本帖最后由 xccxvb 于 2020-6-25 14:43 编辑
在app上看个小说,要么需要会员,要么要看视频才能免广告,太浪费时间了啊!所以我决定自己先把小说爬下来再慢慢看!小说网站和源码我给打码了,此贴仅做技术交流,但不要灰心,继续看下去,小白也会有收获的。
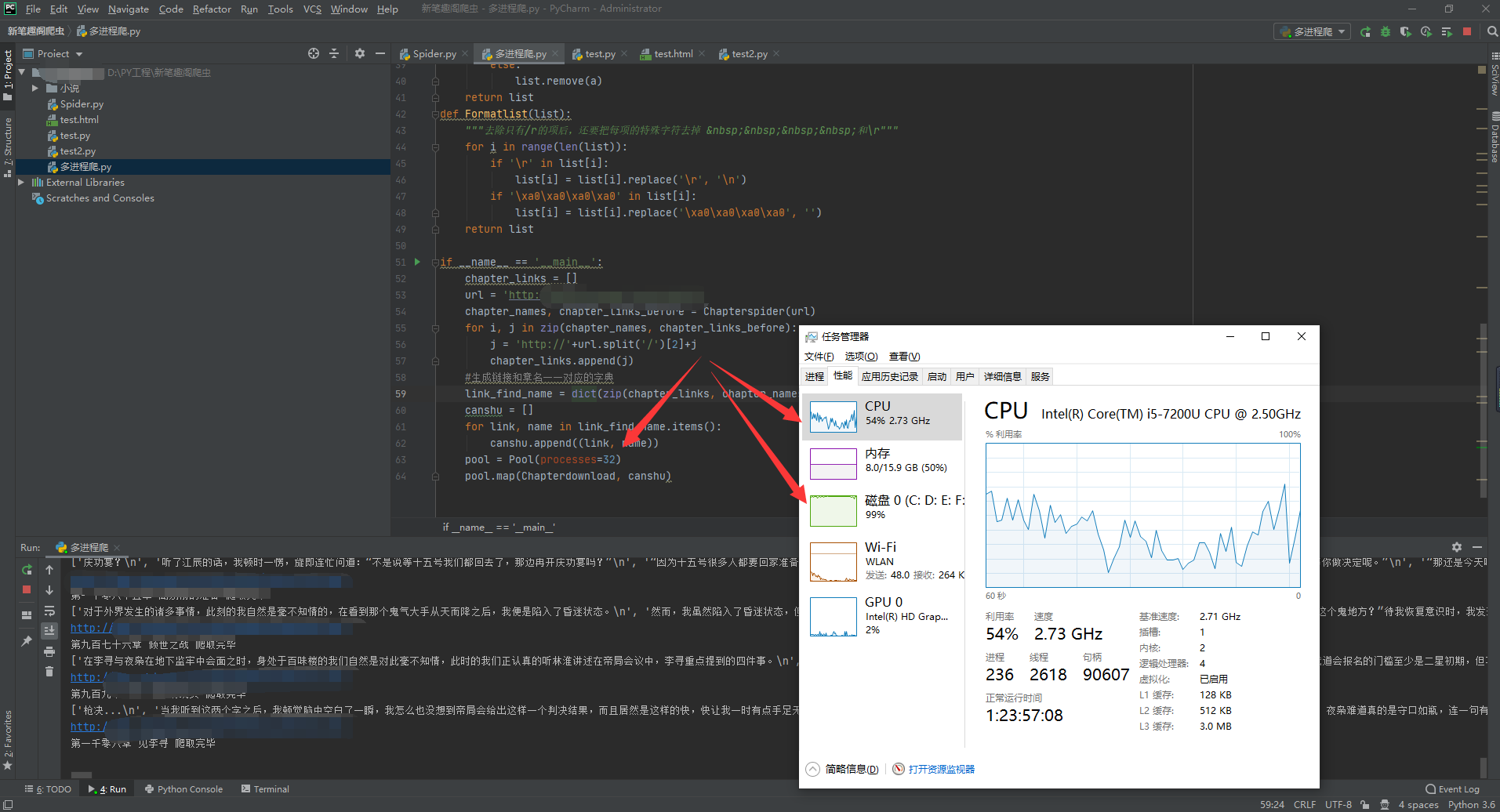
我开了32个进程,磁盘占用100%直接满了,10几秒搞定1400+章!(其实进程数跟cpu核心数一样就可以了)
我开始用单进程试过,太慢了,每秒才3章左右,一部小说全部爬完得好几分钟,于是开始了多进程之旅,速度快了20倍左右!
