拿到文件ida打开,发现是很绝望的究极无敌的代码混淆——控制流平坦化。

控制流平坦化介绍
控制流平坦化(control flow flattening)的基本思想主要是通过一个主分发器来控制程序基本块的执行流程,例如下图是正常的执行流程
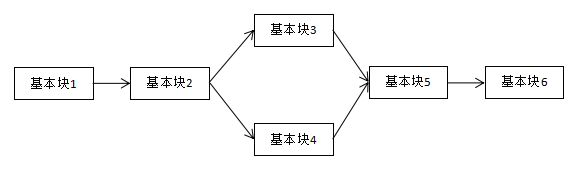
在经过控制流平台化的混淆之后,会变成如下的结构
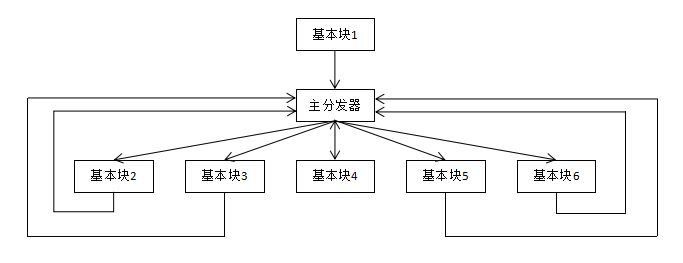
流程图看起来就像是同一级的关系,块之间失去了层次分明,逻辑可读性变得更差。
就好比我们平时做的堆菜单题,选择菜单的时候,逻辑基本就是
while(1){
menu();
int num=getnum();
switch(num){
case 1:
add();
break;
case 2:
edit();
break;
case 3:
delete();
break;
case 4:
show();
break;
default:
error_choice();
}
}
但是有时候经过ida反编译并不是那么清晰的,我也不知道它是不是特意加了混淆还是ida本身的问题,反编译代码变成了下面的情况
while(1){
while(1){
while(1){
while(1){
while(1){
menu();
int num=getnum();
if(num!=1){
break;
}
add();
}
if(num>2){
break;
}
edit();
}
if(num!=3){
break;
}
show();
}
if(num!=4){
break;
}
edit();
}
error_choice;
}
这么说吧,两个代码实现的功能是一样的,但是明显下面的可读性就变差了很多。我也不知道是不是这个在作妖,就是觉得很像,提出来讲一讲hhh。
但是好像又没有关系,因为它们块之间的关系本来就是平坦的,后面只是用while替代switch进行进一步混淆,但是其实有menu函数一看便知,所以它在这里加这样的逻辑混淆的确是无用功。
那么我猜控制流平坦化的流程就是:
①将所有块平坦化
②用switch分发
③把switch转成如上的那种while循环包起来的代码。
至于平坦化了之后如何实现前后的逻辑的关系呢?其实很简单,比如下面这个逻辑
假如明天下雨,那么我带伞,然后出门,否则我带上我的自行车,然后出门,写成伪代码是下面的逻辑
if (rain){
get_umb();
}
else{
get_bike();
}
go_out();
代码这么写起来看起来逻辑还是十分清晰的,那么如果加控制流平坦化混淆它会变成什么样呢?这里很明显出现三个语句块,如果rain条件成立,那么get_umb(),否则get_bike(),最后一定会执行go_out()。那么get_umb和get_bike就是一个二选一的关系,这俩块跟go_out又是先后的关系,这是我们一眼可以看出来的逻辑。
控制流平坦化第一步就是拆掉他们这样的逻辑关系,甭管有多少块,全部用while(1)+switch去控制,如下代码所示。
while(1){
ch=rain;
switch(ch){
case 0:
get_bike();
ch=2;
break;
case 1:
get_umb();
