帮一个做外贸的朋友搞的,他需要电话号去和商家沟通,提供国际货运一条龙服务,不停地切换页面查看手机号,比较麻烦,帮他写个脚本,一次性获取下来,存成Excel。现在分享一下过程,同时记录一下他欠我一顿饭。
前言
阿里巴巴国际站上的商家号码在不同的商家页面上,如图所示,需要登录授权才能查看。
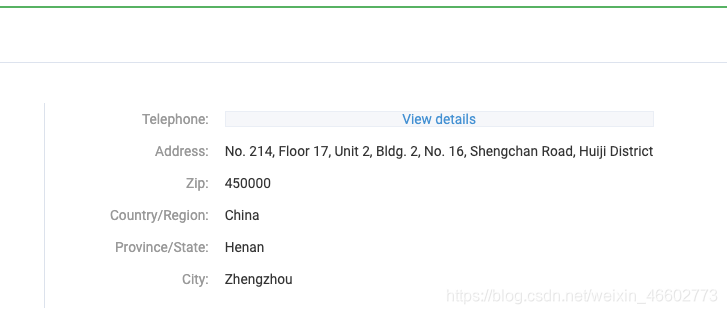
本来想直接通过接口去获取,但是发现每次请求都有一个动态的spm参数不同的变动,所以决定简单一点用selenium启一个webdriver,效率比较慢。
1.启动webdriver,并完成登录
from selenium.webdriver import ChromeOptions
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
import re
import time
from lxml import etree
import csv
# 完成登录 登陆
class Chrome_drive():
def __init__(self):
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_experimental_option('useAutomationExtension', False)
NoImage = {"profile.managed_default_content_settings.images": 2} # 控制 没有图片
option.add_experimental_option("prefs", NoImage)
# option.add_argument(f'user-agent={ua.chrome}') # 增加浏览器头部
# chrome_options.add_argument(f"--proxy-server=http://{self.ip}") # 增加IP地址。。
# option.add_argument('--headless') #无头模式 不弹出浏览器
self.browser = webdriver.Chrome(executable_path="./chromedriver", options=option)
self.browser.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {
'source': 'Object.defineProperty(navigator,"webdriver",{get:()=>undefined})'
}) #去掉selenium的驱动设置
self.browser.set_window_size(1200,768)
self.wait = WebDriverWait(self.browser, 12)
def get_login(self):
url='https://passport.alibaba.com/icbu_login.htm'
self.browser.get(url)
#self.browser.maximize_window() # 在这里登陆的中国大陆的邮编
#这里进行人工登陆。
k = input("输入1")
if 'Your Alibaba.com account is temporarily unavailable' in self.browser.page_source:
self.browser.close()
while k == 1:
break
self.browser.refresh() # 刷新方法 refres
return
为了快速加载web页面,浏览器设置不加载图片,打开登录页后死循环等待,手动登录完成后,控制台输入1 跳出循环。
2.获取页面内容
分析网页
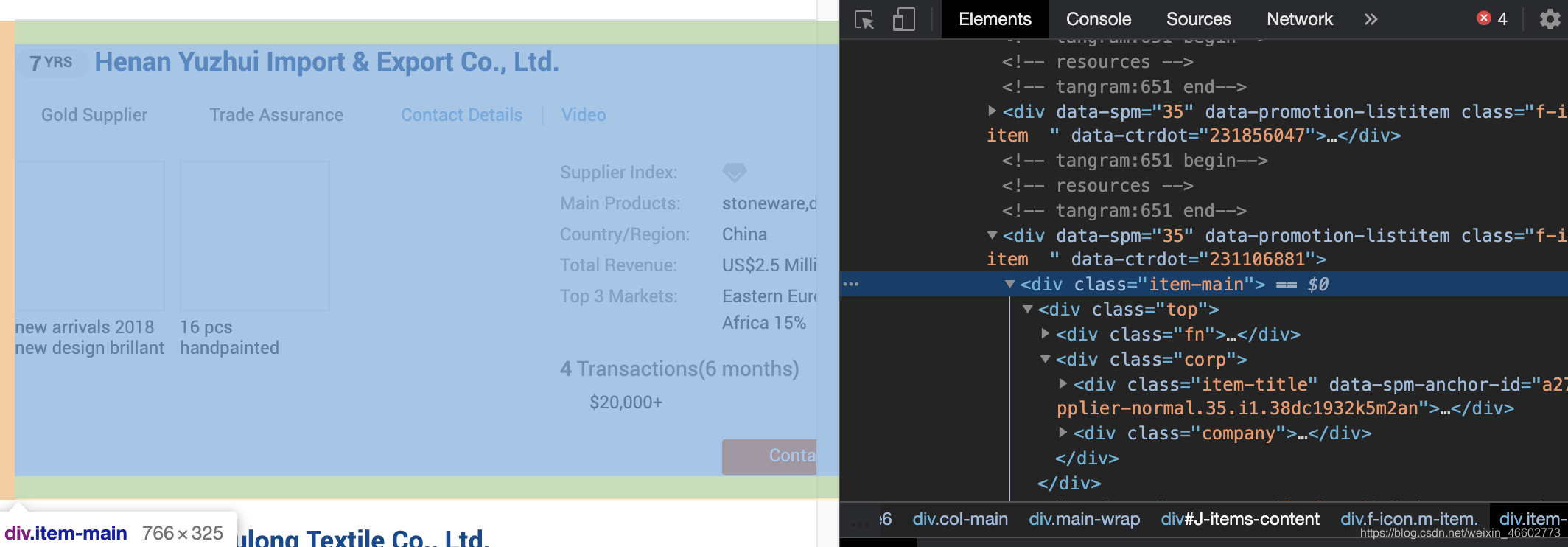
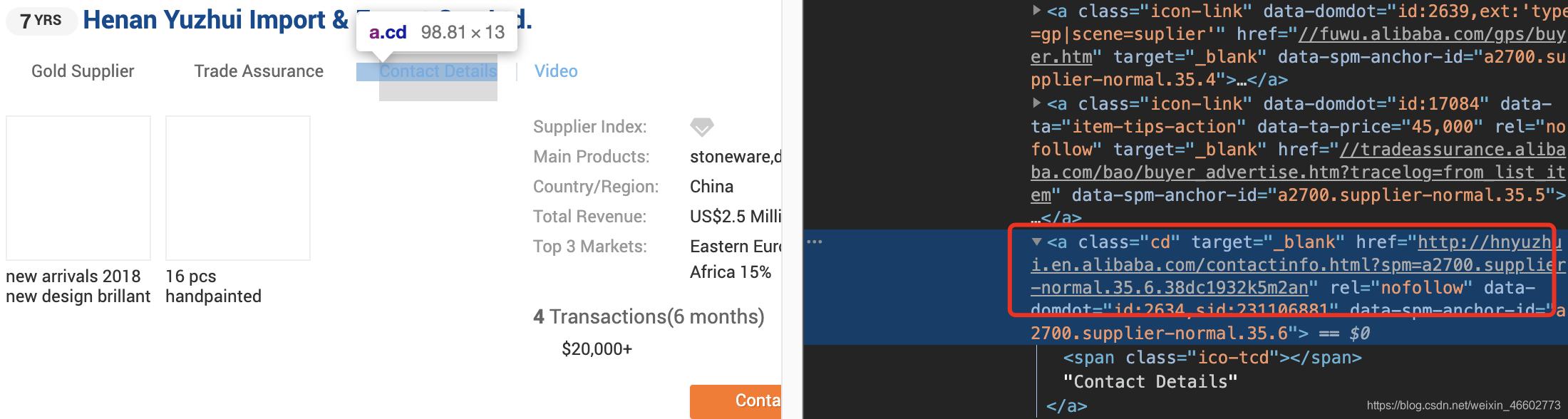
我们首先获取页面上class=item-main的dom,可以拿到商家信息,然后获取dom下class=cd的a标签的src属性可以获取商家详细信息页面链接,获取信息后存成csv文件。代码实现如下:
#获取判断网页文本的内容:
def index_page(self,page,wd):
"""
抓取索引页
:param page: 页码
"""
print('正在爬取第', page, '页')
url = f'https://www.alibaba.com/trade/search?page={page}&keyword={wd}&f1=y&indexArea=company_en&viewType=L&n=38'
js1 = f" window.open('{url}')" # 执行打开新的标签页
print(url)
self.browser.execute_script(js1) # 打开新的网页标签
# 执行打开新一个标签页。
self.browser.switch_to.window(self.browser.window_handles[-1]) # 此行代码用来定位当前页面窗口
self.buffer() # 网页滑动 成功切换
#等待元素加载出来
time.sleep(3)
self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#J-items-content')))
#获取网页的源代码
html = self.browser.page_source
self.get_products(wd,html)
self.close_window()
def get_products(self, wd, html_text):
"""
提取商品数据
"""
e = etree.HTML(html_text)
item_main = e.xpath('//div[@id="J-items-content"]//div[@class="item-main"]')
items = e.xpath('//div[@id="J-items-content"]//div[@class="item-main"]')
print('公司数 ', len(items))
for li in items:
company_name = ''.join(li.xpath('./div[@class="top"]//h2[@class="title ellipsis"]/a/text()')) # 公司名称
company_phone_page = ''.join(li.xpath('./div[@class="top"]//a[@class="cd"]/@href')) # 公司电话连接
product = ''.join(li.xpath('.//div[@class="value ellipsis ph"]/text()')) # 主要产品
