写在前面的话
看过我之前的文章都可能是开发的大佬,最近我在思考一个问题,如果小白看我的文章能够理解吗?大家有没有发现我以前的文章都是那种优质的教程(老脸一红,好吧其实就是我自己的笔记,为了让大家更通俗易通,尝试下改变风格。)
消息队列(mq)是什么?
在之前写过一片叫 使用RabbitMQ的完整图解 的文章讲述了从安装到基本使用,遇到问题的处理,还有每一步的图片详解。
消息队列中间件是分布式系统中重要的组件(单机版也可用:单机版指的是在服务器上安装),主要解决应用耦合,异步消息,流量削锋等问题。
实现高性能,高可用,可伸缩和最终一致性架构。
使用较多的消息队列有ActiveMQ,RabbitMQ,ZeroMQ,Kafka,MetaMQ,RocketMQ。
消息队列,一般我们会简称它为MQ(Message Queue)
名词解释
- 把数据放到(
push)消息队列叫做生产者
- 从消息队列里边取(
get)数据叫做消费者
你有没有想过为什么要用MQ?
你心里可能会想,大家都用了呗,那我也就用。(这回答拉出去枪毙十次)
Tip:这三个场景也是消息队列的经典场景,大家基本上要烂熟于心那种,就是一说到消息队列你脑子就要想到异步、削峰、解耦,条件反射那种。
异步
这个异步的概念可能和Task这个异步不太一样。微软定义的异步(打个比方,你要烧水,扫地,用异步就是把水烧上的同时可能进行扫地)
你要是理解上面的mq是用来干嘛的那就很好理解这个异步是什么意思
再打个比方下单的流程一般就是提交订单接口中有支付,像图片中第一个流程,本来下单就用50ms(Response-Time响应时间),但是到后面的话就用单200ms。如果是放到消息队列里面,他发短信,扣优惠券,积分抵扣等一会在处理也行。(网上样图见后两张)
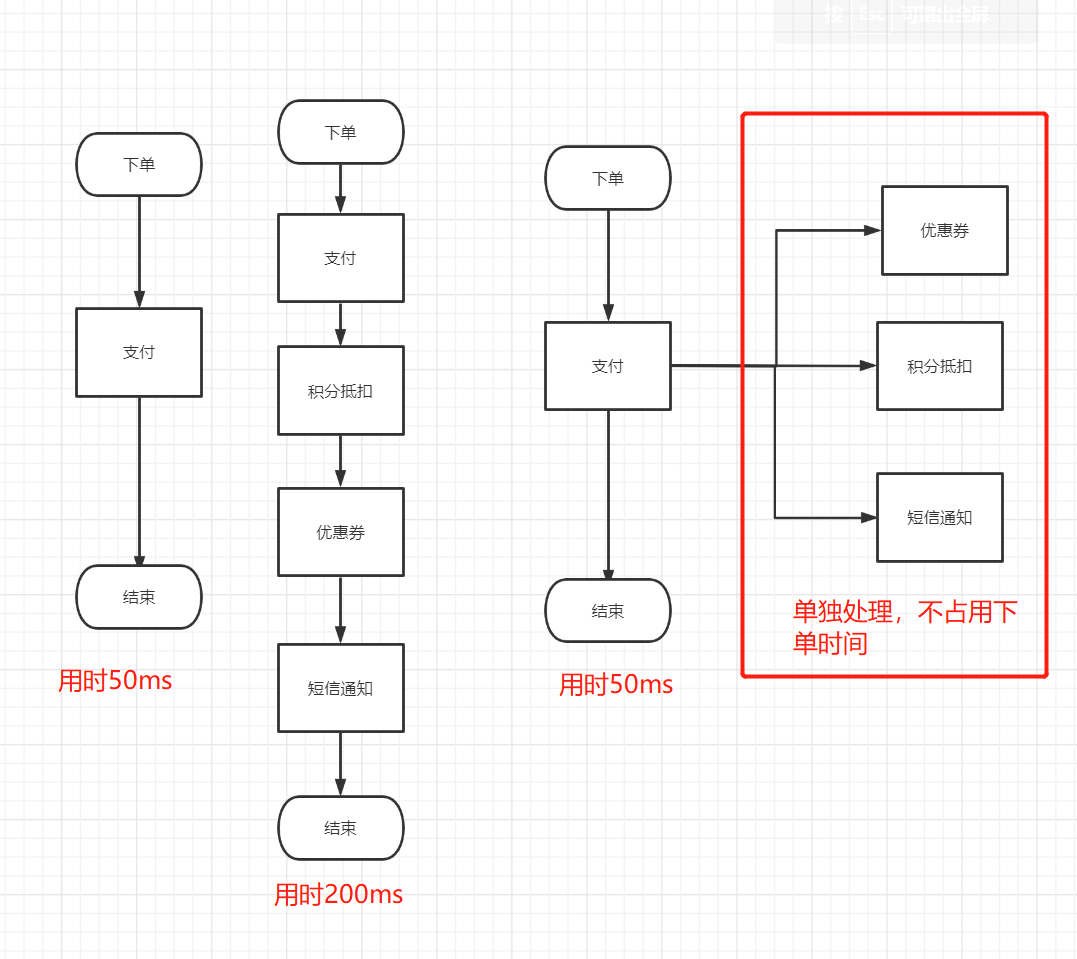
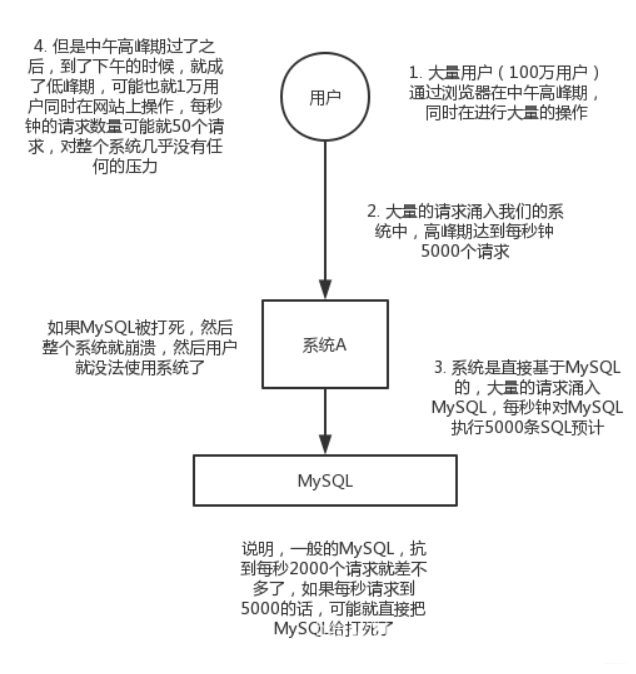
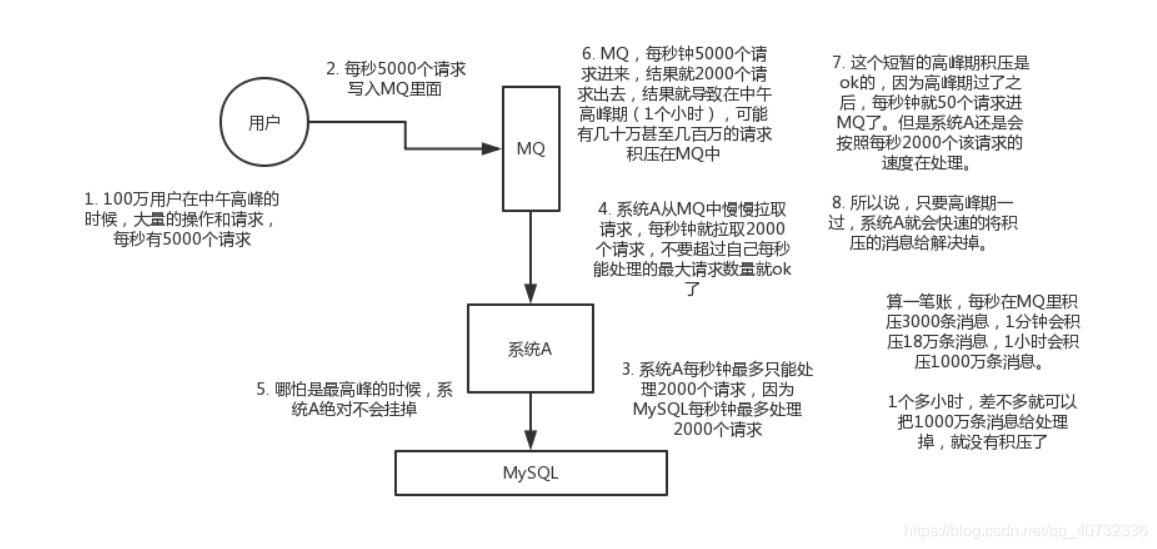
