一、前言
前置技能链接:
DEX文件解析---1、dex文件头解析
DEX文件解析---2、Dex文件checksum(校验和)解析
DEX文件解析--3、dex文件字符串解析
DEX文件解析--4、dex类的类型解析
DEX文件解析--5、dex方法原型解析
DEX文件解析--6、dex文件字段和方法定义解析
PS:Dex文件解析到现在,终于到了最重要也是结构最复杂的部分了,不了解前面的一些必要知识的,可以看我前面几篇文章;这篇文章分析的dex样本来自一个复杂apk的dex文件,但是代码运行时使用的样本是一个在网上找的很简单的dex样本,原因很简单,分析使用的dex涉及的smali指令太多了,大概有200多个,挨个解析起来工作量太大了,有时间我会写一个通用的python解析模块,完成了我会上传到github仓库,有兴趣的完成后可以看一下,用简单的dex只涉及到5个指令,代码写起来就没那么麻烦了!!!(tips:Dex类数据这里解析起来有种俄罗斯套娃的感觉,多看几篇就很容易理解了。)
PS:这篇文章及其之前同系列的整合版(只是所有文章汇总在一起的整合版)都发在某公众号上面了,名字就不说了,怕被认为打广告,所以这不是抄袭哦!!!
二、uleb128编码
PS:本来关于uleb128编码网上一大堆,没必要写这个,但是网上的你抄我的我抄你的,能找的的相关资料基本都一样。。。。或者干脆贴个官方代码,官方代码的位运算写的很巧妙,但是直接去看的化,反正我是没看懂到底是怎么解码出来的。
uleb128编码,是一种可变长度的编码,长度大小为1-5字节,uleb128通过字节的最高位来决定是否用到下一个字节,如果最高位为1,则用到下一个字节,直到某个字节最高位为0或已经读取了5个字节为止,接下来通过一个实例来理解uleb128编码。
假设有以下经过uleb128编码的数据(都为16进制)--81 80 04,首先来看第一个字节81,他的二进制为10000001,他的最高位为1,则说明还要用到下一个字节,它存放的数据则为0000001;再来看第二个字节80,它的二进制为10000000,它的最高位为1,则说明还需要用到第三个字节,存放的数据为0000000;再来看第三个字节04,它的二进制为00000100,最高位为0,说明一共使用了三个字节,它存放的数据为0000100;通过上面的数据我们已经获取了存放的数据,接下来就是把这些bit组合起来获取解码后的数据,dex文件里面的数据都是采用的小端序的方式,uleb128也不例外,在这三个字节,也不例外,第三个字节04存放的数据0000100作为解码后的数据的高7位,第二个字节80存放的数据0000000作为解码后的数据的中7位,第一个字节81存放的数据0000001作为解码后的数据的低7位;那么解码后的数据二进制则为0000100 0000000 0000001,转换为16进制则为0x10001。其他使用5个字节、4个字节照此类推即可,下面是python读取uleb128的代码(ps:该代码是最终类数据解析代码的一共函数,无法单独运行,仅供参考,采用的是官方提供的位运算算法):
def readuleb128(f,addr):
result = [-1,-1]
n = 0
f.seek(addr)
data = oneByte2Int(f.read(1))
if data > 0x7f:
f.seek(addr + 1)
n = 1
tmp = oneByte2Int(f.read(1))
data = (data & 0x7f) | ((tmp & 0x7f) << 7)
if tmp > 0x7f:
f.seek(addr + 2)
n = 2
tmp = oneByte2Int(f.read(1))
data |= (tmp & 0x7f) << 14
if tmp > 0x7f:
f.seek(addr + 3)
n = 3
tmp = oneByte2Int(f.read(1))