ch=2;
break;
case 2:
get_bike();
flag=1;
}
if(flag){
break;
}
}
可以发现平坦化了之后略微有一点点不可读,但是还能接受,但是它往往不会让你看的那么容易,因为它ch不可能就1,2,3,4这么给你弄好了,我再进一步加混淆。
while(1){
ch=(rain*2+9876)*9+100;
switch(ch){
case 88984:
get_bike();
ch=ch*9+1;
break;
case 89002:
get_umb();
ch=(ch-18)*9+1;
break;
case 800857:
get_bike();
flag=1;
}
if(flag){
break;
}
}
如果块再多,运算再复杂,你可能都不能一眼看出来下不下雨和带不带伞是一个什么联系了。
然后switch再同如上的menu这样变换一下逻辑,就更难读了,也就是我们题目中看到的这个样子,可以发现,它平坦的块已经是特别密集了,疯狂while(1)然后中间条件判断去break。
以上分析均为自己个人理解,并使用自己最朴素的语言讲述出来的。
抵抗控制流平坦化
既然有人研究出了这样的代码混淆,自然也有人研究出了对应的解法,这里放项目地址https://github.com/cq674350529/deflat
该项目以angr作为依赖,在个人使用的时候我把它源码download下来还需要把它flat_control_flow目录下的deflat.py移动到上一层目录才能正常使用,使用方式:
$python(3) deflat.py -f [file_name] --addr [function_addr]
这里function_addr即为添加了此混淆的函数地址。放着跑个几分钟,就能跑出来一个控制流比较清晰的elf文件了。
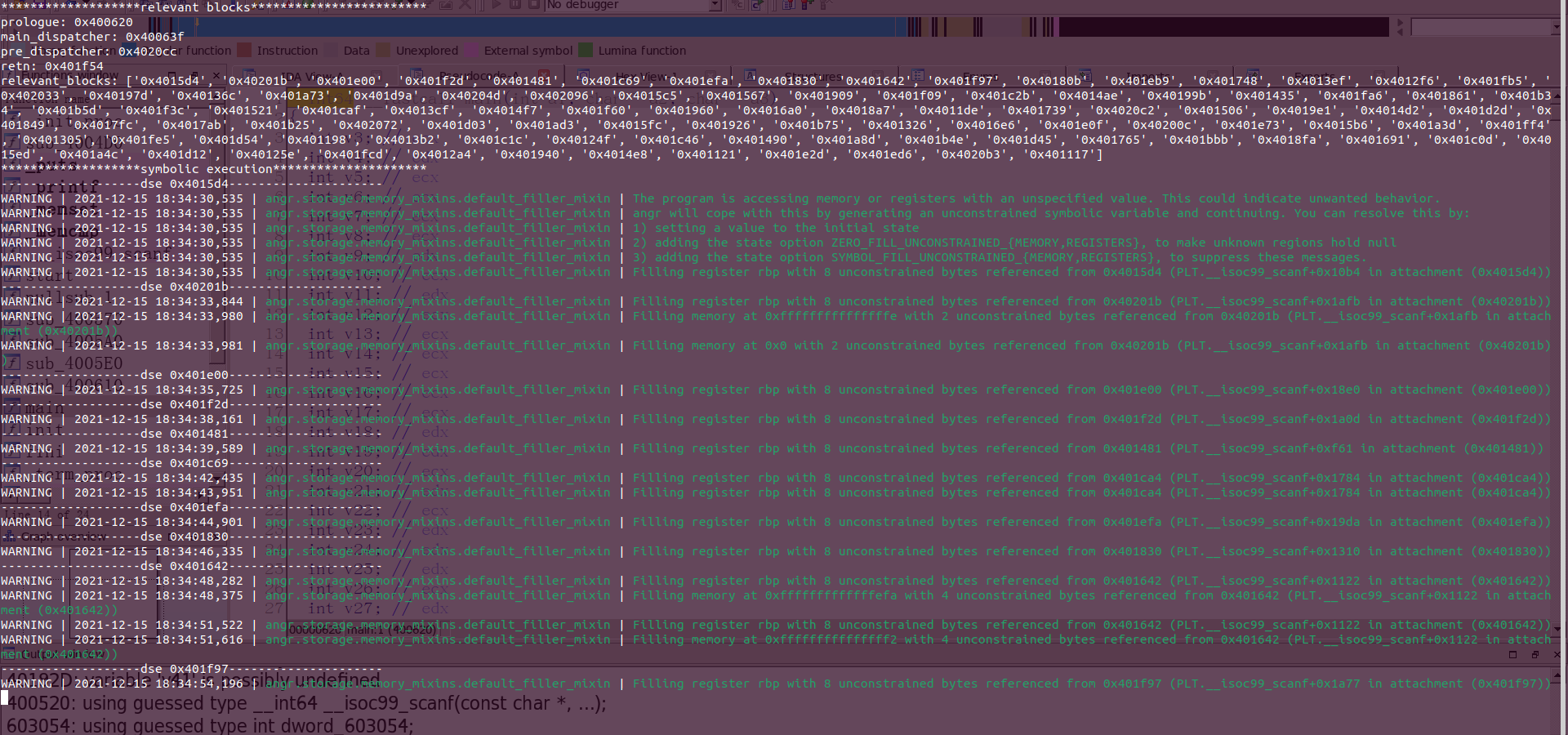
代码分析
我们用ida反编译能得到以下代码
__int64 __fastcall main(int a1, char **a2, char **a3)
{
signed __int64 v4; // [rsp+1E0h] [rbp-110h]
int i; // [rsp+1E8h] [rbp-108h]
int v6; // [rsp+1ECh] [rbp-104h]
int v7; // [rsp+1ECh] [rbp-104h]
char s1[48]; // [rsp+1F0h] [rbp-100h] BYREF
char s[60]; // [rsp+220h] [rbp-D0h] BYREF
unsigned int v10; // [rsp+25Ch] [rbp-94h]
char *v11; // [rsp+260h] [rbp-90h]
int v12; // [rsp+26Ch] [rbp-84h]
bool v13; // [rsp+272h] [rbp-7Eh]
unsigned __int8 v14; // [rsp+273h] [rbp-7Dh]
int v15; // [rsp+274h] [rbp-7Ch]
char *v16; // [rsp+278h] [rbp-78h]
