那天,我在吾爱上逛,看见一篇文章:Python自学记录--实战1--爬取美女图片。碰巧的是,我也正在学习爬虫,只是当时还没有学lxml库,心里一激动,抓紧学了一下。然后就开始尝试自己写程序爬取楼主练手的网站,经过漫长的煎熬,一个多星期内,多次弃之不管,然后再次捡起,我的第一个爬虫程序终于勉强可以用了。
我感觉主要是因为我根本没接触过 HTML,和编程的交集只有刚入门的 python,所以在 HTML 中匹配图片网址的地方浪费了很多时间,经常返回一个空的列表,让我抓狂
和上面那篇文章相比,改进的地方有:
- 下载下来的图片名是乱码(通过
chardet库检测网站编码为 GB2312 ,重编码为 GBK)
- 将代码分割为一个个的函数,函数式编程,方便调用和修正
- 扩大壁纸的范围(原帖只下载了 美女 类别的壁纸)
- 加入
headers参数,一定程度上提高爬虫的稳定性(那一堆ua也是在吾爱上的一个帖子里抄来的)
- 生成可执行文件,电脑上没有 python 环境的小可爱也可以用(比较简陋,因为打包文件我只会一丢丢)
- 减少一个潜在的错误:图片下载的默认保存位置是 D盘的ptoto文件夹 ,但是,如果没有提前新建这个目录,程序就会产生错误。为此,我专门去百度,抄来用
os新建文件夹的代码
在我没有学习爬虫之前,曾经也复制过吾友的代码尝试过运行,总是发生错误。而当时的我没有能力解决错误,就遇错避之,体验很差,所以我尽量降低使用门槛
原帖评论中有位老哥加了IP代{过}{滤}理和多线程,还定义了一个类,很高级,很强大,但是面向对象我还不怎么懂,也没接触过IP代{过}{滤}理,使用起来还是有一定门槛的
温馨提示:我看这个网站的图片基本上都可以免费下载,所以就别一下子爬很多图片了,一天下个几十张还不够?我低调,他不知道,两方利好,皆大欢喜。对于花费时间得到的东西:用到了,就是珍宝;用不到,放在一边蒙尘,就是垃圾
注意,如果遇到了拦路虎,请看:
- 默认保存位置是 d:\photo_from_52pojie.com
对于想复制代码自己运行的,两个地方需要注意:
requests, lxml, chardet 这三个都是第三方库,需要先下载下来ua在这里:
 ua.7z
(1.51 KB, 下载次数: 43)
。(不能上传
ua.7z
(1.51 KB, 下载次数: 43)
。(不能上传py文件,我没敢用 txt 格式,担心格式错误)运行程序的时候把ua.py和主程序的文件放在一个目录下就行
对于下载 exe 文件的,两个地方需要注意:
发布成品的帖子:
【python原创】temp_2 V1.0 壁纸爬取下载(单文件)
https://www.52pojie.cn/thread-1528917-1-1.html
(出处: 吾爱破解论坛)
-
不论是程序运行出错,还是成功下载,最后都会突然关闭页面。除非你眼光犀利到可以在那不到一秒的时间看见最后出来的字,否则想知道结果只能去 d:\photo_from_52pojie.com 这个目录看看有没有下载下来
-
我已经尽力了,体验确实不好,其他的我不会
代码
import requests
from lxml import etree
import chardet
import ua
import os
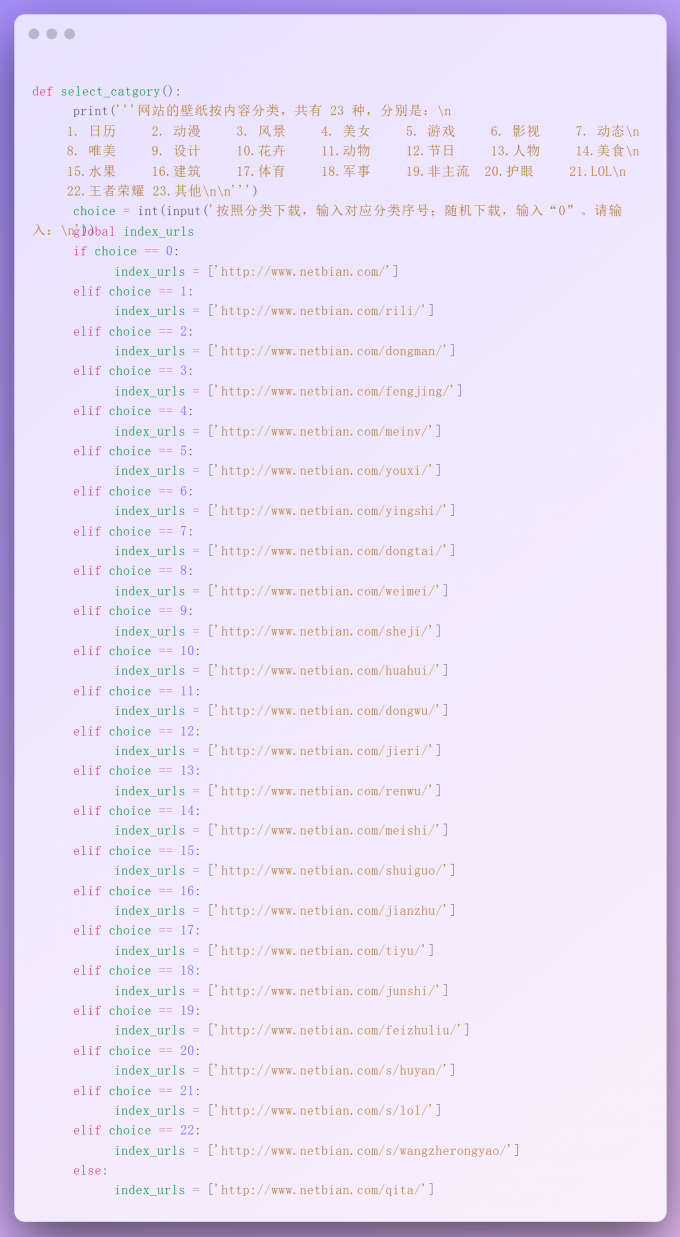
def select_catgory():
print('''网站的壁纸按内容分类,共有 23 种,分别是:\n
1. 日历 2. 动漫 3. 风景 4. 美女 5. 游戏 6. 影视 7. 动态\n
8. 唯美 9. 设计 10.花卉 11.动物 12.节日 13.人物 14.美食\n
15.水果 16.建筑 17.体育 18.军事 19.非主流 20.护眼 21.LOL\n
22.王者荣耀 23.其他\n\n''')
choice = int(input('按照分类下载,输入对应分类序号;随机下载,输入“0”。请输入:\n'))
choices = ['http://www.netbian.com/',
'http://www.netbian.com/rili/',
'http://www.netbian.com/dongman/',
'http://www.netbian.com/fengjing/',
'http://www.netbian.com/meinv/',
'http://www.netbian.com/youxi/',
