二维数组
二维数组初始化
int arr[3][4]={
{1,2,3,4},
{5,6,7,8},
{9,10,11,12}
};
查看反汇编
7: int arr[3][4]={
8: {1,2,3,4},
0040D498 mov dword ptr [ebp-30h],1
0040D49F mov dword ptr [ebp-2Ch],2
0040D4A6 mov dword ptr [ebp-28h],3
0040D4AD mov dword ptr [ebp-24h],4
9: {5,6,7,8},
0040D4B4 mov dword ptr [ebp-20h],5
0040D4BB mov dword ptr [ebp-1Ch],6
0040D4C2 mov dword ptr [ebp-18h],7
0040D4C9 mov dword ptr [ebp-14h],8
10: {9,10,11,12}
0040D4D0 mov dword ptr [ebp-10h],9
0040D4D7 mov dword ptr [ebp-0Ch],0Ah
0040D4DE mov dword ptr [ebp-8],0Bh
0040D4E5 mov dword ptr [ebp-4],0Ch
11: }
可以发现其存储方式和一维数组并没有什么不同,仍然是从低地址开始连续存储
对比一维数组
int arr[12]={1,2,3,4,5,6,7,8,9,10,11,12};
查看反汇编代码:
15: int arr[12]={1,2,3,4,5,6,7,8,9,10,11,12}
00401038 mov dword ptr [ebp-30h],1
0040103F mov dword ptr [ebp-2Ch],2
00401046 mov dword ptr [ebp-28h],3
0040104D mov dword ptr [ebp-24h],4
00401054 mov dword ptr [ebp-20h],5
0040105B mov dword ptr [ebp-1Ch],6
00401062 mov dword ptr [ebp-18h],7
00401069 mov dword ptr [ebp-14h],8
00401070 mov dword ptr [ebp-10h],9
00401077 mov dword ptr [ebp-0Ch],0Ah
0040107E mov dword ptr [ebp-8],0Bh
00401085 mov dword ptr [ebp-4],0Ch
16: }
可以看到,其分配方式一模一样
得出结论
无论是一维数组,二维数组或者其它多维数组,其存储方式实质上并没有区别,都是在内存中连续存储,并没有所谓的行和列的概念
对于一个二维数组来说,编译器为其分配空间实际上也是按一维数组来进行分配的
int arr[m][n] 等同于 int arr[m*n]
拿上面的例子而言就是
int arr[3][4] 等同于 int arr[3*4]=int arr[12]
因此也可以使用下面这种方式初始化二维数组
int arr[3][4]={1,2,3,4,5,6,7,8,9,10,11,12};
省略成员的二维数组
前面声明的二维数组每个数组成员都有对应的数值,如果省略了二维数组某些数组成员,又会如何?
int arr[3][4]={
{1,2},
{5,6,7},
{9}
};
查看反汇编代码:
7: int arr[3][4]={
8: {1,2},
00401038 mov dword ptr [ebp-30h],1
0040103F mov dword ptr [ebp-2Ch],2
00401046 xor eax,eax
00401048 mov dword ptr [ebp-28h],eax
0040104B mov dword ptr [ebp-24h],eax
9: {5,6,7},
0040104E mov dword ptr [ebp-20h],5
00401055 mov dword ptr [ebp-1Ch],6
0040105C mov dword ptr [ebp-18h],7
00401063 xor ecx,ecx
00401065 mov dword ptr [ebp-14h],ecx
10: {9}
00401068 mov dword ptr [ebp-10h],9
0040106F xor edx,edx
00401071 mov dword ptr [ebp-0Ch],edx
00401074 mov dword ptr [ebp-8],edx
00401077 mov dword ptr [ebp-4],edx
11: }
在反汇编代码中,存储内容一目了然,对于没有填充的数组成员,缺省(默认)值为0
也就是说上面的数组等同于
int arr[3][4]={
{1,2,0,0},
{5,6,7,0},
{9,0,0,0}
};
同样对于另一种声明方式也支持不填满
int arr[3][4]={1,2,3,4,5,6,7,8,9,10};
查看反汇编代码
7: int arr[3][4]={1,2,3,4,5,6,7,8,9,10}
00401038 mov dword ptr [ebp-30h],1
0040103F mov dword ptr [ebp-2Ch],2
00401046 mov dword ptr [ebp-28h],3
0040104D mov dword ptr [ebp-24h],4
00401054 mov dword ptr [ebp-20h],5
0040105B mov dword ptr [ebp-1Ch],6
00401062 mov dword ptr [ebp-18h],7
00401069 mov dword ptr [ebp-14h],8
00401070 mov dword ptr [ebp-10h],9
00401077 mov dword ptr [ebp-0Ch],0Ah
0040107E xor eax,eax
00401080 mov dword ptr [ebp-8],eax
00401083 mov dword ptr [ebp-4],eax
8: }
依旧是缺省(默认)值为0
省略维数的二维数组
前面知道了二维数组支持省略某些数组成员,同样的,二维数组也支持省略维数
int arr[][4]={1,2,3,4,5,6,7,8,9,10,11,12};
省略了维数之后,这里编译器会自动分组,这里为4个一组
在省略维数的情况下能否省略成员?