int v17; // [rsp+284h] [rbp-6Ch]
int v18; // [rsp+288h] [rbp-68h]
bool v19; // [rsp+28Fh] [rbp-61h]
char *v20; // [rsp+290h] [rbp-60h]
int v21; // [rsp+298h] [rbp-58h]
bool v22; // [rsp+29Fh] [rbp-51h]
__int64 v23; // [rsp+2A0h] [rbp-50h]
bool v24; // [rsp+2AFh] [rbp-41h]
__int64 v25; // [rsp+2B0h] [rbp-40h]
__int64 v26; // [rsp+2B8h] [rbp-38h]
__int64 v27; // [rsp+2C0h] [rbp-30h]
__int64 v28; // [rsp+2C8h] [rbp-28h]
int v29; // [rsp+2D0h] [rbp-20h]
int v30; // [rsp+2D4h] [rbp-1Ch]
char *v31; // [rsp+2D8h] [rbp-18h]
int v32; // [rsp+2E0h] [rbp-10h]
int v33; // [rsp+2E4h] [rbp-Ch]
bool v34; // [rsp+2EBh] [rbp-5h]
v10 = 0;
memset(s, 0, 0x30uLL);
memset(s1, 0, sizeof(s1));
printf("Input:");
v11 = s;
if ( dword_603058 >= 10 && ((((_BYTE)dword_603054 - 1) * (_BYTE)dword_603054) & 1) != 0 )
goto LABEL_43;
while ( 1 )
{
__isoc99_scanf("%s", v11);
v6 = 0;
if ( dword_603058 < 10 || ((((_BYTE)dword_603054 - 1) * (_BYTE)dword_603054) & 1) == 0 )
break;
LABEL_43:
__isoc99_scanf("%s", v11);
}
while ( 1 )
{
do
v12 = v6;
while ( dword_603058 >= 10 && ((((_BYTE)dword_603054 - 1) * (_BYTE)dword_603054) & 1) != 0 );
v13 = v12 < 64;
while ( dword_603058 >= 10 && ((((_BYTE)dword_603054 - 1) * (_BYTE)dword_603054) & 1) != 0 )
;
if ( !v13 )
break;
v14 = s[v6];
do
v15 = v14;
while ( dword_603058 >= 10 && ((((_BYTE)dword_603054 - 1) * (_BYTE)dword_603054) & 1) != 0 );
if ( v15 == 10 )
{
v16 = &s[v6];
*v16 = 0;
break;
}
v17 = v6 + 1;
