1���� �� I D��AsCenSion
2���������䣺549847849@qq.com
3��ԭ���������£�
���˽��ܣ�
���˱Ƚ�ϲ�����棬ϲ��������ͨ����������һЩ��Դ��
ԭ�����ݽ��ܣ�
�������żȻ�Ա��Ӹ���Ȥ��������������������֪��ԭ�������������̫�������أ����Ծ����Լ�д���������ر��ӡ�Դ����֪���IJ��ÿ�ѧ�������ܷ��ʵı�����վĿǰֻ��erocool��
��ַ����ҳ��https://tellmeurl.com/erocool/���İ��ַ��https://zh.erocool.me/��ͽ��ʦ�ı�����Ķ���������ԣ�
[��ͽ�椦��] ǧ�r -chitose- ����Ԓ (COMIC ����ܞ�� 2020��8�º�) [�й����U]
Ϊ��д�����档
��ַ��https://zh.erocool.me/detail/1686650o321307.html����������chrome��F12���ܷ�����ҳ�б���ͼƬ���������ӣ�
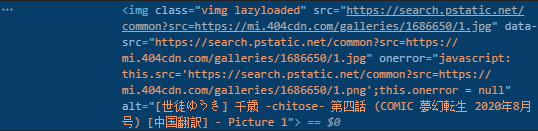
���Կ�����src=���ĺ����и���ַ��https://search.pstatic.net/common?src=https://mi.404cdn.com/galleries/1686650/1.jpg������ͼƬ���ص�ַ����һ�ԣ�ȷʵ�ǡ�
���Լ������ӣ��ɵ����ص�ַ��ʽΪ��https://search.pstatic.net/common?src=https://mi.404cdn.com/galleries/a/n.type����a�ɱ��Ӿ�����n��ҳ����typeΪ�ļ���ʽ���������Ϊjpg��С����Ϊpng��
a��ʵ���DZ��ӵ�ַ�м��һ�����֣�������re.search��ȡ��
���ѷ��������ʽ��벿��Ҳ���Թ���һ����ַ��Ϊ��https://mi.404cdn.com/galleries/a/n.type���Ժ�����Ҳ��һ��ͼƬ�����ص�ַ�����������ٶȽ�����
Ϊ���۷��㣬��A��ʽָ���ϳ��ĸ�ʽ��B��ʽָ���϶̵ĸ�ʽ��A:https://search.pstatic.net/common?src=https://mi.404cdn.com/galleries/a/n.typeB:https://mi.404cdn.com/galleries/a/n.type���߲�����£�
1.A��ʽ��ַ�����ٶȿ죬�ʺ�����ͼƬ����һ���������
2.������ֱ/ˮƽ�����ϴ�������������Ǻ�����ʱ��A��ʽ��ַ���ص�ͼƬ�����ȼ��ͣ�û��������ʱֻ��ʹ��B��ʽ���ء�
A��ʽ����������ʵ���Ͽ�����Xpath��ȡ����ʽΪ��//img[@class = "vimg lazyloaded"]/@src������ҳ��ʹ��Xpath��ȡ��û������ģ�����ʵ����pycharm�У���������ͼƬ�Ǹ������λ�������صģ����ַ��ص�html�ļ�������ȡ���������Ϣ�ġ�
��������ȡͼƬ��ʱ��������Ӿ���Ҫ�����Լ����շ��������ĸ�ʽ�������ˡ�
��͵������ص�ʱ����Ҫ�ֶ�ȷ���������ӵĸ�ʽ�Լ��ļ����͡�����v1���������Ϳ���������ˣ�����������£�import reimport requestsfrom lxml import etreeimport os# ��������# �����ļ���def mkdir(path): # �ж��Ƿ�����ļ��������������Ϊ�ļ��� # ���·�������ڻᴴ�����·�� folder = os.path.exists(path) if not folder: os.makedirs(path)# ��ʱ����def get(url, header): i = 0 while i < 3: try: result = requests.get(url, headers=header, timeout=5) return result except requests.exceptions.RequestException: print("TIME OUT " + str(i+1)) i += 1# �������def zero_fill(path): file_list = os.listdir(path) for file in file_list: if not file.endswith('.txt'): # ��0 10��ʾ��0�����ֹ�10λ filename = file.zfill(10) os.rename(path + '/' + file, path + '/' + filename)# �����ļ�def dld_erocool(erocool_urls, local_path, head_type, file_type): # ���� # ����erocool�����е�ͼƬ # erocool_urls # erocool���� # local_path # ����λ�ã����ڸ�λ�ô����ļ��� # head_type # 1�������ӣ�����һ��ߴ磻0�������ӣ�������ֱ�����س��ߴ磨������ for erocool_url in erocool_urls: print('------------------------------------') # ȷ����������url�в�����erocool��������ȡ url_mid = re.search('detail/(.*)o', erocool_url).group(1) # ȷ����������urlͷ������head_typeȷ�� if head_type == 1: url_head = 'https://search.pstatic.net/common?src=https://mi.404cdn.com/galleries/' elif head_type == 0: url_head = 'https://mi.404cdn.com/galleries/' # User Agent header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 Safari/537.36', 'Cookie': '_ga=GA1.2.99173477.1570796706; csrftoken=OK1ZGOurCtTNFgBhOEauJm3krQyQVR28xSP7Zu9EEv8MjiCgwdQyPyKqViaGkmG4; Hm_lvt_7fdef555dc32f7d31fadd14999021b7b=1570796701,1570941042; _gid=GA1.2.160071259.1570941044; Hm_lpvt_7fdef555dc32f7d31fadd14999021b7b=1570941059', 'Connection': 'close' } # ���� print('\tURL:') print('\t\t' + erocool_url) response = get(erocool_url, header) # print(response.text) with open('temp.txt', 'wb') as file: file.write(response.content) # ѡȡ���ݣ���ҳ�������� pic_num = int( re.search('(.