'http://www.netbian.com/yingshi/',
'http://www.netbian.com/dongtai/',
'http://www.netbian.com/weimei/',
'http://www.netbian.com/sheji/',
'http://www.netbian.com/huahui/',
'http://www.netbian.com/dongwu/',
'http://www.netbian.com/jieri/',
'http://www.netbian.com/renwu/',
'http://www.netbian.com/meishi/',
'http://www.netbian.com/shuiguo/',
'http://www.netbian.com/jianzhu/',
'http://www.netbian.com/tiyu/',
'http://www.netbian.com/junshi/',
'http://www.netbian.com/feizhuliu/',
'http://www.netbian.com/s/huyan/',
'http://www.netbian.com/s/lol/',
'http://www.netbian.com/s/wangzherongyao/',
'http://www.netbian.com/qita/']
global index_urls
index_urls = []
index_urls.append(choices[choice])
global n
n = int(input("需要下载多少张壁纸?\n"))
def get_code_type():
# 请求首页
global r
r = requests.get('http://www.netbian.com/', headers=ua.ua())
code_type = chardet.detect(r.content)['encoding']
if code_type == 'GB2312':
code_type = 'GBK'
r.encoding = code_type
def get_pre(n):
global page_urls
page_urls = []
# 网站总共 1216 页
for i in range(1, n//20+2):
# 获取每一张图片所在页面的 URL,来下载图片原图
r_i = requests.get(index_urls[i-1], headers=ua.ua())
html = etree.HTML(r_i.text)
page_urls += html.xpath('body//*[@class="list"]/ul//li/a/@href')
index_url = '{}index_{}.htm'.format(index_urls[0], i+1)
index_urls.append(index_url)
def get_jpg():
# 获取每一张图片的 URL,下载图片原图
for page_url in page_urls:
if page_urls.index(page_url) > n-1:
break
r_page = requests.get('http://www.netbian.com'+page_url, headers=ua.ua())
if r.encoding == 'GBK':
r_page.encoding = 'GBK'
html = etree.HTML(r_page.text)
jpg_url = html.xpath('body//*[@class="pic"]/p/a/img/@src')
jpg_title = html.xpath('body//*[@class="pic"]/p/a/img/@title')
jpg = list(zip(jpg_title, jpg_url))
r_jpg = requests.get(jpg[0][1], headers=ua.ua())
if r.encoding == 'GBK':
r_jpg.encoding = 'GBK'
if os.path.exists(r'd:\photo_from_52pojie.com'):
pass
else:
os.mkdir(r'd:\photo_from_52pojie.com')
