一、前言
前两篇文章链接:
1、DEX文件头解析
2、DEX文件校验和解析
PS:前几天检查文件夹的时候发现DEX文件解析还只写了开头,正好找点事情来做,就去接着解析DEX文件其余部分了。。。。。(还得多亏了一波疫情,不然都忘了还有这回事了。。。)
二、DEX文件中的字符串
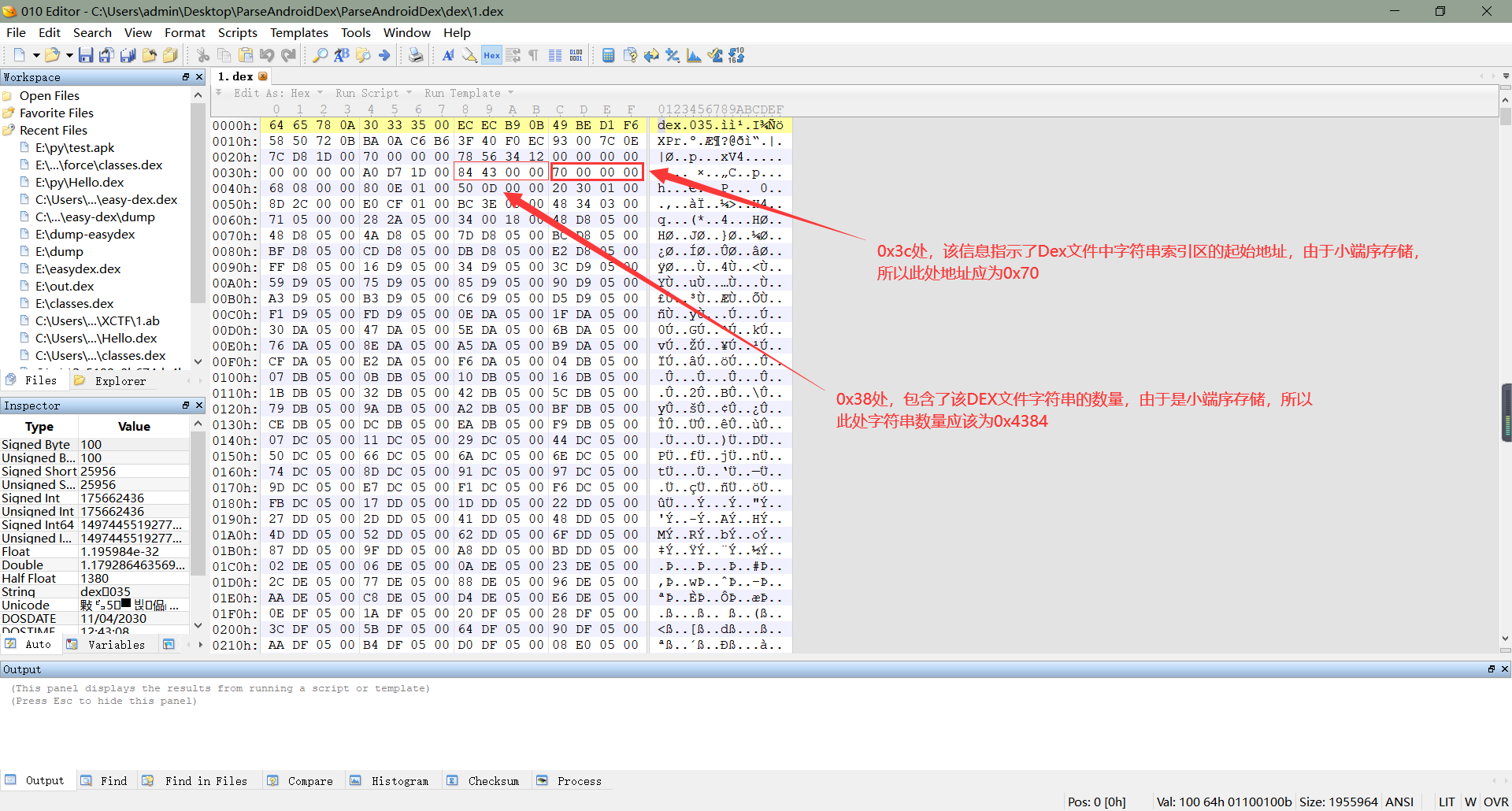
1、DEX文件大致上可以粗略的分为3个部分:文件头、索引区以及数据区。而文件头一般来说占了整个DEX文件0x70个字节(还不了解DEX文件头的可以看一下我前面两篇文章),在文件头中,关于字符串的相关信息一共有8个字节,分别位于0x38(4 Bytes)和0x3c(4 Bytes)处,前者说明了该DEX文件包含了多少个字符串,后者则是字符串索引区的起始地址,但是需要注意的是,DEX存储是以小端序存储的(通俗一点的说就是从后往前读),如下所示:
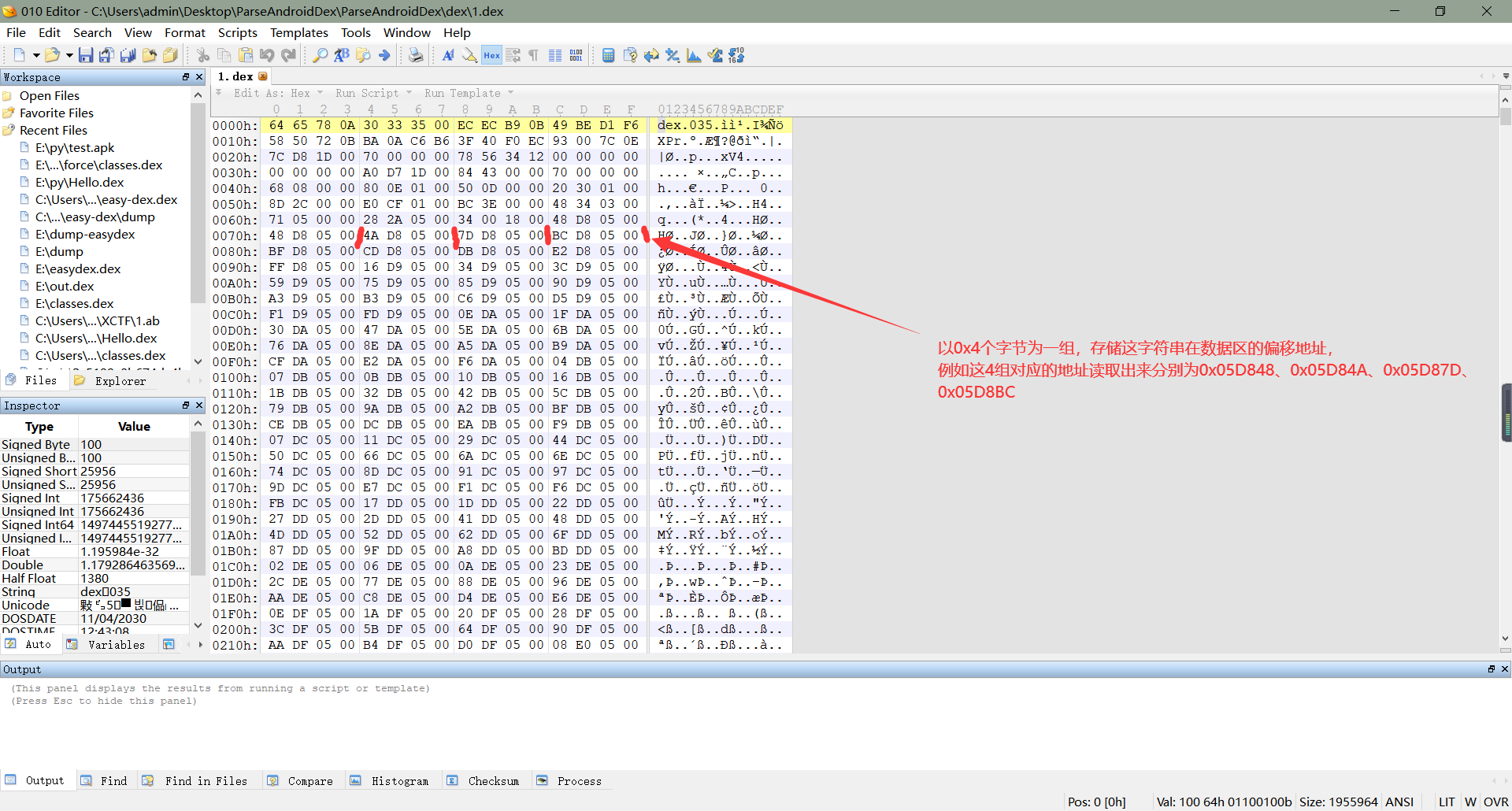
2、前面我们通过文件头知道了字符串数量和字符串索引区起始地址等信息,接下来我们就来具体看一下字符串索引区。字符串索引区存储的是字符串真正存储在数据区的偏移地址,以4个字节为一组,表示一个字符串在数据区的偏移地址,所以索引区一个占字符串数量 X 4个字节那么多,同样的,索引区也采用的是小端序存储,所以我们在读取地址时,需要与小端序的方式来读取真正的地址,如下所示:
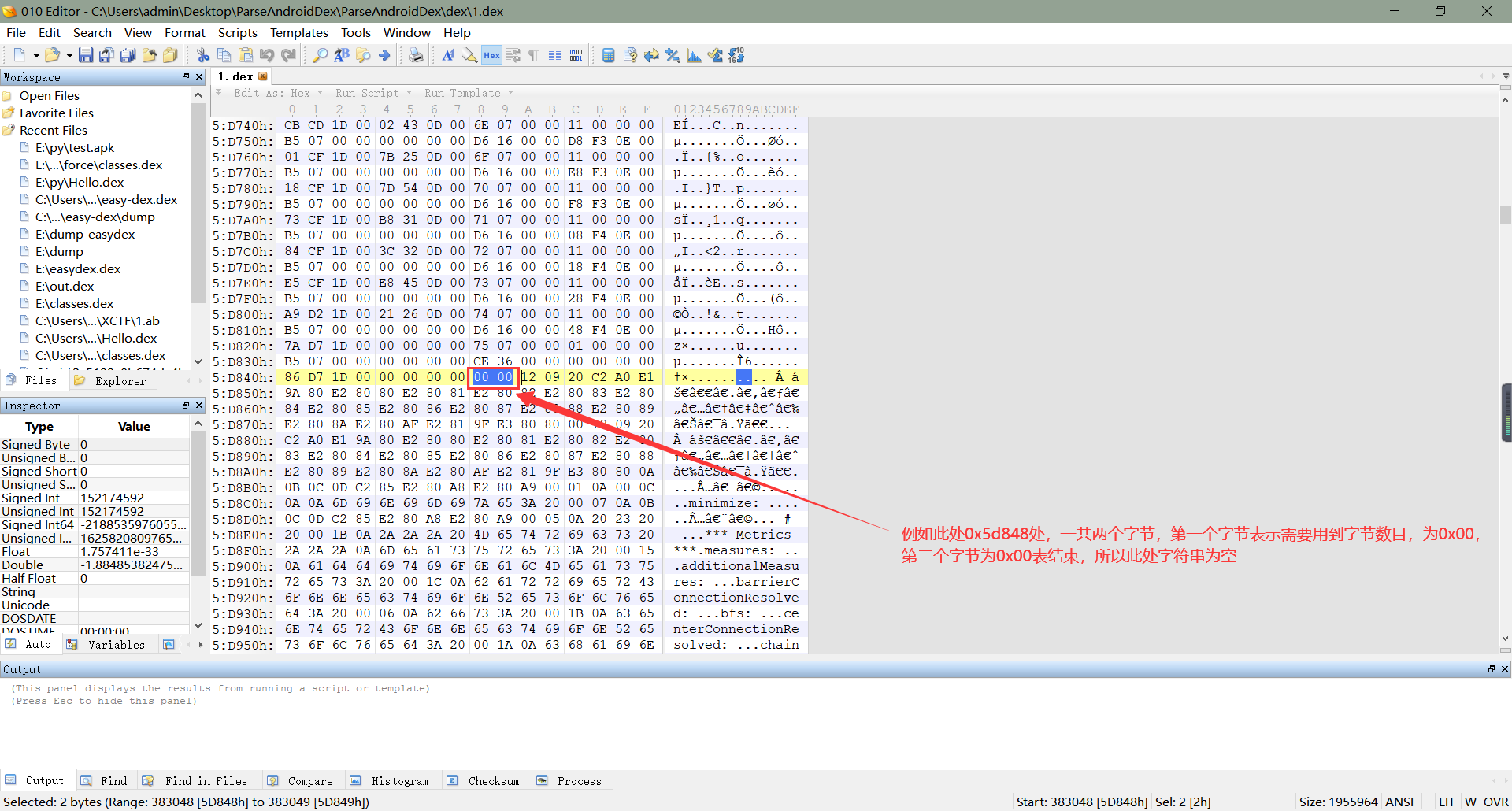
3、从上面我们已经知道了如何找到字符串在数据区的偏移地址,接下来我们需要做的就是解析这些数据区的字节。通过偏移地址我们可以在数据区找到代表字符串的这些字节,在DEX文件中,字符串是通过MUTF-8编码而成的(至于mutf-8是什么编码,我会将一些相关博客链接贴在文末),在MUTF-8编码中,第一个字节代表了这个字符串所需要用到的字节数目(不包括最后一个代表终结的字节),最后一个字节为0x00,表示这个字符串到此结束,跟c语言有点类似,中间部分才是一个字符串的具体内容,如下所示:(PS:mutf-8第一个字节还经过uleb128编码,所以简单的进行进制换算得到的字节数很多人奇怪对不上,由于比较复杂,就不过多解释了,想进一步了解更深的可以去看一下安卓源码中对DEX文件解析出字符串这一部分)
三、解析代码:
PS:我电脑运行环境--python3.6
代码如下:
import binascii
import os
import sys
def getStringsCount(f):
f.seek(0x38)
stringsId = f.read(4)
a = bytearray(stringsId)
a.reverse()
stringsId = bytes(a)
stringsId = str(binascii.b2a_hex(stringsId),encoding='UTF-8')
count = int(stringsId,16)