do
v6 = v17;
while ( dword_603058 >= 10 && ((((_BYTE)dword_603054 - 1) * (_BYTE)dword_603054) & 1) != 0 );
}
for ( i = 0; ; ++i )
{
do
v18 = i;
while ( dword_603058 >= 10 && ((((_BYTE)dword_603054 - 1) * (_BYTE)dword_603054) & 1) != 0 );
do
v19 = v18 < 6;
while ( dword_603058 >= 10 && ((((_BYTE)dword_603054 - 1) * (_BYTE)dword_603054) & 1) != 0 );
if ( !v19 )
break;
do
v20 = s;
while ( dword_603058 >= 10 && ((((_BYTE)dword_603054 - 1) * (_BYTE)dword_603054) & 1) != 0 );
v4 = *(_QWORD *)&v20[8 * i];
v7 = 0;
while ( 1 )
{
v21 = v7;
do
v22 = v21 < 64;
while ( dword_603058 >= 10 && ((((_BYTE)dword_603054 - 1) * (_BYTE)dword_603054) & 1) != 0 );
if ( !v22 )
break;
v23 = v4;
v24 = v4 < 0;
if ( v4 >= 0 )
{
v27 = v4;
do
v28 = 2 * v27;
while ( dword_603058 >= 10 && ((((_BYTE)dword_603054 - 1) * (_BYTE)dword_603054) & 1) != 0 );
v4 = v28;
}
else
{
v25 = 2 * v4;
do
v26 = v25;
while ( dword_603058 >= 10 && ((((_BYTE)dword_603054 - 1) * (_BYTE)dword_603054) & 1) != 0 );
v4 = v26 ^ 0xB0004B7679FA26B3LL;
}
v29 = v7;
do
v7 = v29 + 1;
while ( dword_603058 >= 10 && ((((_BYTE)dword_603054 - 1) * (_BYTE)dword_603054) & 1) != 0 );
}
v30 = 8 * i;
v31 = &s1[8 * i];
if ( dword_603058 >= 10 && ((((_BYTE)dword_603054 - 1) * (_BYTE)dword_603054) & 1) != 0 )
LABEL_55:
*(_QWORD *)v31 = v4;
*(_QWORD *)v31 = v4;
if ( dword_603058 >= 10 && ((((_BYTE)dword_603054 - 1) * (_BYTE)dword_603054) & 1) != 0 )
goto LABEL_55;