data |= (tmp & 0x7f) << 21
if tmp > 0x7f:
f.seek(addr + 4)
n = 4
tmp = oneByte2Int(f.read(1))
data |= tmp << 28
result[0] = data
result[1] = addr + n + 1
return result
三、类解析第一层结构:class_def_item
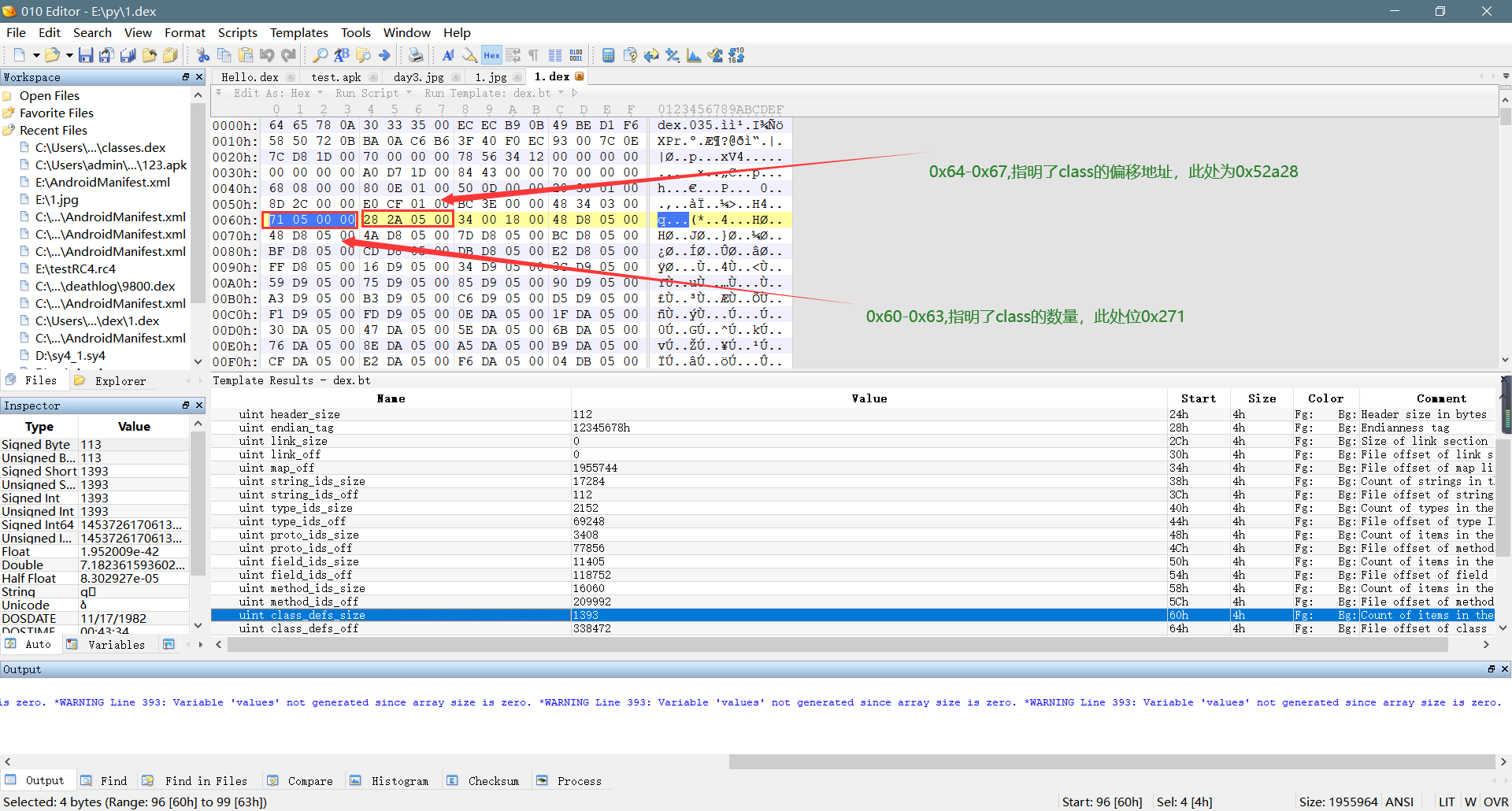
1、在dex文件头0x60-0x63这四个字节,指明了class的数量,在0x64-0x67这四个字节,指明的class_def_item的偏移地址。如下所示:
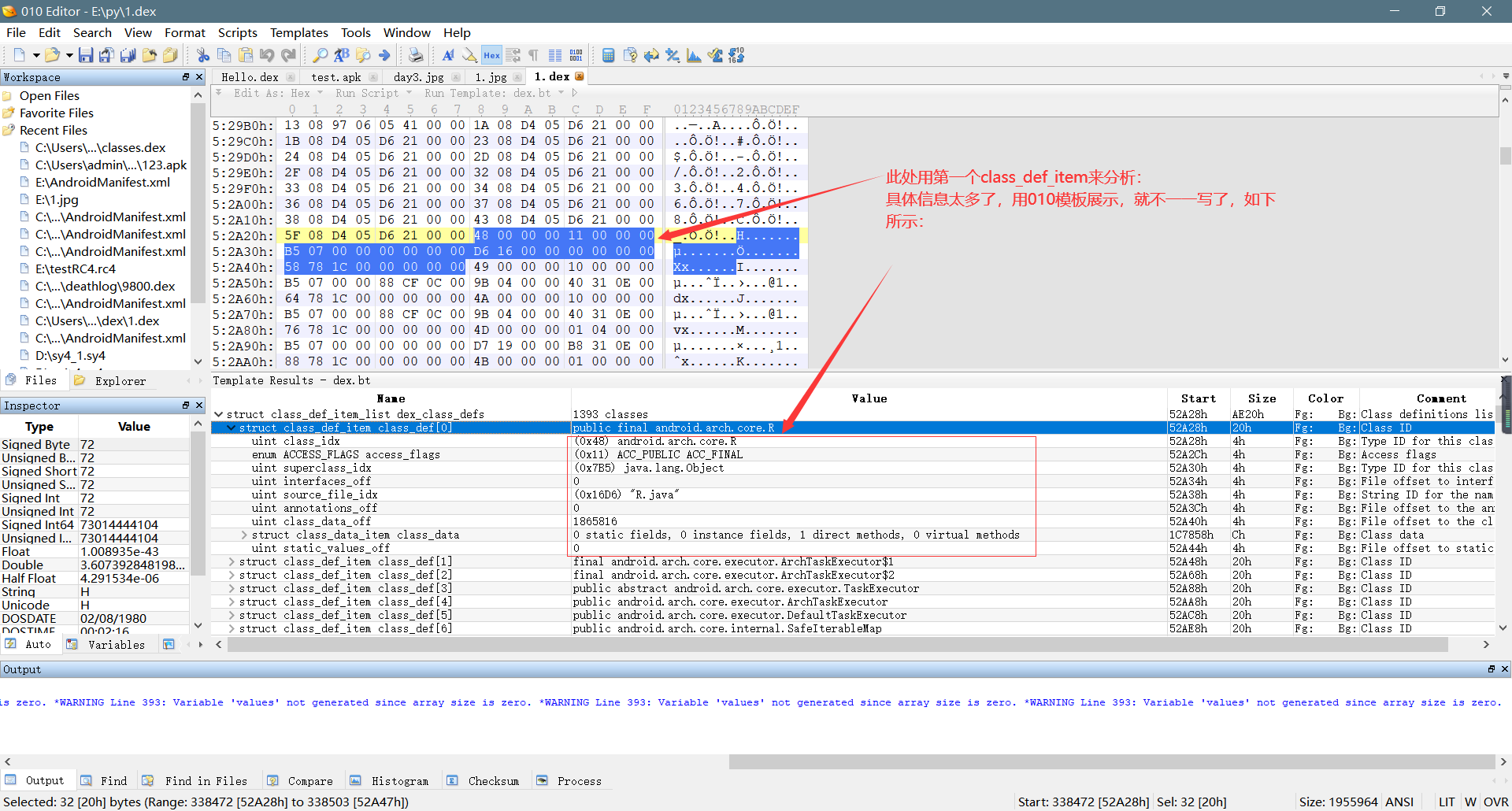
2、通过上面的偏移地址,我们可以找到class_def_item的起始地址,class_def_item包含了一个类的类名、接口、父类、所属java文件名等信息。一个class_def_item结构大小为32字节,分别包含8个信息,每个信息大小为4字节(小端序存储):
第1-4字节--class_idx(该值为前面解析出来的类的类型列表的索引,也就是这个类的类名); 第5-8字节--access_flags(类的访问标志,也就是这个类是public还是private等,这个通过官方的文档查表得知,具体算法在最后面说明); 第9-12字节--superclass_idx(该值也为前面解析出来的类的类型列表的索引,指明了父类的类名) 第13-16字节--interfaces_off(该值指明了接口信息的偏移地址,所指向的地址结构为typelist,前面的文章有说过,这里不再多说,如果该类没有接口,该值则为0) 第17-20字节--source_file_idx(该值为dex字符串列表的的索引,指明了该类所在的java文件名) 第21-24字节--annotations_off(该值为注释信息的偏移地址,由于注释信息不是我要解析的重点,要查看注释信息具体结构的可以参考官方文档,官方文档地址粘贴在文末) 第25-28字节--class_data_off(该值是这个类数据第二层结构的偏移地址,在该结构中指明了该类的字段和方法) 第29-32字节--static_value_off(该值也是一个偏移地址,指向了一个结构,不是重点,感兴趣的参考官方文档,如果没相关信息,则该值为0)
具体分析过程,如下图所示:
四、类解析第二层结构:class_data_item
1、通过上面class_def_item的分析,我们知道了类的基本信息,例如类名、父类等啊,接下来就是要找到类里面的字段和方法这些信息,而这些信息,在class_def_item里面的class_data_off字段给我们指明class_data_item就包含这些信息并给出了偏移地址,即现在需要解析class_data_iem结构获取字段和方法信息。(ps:以下的数据结构不做特别说明都为uleb128编码格式)
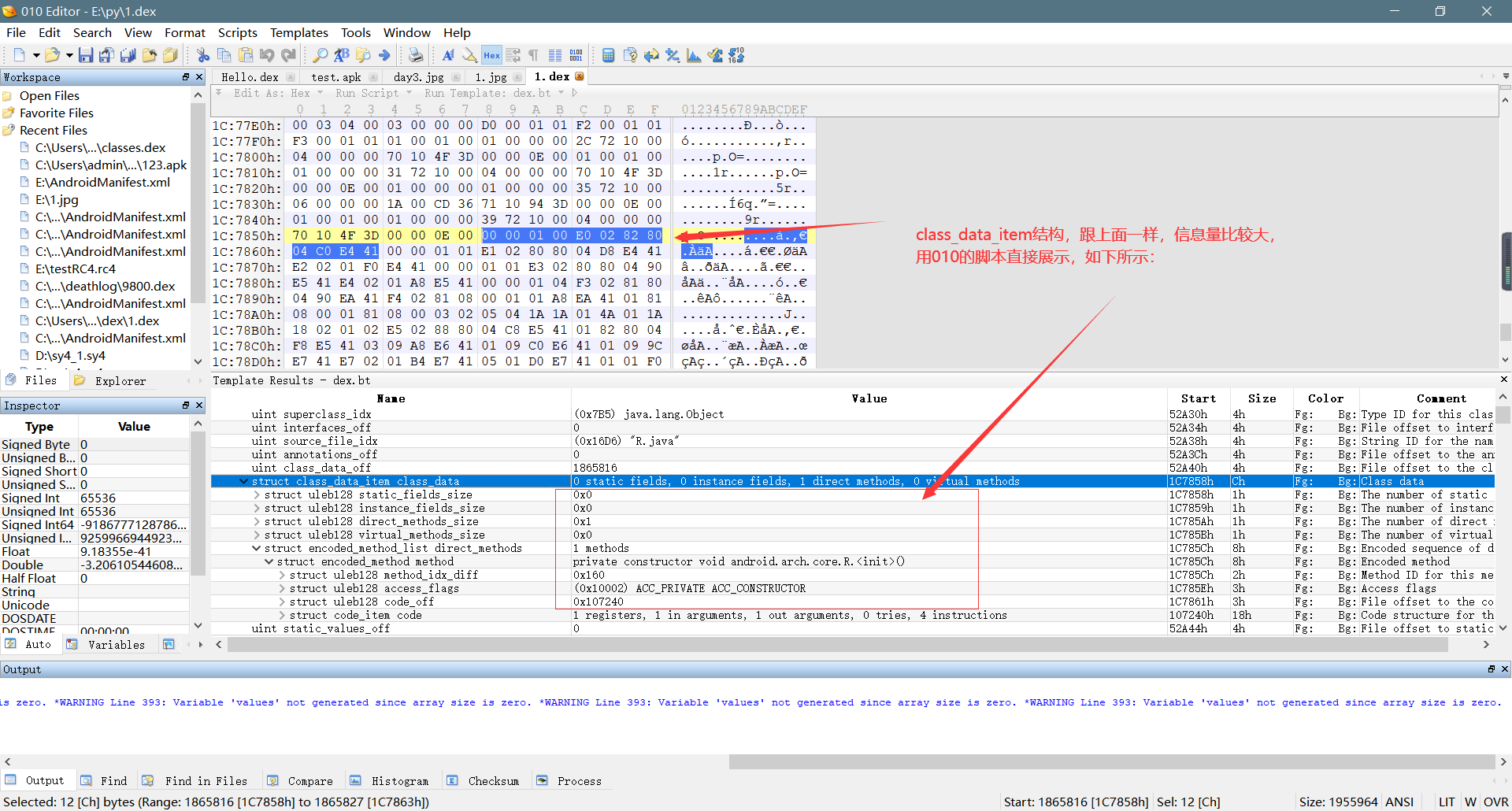
2、class_data_item结构包含以下信息:
第一个uleb128编码--static_field_size,指明了该类的静态字段的数量第二个uleb128编码--instance_field_size,指明了该类的实例字段的数量(实例字段不知道是啥的建议百度) 第三个uleb128编码--direct_method_size,指明了该类的直接方法的个数第四个uleb128编码--virtual_method_size,指明了该类的虚方法的个数(虚方法理解不清楚的建议百度一下) encoded_field--static_fields,该结构指明了具体的静态字段信息,该结构的存在前提是static_field_size >0,该结构包含两个uleb128编码,第一个uleb128编码为前面解析出来的字段列表的索引,第二个uleb128编码指明了该字段的访问标志 