Attrs = li.xpath('.//div[@class="attrs"]//span[@class="ellipsis search"]/text()')
length = len(Attrs)
counctry = ''
total_evenue = ''
sell_adress = ''
product_img = ''
if length > 0:
counctry = ''.join(Attrs[0]) # 国家
if length > 1:
total_evenue = ''.join(Attrs[1]) # Total 收入
if length > 2:
sell_adress = ''.join(Attrs[2]) # 主要销售地
if length > 3:
sell_adress += '、' + ''.join(Attrs[3]) # 主要销售地
if length > 4:
sell_adress += '、' + ''.join(Attrs[4]) # 主要销售地
product_img_list = li.xpath('.//div[@class="product"]/div/a/img/@src')
if len(product_img_list) > 0:
product_img = ','.join(product_img_list) # 产品图片
self.browser.get(company_phone_page)
phone = ''
address = ''
mobilePhone = ''
try:
if 'Your Alibaba.com account is temporarily unavailable' in self.browser.page_source:
self.browser.close()
self.browser.find_element_by_xpath('//div[@class="sens-mask"]/a').click()
phone = ''.join(re.findall('Telephone:</th><td>(.*?)</td>', self.browser.page_source, re.S))
mobilePhone = ''.join(re.findall('Mobile Phone:</th><td>(.*?)</td>', self.browser.page_source, re.S))
address = ''.join(re.findall('Address:</th><td>(.*?)</td>', self.browser.page_source, re.S))
except:
print("该公司没有电话")
all_down = [wd, company_name, company_phone_page, product, counctry, phone, mobilePhone, address,
total_evenue, sell_adress, product_img]
save_csv(all_down)
print(company_name, company_phone_page, product, counctry, phone, mobilePhone, address, total_evenue,
sell_adress, product_img)