v32 = i + 1;
}
do
v33 = memcmp(s1, &unk_402170, 0x30uLL);
while ( dword_603058 >= 10 && ((((_BYTE)dword_603054 - 1) * (_BYTE)dword_603054) & 1) != 0 );
v34 = v33 != 0;
while ( dword_603058 >= 10 && ((((_BYTE)dword_603054 - 1) * (_BYTE)dword_603054) & 1) != 0 )
;
if ( v34 )
puts("Wrong!");
else
puts("Correct!");
return v10;
}
自习一看其实就发现其实它还是加了一些混淆,比如里面重复的
while ( dword_603058 >= 10 && ((((_BYTE)dword_603054 - 1) * (_BYTE)dword_603054) & 1) != 0 )
这个表达式实际上是永远为假的,它因为dword_603058这个全局变量是在bss段上的,bss段上为未初始化的全局变量,所以它就是0。而且查一下它的交叉引用表也会发现与它相关的指令都是作为源操作数而非目的操作数,而且也没有取它地址做某些操作,在此基础之上我们基本可以认为它就是不变的。
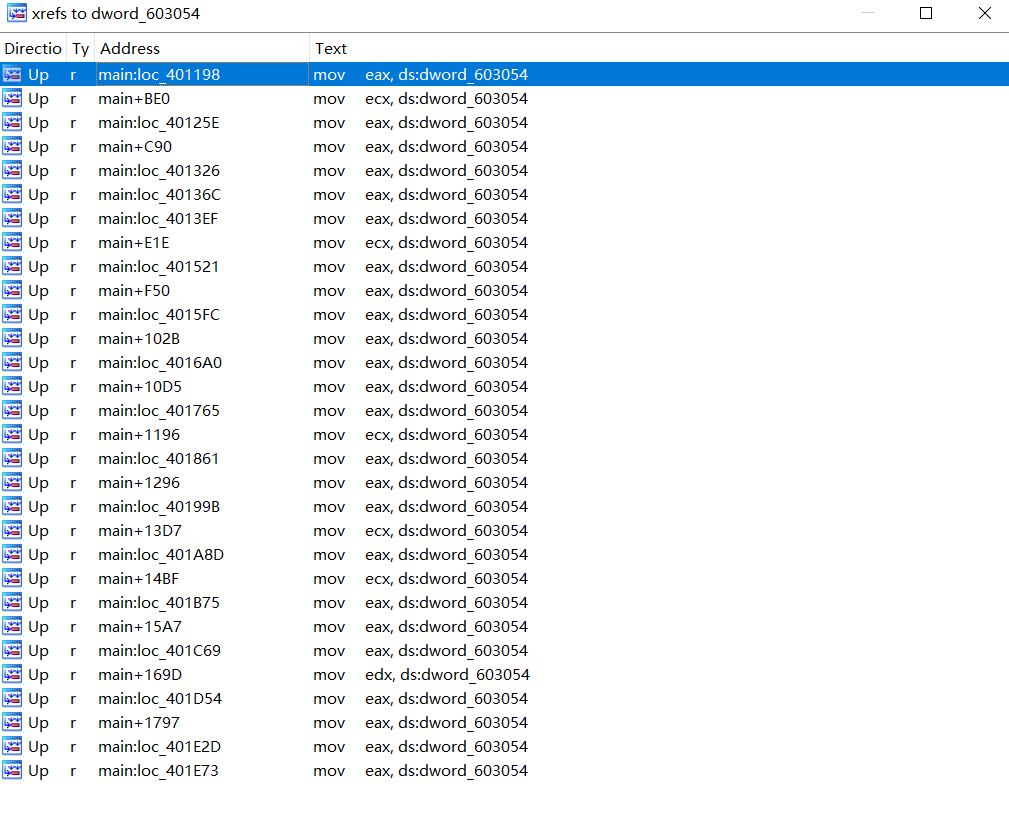
所以这去了混淆之后还有一百多行的代码其实是他自己手动疯狂加的混淆。所以这里直接把所有的
do
xxx
while ( dword_603058 >= 10 && ((((_BYTE)dword_603054 - 1) * (_BYTE)dword_603054) & 1) != 0 )
全部替换成xxx就好了,因为它只执行一次就退出了。
此外还有一些永为1的表达式。
if ( dword_603058 < 10 || ((((_BYTE)dword_603054 - 1) * (_BYTE)dword_603054) & 1) == 0 )
break;
这种情况下我我们直接把while循环去了,然后把这个语句之后在while循环语句内的所有语句都删了。
然后得到了以下的代码
__int64 __fastcall main(int a1, char **a2, char **a3)
{
signed __int64 v4; // [rsp+1E0h] [rbp-110h]
int i; // [rsp+1E8h] [rbp-108h]
int v6; // [rsp+1ECh] [rbp-104h]
int v7; // [rsp+1ECh] [rbp-104h]
char s1[48]; // [rsp+1F0h] [rbp-100h] BYREF
char s[60]; // [rsp+220h] [rbp-D0h] BYREF
unsigned int v10; // [rsp+25Ch] [rbp-94h]
char *v11; // [rsp+260h] [rbp-90h]
int v12; // [rsp+26Ch] [rbp-84h]
bool v13; // [rsp+272h] [rbp-7Eh]