encoded_field--instance_fields,跟上面类似,不再多说,值得注意的是,该结构存在的前提是instance_field_size > 0 encoded_method--direct_methods,该结构指明了直接方法具体信息,该结构存在的前提同样是direct_method_size > 0,该结构包含3个uleb128编码,第一个uleb128为前面文章解析出来的方法原型列表的索引值,第二个uleb128编码为该方法的访问标志,第三个uleb128为code_off,也就是该方法具体代码的字节码的偏移地址,对应的结构为code_item,code_item结构里面包含了该方法内部的代码,这里是字节码,也就是smali(ps:如果该方法为抽象方法,例如native方法,这时code_off对应的值为0,即该方法不存在具体代码) encoded_method--virtual_methods,该结构指明了该类的虚方法的具体信息,存在前提为virtual_method_size > 0,具体结构和上面一样,不再多说
具体分析过程,如下图所示:
五、类解析的第三层结构:code_item
1、在上面的class_data_item结构中的encoded_method结构的第三个uleb128编码中,指出了一个类中的方法具体代码的偏移地址,也就是dv虚拟机在执行该方法的具体指令的偏移地址,该值指向的地址结构为code_item,里面包含了寄存器数量、具体指令等信息,下面来分析一下该结构。
2、code_item结构包含以下信息:
第1-2字节--registers_size,该值指明了该方法使用的寄存器数量,对应的smali语法中的.register的值 第3-4字节--ins_size,该值指明了传入参数的个数 第5-6字节--outs_size,该值指明了该方法内部调用其他函数用到的寄存器个数 第7-8字节--tries_size,该值指明了该方法用到的try-catch语句的个数 第9-12字节--debug_info_off,该值指明了调试信息结构的偏移地址,如果不存在调试信息,则该值为0 第13-16字节--insns_size,该值指明了指令列表的大小,可以这么理解:规定了指令所用的字节数大小--2 x insns_size ushort[insns_size]--insns,这个是指令列表,包含了该方法所用到的指令的字节,每个指令占用的字节数可以参考官方文档,这个没什么算法,就是一个查表的过程,例如invoke-direct指令占用6个字节,return-void指令占用2个字节 2个字节--padding,该值存在的前提是tries-size > 0,作用用来对齐代码 try_item--tries,该值存在的前提是tries-size > 0,作用是指明异常具体位置和处理方式,该结构不是解析重点,重点是解析指令,感兴趣的查看官方文档 encoded_catch_handler_list--handlers,该结构存在前提为tries-size > 0,同样不是解析重点,感兴趣的查看官方文档
具体分析过程,如下图所示:

六、access_flags算法
access_flags访问标志具体值可以去查看官方文档,下图只截了一部分。如果access_flags的算法为access_flags = flag1 | flag2 | ...,如果访问标志只有一共,直接查表即可,如果是两个,按照算法对比值即可,下面举给=个例子来理解该算法。

例如我有一个类的访问标志为public static,经过查表得知public对应的值为0x01,static对应的值为0x8,那么public static对应的访问标志为0x01 | 0x08 = 0x9,如果读取出来的access_flags为0x09,那么对应的访问标志则为public static,其余的照此算法计算即可!!!