答案是可以的
int arr[][4]={1,2,3,4,5,6,7,8,9,10};
此时的编译器依旧是以4个为一组,后面不够的部分自动会补0
编译器不支持省略后面的维数,如:
int arr[][4]={1,2,3,4,5,6,7,8,9,10};
因为最后面的维数是作为组数,进行分组的
为什么使用二维数组
经过前面对二维数组初始化的了解,发现二维数组实际上和一维数组并没有什么不同,那么为什么要使用二维数组?
因为使用二维数组更为直观,方便对数据进行管理
二维数组的寻址
了解完二维数组的初始化后,再来看看二维数组如何寻址
int arr[3][4]={
{1,2,3,4},
{5,6,7,8},
{9,10,11,12}
};
int a=arr[2][3];
int i=1,j=2;
int b=arr[i][j];
int c=arr[i+j][i*2];
查看反汇编
7: int arr[3][4]={
8: {1,2,3,4},
0040103E mov dword ptr [ebp-30h],1
00401045 mov dword ptr [ebp-2Ch],2
0040104C mov dword ptr [ebp-28h],3
00401053 mov dword ptr [ebp-24h],4
9: {5,6,7,8},
0040105A mov dword ptr [ebp-20h],5
00401061 mov dword ptr [ebp-1Ch],6
00401068 mov dword ptr [ebp-18h],7
0040106F mov dword ptr [ebp-14h],8
10: {9,10,11,12}
00401076 mov dword ptr [ebp-10h],9
0040107D mov dword ptr [ebp-0Ch],0Ah
00401084 mov dword ptr [ebp-8],0Bh
0040108B mov dword ptr [ebp-4],0Ch
11: }
12: int a=arr[2][3]
00401092 mov eax,dword ptr [ebp-4]
00401095 mov dword ptr [ebp-34h],eax
13: int i=1,j=2
00401098 mov dword ptr [ebp-38h],1
0040109F mov dword ptr [ebp-3Ch],2
14: int b=arr[i][j]
004010A6 mov ecx,dword ptr [ebp-38h]
004010A9 shl ecx,4
004010AC lea edx,[ebp+ecx-30h]
004010B0 mov eax,dword ptr [ebp-3Ch]
004010B3 mov ecx,dword ptr [edx+eax*4]
004010B6 mov dword ptr [ebp-40h],ecx
15: int c=arr[i+j][i*2]
004010B9 mov edx,dword ptr [ebp-38h]
004010BC add edx,dword ptr [ebp-3Ch]
004010BF shl edx,4
004010C2 lea eax,[ebp+edx-30h]
