利用Python爬取网络热门表情包,告别斗图烦恼
本帖最后由 zz443470785 于 2022-8-14 08:50 编辑# 利用Python爬取网络热门表情包
### 前言:刚接触python爬虫半个月,由于群里经常斗图,便想着能不能利用python爬取网络上一些热门表情包,刚好也可以练练手,便写了这段代码。由于刚入门,很多地方写的还不够好,能够优化的地方欢迎各位大佬指出!
### 开发环境:Pycharm(python 3.9)
### 使用方法:复制源码到相应环境,修改文件保存路径,直接运行即可
### 相关说明:①为了提高爬取效率,我设置了三个线程,②相关资源来自于互联网,如有侵权请告知我删除,同时源码仅供交流学习使用,严禁用作商业用途!
### 运行效果如下
[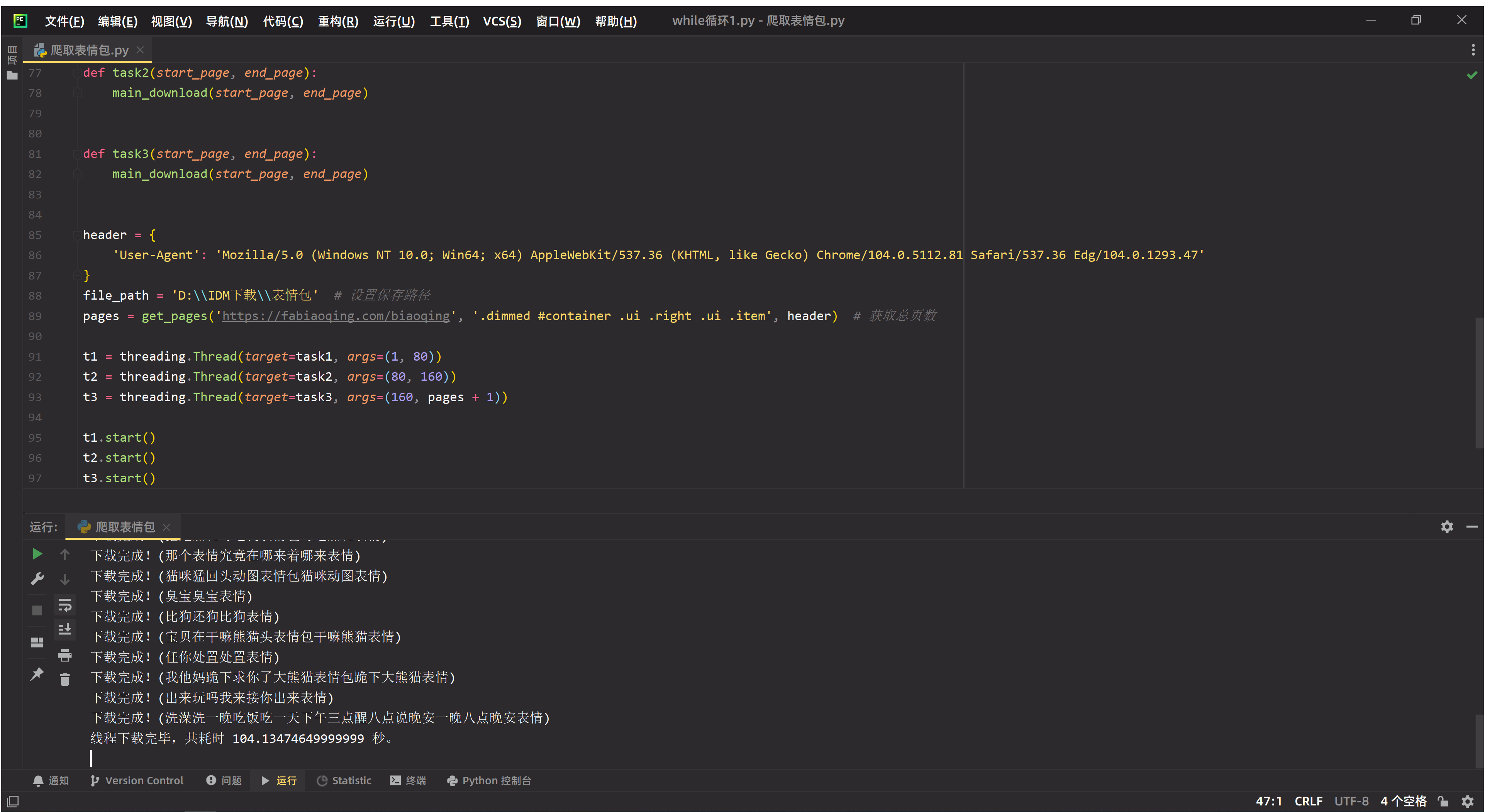](https://imgtu.com/i/vNvcEn)
[](https://imgtu.com/i/vNvWCV)
### 附上源代码
```python
"""
-*- coding: utf-8 -*-
文件名:爬取表情包.py
作者:nobody
环境: PyCharm
日期:2022/8/13 20:59
功能:爬取网络热门表情包
"""
import random
import re
import requests
import time
import threading
from bs4 import BeautifulSoup
from w3lib.html import remove_tags
# 得到网页
def get_html(url, sign, headers):
time.sleep(random.random())
html = requests.get(url, headers=headers, timeout=10)
html.encoding = 'utf-8'
soup = BeautifulSoup(html.text, 'lxml')
text = soup.select(sign)
return text
# 获取总页数
def get_pages(url, sign, headers):
html = get_html(url, sign, headers=headers)
page = remove_tags(str(html[-3]))
return int(page)
# 获取每页链接
def get_page_html(pages_count):
str_1 = 'https://fabiaoqing.com/biaoqing/lists/page/'
page_html = []
for x in range(1, pages_count + 1):
page_html.append(str_1 + str(x) + '.html')
return page_html
# 获取gif下载链接并下载
def download(url, title, headers, path):
time.sleep(random.random())
img_resp = requests.get(url, headers=headers).content
endswith = url.split('.')[-1]
title = re.sub('([^\u4e00-\u9fa5\d])', '', title)
with open(path + r'\\' + title + '.' + endswith, 'wb') as f:
f.write(img_resp)
print("下载完成!({})".format(title))
# 主下载函数
def main_download(x, y):
start = time.perf_counter()
for page_address in get_page_html(pages):
gifs_html = get_html(page_address, '.dimmed #container .ui .right .ui .tagbqppdiv a', header)
for gif_html in gifs_html:
time.sleep(random.random())
gif = 'https://fabiaoqing.com' + gif_html['href']
gif_main_html = get_html(gif, '.dimmed #container .swiper-wrapper .biaoqingpp', header)
for gif in gif_main_html:
gif_title = gif['title']
gif_address = gif['src']
download(gif_address, gif_title, header, file_path)
end = time.perf_counter()
print('线程下载完毕,共耗时 {} 秒。'.format(end - start))
# 设置三个线程
def task1(start_page, end_page):
main_download(start_page, end_page)
def task2(start_page, end_page):