七、解析代码
PS:代码运行环境推荐3.6及其以上,需要模块binascii,运行样本为Hello.dex,样本附在文末网盘链接中!!!
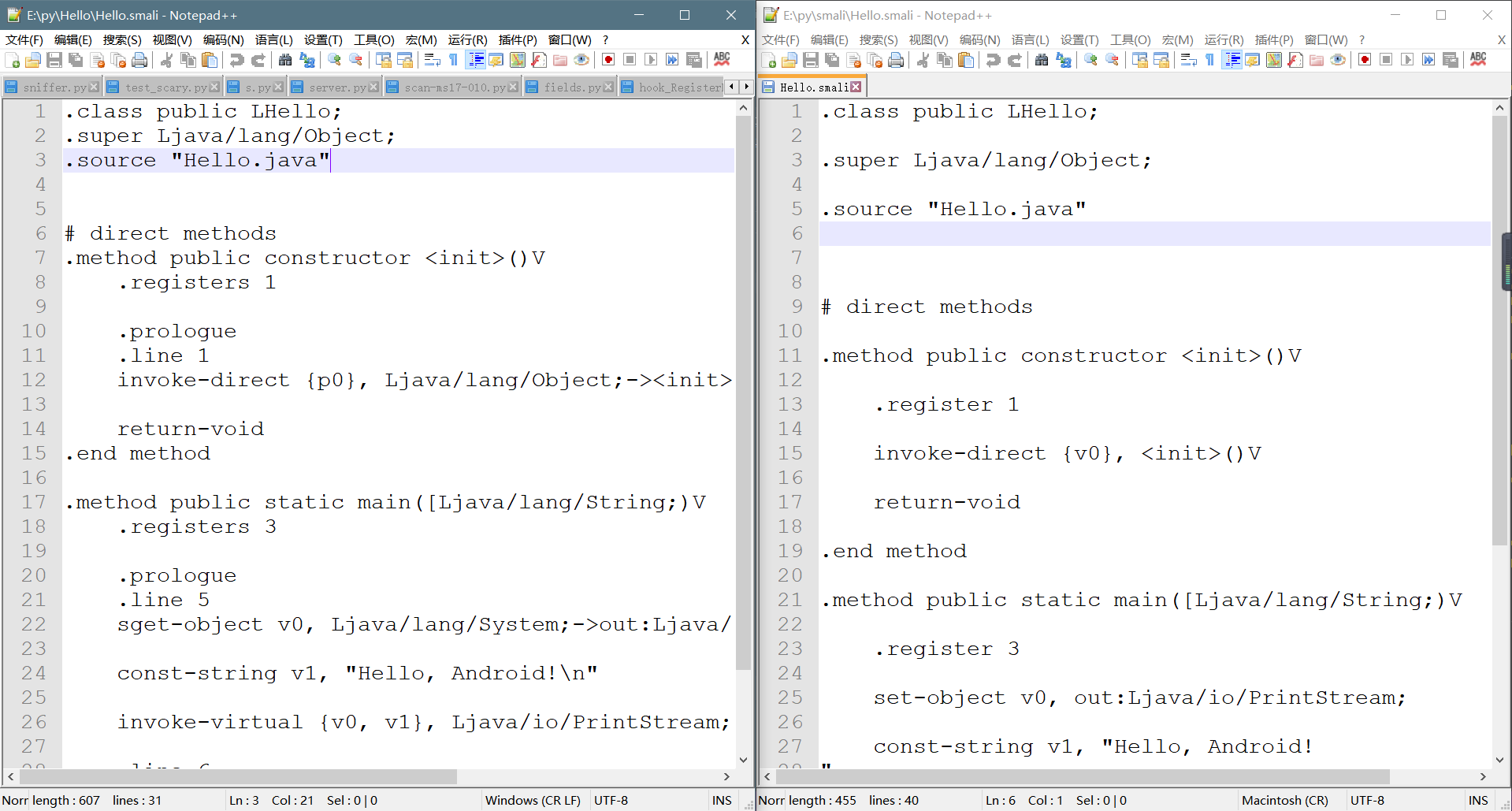
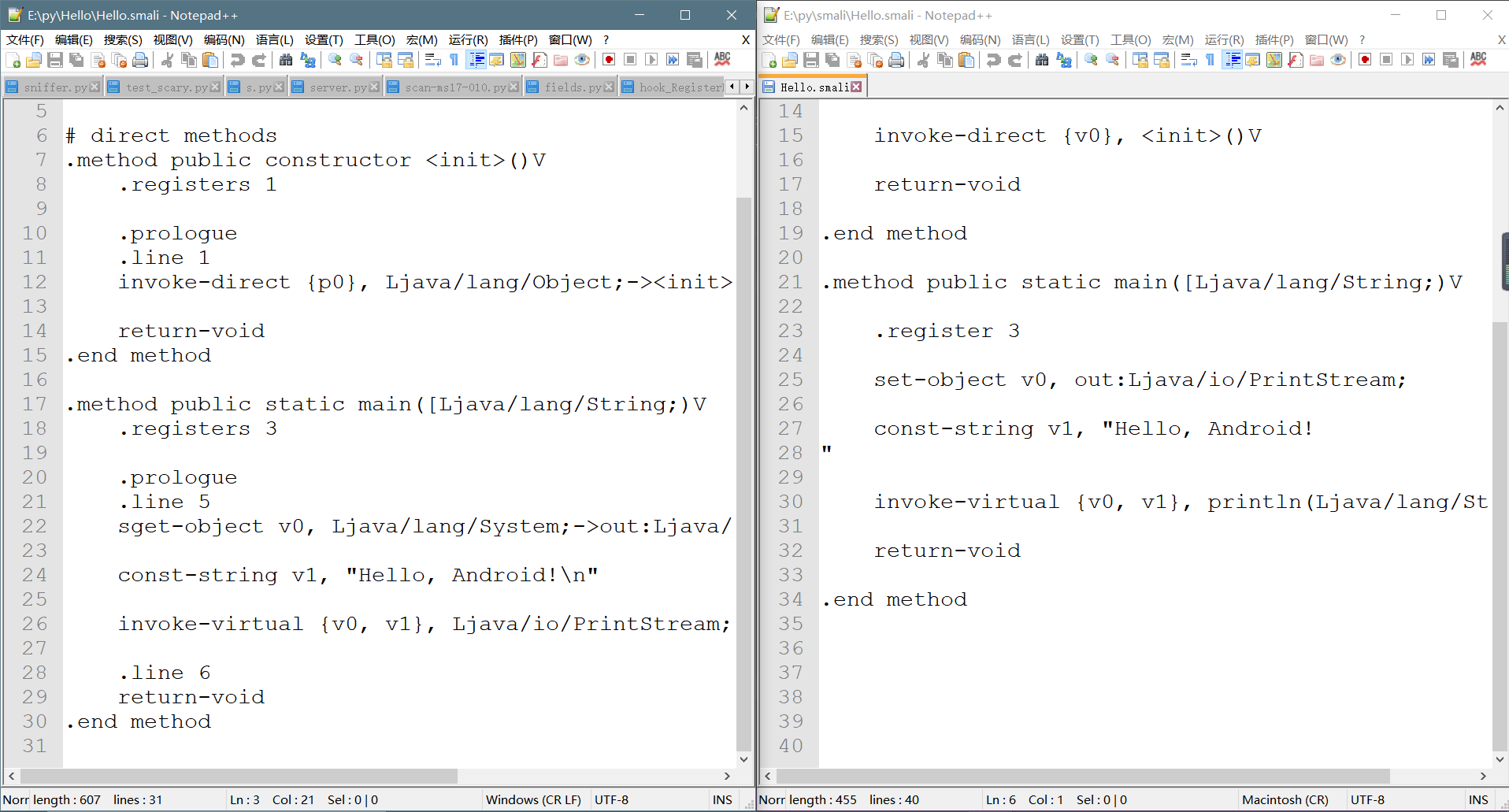
运行截图
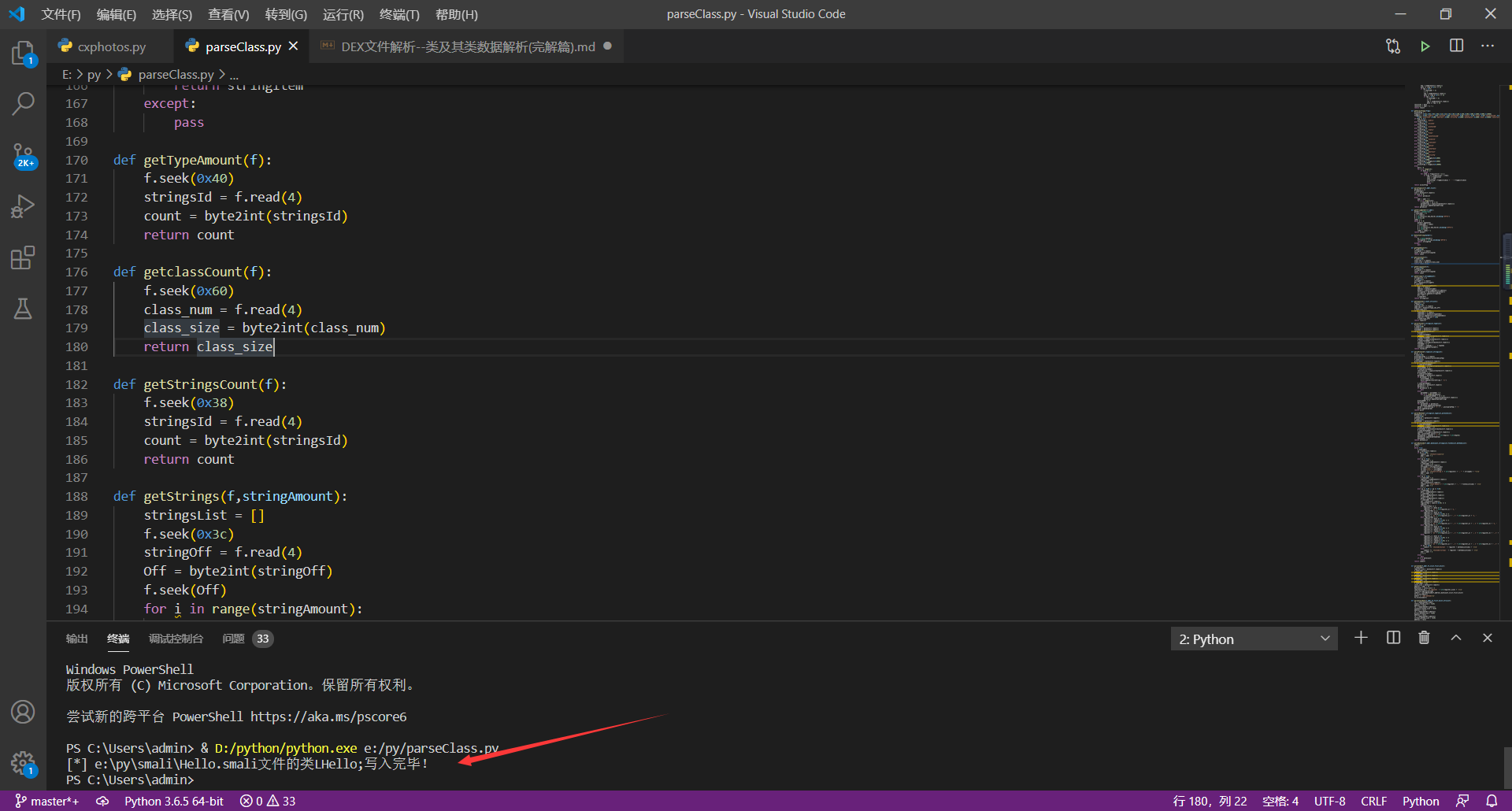
通过脚本解析出来的和通过apktools反编译出来的smali文件对比图
(ps:左侧为apktools反编译出来的,右侧为脚本解析出来的,可以发现基本差不多)
解析代码(ps:代码量有点多):
'''
__----~~~~~~~~~~~------___
. . ~~//====...... __--~ ~~
-. \_|// |||\\ ~~~~~~::::... /~
___-==_ _-~o~ \/ ||| \\ _/~~-
__---~~~.==~||\=_ -_--~/_-~|- |\\ \\ _/~
_-~~ .=~ | \\-_ '-~7 /- / || \ /
.~ .~ | \\ -_ / /- / || \ /
/ ____ / | \\ ~-_/ /|- _/ .|| \ /
|~~ ~~|--~~~~--_ \ ~==-/ | \~--===~~ .\
' ~-| /| |-~\~~ __--~~
|-~~-_/ | | ~\_ _-~ /\
/ \ \__ \/~ \__
_--~ _/ | .-~~____--~-/ ~~==.