先给你们看下成果我再继续讲吧。
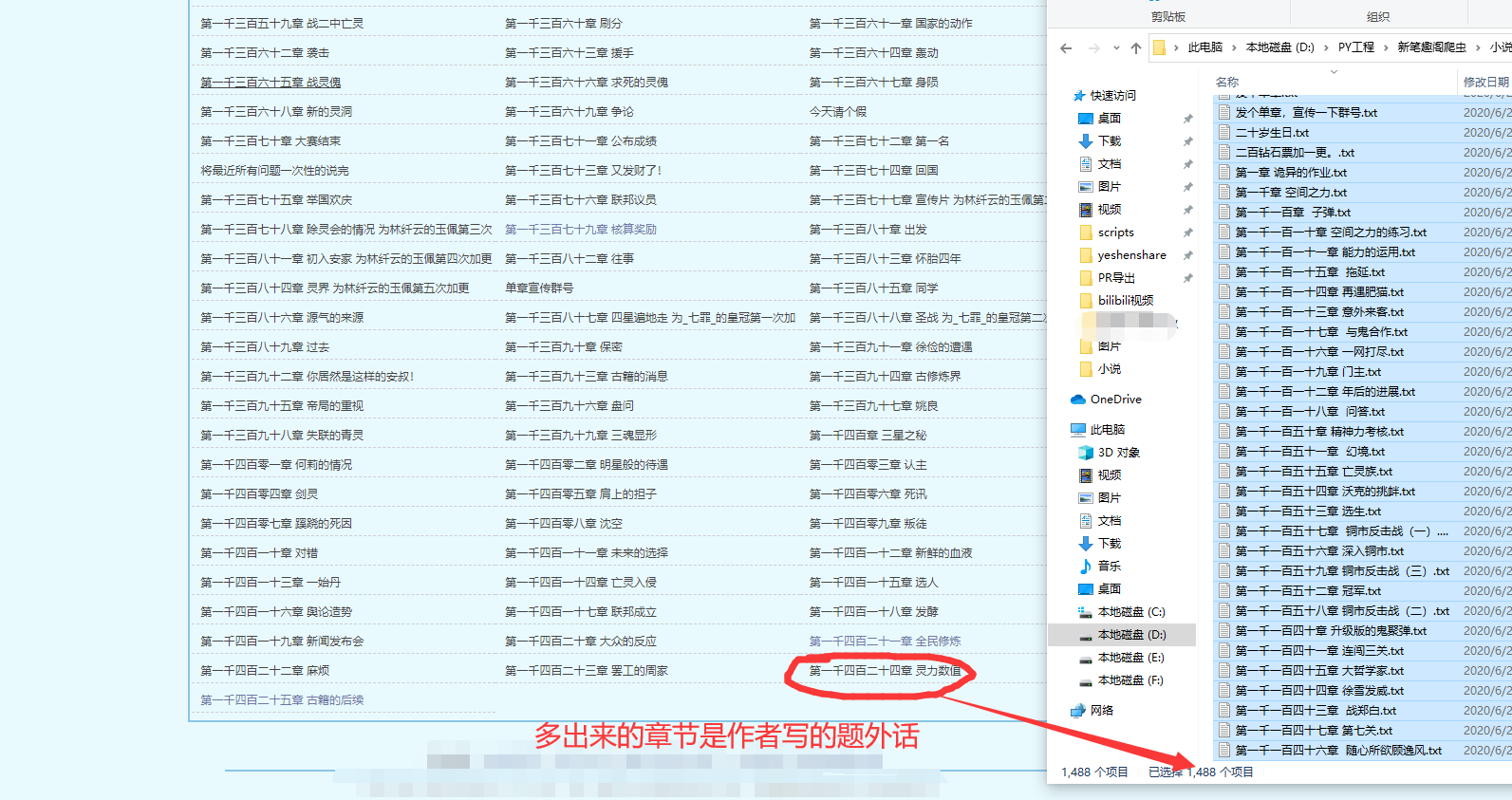
有耐心看到这里的朋友我可以给你们提示一下,所有小说网站,只要你看他是上图这个目录结构,基本上网页架构都是一样的,在我的源码里填上链接就可以爬。但不能爬也别怪我,我说了是基本上,没有说完全哈,重要的是思路。
