests.post(
url, data=myDate, headers=myHeader, cookies=myCookies)
except requests.exceptions.RequestException as e:
print("网络请求失败:", e)
return
result = re.findall('"error":"(.*?)"', str(resp.text))[0]
if result == "need vcode":
print("需要验证码")
result = SingUpCode(tb, resp.json()['data']['captcha_vcode_str'])
if result.encode().decode("unicode_escape") == "":
print(f"在{tb}签到成功了!!")
succeedlist.append(tb)
elif result.encode().decode("unicode_escape").find("签过了") != -1:
succeedlist.append(tb)
print(f"在{tb}签到失败了,返回信息: 请不要重复签到")
else:
failList.append(tb)
print(f"在{tb}签到失败了,返回信息: " + result.encode().decode("unicode_escape"))
def send(msg):
# 使用PUSHPLUS发送消息
if token == "":
return
url = f"http://www.pushplus.plus/send/{token}?title=百度贴吧签到&content={msg}"
requests.get(url=url)
pass
# 识别验证码
def getCode(captcha_vcode_str):
# 先下载验证码图片
code_url = "https://tieba.baidu.com/cgi-bin/genimg?"+captcha_vcode_str
print("验证码地址:"+code_url)
content = requests.get(url=code_url, headers=myHeader,
cookies=myCookies).content
with open("vcode.png", "wb") as f:
f.write(content)
orc = ddddocr.DdddOcr()
with open('vcode.png', 'rb+') as fp:
img_bytes = fp.read()
res = orc.classification(img_bytes)
# print("验证码识别结果:"+res)
return res
# 签到失败的吧
# PUSH的token
if __name__ == '__main__':
# 你的PUSHPLUS的token,,https://www.pushplus.plus/登录获取,微信一对一推送,不需要可以留空
token = ""
# 你的ck(可以多账号[ck1,ck2,...]),https://tieba.baidu.com/,登陆后F12,在headers中获取,必填
ck = ""
myHeader = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36",
}
myCookies = {
"Cookie": ck,
}
# 用于签到时候的url
url = "https://tieba.baidu.com/sign/add"
# 签到失败列表
failList = []
# 签到成功列表
succeedlist = []
getTblikes()


 [复制链接]
[复制链接]
 发表于 2022-8-3 21:14
发表于 2022-8-3 21:14
 发表于 2022-8-9 19:43
发表于 2022-8-9 19:43
 |
发表于 2022-8-14 10:39
|
发表于 2022-8-14 10:39