((->/~ '.|||' -_| ~~-/ , . _||
-_ ~\ ~~---l__i__i__i--~~_/
_-~-__ ~) \--______________--~~
//.-~~~-~_--~- |-------~~~~~~~~
//.-~~~--\
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
神兽保佑 永无BUG
@Author: windy_ll
@Date: 2020-07-08 16:21:27
@LastEditors: windy_ll
@LastEditTime: 2020-07-14 23:45:28
@Description: file content
'''
import binascii
import re
import os
import sys
def byte2int(bs):
tmp = bytearray(bs)
tmp.reverse()
rl = bytes(tmp)
rl = str(binascii.b2a_hex(rl),encoding='UTF-8')
rl = int(rl,16)
return rl
def oneByte2Int(bs):
num = str(binascii.b2a_hex(bs),encoding='UTF-8')
num = int(num,16)
return num
def getSmaliName(oldname):
newname = ''
tmpname = oldname.split('.')
newname = str(os.path.join(sys.path[0])) + '\\smali\\' + str(tmpname[0]) + '.smali'
return newname
def readuleb128(f,addr):
result = [-1,-1]
n = 0
f.seek(addr)
data = oneByte2Int(f.read(1))
if data > 0x7f:
f.seek(addr + 1)
n = 1
tmp = oneByte2Int(f.read(1))
data = (data & 0x7f) | ((tmp & 0x7f) << 7)
if tmp > 0x7f:
f.seek(addr + 2)
n = 2
tmp = oneByte2Int(f.read(1))
data |= (tmp & 0x7f) << 14
if tmp > 0x7f:
f.seek(addr + 3)
n = 3
tmp = oneByte2Int(f.read(1))
data |= (tmp & 0x7f) << 21
if tmp > 0x7f:
f.seek(addr + 4)
n = 4
tmp = oneByte2Int(f.read(1))
data |= tmp << 28
result[0] = data
result[1] = addr + n + 1
return result
def getAccessFlags(flag):
accessFlag = ''
flagList = [0x01,0x02,0x04,0x08,0x10,0x20,0x40,0x80,0x100,0x200,0x400,0x800,0x2000,0x4000,0x10000]
flagdict = {0x01:'public',0x02:'private',0x04:'protected',0x08:'static',0x10:'final',0x20:'synchronized',0x40:'volatile',0x80:'transient',0x100:'native',\
0x200:'interface',0x400:'abstract',0x800:'strictfp',0x2000:'annotayion',0x4000:'enum',0x10000:'constructor'}
if flag == 0x1:
accessFlag = 'public'
elif flag == 0x2:
accessFlag = 'private'
elif flag == 0x4:
accessFlag = 'protected'
elif flag == 0x8:
accessFlag = 'static'
elif flag == 0x10:
accessFlag = 'final'
elif flag == 0x20:
accessFlag = 'synchronized'
elif flag == 0x40:
accessFlag = 'volatile'
elif flag == 0x80:
accessFlag = 'transient'
elif flag == 0x100:
accessFlag = 'native'
elif flag == 0x200:
accessFlag = 'interface'
elif flag == 0x400:
accessFlag = 'abstract'
elif flag == 0x800:
accessFlag = 'strictfp'
elif flag == 0x2000:
accessFlag = flagdict[0x2000]
elif flag == 0x4000:
accessFlag = flagdict[0x4000]
elif flag == 0x10000:
accessFlag = flagdict[0x10000]
else:
mark = 0
for k in range(14):
if mark == 1:
break
for item in flagList[(k + 1):]:
if flag == (flagList[k] | item):
idx1 = flagList[k]
idx2 = item
accessFlag = flagdict[idx1] + ' ' + flagdict[idx2]
mark = 1
break
return accessFlag
def parseTypeList(f,addr,tList):
paramList = []
f.seek(addr)
size = byte2int(f.read(4))
if size == 0:
return paramList
else:
addr = addr + 4
for k in range(size):
f.seek(addr + (k * 2))
paramString = typeList[byte2int(f.read(2))]
paramList.append(paramString)
return paramList
def getStringByteArr(f,addr):
byteArr = bytearray()
f.seek(addr + 1)
b = f.read(1)
b = str(binascii.b2a_hex(b),encoding='UTF-8')
b = int(b,16)
index = 2
while b != 0:
byteArr.append(b)
f.seek(addr + index)
b = f.read(1)
b = str(binascii.b2a_hex(b),encoding='UTF-8')
b = int(b,16)
index = index + 1
return byteArr
def BytesToString(byteArr):
try:
bs = bytes(byteArr)
stringItem = str(bs,encoding='UTF-8')
return stringItem
except:
pass
def getTypeAmount(f):
f.seek(0x40)
stringsId = f.read(4)
count = byte2int(stringsId)
return count
def getclassCount(f):
f.seek(0x60)
class_num = f.read(4)
class_size = byte2int(class_num)
return class_size
def getStringsCount(f):
f.seek(0x38)
stringsId = f.read(4)
count = byte2int(stringsId)
return count
def getStrings(f,stringAmount):
stringsList = []
f.seek(0x3c)
stringOff = f.read(4)
Off = byte2int(stringOff)
f.seek(Off)
for i in range(stringAmount):
addr = f.read(4)
address = byte2int(addr)
byteArr = getStringByteArr(f,address)
stringItem = BytesToString(byteArr)
stringsList.append(stringItem)
Off = Off + 4
f.seek(Off)
return stringsList
def getTypeItem(f,count,strLists):
typeList = []
f.seek(0x44)
type_ids_off = f.read(4)
type_off = byte2int(type_ids_off)
f.seek(type_off)
for i in range(count):
typeIndex = f.read(4)
typeIndex = byte2int(typeIndex)
typeList.append(strLists[typeIndex])
type_off = type_off + 0x04
f.seek(type_off)
return typeList
def parserField(f,stringList,typelist):
fieldList = []
f.seek(0x50)
fieldSize = byte2int(f.read(4))
fieldAddr = byte2int(f.read(4))
for i in range(fieldSize):