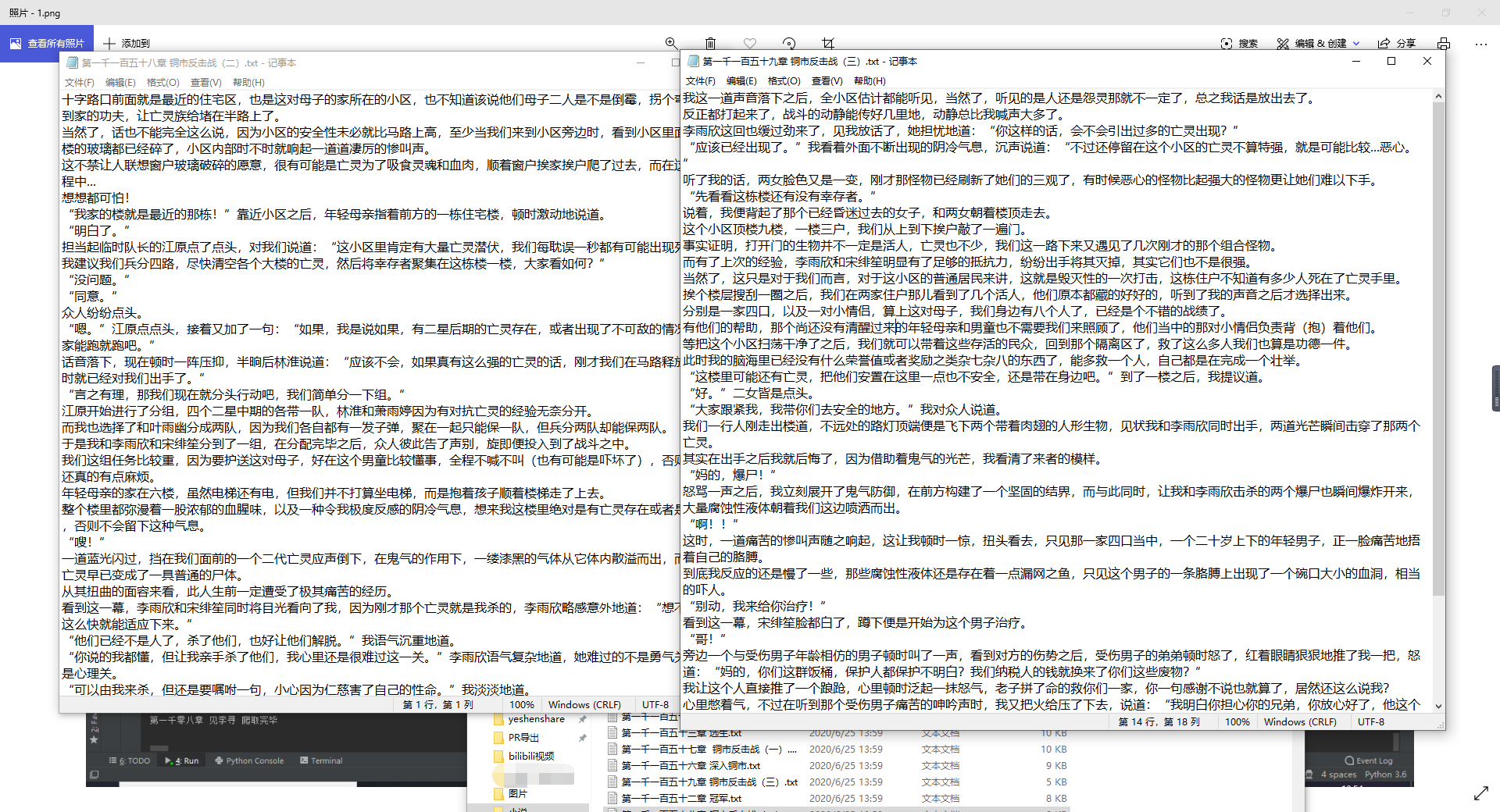
可以看到全部成功爬取,这些txt你们自己用软件合并可以做成带目录的pdf阅读,或者直接合并txt,在有些app上也是可以自动根据文字生成目录的。
阅读效果也是很不错的,没有乱码,段落明显!
