本帖最后由 zz443470785 于 2022-8-14 08:50 编辑
利用Python爬取网络热门表情包
前言:刚接触python爬虫半个月,由于群里经常斗图,便想着能不能利用python爬取网络上一些热门表情包,刚好也可以练练手,便写了这段代码。由于刚入门,很多地方写的还不够好,能够优化的地方欢迎各位大佬指出!
开发环境:Pycharm(python 3.9)
使用方法:复制源码到相应环境,修改文件保存路径,直接运行即可
相关说明:①为了提高爬取效率,我设置了三个线程,②相关资源来自于互联网,如有侵权请告知我删除,同时源码仅供交流学习使用,严禁用作商业用途!
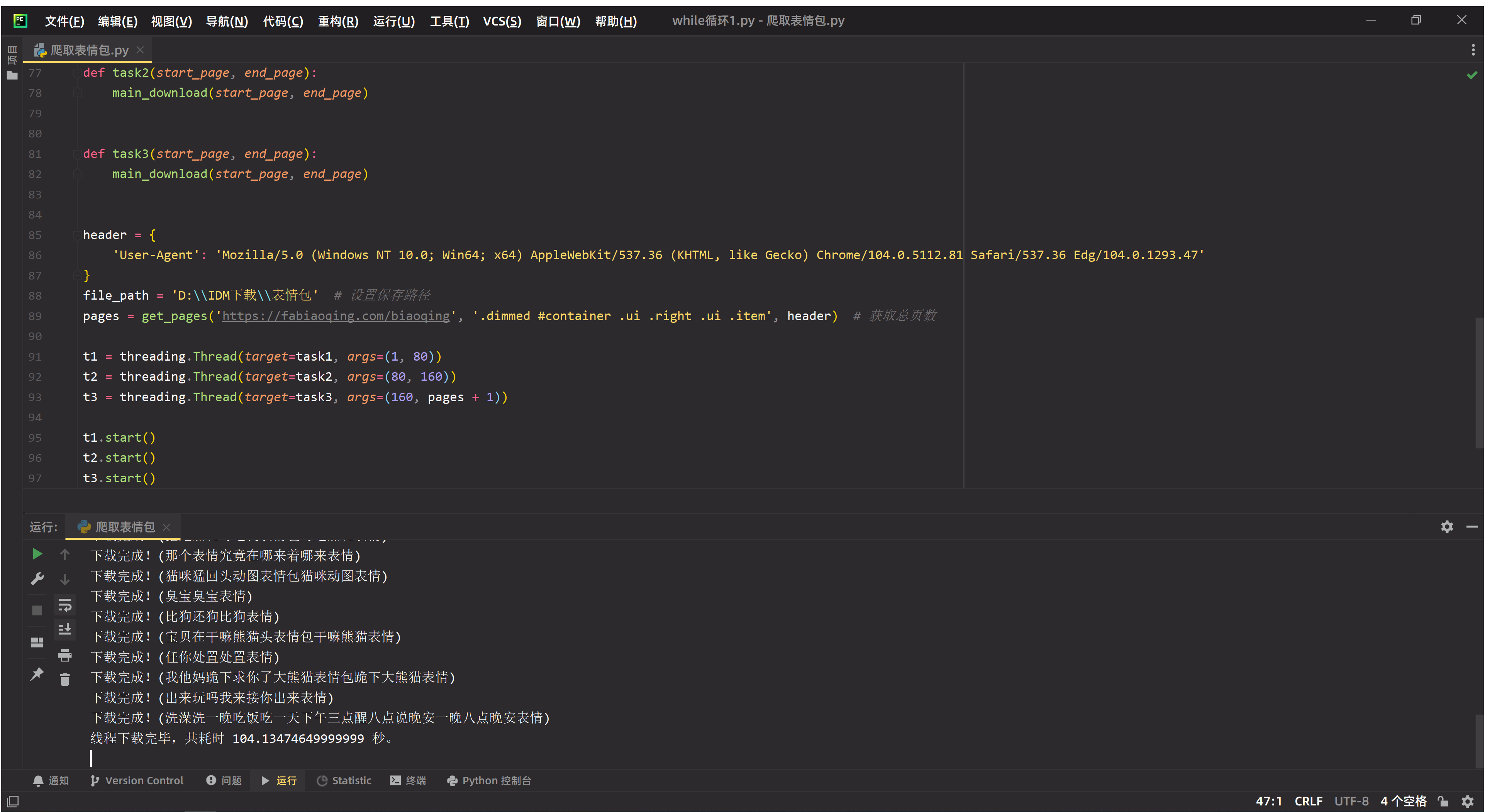
运行效果如下

附上源代码
"""
-*- coding: utf-8 -*-
文件名:爬取表情包.py
作者:nobody
环境: PyCharm
日期:2022/8/13 20:59
功能:爬取网络热门表情包
"""
import random
import re
import requests
import time
import threading
from bs4 import BeautifulSoup
from w3lib.html import remove_tags
# 得到网页
def get_html(url, sign, headers):
time.sleep(random.random())
html = requests.get(url, headers=headers, timeout=10)
html.encoding = 'utf-8'
soup = BeautifulSoup(html.text, 'lxml')
text = soup.select(sign)
return text
# 获取总页数
def get_pages(url, sign, headers):
html = get_html(url, sign, headers=headers)
page = remove_tags(str(html[-3]))
return int(page)
# 获取每页链接
def get_page_html(pages_count):
str_1 = 'https://fabiaoqing.com/biaoqing/lists/page/'
page_html = []
for x in range(1, pages_count + 1):
page_html.append(str_1 + str(x) + '.html')
return page_html
# 获取gif下载链接并下载
def download(url, title, headers, path):
time.sleep(random.random())
img_resp = requests.get(url, headers=headers).content
endswith = url.split('.')[-1]
title = re.sub('([^\u4e00-\u9fa5\d])', '', title)
with open(path + r'\\' + title + '.' + endswith, 'wb') as f:
f.write(img_resp)
print("下载完成!({})".format(title))
# 主下载函数
def main_download(x, y):
start = time.perf_counter()
for page_address in get_page_html(pages)[x:y]:
gifs_html = get_html(page_address, '.dimmed #container .ui .right .ui .tagbqppdiv a', header)
for gif_html in gifs_html:
time.sleep(random.random())
gif = 'https://fabiaoqing.com' + gif_html['href']
gif_main_html = get_html(gif, '.dimmed #container .swiper-wrapper .biaoqingpp', header)
for gif in gif_main_html:
gif_title = gif['title']
gif_address = gif['src']
download(gif_address, gif_title, header, file_path)
end = time.perf_counter()
print('线程下载完毕,共耗时 {} 秒。'.format(end - start))
# 设置三个线程
def task1(start_page, end_page):
main_download(start_page, end_page)
def task2(start_page, end_page):
main_download(start_page, end_page)
def task3(start_page, end_page):
main_download(start_page, end_page)
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.81 Safari/537.36 Edg/104.0.1293.47'
}
file_path = 'D:\\IDM下载\\表情包' # 设置保存路径
pages = get_pages('https://fabiaoqing.com/biaoqing', '.dimmed #container .ui .right .ui .item', header) # 获取总页数
t1 = threading.Thread(target=task1, args=(1, 80))
t2 = threading.Thread(target=task2, args=(80, 160))
t3 = threading.Thread(target=task3, args=(160, pages + 1))
t1.start()
t2.start()
t3.start()
| 
 [复制链接]
[复制链接]
 发表于 2022-8-14 08:47
发表于 2022-8-14 08:47
 |
发表于 2022-10-14 22:24
|
发表于 2022-10-14 22:24