*) �', etree.HTML(response.text).xpath('//div[@class = "ld_box"]/div/div/text()')[3).group(1)) ero_name = etree.HTML(response.text).xpath('//h1/text()')[0 ero_name = ero_name.replace('/', '-') ero_name = ero_name.replace(':', '-') # �����ļ��� local_ero_path = local_path + '/' + ero_name mkdir(local_ero_path) local_url_path = local_ero_path + '/url.txt' with open(local_url_path, 'w') as file: file.write(erocool_url) print('\t' + 'Local directory:') print('\t\t' + local_ero_path) for i in range(1, pic_num + 1): pic_name = str(i) + '.' + file_type pic_url = url_head + url_mid + '/' + pic_name local_name = local_ero_path + '/' + pic_name.zfill(10) # �ж��Ƿ�����ļ� exist = os.path.isfile(local_name) print('\t' + str(i) + '/' + str(pic_num)) if not exist: print('\t\t' + 'State: no such file, to be downloaded') # ���� with open(local_name, 'wb') as file: content_temp = get(pic_url, header) file.write(content_temp.content) print('\t\t' + 'Download finished') else: # �ж��ļ��Ƿ���Ч if os.path.getsize(local_name) < 1024: print('\t\t' + 'State: invalid file, to be downloaded') # ���� with open(local_name, 'wb') as file: content_temp = get(pic_url, header) file.write(content_temp.content) print('\t\t' + 'Download finished') else: print('\t\t' + 'State: downloaded already') size = str(round(os.path.getsize(local_name) / 1024, 2)) print('\t\t' + 'File size: ' + size + ' KB')# ������# ����λ�ã����ڸ�λ�ô����ļ���local_path = "F:/temp/aira2temp/erocool"# erocool����urls = [ 'https://zh.erocool.me/detail/1686650o321307.html',# ͼƬ������������# 1�������ӣ�����һ��ߴ磻0�������ӣ�������ֱ�����س��ߴ磨������head_type = 1# ͼƬ����# һ����jpg��С������pngfile_type = 'jpg'# ����dld_erocool(urls, local_path, head_type, file_type)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
�������н����------------------------------------ URL: https://zh.erocool.me/detail/1686650o321307.html Local directory: F:/temp/aira2temp/erocool/[��ͽ�椦��] ǧ�r -chitose- ����Ԓ (COMIC ����ܞ�� 2020��8�º�) [�й����U] 1/42 State: no such file, to be downloaded Download finished File size: 460.71 KB 2/42 State: no such file, to be downloaded Download finished File size: 400.66 KB 3/42 State: no such file, to be downloaded Download finished File size: 434.52 KB 4/42 State: no such file, to be downloaded Download finished File size: 414.37 KB 5/42 State: no such file, to be downloaded Download finished File size: 381.43 KB 6/42 State: no such file, to be downloaded Download finished File size: 407.48 KB 7/42 State: no such file, to be downloaded Download finished File size: 388.39 KB 8/42 State: no such file, to be downloaded Download finished File size: 404.4 KB 9/42 State: no such file, to be downloaded Download finished File size: 432.16 KB 10/42 State: no such file, to be downloaded Download finished File size: 391.35 KB 11/42 State: no such file, to be downloaded Download finished File size: 365.73 KB 12/42 State: no such file, to be downloaded Download finished File size: 416.43 KB 13/42 State: no such file, to be downloaded Download finished File size: 367.79 KB 14/42 State: no such file, to be downloaded Download finished File size: 396.92 KB 15/42 State: no such file, to be downloaded Download finished File size: 385.43 KB 16/42 State: no such file, to be downloaded Download finished File size: 479.14 KB 17/42 State: no such file, to be downloaded Download finished File size: 444.29 KB 18/42 State: no such file, to be downloaded Download finished File size: 405.21 KB 19/42 State: no such file, to be downloaded Download finished File size: 398.37 KB 20/42 State: no such file, to be downloaded Download finished File size: 455.32 KB 21/42 State: no such file, to be downloaded Download finished File size: 409.46 KB 22/42 State: no such file, to be downloaded Download finished File size: 365.91 KB 23/42 State: no such file, to be downloaded Download finished File size: 397.73 KB 24/42 State: no such file, to be downloaded Download finished File size: 491.33 KB 25/42 State: no such file, to be downloaded Download finished File size: 420.46 KB 26/42 State: no such file, to be downloaded Download finished File size: 418.84 KB 27/42 State: no such file, to be downloaded Download finished File size: 449.82 KB 28/42 State: no such file, to be downloaded Download finished File size: 489.8 KB 29/42 State: no such file, to be downloaded Download finished File size: 487.49 KB 30/42 State: no such file, to be downloaded Download finished File size: 434.8 KB 31/42 State: no such file, to be downloaded Download finished File size: 352.65 KB 32/42 State: no such file, to be downloaded Download finished File size: 369.91 KB 33/42 State: no such file, to be downloaded Download finished File size: 481.56 KB 34/42 State: no such file, to be downloaded Download finished File size: 371.06 KB 35/42 State: no such file, to be downloaded Download finished File size: 333.14 KB 36/42 State: no such file, to be downloaded Download finished File size: 367.17 KB 37/42 State: no such file, to be downloaded Download finished File size: 403.3 KB 38/42 State: no such file, to be downloaded Download finished File size: 405.74 KB 39/42 State: no such file, to be downloaded Download finished File size: 457.22 KB 40/42 State: no such file, to be downloaded Download finished File size: 425.29 KB 41/42 State: no such file, to be downloaded Download finished File size: 438.93 KB 42/42 State: no such file, to be downloaded Download finished File size: 417.93 KBProcess finished with exit code 0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
���������·����Ը�������λ���Լ��������ӡ�
����֮�����ھ���ͼƬ�����������͡�ͼƬ����Ҫ���ݱ��Ӿ������������жϡ�ԭ����DZ������ӷ��ص�html������û����Щ��Ϣ��
��λ����������ܹ�ͨ���������ӷ��ص�html��������ȡͼƬ�����������͡�ͼƬ���͵ķ��������������������ҡ�v2�ڶ�����롣
�����һ��ĸĽ���Ĭ������jpg�ļ�������ļ�̫С�����Ϊ�ļ���Ч����������png�ļ���������һ�治��Ҫ֪��ͼƬ�����������jpg����png������Ӧ���������ݼ���jpgҲ��png�������
���´������ص���һ������jpgҲ��png�ı��ӡ�
���룺import reimport requestsfrom lxml import etreeimport os# ��������# �����ļ���def mkdir(path): # �ж��Ƿ�����ļ��������������Ϊ�ļ��� # ���·�������ڻᴴ�����·�� folder = os.path.exists(path) if not folder: os.makedirs(path)# ��ʱ����def get(url, header): i = 0 while i < 3: try: result = requests.get(url, headers=header, timeout=5) return result except requests.exceptions.RequestException: print("TIME OUT " + str(i+1)) i += 1# �������def zero_fill(path): file_list = os.listdir(path) for file in file_list: if not file.endswith('.txt'): # ��0 10��ʾ��0�����ֹ�10λ filename = file.zfill(10) os.rename(path + '/' + file, path + '/' + filename)# �����ļ�def dld_erocool(erocool_urls, local_path, head_type): # ���� # ����erocool�����е�ͼƬ # erocool_urls # erocool���� # local_path # ����λ�ã����ڸ�λ�ô����ļ��� # head_type # 1�������ӣ�����һ��ߴ磻0�������ӣ�������ֱ�����س��ߴ磨������ for erocool_url in erocool_urls: print('------------------------------------') # ȷ����������url�в�����erocool��������ȡ url_mid = re.search('detail/(.*)o', erocool_url).group(1) # ȷ����������urlͷ������head_typeȷ�� if head_type == 1: url_head = 'https://search.pstatic.net/common?src=https://mi.404cdn.com/galleries/' elif head_type == 0: url_head = 'https://mi.404cdn.com/galleries/' # User Agent header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 Safari/537.36', 'Cookie': '_ga=GA1.2.99173477.1570796706; csrftoken=OK1ZGOurCtTNFgBhOEauJm3krQyQVR28xSP7Zu9EEv8MjiCgwdQyPyKqViaGkmG4; Hm_lvt_7fdef555dc32f7d31fadd14999021b7b=1570796701,1570941042; _gid=GA1.2.160071259.1570941044; Hm_lpvt_7fdef555dc32f7d31fadd14999021b7b=1570941059', 'Connection': 'close' } # ���� print('\tURL:') print('\t\t' + erocool_url) response = get(erocool_url, header) # print(response.text) with open('temp.txt', 'wb') as file: file.write(response.content) # ѡȡ���ݣ���ҳ�������� pic_num = int( re.search('(.*) �', etree.HTML(response.text).xpath('//div[@class = "ld_box"]/div/div/text()')[3).group(1)) ero_name = etree.HTML(response.text).xpath('//h1/text()')[0 ero_name = ero_name.replace('/', '-') ero_name = ero_name.replace(':', '-') ero_name = ero_name.replace('?', '-') # �����ļ��� local_ero_path = local_path + '/' + ero_name mkdir(local_ero_path) local_url_path = local_ero_path + '/url.txt' with open(local_url_path, 'w') as file: file.write(erocool_url) print('\t' + 'Local directory:') print('\t\t' + local_ero_path) for i in range(1, pic_num + 1): pic_name = str(i) + '.' + 'jpg' pic_url = url_head + url_mid + '/' + pic_name local_name = local_ero_path + '/' + pic_name.zfill(10) print('\t' + str(i) + '/' + str(pic_num)) # �ж��Ƿ����jpg���ļ� exist = os.path.isfile(local_name) if not exist: print('\t\t' + 'State: no jpg file, to be downloaded') # ���� with open(local_name, 'wb') as file: content_temp = get(pic_url, header) file.write(content_temp.content) print('\t\t' + 'Download finished') else: print('\t\t' + 'State: jpg downloaded already') # �ж�jpg�ļ��Ƿ���Ч����Ч�������� if os.path.getsize(local_name) < 1024: print('\t\t' + 'State: invalid jpg file, try again') os.remove(local_name) pic_name = str(i) + '.' + 'jpg' pic_url = url_head + url_mid + '/' + pic_name local_name = local_ero_path + '/' + pic_name.zfill(10) # ���� with open(local_name, 'wb') as file: content_temp = get(pic_url, header) file.write(content_temp.content) print('\t\t' + 'Download finished') # �ж�jpg�ļ��Ƿ���Ч����Ч������png if os.path.getsize(local_name) < 1024: print('\t\t' + 'State: invalid jpg file, try png') os.remove(local_name) pic_name = str(i) + '.' + 'png' pic_url = url_head + url_mid + '/' + pic_name local_name = local_ero_path + '/' + pic_name.zfill(10) # �ж��Ƿ����png���ļ� exist = os.path.isfile(local_name) if not exist: print('\t\t' + 'State: no png file, to be downloaded') # ���� with open(local_name, 'wb') as file: content_temp = get(pic_url, header) file.write(content_temp.content) print('\t\t' + 'Download finished') else: print('\t\t' + 'State: png downloaded already') # �ж�png�ļ��Ƿ���Ч����Ч�������� if os.path.getsize(local_name) < 1024: print('\t\t' + 'State: invalid png file, try again') os.remove(local_name) pic_name = str(i) + '.' + 'png' pic_url = url_head + url_mid + '/' + pic_name local_name = local_ero_path + '/' + pic_name.zfill(10) # ���� with open(local_name, 'wb') as file: content_temp = get(pic_url, header) file.write(content_temp.content) print('\t\t' + 'Download finished') size = str(round(os.path.getsize(local_name) / 1024, 2)) print('\t\t' + 'File size: ' + size + ' KB')# ������# ����λ�ã����ڸ�λ�ô����ļ���local_path = "F:/temp/aira2temp/erocool"# erocool����urls = [ 'https://zh.erocool.me/detail/1547299o296458.html',# ͼƬ������������# 1�������ӣ�����һ��ߴ磻0�������ӣ�������ֱ�����س��ߴ磨������head_type = 1# ����dld_erocool(urls, local_path, head_type)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
�������н����------------------------------------ URL: https://zh.erocool.me/detail/1547299o296458.html Local directory: F:/temp/aira2temp/erocool/[����] ��A��݆�Ϥ�ӻ�� (���ߥå� ������ 22) [�й����U] [DL��] 1/27 State: no jpg file, to be downloaded Download finished File size: 433.84 KB 2/27 State: no jpg file, to be downloaded Download finished File size: 430.27 KB 3/27 State: no jpg file, to be downloaded Download finished File size: 406.48 KB 4/27 State: no jpg file, to be downloaded Download finished File size: 437.8 KB 5/27 State: no jpg file, to be downloaded Download finished File size: 492.18 KB 6/27 State: no jpg file, to be downloaded Download finished File size: 494.39 KB 7/27 State: no jpg file, to be downloaded Download finished File size: 461.91 KB 8/27 State: no jpg file, to be downloaded Download finished File size: 419.5 KB 9/27 State: no jpg file, to be downloaded Download finished File size: 442.8 KB 10/27 State: no jpg file, to be downloaded Download finished File size: 408.69 KB 11/27 State: no jpg file, to be downloaded Download finished File size: 393.77 KB 12/27 State: no jpg file, to be downloaded Download finished File size: 394.89 KB 13/27 State: no jpg file, to be downloaded Download finished File size: 436.82 KB 14/27 State: no jpg file, to be downloaded Download finished File size: 410.19 KB 15/27 State: no jpg file, to be downloaded Download finished File size: 440.01 KB 16/27 State: no jpg file, to be downloaded Download finished State: invalid jpg file, try again Download finished State: invalid jpg file, try png State: no png file, to be downloaded Download finished File size: 1201.58 KB 17/27 State: no jpg file, to be downloaded Download finished State: invalid jpg file, try again Download finished State: invalid jpg file, try png State: no png file, to be downloaded Download finished File size: 1109.1 KB 18/27 State: no jpg file, to be downloaded Download finished File size: 408.06 KB 19/27 State: no jpg file, to be downloaded Download finished File size: 386.98 KB 20/27 State: no jpg file, to be downloaded Download finished File size: 435.79 KB 21/27 State: no jpg file, to be downloaded Download finished File size: 423.48 KB 22/27 State: no jpg file, to be downloaded Download finished File size: 414.71 KB 23/27 State: no jpg file, to be downloaded Download finished File size: 405.81 KB 24/27 State: no jpg file, to be downloaded Download finished State: invalid jpg file, try again Download finished State: invalid jpg file, try png State: no png file, to be downloaded Download finished File size: 1176.14 KB 25/27 State: no jpg file, to be downloaded Download finished File size: 432.11 KB 26/27 State: no jpg file, to be downloaded Download finished File size: 372.41 KB 27/27 State: no jpg file, to be downloaded Download finished File size: 173.54 KBProcess finished with exit code 0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
V3�Ľ�������jpg��png�����������˴�����ҳ����ȡ����url�Ĺ��ܡ�
���룺import reimport requestsfrom lxml import etreeimport os# ��������# �����ļ���def mkdir(path): # �ж��Ƿ�����ļ��������������Ϊ�ļ��� # ���·�������ڻᴴ�����·�� folder = os.path.exists(path) if not folder: os.makedirs(path)# ��ʱ����def get(url, header): i = 0 while i < 3: try: result = requests.get(url, headers=header, timeout=5) return result except requests.exceptions.RequestException: print("TIME OUT " + str(i+1)) i += 1# �������def zero_fill(path): file_list = os.listdir(path) for file in file_list: if not file.endswith('.txt'): # ��0 10��ʾ��0�����ֹ�10λ filename = file.zfill(10) os.rename(path + '/' + file, path + '/' + filename)# ������ҳ����ȡurlsdef get_urls(search_url): # User Agent header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 Safari/537.36', 'Cookie': '_ga=GA1.2.99173477.1570796706; csrftoken=OK1ZGOurCtTNFgBhOEauJm3krQyQVR28xSP7Zu9EEv8MjiCgwdQyPyKqViaGkmG4; Hm_lvt_7fdef555dc32f7d31fadd14999021b7b=1570796701,1570941042; _gid=GA1.2.160071259.1570941044; Hm_lpvt_7fdef555dc32f7d31fadd14999021b7b=1570941059', 'Connection': 'close' } response = get(search_url, header) if response is None: return [ url_head = 'https://zh.erocool.me' urls = etree.HTML(response.text).xpath('//div[@class="list-wrapper"]/a/@href') for i in range(len(urls)): urls[i = url_head + urls[i print(urls[i) return urls# �����ļ�def dld_erocool(erocool_urls, local_path, head_type): # ���� # ����erocool�����е�ͼƬ # erocool_urls # erocool���� # local_path # ����λ�ã����ڸ�λ�ô����ļ��� # head_type # 1�������ӣ�����һ��ߴ磻0�������ӣ�������ֱ�����س��ߴ磨������ for erocool_url in erocool_urls: print('------------------------------------') # ȷ����������url�в�����erocool��������ȡ url_mid = re.search('detail/(.*)o', erocool_url).group(1) # ȷ����������urlͷ������head_typeȷ�� if head_type == 1: url_head = 'https://search.pstatic.net/common?src=https://mi.404cdn.com/galleries/' elif head_type == 0: url_head = 'https://mi.404cdn.com/galleries/' # User Agent header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 Safari/537.36', 'Cookie': '_ga=GA1.2.99173477.1570796706; csrftoken=OK1ZGOurCtTNFgBhOEauJm3krQyQVR28xSP7Zu9EEv8MjiCgwdQyPyKqViaGkmG4; Hm_lvt_7fdef555dc32f7d31fadd14999021b7b=1570796701,1570941042; _gid=GA1.2.160071259.1570941044; Hm_lpvt_7fdef555dc32f7d31fadd14999021b7b=1570941059', 'Connection': 'close' } # ���� print('\tURL:') print('\t\t' + erocool_url) response = get(erocool_url, header) # ѡȡ���ݣ���ҳ�������� pic_num = int( re.search('(.