with open(fr'd:\photo_from_52pojie.com\{jpg[0][0]}.jpg', 'wb') as f:
f.write(r_jpg.content)
print('第{}张图片下载完成!'.format(page_urls.index(page_url)+1))
def main():
get_code_type()
try:
select_catgory()
get_pre(n)
get_jpg()
print(f'{n}张图片全部下载完成,默认保存位置是 d:\photo_from_52pojie.com')
except ValueError:
print('输入有误,请输入一个非负整数!')
except IndexError:
print('请输入正确的序号!')
except:
print('发生未知错误!')
main()
我的倔强
有时候,为了心中莫名的倔强,你会坚持泅水过河,而不是走旁边的桥
于是,过河后,我一边拧着身上的水,一边笑嘻嘻,心里甜蜜蜜
我希望可以选择性的下载网站中各个类别的壁纸,所以,昨天下午,我在代码中加了这些东西:
如你所见,过程枯燥无比,代码又臭又长。甚至还想着把这个函数单独放在一个py文件里,然后import
今天早上打开文件的时候灵光一闪,把所有的网址放进一个列表里,然后通过索引访问网址不好吗?
说干就干,我开始把网址一个个的复制进列表里,,,
在复制的过程中,我想起来一件事:在学习 python 之前,我听说过一句话,大致意思是所有重复性很高的工作都可以交给计算机来做。
然后我就想,在交给计算机之前,人还是要做一些重复性的工作啊。突然,我又灵光一闪,现在做的事也可以交给计算机啊
别看说起来啰里吧嗦,实际上只在须臾之间就发生了,像玄幻小说里写的一样:眨眼间过招百余次
我向下滑了滑鼠标滚轮,发现此时复制了 8 个网址,大概 1/3 ,嗯,有操作空间
说干就干,我把那一堆if语句复制到一个空文件。稍加琢磨,写出如下东东:
result = []
for choice in range(24):
if choice == 0:
# 省略几十行
else:
index_urls = ['http://www.netbian.com/qita/']
result += index_urls
print(result)
结果如下:
['http://www.netbian.com/', 'http://www.netbian.com/rili/', 'http://www.netbian.com/dongman/', 'http://www.netbian.com/fengjing/', 'http://www.netbian.com/meinv/', 'http://www.netbian.com/youxi/', 'http://www.netbian.com/yingshi/', 'http://www.netbian.com/dongtai/', 'http://www.netbian.com/weimei/', 'http://www.netbian.com/sheji/', 'http://www.netbian.com/huahui/', 'http://www.netbian.com/dongwu/', 'http://www.netbian.com/jieri/', 'http://www.netbian.com/renwu/', 'http://www.netbian.com/meishi/', 'http://www.netbian.com/shuiguo/', 'http://www.netbian.com/jianzhu/', 'http://www.netbian.com/tiyu/', 'http://www.netbian.com/junshi/', 'http://www.netbian.com/feizhuliu/', 'http://www.netbian.com/s/huyan/', 'http://www.netbian.com/s/lol/', 'http://www.netbian.com/s/wangzherongyao/', 'http://www.netbian.com/qita/']
本来,事情到这里就结束了,但是,我又想把这个列表中的每个元素单独放在一行,只是为了整洁美观
说干就干,我开始一下一下按 enter 键,在我按了两次后,突然又灵光一闪,让程序输出我想要的样子不行吗?