fieldStr = ''
f.seek(fieldAddr)
classIdx = typelist[byte2int(f.read(2))]
f.seek(fieldAddr + 2)
typeIdx = typelist[byte2int(f.read(2))]
f.seek(fieldAddr + 4)
nameIdx = stringList[byte2int(f.read(4))]
fieldAddr += 8
fieldStr = nameIdx + ':' + typeIdx
fieldList.append(fieldStr)
return fieldList
def parseProtold(f,typeList,stringList):
pList = []
f.seek(0x48)
protoldSizeTmp = f.read(4)
protoldSize = byte2int(protoldSizeTmp)
f.seek(0x4c)
protoldAddr = byte2int(f.read(4))
for i in range(protoldSize):
f.seek(protoldAddr)
AllString = stringList[byte2int(f.read(4))]
protoldAddr += 4
f.seek(protoldAddr)
returnString = typeList[byte2int(f.read(4))]
protoldAddr += 4
f.seek(protoldAddr)
paramAddr = byte2int(f.read(4))
if paramAddr == 0:
protoldAddr += 4
pList.append(returnString + '()')
continue
f.seek(paramAddr)
paramSize = byte2int(f.read(4))
paramList = []
if paramSize == 0:
pass
else:
paramAddr = paramAddr + 4
for k in range(paramSize):
f.seek(paramAddr + (k * 2))
paramString = typeList[byte2int(f.read(2))]
paramList.append(paramString)
protoldAddr += 4
paramTmp = []
for paramItem in paramList:
paramTmp.append(paramItem)
param = returnString + '(' + ','.join(paramTmp) + ')'
pList.append(param)
return pList
def parserMethod(f,stringlist,typelist,protoldlist):
methodlist = []
f.seek(0x58)
methodSize = byte2int(f.read(4))
f.seek(0x5c)
methodAddr = byte2int(f.read(4))
for i in range(methodSize):
f.seek(methodAddr)
classIdx = typelist[byte2int(f.read(2))]
f.seek(methodAddr + 2)
protoldIdx = protoldlist[byte2int(f.read(2))]
f.seek(methodAddr + 4)
nameIdx = stringlist[byte2int(f.read(4))]
tmp = protoldIdx.split('(',1)
methodItem = nameIdx + '(' + str(tmp[1]) + str(tmp[0])
methodlist.append(methodItem)
methodAddr += 8
return methodlist
def parseBytecode(f,addr,bytecount,stringsList,fieldsList,methodsList):
codestr = ''
n = 0
while True:
f.seek(addr)
op = byte2int(f.read(1))
if op == 0x0e:
codestr += '\treturn-void\r\n'
addr = addr + 2
n += 2
elif op == 0x1a:
f.seek(addr + 1)
register = oneByte2Int(f.read(1))
f.seek(addr + 2)
idx = byte2int(f.read(2))
stringIdx = stringsList[idx]
re.sub("[\n]","",stringIdx)
re.sub("[\r]","",stringIdx)
codestr += '\tconst-string v' + str(register) + ', "' + stringIdx + '"\r\n'
addr = addr + 4
n += 4
elif op == 0x62:
f.seek(addr + 1)
register = oneByte2Int(f.read(1))
f.seek(addr + 2)
idx = byte2int(f.read(2))
codestr += '\tset-object v' + str(register) + ', ' + fieldsList[idx] + '\r\n'
addr = addr + 4
n += 4
elif op == 0x70 or op == 0x6e:
f.seek(addr + 1)
data = oneByte2Int(f.read(1))
f.seek(addr + 4)
data1 = oneByte2Int(f.read(1))
f.seek(addr + 5)
data2 = oneByte2Int(f.read(1))
f.seek(addr + 2)
idx = byte2int(f.read(2))
registerNum = (data & 0xf0) >> 4
register = ''
if registerNum == 1:
register_1 = data & 0xf
register = '{v' + str(register_1) + '}, '
elif registerNum == 2:
register_1 = data & 0xf
register_2 = (data1 & 0xf0) >> 4
register = '{v' + str(register_1) + ', v' + str(register_2) + '}, '
elif registerNum == 3:
register_1 = data & 0xf
register_2 = (data1 & 0xf0) >> 4
register_3 = data1 & 0xf
register = '{v' + str(register_1) + ', v' + str(register_2) + ', v' + str(register_3) + '}, '
elif registerNum == 4:
register_1 = data & 0xf
register_2 = (data1 & 0xf0) >> 4
register_3 = data1 & 0xf
register_4 = (data2 & 0xf0) >> 4
register = '{v' + str(register_1) + ', v' + str(register_2) + ', v' + str(register_3) + ', v' + str(register_4) + '}, '
else:
register_1 = data & 0xf
register_2 = (data1 & 0xf0) >> 4
register_3 = data1 & 0xf
register_4 = (data2 & 0xf0) >> 4
register_5 = data2 & 0xf
register = '{v' + str(register_1) + ', v' + str(register_2) + ', v' + str(register_3) + ', v' + str(register_4) + ', v' + str(register_5) + '}, '
if op == 0x70:
codestr += '\tinvoke-direct ' + register + methodsList[idx] + '\r\n'
else:
codestr += '\tinvoke-virtual ' + register + methodsList[idx] + '\r\n'
addr = addr + 6
n += 6
else:
pass
if n == bytecount:
break
return codestr
def parseCode(f,addr,fn,slist,flist,mlist):
f.seek(addr)
register_size = byte2int(f.read(2))
f.seek(addr + 2)
ins_size = byte2int(f.read(2))
f.seek(addr + 4)
out_size = byte2int(f.read(2))
f.seek(addr + 6)
try_size = byte2int(f.read(2))
f.seek(addr + 8)
debug_off = byte2int(f.read(4))
f.seek(addr + 12)
insns_size = byte2int(f.read(4))
address = addr + 16
bytecount = insns_size * 2
registerString = '\t.register ' + str(register_size) + '\r\n'
fn.write(registerString)