*) �', etree.HTML(response.text).xpath('//div[@class = "ld_box"]/div/div/text()')[3).group(1)) ero_name = etree.HTML(response.text).xpath('//h1/text()')[0 ero_name = ero_name.replace('/', '-') ero_name = ero_name.replace(':', '-') ero_name = ero_name.replace('?', '-') # �����ļ��� local_ero_path = local_path + '/' + ero_name mkdir(local_ero_path) local_url_path = local_ero_path + '/url.txt' with open(local_url_path, 'w') as file: file.write(erocool_url) print('\t' + 'Local directory:') print('\t\t' + local_ero_path) # ��һ�ŵ�Ĭ���������� # 1��jpg # 0��png default_type = 1 for i in range(1, pic_num + 1): print('\t' + str(i) + '/' + str(pic_num)) pic_name_jpg = str(i) + '.' + 'jpg' pic_url_jpg = url_head + url_mid + '/' + pic_name_jpg local_name_jpg = local_ero_path + '/' + pic_name_jpg.zfill(10) pic_name_png = str(i) + '.' + 'png' pic_url_png = url_head + url_mid + '/' + pic_name_png local_name_png = local_ero_path + '/' + pic_name_png.zfill(10) size = 0 while size < 1024: # �Ƿ����jpg���ļ� exist_jpg = os.path.isfile(local_name_jpg) # �Ƿ����png���ļ� exist_png = os.path.isfile(local_name_png) # ����������� if (not exist_jpg) & (not exist_png): if default_type == 1: print('\t\t' + 'State: no jpg or png file, try jpg') # ����jpg with open(local_name_jpg, 'wb') as file: content_temp = get(pic_url_jpg, header) file.write(content_temp.content) print('\t\t' + 'Download finished') size = os.path.getsize(local_name_jpg) elif default_type == 0: print('\t\t' + 'State: no jpg or png file, try png') # ����jpg with open(local_name_png, 'wb') as file: content_temp = get(pic_url_png, header) file.write(content_temp.content) print('\t\t' + 'Download finished') size = os.path.getsize(local_name_png) # ���jpg���� elif exist_jpg: # ���jpg��Ч if os.path.getsize(local_name_jpg) < 1024: # ����png print('\t\t' + 'State: invalid jpg file, try png') os.remove(local_name_jpg) with open(local_name_png, 'wb') as file: content_temp = get(pic_url_png, header) file.write(content_temp.content) print('\t\t' + 'Download finished') size = os.path.getsize(local_name_png) default_type = 0 else: print('\t\t' + 'State: valid jpg file') size = os.path.getsize(local_name_jpg) # ���png���� elif exist_png: # ���png��Ч if os.path.getsize(local_name_png) < 1024: # ����jpg print('\t\t' + 'State: invalid png file, try jpg') os.remove(local_name_png) with open(local_name_jpg, 'wb') as file: content_temp = get(pic_url_jpg, header) file.write(content_temp.content) print('\t\t' + 'Download finished') size = os.path.getsize(local_name_jpg) default_type = 1 else: print('\t\t' + 'State: valid png file') size = os.path.getsize(local_name_png) print('\t\t' + 'File size: ' + str(round(size / 1024, 2)) + ' KB')# ������# ����λ�ã����ڸ�λ�ô����ļ���local_path = "F:/temp/aira2temp/erocool"# ������������ȡurlssearch_url = ''# ֱ�Ӹ����屾�ӵ�urlsurls2 = [# ͼƬ������������# 1�������ӣ�����һ��ߴ磻0�������ӣ�������ֱ�����س��ߴ磨������head_type = 1# ����urls1 = get_urls(search_url)dld_erocool(urls1, local_path, head_type)dld_erocool(urls2, local_path, head_type)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
������û�о�����������ӡ� |

 �ᰮ�ο�
������ 2020-8-4 12:20
�ᰮ�ο�
������ 2020-8-4 12:20




