Python协程爬虫实现断点续爬与分布式爬虫原理举例
具体网站我已经去除,该代码仅作编程技术的学习交流
前言
之前几次都是在写多线程或者是多进程的爬虫,其实Python里最强的还是协程爬虫,因为对于这类I/O密集型任务,用多进程就是杀鸡用牛刀,太消耗系统资源了,而Python里的多线程又有个GIL(全局锁),这导致Python的多线程其实是一个“假的”多线程,所以协程的优势就体现出来了,协程也叫微线程,会在I/O阻塞时自动将任务转向其它协程和主线程,并且消耗的资源极小。如果我们开3000个线程,普通电脑很有可能蓝屏,但我们即使开10000个协程,电脑也没什么感觉,效果却可以和10000个线程相媲美,因此,其实协程才是最适合爬虫的。
先给你们看看协程的速度,(单线程时只有几百K/s),这个站点50多g图片单线程要爬46个小时才能爬完,协程只需要一个半小时。
断点续爬
1.我们知道,像这种资源很多的网站,有的地方爬的时候会出现一些莫名其妙的错误,因此我们需要用try来执行所有的requests.get(),当出错时重复执行5次,直到成功,如下:
try:
rsp = requests.get(url, headers=headers, timeout=5)
print(rsp.status_code)
with open(img_path+img_name, 'wb') as f:
f.write(rsp.content)
except requests.exceptions.Timeout:
print('超时')
try:
for i in range(5):
rsp = requests.get(url, headers=headers, timeout=5)
if rsp.status_code == 200:
with open(img_path + img_name, 'wb') as f:
f.write(rsp.content)
break
except:
print('出错')
pass
2.但即使这样,也并不能保证那重复执行的5次中就能有一次成功,而且这么庞大的数据量,有时候无法一次爬完,中途程序如果中断,又得重爬岂不是得不偿失?因此我们引入了断点续爬,断点续爬有很多种方式,我这里用的是最稳健的一种方法,那就是引入mongo数据库,如下图:
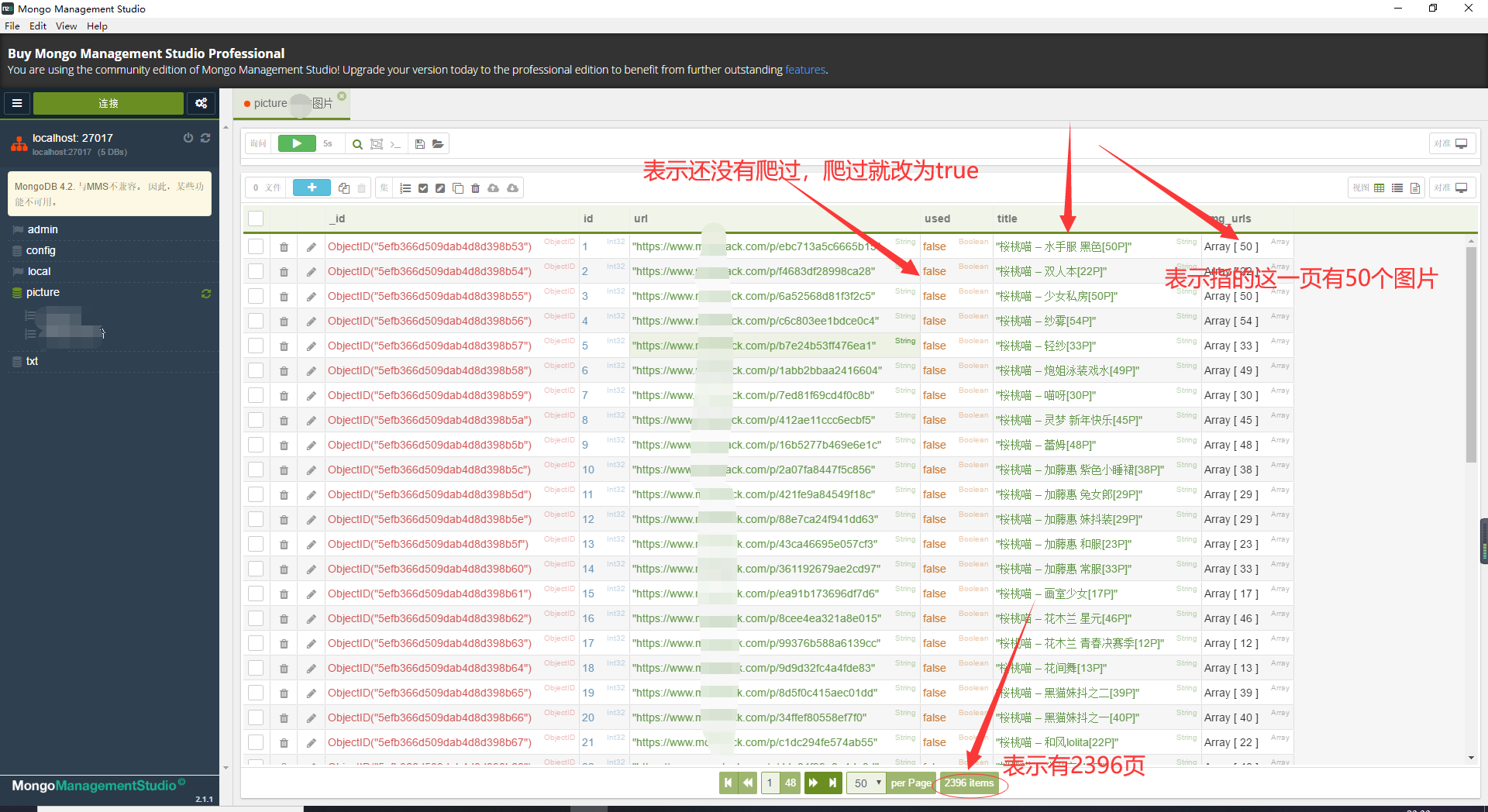
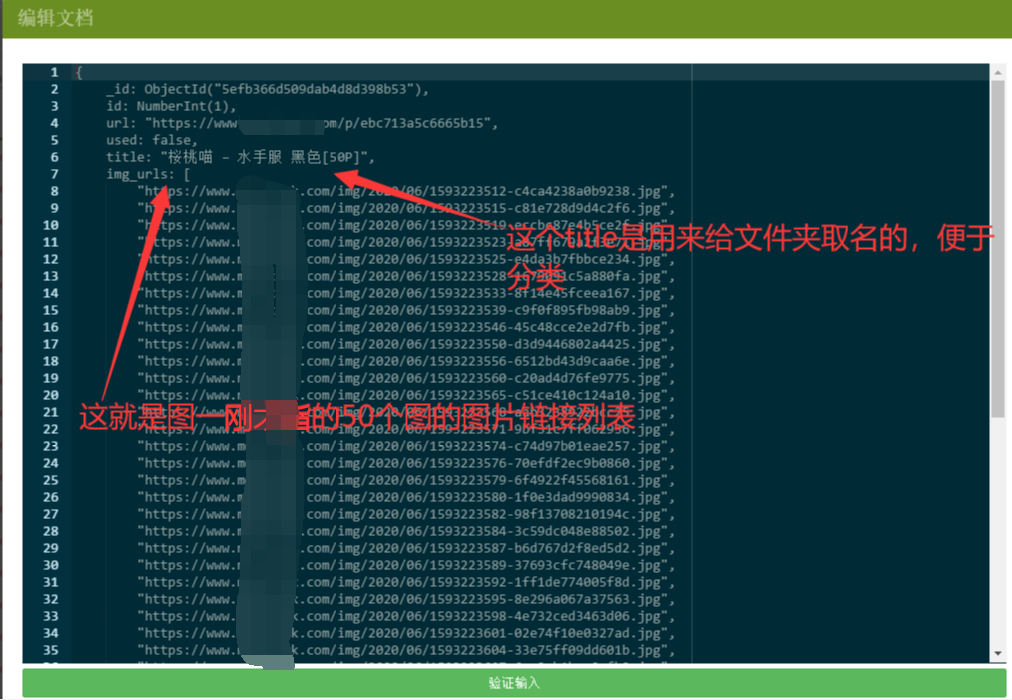