为了防止侵权,这是我的源码改动,仅此一处有网址,就是上上个图的目录网址:
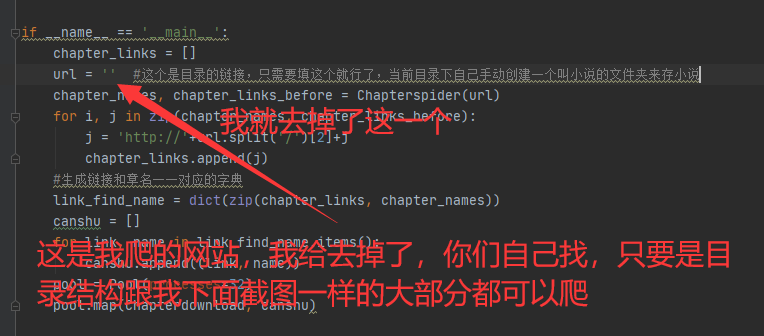
源码说明在注释里,分工很明确,主要是多进程,我开了32个,其实太多了,你们按照自己的想法改就行。
[Python] 纯文本查看 复制代码
import requests
from lxml import etree
from multiprocessing import Pool
def Chapterspider(self):
"""章节爬虫,参数传入目录,返回(章节名称, 对应页面链接)的列表"""
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36'
}
content = requests.get(url, headers=headers).content
html = etree.HTML(content)
chapter_names = html.xpath('//dd/a/text()')
chapter_links = html.xpath('//dd/a/@href')
return chapter_names, chapter_links
def Chapterdownload(turple):
"""章节下载成对应的txt,这个url参数指每一页的链接,chapter_link"""
url = turple[0]
name = turple[1]
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36'
}
rsp = requests.get(url, headers=headers)
content = rsp.content
html = etree.HTML(content)
content_list = html.xpath('//div[@id="content"]//text()')
content_list = Remove_r(content_list, "\r")
content_list = Formatlist(content_list)[:-2]
with open('小说/'+name+'.txt', 'w', encoding='utf-8') as f:
f.writelines(content_list)
print(content_list)
print(url)
print(name, '爬取完毕')
def Remove_r(list, a):
"""去除列表中含字符串a的项"""
while True: # 无限循环,利用break退出
if a not in list: # 判断"a"在不在char_list里,不在就break。否则执行删除“a”的操作
break
else:
list.remove(a)
return list
def Formatlist(list):
"""去除只有/r的项后,还要把每项的特殊字符去掉 和\r"""
for i in range(len(list)):
if '\r' in list[i]:
list[i] = list[i].replace('\r', '\n')
if '\xa0\xa0\xa0\xa0' in list[i]:
list[i] = list[i].replace('\xa0\xa0\xa0\xa0', '')
return list
if __name__ == '__main__':
chapter_links = []
url = '' #这个是目录的链接,只需要填这个就行了,当前目录下自己手动创建一个叫小说的文件夹来存小说
chapter_names, chapter_links_before = Chapterspider(url)
for i, j in zip(chapter_names, chapter_links_before):
j = 'http://'+url.split('/')[2]+j
chapter_links.append(j)
#生成链接和章名一一对应的字典
link_find_name = dict(zip(chapter_links, chapter_names))
canshu = []
for link, name in link_find_name.items():
canshu.append((link, name))
pool = Pool(processes=32)
pool.map(Chapterdownload, canshu)
如果你觉得有用请给我一点免费的评分支持一下,谢谢咯! | 
 [复制链接]
[复制链接]
 发表于 2020-6-25 14:43
发表于 2020-6-25 14:43
 |
发表于 2020-6-25 15:10
|
发表于 2020-6-25 15:10
 发表于 2020-6-25 17:10
发表于 2020-6-25 17:10




 ios端的能理解,如果是安卓的那大佬,别麻烦的下载了,直接把软件破了吧
ios端的能理解,如果是安卓的那大佬,别麻烦的下载了,直接把软件破了吧