注意:国际站列表图片是懒加载的,也就是说没有滑动出来的时候产品图片地址是空的,我们增加一个窗口滑动操作和一个关闭标签页的动作
def buffer(self): #滑动网页的
for i in range(33):
time.sleep(0.5)
self.browser.execute_script('window.scrollBy(0,380)', '') # 向下滑行300像素。
def close_window(self):
length=self.browser.window_handles
if len(length) > 3:
self.browser.switch_to.window(self.browser.window_handles[1])
self.browser.close()
time.sleep(1)
self.browser.switch_to.window(self.browser.window_handles[-1])
获取信息如下
然后是main方法,这里我省事了,就是先搜了一下关键词之后,看了下一共多少页,写了个for循环,有时间可以修改成获取列表的总页数,自动循环:
def save_csv(lise_line):
file = csv.writer(open("./alibaba_com_img.csv", 'a', newline="", encoding="utf-8"))
file.writerow(lise_line)
def main():
"""
遍历每一页
"""
run = Chrome_drive()
run.get_login() #先登录
wd ='henan'
for i in range(1,32):
run.index_page(i, wd)
if __name__ == '__main__':
csv_title = 'wd,company_name,company_phone_page,product,counctry,phone,mobilePhone,address,total_evenue,sell_adress,product_img'.split(
',')
save_csv(csv_title)
main()
3.获取产品图片
第二步执行完,我们就获取关键词搜索后的全部商家信息,这一步我们把商家的产品图片全部下载下来,代码如下:
# -*- coding: utf-8 -*-
import requests
import pandas as pd
def open_requests(img, img_name):
img_url ='https:'+ img
res=requests.get(img_url)
with open(f"./downloads_picture/{img_name}", 'wb') as fn:
fn.write(res.content)
df1=pd.read_csv('./alibaba_com_img.csv',)
for imgs in df1["product_img"]:
imgList = str(imgs).split(',')
if len(imgList) > 0:
img = imgList[0]
img_name = img[24:]
print(img, img_name)
open_requests(img, img_name)

4.获取插入图片
刚才保存的是一个csv文件,我们把csv转成Excel,==注意csv转成Excel时不要直接用文件转换,容易有乱码问题,我们选择数据导入方式转换。==