print('[+] stringSize ==> ' + str(count))
return count
def getStringByteArr(f,addr):
byteArr = bytearray()
f.seek(addr + 1)
b = f.read(1)
b = str(binascii.b2a_hex(b),encoding='UTF-8')
b = int(b,16)
index = 2
while b != 0:
byteArr.append(b)
f.seek(addr + index)
b = f.read(1)
b = str(binascii.b2a_hex(b),encoding='UTF-8')
b = int(b,16)
index = index + 1
return byteArr
def BytesToString(byteArr):
try:
bs = bytes(byteArr)
stringItem = str(bs,encoding='UTF-8')
print(' str = ' + stringItem)
return stringItem
except:
pass
def getAddress(addr):
address = bytearray(addr)
address.reverse()
address = bytes(address)
address = str(binascii.b2a_hex(address),encoding='UTF-8')
address = int(address,16)
return address
def getStrings(f,stringAmount):
stringsList = []
f.seek(0x3c)
stringOff = f.read(4)
Off = getAddress(stringOff)
f.seek(Off)
for i in range(stringAmount):
addr = f.read(4)
address = getAddress(addr)
byteArr = getStringByteArr(f,address)
stringItem = BytesToString(byteArr)
stringsList.append(stringItem)
Off = Off + 4
f.seek(Off)
if __name__ == '__main__':
filename = str(os.path.join(sys.path[0])) + '\\1.dex'
f = open(filename,'rb',True)
stringsCount = getStringsCount(f)
getStrings(f,stringsCount)
f.close()
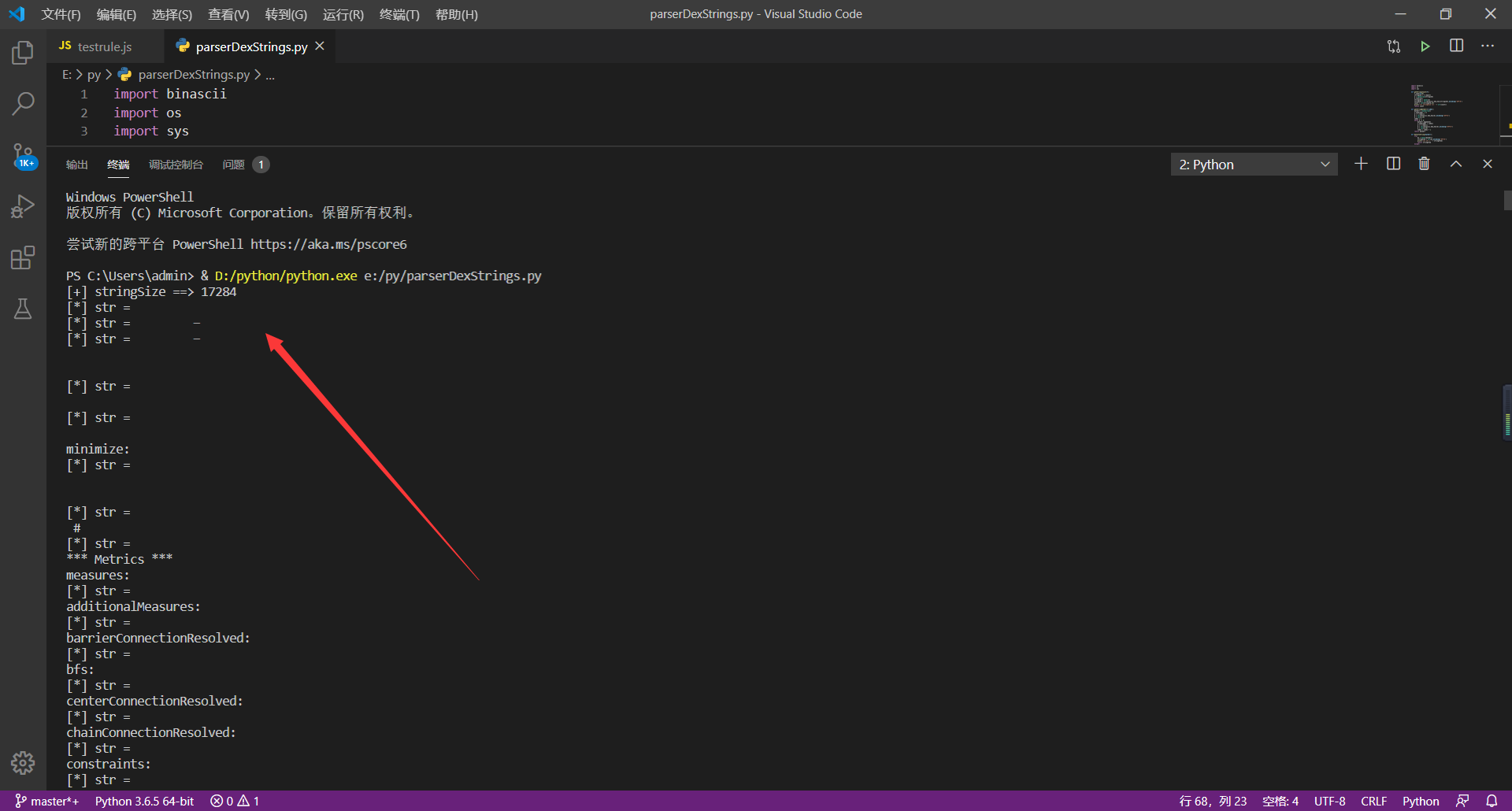
运行截图:
四、一些总结