004010C6 mov ecx,dword ptr [ebp-38h]
004010C9 shl ecx,1
004010CB mov edx,dword ptr [eax+ecx*4]
004010CE mov dword ptr [ebp-44h],edx
常数数组下标的寻址
12: int a=arr[2][3]
00401092 mov eax,dword ptr [ebp-4]
00401095 mov dword ptr [ebp-34h],eax
可以看到,当指明了数组下标后,编译器就可以直接找到对应的数组成员地址
变量数组下标的寻址
14: int b=arr[i][j]
004010A6 mov ecx,dword ptr [ebp-38h]
004010A9 shl ecx,4
004010AC lea edx,[ebp+ecx-30h]
004010B0 mov eax,dword ptr [ebp-3Ch]
004010B3 mov ecx,dword ptr [edx+eax*4]
004010B6 mov dword ptr [ebp-40h],ecx
稍微分析一下这段代码
首先将 i 赋给ecx
004010A6 mov ecx,dword ptr [ebp-38h]
然后对ecx左移4位,相当于ecx=ecx*2^4=ecx*16,关于左移右移的详细说明在后面
004010A9 shl ecx,4
执行前:
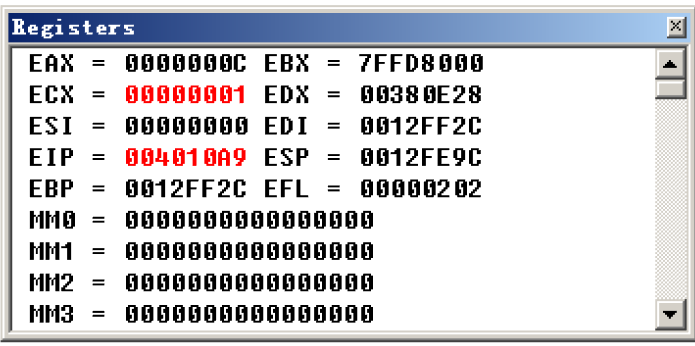
执行后:
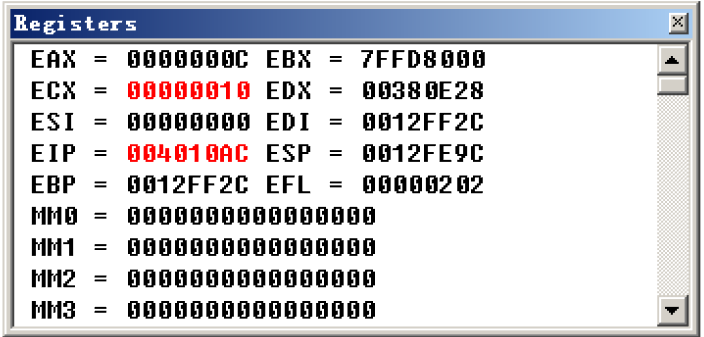
可以看到原本的ecx从1变成了0x10=16
为什么是乘以16?具体在下面的总结寻址方式里说明
接着向下看:
004010AC lea edx,[ebp+ecx-30h]
这里先不管ecx,看看[ebp-30h]对应什么
0040103E mov dword ptr [ebp-30h],1
可以发现[ebp-30h]正好对应数组的一个数组成员
所以这里便是从数组的第一个成员开始,加上ecx的偏移,先找到目标数组成员所在行数的第一个成员地址
再接着向下看:
004010B0 mov eax,dword ptr [ebp-3Ch]
这里是将 j 的值赋给eax
再看:
004010B3 mov ecx,dword ptr [edx+eax*4]
用前面得到的edx,也就是目标成员数组成员所在行数的第一个成员地址加上偏移:eax*4,即数组下标 × 数据宽度得到目标数组成员
然后将目标数组成员的值赋给ecx
最后:
004010B6 mov dword ptr [ebp-40h],ecx
将ecx,也就是目标数组成员的值赋给 b
再下面的变量计算无非就是先算出值再操作,这里就不再赘述了
总结寻址方式
二维数组的寻址方式大体可分为两种:
常量
通过常量给定下标来寻址时 和 一维数组 一样,编译器可以直接通过下标来找到对应的数组成员地址
变量
相比之下,通过变量给定下标来寻址时则相对麻烦一些
为使得说明不那么抽象就拿前面的数组为例
int arr[3][4]={
{1,2,3,4},
{5,6,7,8},
{9,10,11,12}
};
首先是拿出数组的行数:3,并将这个数 × 16,为什么是乘以16?