main_download(start_page, end_page)
def task3(start_page, end_page):
main_download(start_page, end_page)
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.81 Safari/537.36 Edg/104.0.1293.47'
}
file_path = 'D:\\IDM下载\\表情包'# 设置保存路径
pages = get_pages('https://fabiaoqing.com/biaoqing', '.dimmed #container .ui .right .ui .item', header)# 获取总页数
t1 = threading.Thread(target=task1, args=(1, 80))
t2 = threading.Thread(target=task2, args=(80, 160))
t3 = threading.Thread(target=task3, args=(160, pages + 1))
t1.start()
t2.start()
t3.start()
``` 吾嗳破解 发表于 2022-8-18 14:14
大佬,方便分享一下小白的话应该怎么入门系统化地学习Python吗?是完全没有任何编程基础
建议先看书,了解一下编程,我是先看的《python编程:从入门到实践》,然后看的视频,开始自学 感谢分享,爬取了2855个后出错!
Exception in thread Thread-1:
Traceback (most recent call last):
File "C:\Users\ltb\AppData\Local\Programs\Python\Python38\lib\threading.py", line 932, in _bootstrap_inner
self.run()
File "C:\Users\ltb\AppData\Local\Programs\Python\Python38\lib\threading.py", line 870, in run
self._target(*self._args, **self._kwargs)
File "C:/Users/ltb/PycharmProjects/pythonProject/getgif.py", line 68, in task1
main_download(start_page, end_page)
File "C:/Users/ltb/PycharmProjects/pythonProject/getgif.py", line 62, in main_download
download(gif_address, gif_title, header, file_path)
File "C:/Users/ltb/PycharmProjects/pythonProject/getgif.py", line 46, in download
with open(path + r'\\' + title + '.' + endswith, 'wb') as f:
FileNotFoundError: No such file or directory: 'D:\\下载文档\\表情包\\\\好事多磨难以想象过意不去振作点儿说的没错习惯就好都不容易想开一点听我句劝吃亏是福多大点事都是朋友别太计较算了算了换位思考你辛苦了这人不行我的妈呀震惊我妈下巴掉了不想听牢骚万能回复啊这也太内个了吧咋会这样真有你的好问题太过分了对对对原来是这样确实会好的咋能这样呢好家伙我就知道可以的笑死这叫啥事啊说的是啊是你厉害我就不行厉害真的这人也真是谁不是呢我可以理解为这是高级及我都行怎么啦怎么回事振作点儿凡尔赛吗看你难搞哦怎么能这样呢真过意不去开眼界了太棒了我懂哇嚯害服了好说好说还是要打起精神来蛮好的就是个人理解详细说说简直难以想象我也这么觉得不错子那也是有道理我也是别见外你知道我多想成为你吗不想听吹牛拒绝闲聊真的吗好厉害啊上班不忙吗可不是嘛是吗你不上班吗你说的没错对对对你很无聊吗看你自己好惨啊咋能这样啊不愧是你最近很闲吗也没啥意思我也生气了无语了我觉得挺牛的咋欺负人呢我觉得也是都这样不难过了哦会好起来的要用辩证的眼光看待事物硬着头皮上吧慢慢来聊天鼓励对方说下去为什么怎么会真的啊我都不知道诶那怎么办后来呢原来是这样我辈楷模有内味儿了瑞思拜大佬大佬学到了那还挺好的那就先这样好像是有点儿没事儿美女的事你少管哈哈不用啦确实该干嘛就干嘛聊天背景图万能回复振作厉害这样表情.jpg'
进程已结束,退出代码0 谢谢分享{:1_893:} 大佬,方便分享一下小白的话应该怎么入门系统化地学习Python吗?是完全没有任何编程基础{:1_909:} 已经运行成功,顺带学习了一把,感谢楼主。 这才是实实在在滴为r着想的真大佬1 18591991311 发表于 2022-8-19 11:00
已经运行成功,顺带学习了一把,感谢楼主。
我也是初学者 感谢分享 zz443470785 发表于 2022-10-14 22:24
建议先看书,了解一下编程,我是先看的《python编程:从入门到实践》,然后看的视频,开始自学
好的,感谢{:1_893:}
页:
[1]
2