unsigned __int8 v14; // [rsp+273h] [rbp-7Dh]
int v15; // [rsp+274h] [rbp-7Ch]
char *v16; // [rsp+278h] [rbp-78h]
int v17; // [rsp+284h] [rbp-6Ch]
int v18; // [rsp+288h] [rbp-68h]
bool v19; // [rsp+28Fh] [rbp-61h]
char *v20; // [rsp+290h] [rbp-60h]
int v21; // [rsp+298h] [rbp-58h]
bool v22; // [rsp+29Fh] [rbp-51h]
__int64 v23; // [rsp+2A0h] [rbp-50h]
bool v24; // [rsp+2AFh] [rbp-41h]
__int64 v25; // [rsp+2B0h] [rbp-40h]
__int64 v26; // [rsp+2B8h] [rbp-38h]
__int64 v27; // [rsp+2C0h] [rbp-30h]
__int64 v28; // [rsp+2C8h] [rbp-28h]
int v29; // [rsp+2D0h] [rbp-20h]
int v30; // [rsp+2D4h] [rbp-1Ch]
char *v31; // [rsp+2D8h] [rbp-18h]
int v32; // [rsp+2E0h] [rbp-10h]
int v33; // [rsp+2E4h] [rbp-Ch]
bool v34; // [rsp+2EBh] [rbp-5h]
v10 = 0;
memset(s, 0, 0x30uLL);
memset(s1, 0, sizeof(s1));
printf("Input:");
v11 = s;
__isoc99_scanf("%s", v11);
v6 = 0;
//输入部分,碰到\n截止
while ( 1 )
{
v12 = v6;
v13 = v12 < 64;
if ( !v13 )
break;
v14 = s[v6];
v15 = v14;
if ( v15 == 10 )
{
v16 = &s[v6];
*v16 = 0;
break;
}
v17 = v6 + 1;
v6 = v17;
}
for ( i = 0; ; ++i )
{
v18 = i;
v19 = v18 < 6;//这里可以看出只有6组
if ( !v19 )
break;
v20 = s;
v4 = *(_QWORD *)&v20[8 * i];//转为了QWORD,每组八个字节
v7 = 0;
while ( 1 )
{
v21 = v7;
v22 = v21 < 64;
if ( !v22 )
break;
v23 = v4;
v24 = v4 < 0;
if ( v4 >= 0 )
{
v27 = v4;
v28 = 2 * v27;
v4 = v28;
}
else
{
v25 = 2 * v4;
v26 = v25;
v4 = v26 ^ 0xB0004B7679FA26B3LL;
}
v29 = v7;
v7 = v29 + 1;
}
v30 = 8 * i;
v31 = &s1[8 * i];
