修改游戏的前提是要去了解这个游戏, 虽然还是有很大一部分游戏公司对某些数据还是用基本数据类型, 但是精明的公司会自制新的类型来防止被直接修改, 本文这次带来的是C#的字符串解析
前言
C#的字符串生成可以通过hook il2cpp自带的new函数进行生成(使用方法参考本人的上一篇文章)
namespace il2cpp {
namespace vm {
class String {
...
static Il2CppString* New (const char* str);
...
};
} /* namespace vm */
} /* namespace il2cpp */
生成是轻松了, 但是解析就出大问题了, 涉及到大小端问题, 字节问题, 解析后出现的字节不对称问题, 简直要命
相关文章
冰鸽的开路教程
unicode和utf-8互转
获取字节数组
通过冰鸽的教程, 可知C#内置的String是Unicode, 而我们linux则是utf-8
虽然一开始就打算使用内置的方法去获取对应的字节起始地址和字符数, 但是终究这种方法效率没直接硬核的对地址操作来得快, 所以还是用冰鸽开路留下来的结构体吧
//C#字符串结构体仿制版
typedef struct CString
{
void *Empty;
void *WhiteChars;
int32_t length;
char start_char[1];
} CString;

转换
接下来就是Unicode转UTF-8的环节了
看了一早上的相关介绍/说明文章, 头都要裂开了, 总结就是
- Unicode是保存字符的码值, 比如 吗 字, 码值为 0x5417
- 而UTF-8才是具体存放到内存中做交互的, 吗 字在内存中是 0x97 0x90 0xE5
Unicode的占用还好是固定的2字节, 问题最大的就是UTF-8的文字字节并不是固定的, 英文字符只占一个字节, 汉字貌似都是3个字节吧
还好看到这篇dalaoの文章, 这位大佬已经提供好了实现, 直接搬过来用就好了
int unicode2UTF(long unic, char *pOutput)
{
if (unic >= 0xFFFF0000)
unic %= 0xFFFF0000;
if (unic <= 0x0000007F)
{
*pOutput = (unic & 0x7F);
return 1;
}
else if (unic >= 0x00000080 && unic <= 0x000007FF)
{
*(pOutput + 1) = (unic & 0x3F) | 0x80;
*pOutput = ((unic >> 6) & 0x1F) | 0xC0;
return 2;
}
else if (unic >= 0x00000800 && unic <= 0x0000FFFF)
{
*(pOutput + 2) = (unic & 0x3F) | 0x80;
*(pOutput + 1) = ((unic >> 6) & 0x3F) | 0x80;
*pOutput = ((unic >> 12) & 0x0F) | 0xE0;
return 3;
}
else if (unic >= 0x00010000 && unic <= 0x001FFFFF)
{
*(pOutput + 3) = (unic & 0x3F) | 0x80;
*(pOutput + 2) = ((unic >> 6) & 0x3F) | 0x80;
*(pOutput + 1) = ((unic >> 12) & 0x3F) | 0x80;
*pOutput = ((unic >> 18) & 0x07) | 0xF0;
return 4;
}
else if (unic >= 0x00200000 && unic <= 0x03FFFFFF)
{
*(pOutput + 4) = (unic & 0x3F) | 0x80;
*(pOutput + 3) = ((unic >> 6) & 0x3F) | 0x80;
*(pOutput + 2) = ((unic >> 12) & 0x3F) | 0x80;
*(pOutput + 1) = ((unic >> 18) & 0x3F) | 0x80;
*pOutput = ((unic >> 24) & 0x03) | 0xF8;
return 5;
}
else if (unic >= 0x04000000 && unic <= 0x7FFFFFFF)
{
*(pOutput + 5) = (unic & 0x3F) | 0x80;
*(pOutput + 4) = ((unic >> 6) & 0x3F) | 0x80;
*(pOutput + 3) = ((unic >> 12) & 0x3F) | 0x80;
*(pOutput + 2) = ((unic >> 18) & 0x3F) | 0x80;
*(pOutput + 1) = ((unic >> 24) & 0x3F) | 0x80;
*pOutput = ((unic >> 30) & 0x01) | 0xFC;
return 6;
}
return 0;
}
void CString_Print(CString *self)
{
char *buff = (char *)malloc(self->length * 6);
memset(buff,0,self->length * 6);
for (int i = 0, off = 0; i < self->length; ++i)
off += unicode2UTF(((short *)self->start_char)[i], buff + off);
LOGD("%s", buff);
// showMemoryHex(self->start_char, self->length * 2);
free(buff);
}
虽然感觉有点浪费内存, 但是总比解析到一半, 缓冲区不够用重新扩充好(空间换时间, 最开始写的时候就很头大这个问题)
踩坑
BUG1
测试解析的时候, 意外的发现, 草 这个字符, Unicode编码为 0x8349
然后跑了一遍, 居然解析成字符 I, 我都傻了

将unicode2UTF函数的unic参数值打印出来一看更傻眼了

具体怎么产生这个BUG的问题还是没想出来, 有dalao知道的话请教一下小弟
解决方法是直接抹除0xFFFFxxxx, 取低字节两位完事 好用完事, 出bug再说(逃
BUG2
本文的CString_Print函数其实还有另一个版本

直到前几天发现了神奇的状况, 一会乱码一会不乱码 (偷懒不截全)

经过一顿猛如肥宅的操作后, 确认过unic也没问题, 就纳闷了怎么还会出现乱码呢
然后调整了一下结束符 '\0'
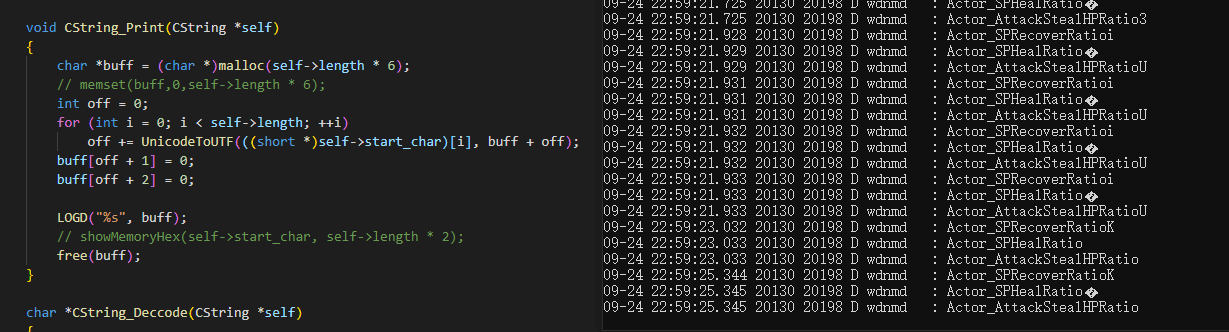
还是莫得用, 绝了
最后搬出 memset 大法
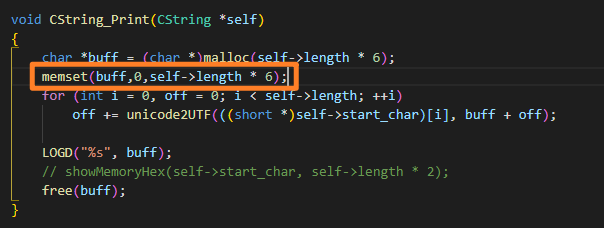
虽然不知道发生了什么, 但是问题解决了


 [复制链接]
[复制链接]
 发表于 2019-9-27 01:30
发表于 2019-9-27 01:30
 |
发表于 2019-9-27 14:02
|
发表于 2019-9-27 14:02