选择菜单栏选择文件,然后选择导入,菜单选择csv文件然后点导入
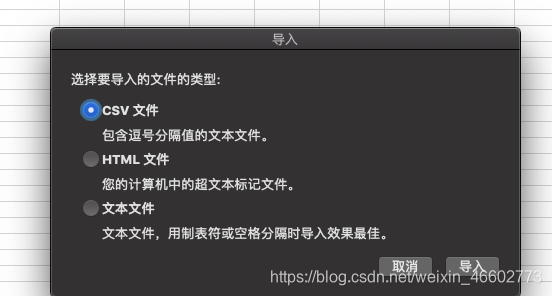
选择文件原始格式:UTF-8,然后点下一步
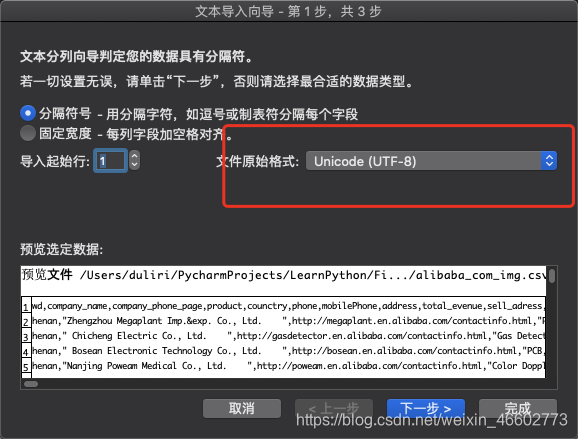
间隔符选择逗号和制表符。
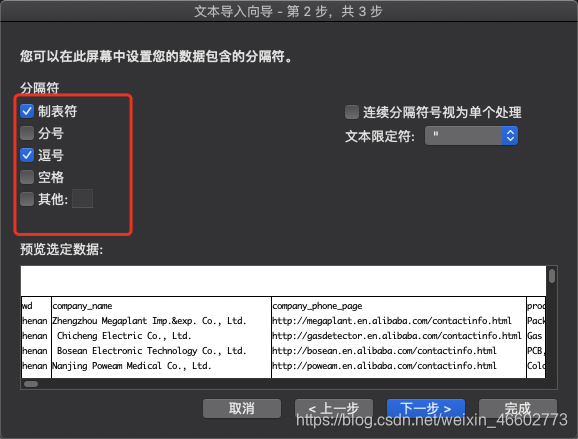
把列数据格式全部输入成文本,不然电话号会自动转成16进制。。
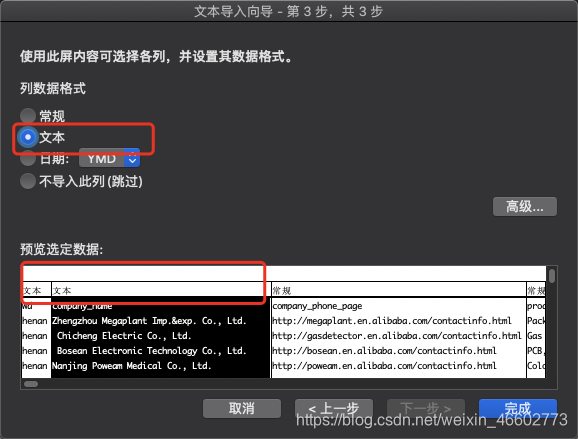
导入成功后,我们选择C列然后插入一列,准备插入图片。

插入第三步下载好的图片,代码如下:
# -*- coding: utf-8 -*-
from PIL import Image
import os
import xlwings as xw
path='alibaba_com.xlsx'
app = xw.App(visible=True, add_book=False)
wb = app.books.open(path)
sht = wb.sheets['Sheet1']
img_list=sht.range("L2").expand('down').value
print(len(img_list))
def write_pic(cell,img_name):
path=f'./downloads_picture/{img_name}'
print(path)
fileName = os.path.join(os.getcwd(), path)
img = Image.open(path).convert("RGB")
print(img.size)
w, h = img.size
x_s = 70 # 设置宽 excel中,我设置了200x200的格式
y_s = h * x_s / w # 等比例设置高
sht.pictures.add(fileName, left=sht.range(cell).left, top=sht.range(cell).top, width=x_s, height=y_s)
if __name__ == '__main__':
for index,imgs in enumerate(img_list):
cell="C"+str(index + 2)
imgsList = str(imgs).split(',')
if len(imgsList) > 0:
img = imgsList[0]
img_name = img[24:]
try:
write_pic(cell,img_name)
print(cell,img_name)
except:
print("没有找到这个img_name的图片",img_name)
wb.save()
wb.close()
app.quit()
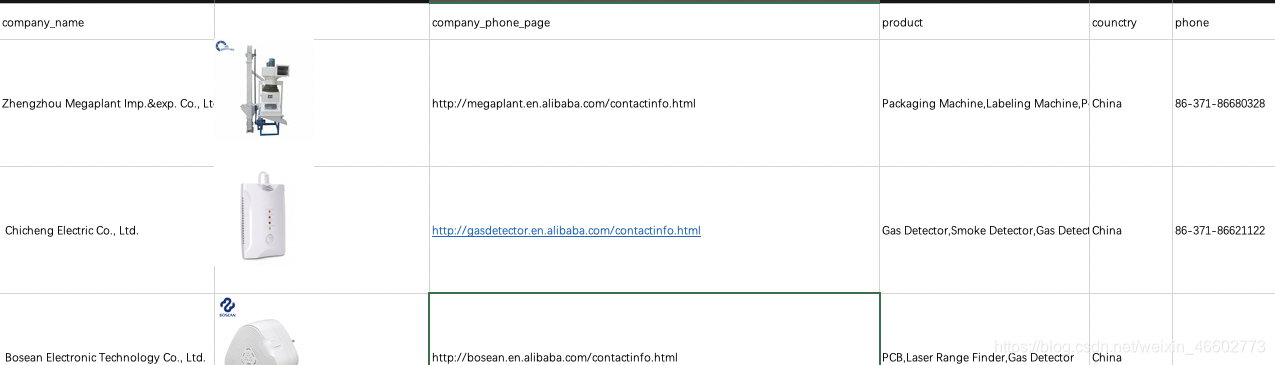
最终效果如下:
项目地址如下:https://github.com/FORMAT-qi/alibababBsinessInfo
欢迎关注,欢迎点赞,如代码对您有帮助,请给我github一个star,谢谢。


 发表于 2020-12-8 11:53
发表于 2020-12-8 11:53
 |
发表于 2020-12-17 08:50
|
发表于 2020-12-17 08:50