我们可以看出,首先我们把所有要爬取的页面链接和页面里的图片链接都存储在了mongo数据库里,url字段指页面链接,img_urls字段指那一页的所有图片链接,title是标题,也是后面给不同图片下载到不同文件夹分类的依据,最重要的是used字段,这个字段的值直接控制着我们这一页图片是否爬取完毕,爬取完毕我们就更新其值为true,每次我们都查询used值为false的字段来爬取就可以实现断点续爬了,下图更详细:
3.既然我们所有的需要爬的信息,和断点续爬的方法都实现了,那么我们就要开始构建下载图片的函数了:
def Download(url, path_to):
img_path = path+'/'+path_to+'/'
if not os.path.exists(img_path):
os.mkdir(img_path)
img_name = url.split('/')[-1]
try:
rsp = requests.get(url, headers=headers, timeout=5)
print(rsp.status_code)
with open(img_path+img_name, 'wb') as f:
f.write(rsp.content)
except requests.exceptions.Timeout:
print('超时')
try:
for i in range(5):
rsp = requests.get(url, headers=headers, timeout=5)
if rsp.status_code == 200:
with open(img_path + img_name, 'wb') as f:
f.write(rsp.content)
break
except:
print('出错')
pass
def Spider(item):
path_to = item['title']
img_urls = item['img_urls']
g2 = []
try:
for url in img_urls:
Download(url, path_to)
"""g2.append(gevent.spawn(Download, url, path_to))
gevent.joinall(g2)"""
item['used'] = True
print('下载完毕', item)
collection.update({'id': item['id']}, item)
except:
pass
4.函数构造完毕后我们设置程序入点,开始执行!
if __name__ == '__main__':
if not os.path.exists(path):
os.mkdir(path)
needed_all = collection.find({'used': False})
g = []
for item in needed_all:
g.append(gevent.spawn(Spider, item))
gevent.joinall(g)
这样我们不管什么时候中断,第4行代码只拿used字段为false的记录,而爬取完毕的记录的used字段已经全部被更新为true了,所以我们实现了断点续爬。
5.以下为本次程序导入的包和全局变量
from gevent import monkey; monkey.patch_all()
import pymongo, requests, gevent, os
path = 'G:/储藏室/图片/'
client = pymongo.MongoClient(host='localhost', port=27017)
db = client['picture']
collection = db['数据库名']
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36'
}
6.总结
至此,我们的断点续爬就已经完成了!这也是协程全部的完整源码,一行都没有少的,数据在数据库里,别人网站50多G的图片数据,我怕违规,所以数据库没发出来,但我们主要也是交流思路方法,所以我觉得没有数据库就显得并不重要了。
分布式爬虫
1.什么是分布式爬虫
前面我们所讲的,不论是多线程还是多进程还是协程,全部都是在一台电脑上完成的,而分布式爬虫则是将多台主机组合起来,共同完成一个爬取任务,这将大大提高爬取的效率。
2.分布式爬虫实现的难点
有人这时会想,我连多线程之间的数据共享都搞不清楚,你让我在多台电脑里共享数据?这也是给很多新手劝退的地方,但其实并没有你想的那么复杂。
3.分布式爬虫实现的方法
我们知道,多线程之间共享数据,要么用线程锁,要么用队列Queue,多进程共享数据,需要用到多进程模块下特有的Queue,那多台电脑之间共享数据也当然有其独特的方法。
就拿我刚才断点续爬举的例子,如果我们把数据库假设在一台公网服务器上,供其它所有主机连接,然后把used字段的值设为1、2、3。1表示还未爬取的,2表示正在爬取的,3表示爬取完毕的,每台主机拿走数据库里的一条记录时,我们把used值更新为2,如果爬取失败,再将used值更新回1,成功就把used值更新为3,每次我们只拿used值为1的记录不就可以实现共享数据加断点续爬了吗?
4.总结
当然,这并不是唯一的方法,但这是很容易理解的方法,真正的分布式爬虫需要考虑的比我所讲的其实还是要多一些的,但总的原理就是这样,欢迎大家评论交流。

 [复制链接]
[复制链接]

 发表于 2020-7-1 09:01
发表于 2020-7-1 09:01
 |
发表于 2020-7-1 10:10
|
发表于 2020-7-1 10:10