其实也没有什么好总结的,因为本身这没有什么难点之处,就记录一些遇见的问题吧!!!最开始解析字符串的时候发现MUTF-8编码的时候好不容易弄懂了的时候,发现还经过uleb128,所以最开始一直没办法通过第一个字节计算出需要编码的字节个数,最后取了个巧,从第二个字节开始读取知道读取到0x00为止;然后是怎么编码这些字节显示字符串,后来看了一下姜维大佬写的解析代码,发现直接用的是utf-8进行编码,转念一想,mutf-8也是utf-8的变种,所以大部分解析出来基本没有问题。写完代码后本来打算去看一下安卓源码是怎么解析这一块的再来模仿一下,但是这疫情让我已经耍了这么久了,实在没精神去看了,我还是接着去微博上蹲在@四川教育吧,看源码什么的还是开学了再说吧!!!
五、一下链接和附件
1、相关知识链接:
MUTF-8编码:https://blog.csdn.net/Roland_Sun/article/details/46716965
uleb128:https://blog.csdn.net/Roland_Sun/article/details/46708061
2、样本及代码下载链接:
百度网盘链接:https://pan.baidu.com/s/1_CQP7Zrj9LHcLOIjdGD95A;提取码:yc9y

 发表于 2020-4-4 17:03
发表于 2020-4-4 17:03
 |
发表于 2020-4-18 18:47
|
发表于 2020-4-18 18:47