这里的16=4*4,一个4为数组的组数,也就是arr[3][4]中的4
另一个4为数组成员的数据宽度:4(单位为字节),int类型在32位系统中占4字节
再举一个例子:
int arr[3][5]={
{1,2,3,4,0},
{5,6,7,8,0},
{9,10,11,12,0}
};
此时再查看对应的反汇编代码:
15: int b=arr[i][j]
004010B5 mov ecx,dword ptr [ebp-44h]
004010B8 imul ecx,ecx,14h
可以看到原本的shl 4变成了imul ecx,ecx,14h
14h对应的十进制为20=4*5,4为数组成员的数据宽度,5则为arr[3][5]中的5
然后和一维数组的寻址有些类似,都是从数组的第一个成员地址开始,加上偏移,只不过二维数组需要二次寻址
- 第一次寻址找到数组成员所在行数
- 第二次寻址才真正找到数组成员
第一次寻址就是将通过数组第一个成员地址+ i × j × 数组成员类型的数据宽度 得到的
第二次寻址则是通过第一次寻址结果+ j*数组成员类型的数据宽度得到的
二维数组变量寻址流程图
将上述的分析画成流程图:

位移
前面在寻址的过程中分别用到了乘法,当乘数为2的n次方时,可以直接使用左移来实现,无需imul指令
汇编中有常用的两种位移指令:shl和shr
使用方法并没有太大的区别,这里就拿shl指令作为例子
shl指令
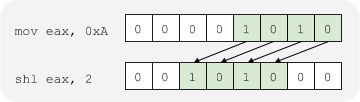
SHL是一个汇编指令,作用是逻辑左移指令,将目的操作数顺序左移1位或CL寄存器中指定的位数。左移一位时,操作数的最高位移入进位标志位CF,最低位补零。
运算例子:
乘法对应例子:
int i=1;
i=i*4;
i=i*8;
i=i*16;
8: i=i*4
0040103F mov eax,dword ptr [ebp-4]
00401042 shl eax,2
00401045 mov dword ptr [ebp-4],eax
9: i=i*8
00401048 mov ecx,dword ptr [ebp-4]
0040104B shl ecx,3
0040104E mov dword ptr [ebp-4],ecx
10: i=i*16
00401051 mov edx,dword ptr [ebp-4]
00401054 shl edx,4
00401057 mov dword ptr [ebp-4],edx
可以看到*4时,对应左移两位,*8则对应左移3位,*16对应左移4位
乘法
imul指令
imul指令使用起来和div指令有些类似,有关div指令可以参考:【原创】另类汇编解反转数字题
IMUL(有符号数乘法)指令执行有符号整数乘法
x86 指令集支持三种格式的 IMUL 指令:单操作数、双操作数和三操作数。单操作数格式中,乘数和被乘数大小相同,而乘积的大小是它们的两倍
这里限于篇幅,仅介绍上面使用到的三操作数,其余部分可以参考:汇编语言IMUL指令:有符号数乘法
例子
int i=1;
i=i*5;
i=i*6;
i=i*7;
查看汇编代码
7: int i=1
00401038 mov dword ptr [ebp-4],1
8: i=i*5
0040103F mov eax,dword ptr [ebp-4]
00401042 imul eax,eax,5
00401045 mov dword ptr [ebp-4],eax
9: i=i*6
00401048 mov ecx,dword ptr [ebp-4]
0040104B imul ecx,ecx,6
0040104E mov dword ptr [ebp-4],ecx
10: i=i*7
00401051 mov edx,dword ptr [ebp-4]
00401054 imul edx,edx,7
00401057 mov dword ptr [ebp-4],edx
可以看到:这里使用了三操作数的imul指令,分别乘以了5、6、7
当imul指令为三操作数时,就是将第二个操作数和第三个操作数的乘积保存到第一个操作数中
拿上面的例子来说:
00401042 imul eax,eax,5
就是(第一个操作数)eax=(第二个操作数)eax × (第三个操作数)5

 [复制链接]
[复制链接]
 发表于 2021-3-6 18:19
发表于 2021-3-6 18:19
 |
发表于 2021-5-9 13:41
|
发表于 2021-5-9 13:41