codestr = parseBytecode(f,address,bytecount,slist,flist,mlist)
fn.write(codestr)
endstr = '.end method\r\n'
fn.write(endstr)
def parseClassData(f,addr,fn,fList,mList,strsList):
re = readuleb128(f,addr)
static_fields_size = re[0]
address = re[1]
re = readuleb128(f,address)
instance_fields_size = re[0]
address = re[1]
re = readuleb128(f,address)
direct_method_size = re[0]
address = re[1]
re = readuleb128(f,address)
virtual_method_size = re[0]
address = re[1]
fieldStr = ''
if static_fields_size != 0:
fieldStr += '# static fields\r\n'
for i in range(static_fields_size):
re = readuleb128(f,address)
fieldidx = re[0]
address = re[1]
re = readuleb128(f,address)
accflag = re[0]
address = re[1]
fieldStr += '.field ' + getAccessFlags(accflag) + ' ' + fList[fieldidx] + '\r\n'
fieldStr += '\r\n\r\n'
fn.write(fieldStr)
fieldStr = ''
if instance_fields_size != 0:
fieldStr += '# instance fields\r\n'
for i in range(instance_fields_size):
re = readuleb128(f,address)
fieldidx = re[0]
address = re[1]
re = readuleb128(f,address)
accflag = re[0]
address = re[1]
fieldStr += '.field ' + getAccessFlags(accflag) + ' ' + fList[fieldidx] + '\r\n'
fieldStr += '\r\n\r\n'
fn.write(fieldStr)
methodStr = ''
if direct_method_size != 0:
methodStr += '# direct methods\r\n'
fn.write(methodStr)
for i in range(direct_method_size):
re = readuleb128(f,address)
methodidx = re[0]
address = re[1]
re = readuleb128(f,address)
accflag = re[0]
address = re[1]
re = readuleb128(f,address)
code_off = re[0]
address = re[1]
methodStr = '.method ' + getAccessFlags(accflag) + ' ' + mList[methodidx] + '\r\n'
fn.write(methodStr)
parseCode(f,code_off,fn,strsList,fList,mList)
methodStr = '\r\n\r\n'
fn.write(methodStr)
methodStr = ''
if virtual_method_size != 0:
methodStr = '# virtual methods\r\n'
fn.write(methodStr)
for i in range(virtual_method_size):
re = readuleb128(f,address)
methodidx = re[0]
address = re[1]
re = readuleb128(f,address)
accflag = re[0]
address = re[1]
re = readuleb128(f,address)
code_off = re[0]
address = re[1]
methodStr = '.method ' + getAccessFlags(accflag) + ' ' + mList[methodidx] + '\r\n'
fn.write(methodStr)
parseCode(f,code_off,fn,strsList,fList,mList)
methodStr = '\r\n\r\n'
fn.write(methodStr)
def parseClassDefItem(f,class_num,tList,sList,fieldlist,methodlist):
f.seek(0x64)
addr = byte2int(f.read(4))
for i in range(class_num):
f.seek(addr)
classIdx = tList[byte2int(f.read(4))]
f.seek(addr + 4)
accessFlags = getAccessFlags(byte2int(f.read(4)))
if accessFlags != 'error':
pass
f.seek(addr + 8)
superclass_idx = tList[byte2int(f.read(4))]
f.seek(addr + 12)
interfaces_off = byte2int(f.read(4))
if interfaces_off == 0:
pass
else:
parseTypeList(f,interfaces_off,tList)
f.seek(addr + 16)
sourceFileIdx = sList[byte2int(f.read(4))]
f.seek(addr + 20)
annotions_off = byte2int(f.read(4))
address = 0
f.seek(addr + 24)
class_data_off = byte2int(f.read(4))
f.seek(addr + 28)
static_value_off = byte2int(f.read(4))
fname = getSmaliName(sourceFileIdx)
fn = open(fname,'a+',True)
headstr = '.class ' + str(accessFlags) + ' ' + str(classIdx) + '\r\n'
headstr += '.super ' + str(superclass_idx) + '\r\n'
headstr += '.source ' + '"' + str(sourceFileIdx) + '"\r\n\r\n'
fn.write(headstr)
if class_data_off != 0:
parseClassData(f,class_data_off,fn,fieldlist,methodlist,sList)
fn.close()
print(' %s文件的类%s写入完毕!'%(fname,classIdx))
addr += 32
if __name__ == '__main__':
filename = str(os.path.join(sys.path[0])) + '\\Hello.dex'
dir = str(os.path.join(sys.path[0])) + '\\smali'
if not os.path.exists(dir):
os.makedirs(dir)
f = open(filename,'rb',True)
stringsCount = getStringsCount(f)
strList = getStrings(f,stringsCount)
typeCount = getTypeAmount(f)
typeList = getTypeItem(f,typeCount,strList)
fieldList = parserField(f,strList,typeList)
protoldList = parseProtold(f,typeList,strList)
methodList = parserMethod(f,strList,typeList,protoldList)
classNum = getclassCount(f)
parseClassDefItem(f,classNum,typeList,strList,fieldList,methodList)
f.close()
八、参考资料以及样本下载
参考资料:
1、Android逆向之旅—解析编译之后的Dex文件格式:http://www.520monkey.com/archives/579
2、一篇文章带你搞懂DEX文件的结构:https://blog.csdn.net/sinat_18268881/article/details/55832757
3、官方文档:https://source.android.google.cn/devices/tech/dalvik/dex-format#embedded-in-class_def_item,-encoded_field,-encoded_method,-and-innerclass
样本及代码下载:
蓝奏云链接:https://wws.lanzouj.com/iG8Cuemlw4d;密码:chb6
github链接:https://github.com/windy-purple/parserDex

 [复制链接]
[复制链接]

 发表于 2020-7-16 13:35
发表于 2020-7-16 13:35
 |
发表于 2020-7-24 19:33
|
发表于 2020-7-24 19:33