然后我把这个结果复制进文件,开始观察,同时心中飘过一些碎碎念:print()输出的字符串没有引号;用join()方法行不行;。。。
几经修改,代码变成了这个样子:
result = []
for choice in range(24):
if choice == 0:
# 省略几十行
else:
index_urls = ['http://www.netbian.com/qita/']
result += index_urls
for i in range(24):
print("'{}'".format(result[i]),end='')
if i == 23:
break
print(',')
运行结果:
'http://www.netbian.com/',
'http://www.netbian.com/rili/',
'http://www.netbian.com/dongman/',
'http://www.netbian.com/fengjing/',
'http://www.netbian.com/meinv/',
'http://www.netbian.com/youxi/',
'http://www.netbian.com/yingshi/',
'http://www.netbian.com/dongtai/',
'http://www.netbian.com/weimei/',
'http://www.netbian.com/sheji/',
'http://www.netbian.com/huahui/',
'http://www.netbian.com/dongwu/',
'http://www.netbian.com/jieri/',
'http://www.netbian.com/renwu/',
'http://www.netbian.com/meishi/',
'http://www.netbian.com/shuiguo/',
'http://www.netbian.com/jianzhu/',
'http://www.netbian.com/tiyu/',
'http://www.netbian.com/junshi/',
'http://www.netbian.com/feizhuliu/',
'http://www.netbian.com/s/huyan/',
'http://www.netbian.com/s/lol/',
'http://www.netbian.com/s/wangzherongyao/',
'http://www.netbian.com/qita/'
对的,你没有看错,只是为了最后那一个逗号不用 delete 键删除,我在像看媳妇一样看了运行结果几秒后,多写了 3 行代码,然后花费了好几分钟调试:两个print语句到底哪个后面需要加end参数?怎么逗号单独成行了?怎么两个 URL 之间有个空行?还用了两三分钟琢磨这段话废话怎么写,然后敲下来。
一切,只是为了倔强
有时候,为了心中莫名的倔强,你会坚持泅水过河,而不是走旁边的桥
于是,过河后,我一边拧着身上的水,一边笑嘻嘻,心里甜蜜蜜
不管是手动复制,还是按回车,甚至是删除一个标点符号,我都不愿意手动完成,只是为了实现那句话:交给计算机做
完成一切之后,我又想:为什么不想办法让程序直接输出一个列表呢?这样你连[]都不用加了。我想,是因为:解决这三件琐碎事情,我已经心疲力竭,耗光了倔强,耐心也消耗殆尽。已经浪费了不少时间,是时候停止顽皮了。
嘿,哥们,你的beautifulsoup4还没练会呢,你的作业还没写呢,你的淘宝嫖红包的每日任务还没做呢,你的肚子好像快饿了,你今天还没浏览美女图片以求长寿呢,,,

 [复制链接]
[复制链接]
 发表于 2021-10-16 17:18
发表于 2021-10-16 17:18