削峰/限流
比如每周会有一次限时抢购的活动,活动刚开始的时候就会有打部分的用户,造成高并发,倘若系统一次只能让500个人同时进来,用户有2000个同时进来,不可能不让用户进来吧,同时进来的话就会给服务器造成压力,甚至宕机(关机-停止服务)。解决办法就用到了消息队列,消息队列有一个原则,先进先出(像去超市买东西结账排队一样)。这样的话就处理ok了
解耦
公司有几个系统A,B,C,D,A系统有一个字符串(你可以理解为有一个东西),供B,C系统调用,你用代码实现,直接调用B,C系统的方法,讲参数给传递过去;过来几天,老大说,B不用这个字符串了,管理A系统的人改改代码完成了,去掉了调用的方法,有过几天B系统又用这个字符串了,你有重新调用,但一天过去了,需求不断更改。管理A系统的人跑路了,后面来个大佬,直接新定义,你B,C,D那个系统用这个字符串,你直接去MQ(消息队列里面去拿),然后就不用管B,C,D他用不用这个东西(第一次尝试用xmind,画的不太好,我画的怎么好,就从网上下载了两只样图
)。
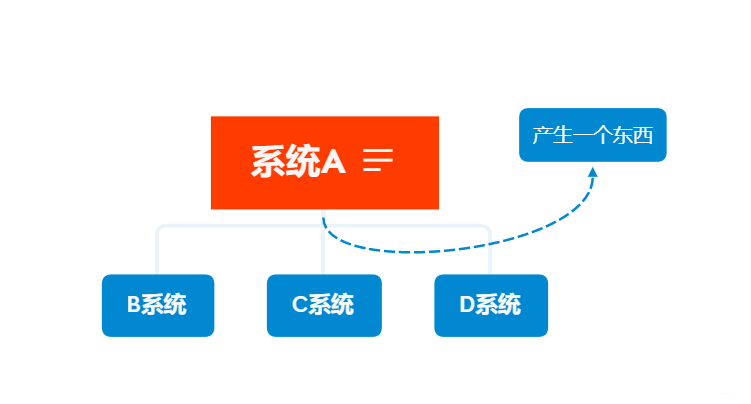
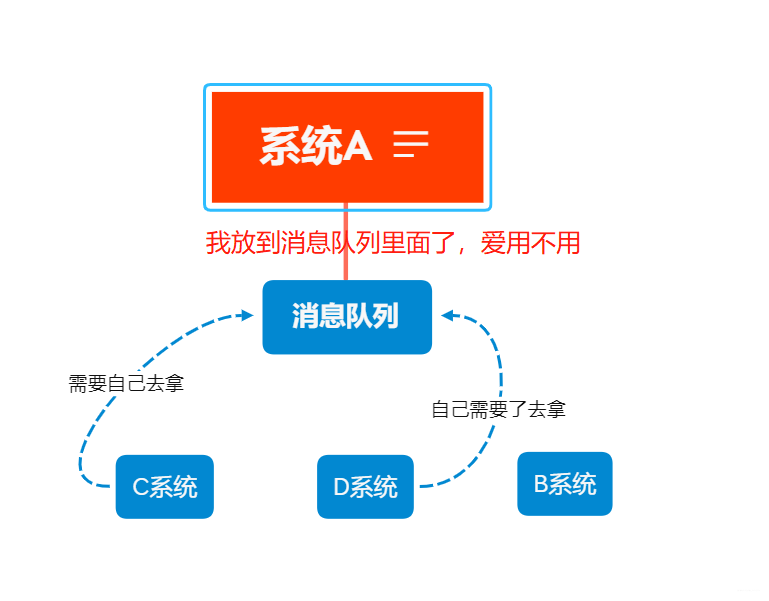
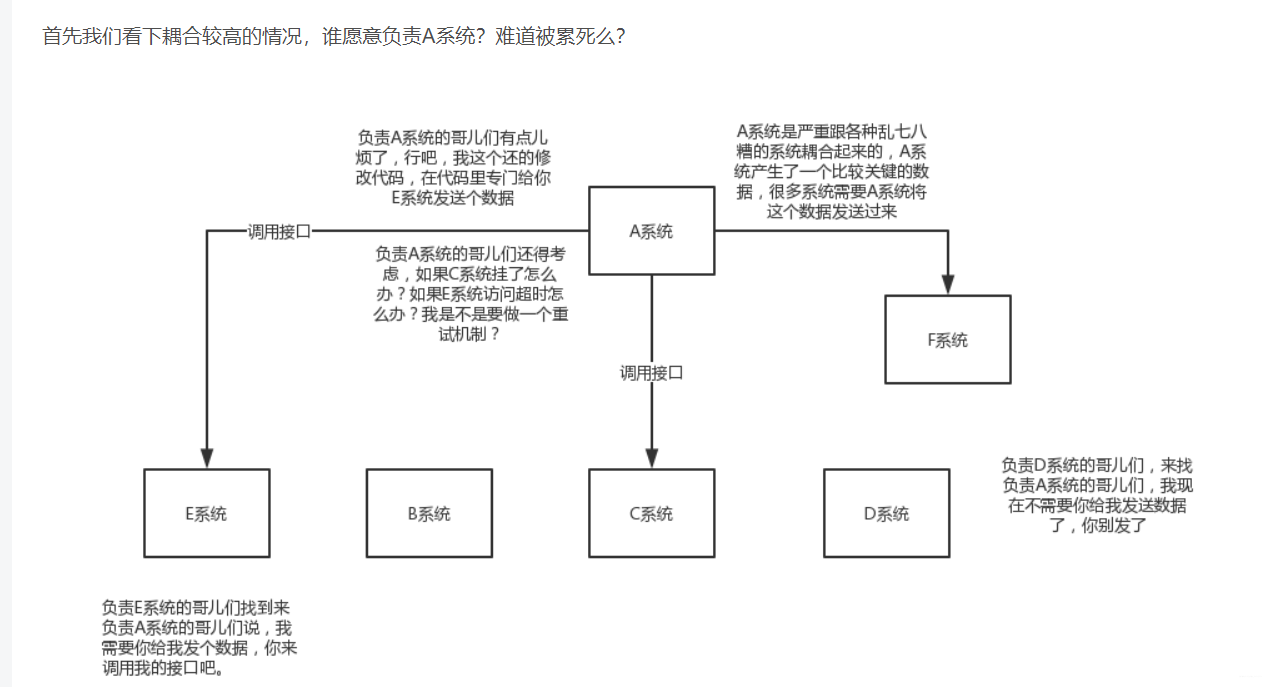
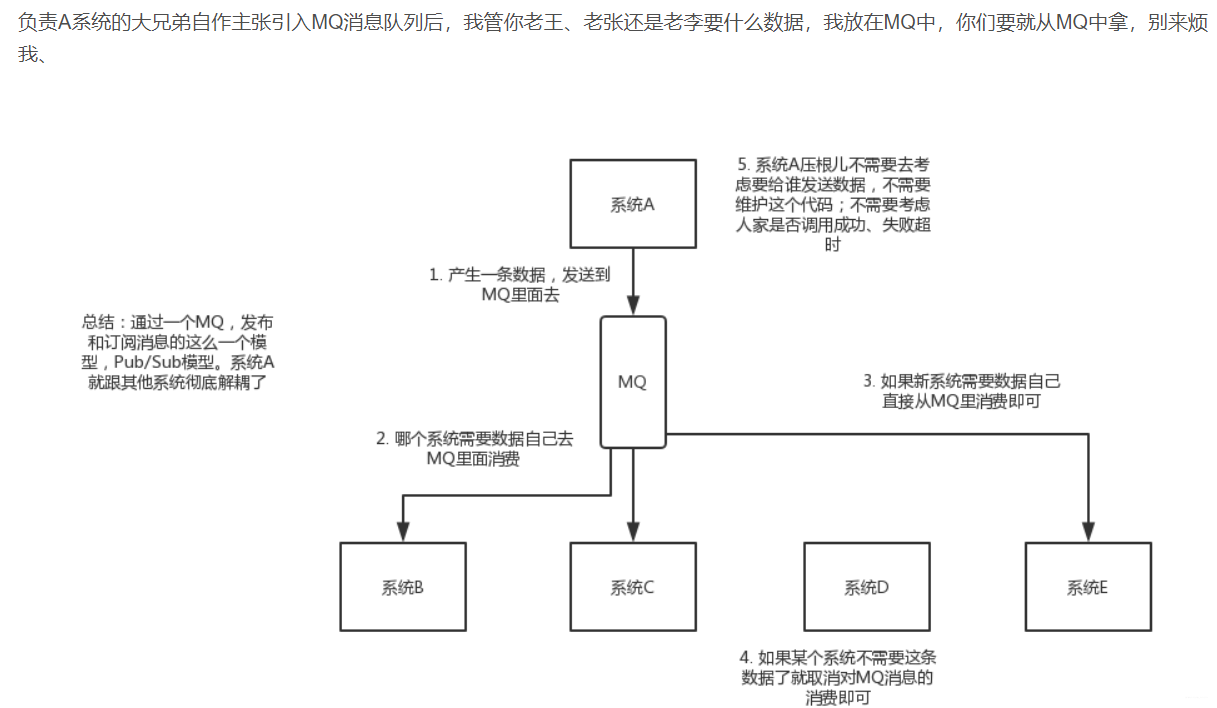
用到分布式的话,后面还有好多坑。先挖坑
- 如何保证队列消息高可用(比如队列消息挂了)
- 分布式如何处理
- 数据是否持久化保存
每日一面
堆和栈的区别:
一、堆栈空间分配区别:
1、栈(操作系统):由操作系统自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈;
2、堆(操作系统): 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收,分配方式倒是类似于链表。
二、堆栈缓存方式区别:
1、栈使用的是一级缓存, 他们通常都是被调用时处于存储空间中,调用完毕立即释放;
2、堆是存放在二级缓存中,生命周期由虚拟机的垃圾回收算法来决定(并不是一旦成为孤儿对象就能被回收)。所以调用这些对象的速度要相对来得低一些。
三、堆栈数据结构区别:
堆(数据结构):堆可以被看成是一棵树,如:堆排序;
栈(数据结构):一种先进后出的数据结构。
关于其他个人笔记
- C# 使用RabbitMQ的完整图解
- VS中进行编码时智能提示由英文切换为中文
- 开源项目-一沙后台管理(core-mvc-缓存,支持多数据库)
- ASP.NET Core中使用NLog记录日志
- Visual Studio中Git的使用
- [完全图解]NET Croe 使用JWT验证签名

 [复制链接]
[复制链接]
 发表于 2021-3-20 22:32
发表于 2021-3-20 22:32
 |
发表于 2021-3-24 13:12
|
发表于 2021-3-24 13:12



