import re
import json
from multiprocessing import thread
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36',
}
url = input("请输入视频地址:")
with open('SESSDATA.txt', 'r') as f:
SESSDATA = f.read()
if SESSDATA == '0':
print('检测到您未设置SESSDATA,最高只能下载480p画质哦!')
r = requests.get(url)
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text, 'html.parser')
name = soup.title.text.split('_')[0]
print(name)
if '?' in url:
url = url.split('?')[0]
print(url)
bvid = re.search(r'BV.*', url).group()
print('BV号:' + bvid + "1111")
cid_json = requests.get('https://api.bilibili.com/x/player/pagelist?bvid={}&jsonp=jsonp'.format(bvid)).text
print(cid_json)
cid = re.search(r'{"cid":(\d+)', cid_json).group()[7:]
print('CID:' + cid)
rsp = requests.get(url, headers=headers)
aid = re.search(r'"aid":(.*?),"', rsp.text).group()[6:-2]
print('AV号:' + aid)
qn = 16
headers['Referer'] = url
api_url = 'https://api.bilibili.com/x/player/playurl?cid={}&avid={}&qn={}&otype=json&requestFrom=bilibili-helper'.format(
cid, aid, qn)
qn_dict = {}
rsp = requests.get(api_url, headers=headers).content
rsp = json.loads(rsp)
qn_accept_description = rsp.get('data').get('accept_description')
qn_accept_quality = rsp.get('data').get('accept_quality')
print('下载视频清晰度选择')
for i, j, xuhao in zip(qn_accept_description, qn_accept_quality, range(len(qn_accept_quality))):
print(str(xuhao + 1) + ':' + i)
qn_dict[str(xuhao + 1)] = j
xuhao = input('请选择(输入清晰度前的标号):')
qn = qn_dict[xuhao]
print('清晰度参数qn:' + str(qn))
api_url = 'https://api.bilibili.com/x/player/playurl?cid={}&avid={}&qn={}&otype=json&requestFrom=bilibili-helper'.format(
cid, aid, qn)
cookies = {}
cookies['SESSDATA'] = SESSDATA
rsp = requests.get(api_url, headers=headers, cookies=cookies).content
rsp = json.loads(rsp)
real_url = rsp.get('data').get('durl')[0].get('url')
print('成功获取视频直链!')
print('正在开启多线程极速下载……')
thread(real_url, url, name + '.flv')

 [复制链接]
[复制链接]
 发表于 2020-6-18 21:12
发表于 2020-6-18 21:12
 |
发表于 2020-6-18 21:53
|
发表于 2020-6-18 21:53



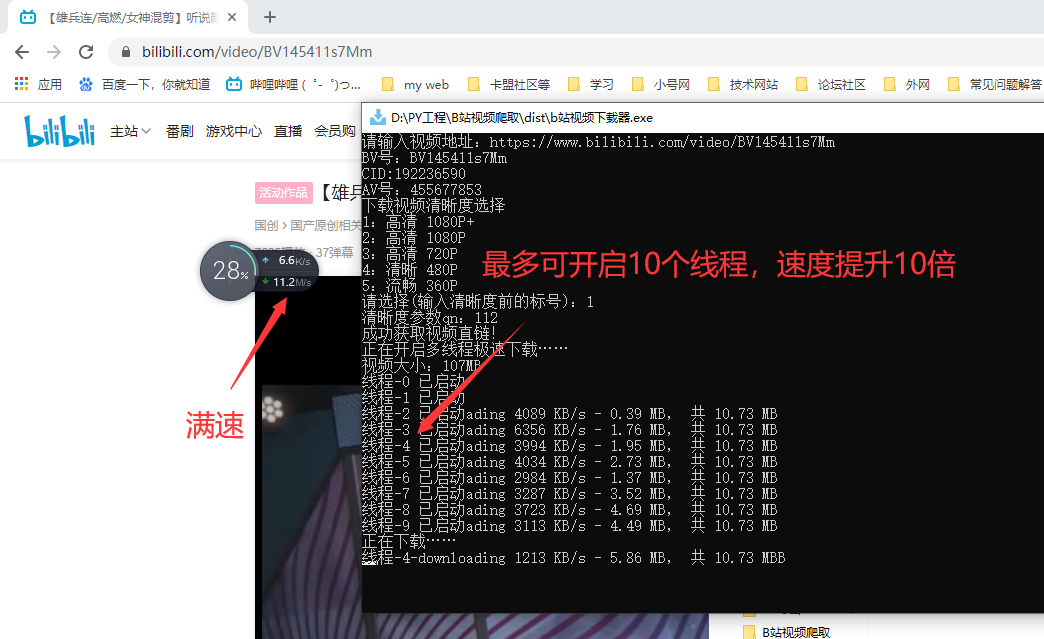
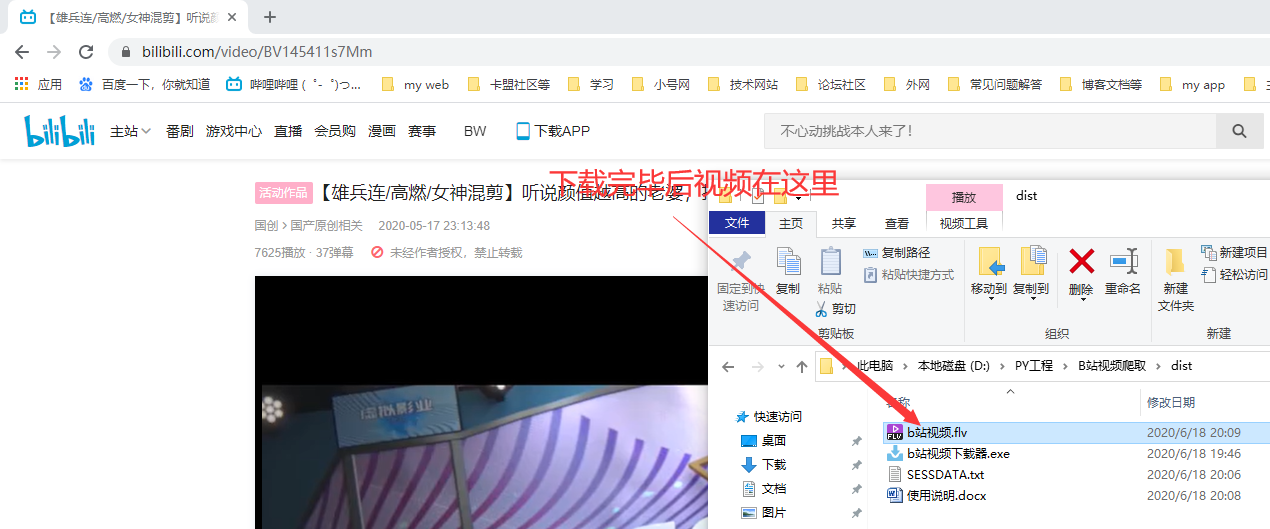
 ,还有就是可以研究下多P下载
,还有就是可以研究下多P下载