*(_QWORD *)v31 = v4;
v32 = i + 1;
}
v33 = memcmp(s1, &unk_402170, 0x30uLL);
v34 = v33 != 0;
if ( v34 )
puts("Wrong!");
else
puts("Correct!");
return v10;
}
其实最后看来也就是将输入的字符串分为6组,每组八个字节。然后作为long long 类型进行64次变换。
主要变换逻辑如下
if ( v4 >= 0 )
{
v27 = v4;
v28 = 2 * v27;
v4 = v28;
}
else
{
v25 = 2 * v4;
v26 = v25;
v4 = v26 ^ 0xB0004B7679FA26B3LL;
}
如果大于0则直接*2,否则再异或一个0xB0004B7679FA26B3LL。
然后最后跟unk_402170做一个memcmp,那么就已知结果逆向输入了。主要我们需要怎么判断它是否>0呢,其实很简单,我们可以看到如果>0就单纯*2了,否则还会异或一个奇数,那么就从最低位的奇偶入手,如果是偶数则/2,如果不是那么就先异或再/2就好了。但是需要注意,负数/2并不能单纯右移一位,还要再高位添1才能保证是负数/2。
exp
据此写出脚本
#include<stdio.h>
unsigned char s[] =
{
0x96, 0x62, 0x53, 0x43, 0x6D, 0xF2, 0x8F, 0xBC,
0x16, 0xEE, 0x30, 0x05, 0x78, 0x00, 0x01, 0x52,
0xEC, 0x08, 0x5F, 0x93, 0xEA, 0xB5, 0xC0, 0x4D,
0x50, 0xF4, 0x53, 0xD8, 0xAF, 0x90, 0x2B, 0x34,
0x81, 0x36, 0x2C, 0xAA, 0xBC, 0x0E, 0x25, 0x8B,
0xE4, 0x8A, 0xC6, 0xA2, 0x81, 0x9F, 0x75, 0x55,
};
unsigned long long key=0xB0004B7679FA26B3uLL;
int main(){
unsigned long long *p=(unsigned long long *)s;
int iter=0;
while(iter<6){
unsigned long long k=*p;
for(int i=0;i<64;i++){
if(k%2){
k^=key;
k/=2;
k |= 0x8000000000000000;
}
else{
k/=2;
}
}
for(int j=0;j<8;j++){
write(1,((char *)& k)+j,1);
}
p++;
iter++;
}
}
get flag
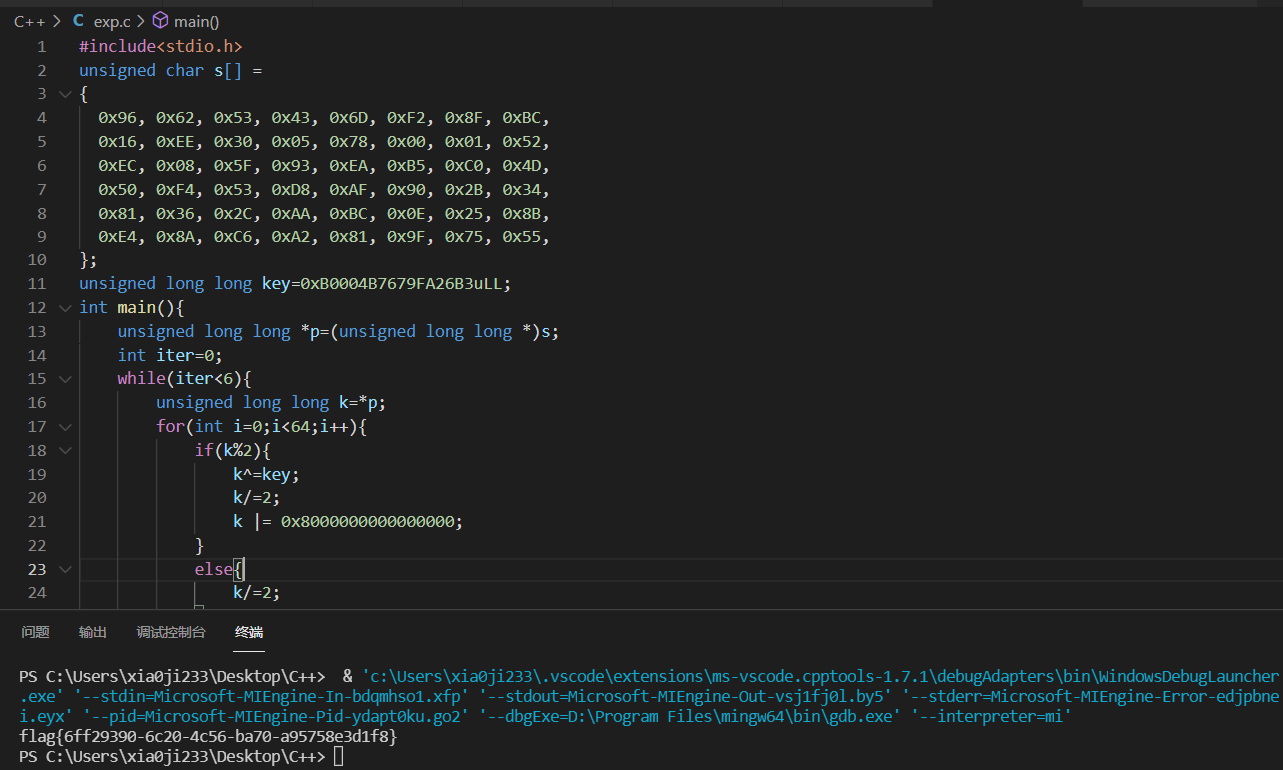
flag:flag{6ff29390-6c20-4c56-ba70-a95758e3d1f8}

 [复制链接]
[复制链接]
 发表于 2021-12-15 20:34
发表于 2021-12-15 20:34
 |
发表于 2021-12-17 19:55
|
发表于 2021-12-17 19:55



