(本帖翻译自r0da的博客)[https://whereisr0da.github.io/blog/posts/2021-01-26-vmp-2/]
序
嗨
这是我对VMP变异引擎的简短研究。
VMP是一款非常有名的加壳保护软件,它具有很多功能,其中一个核心功能是虚拟化引擎。这款引擎很优秀,尽管精英破解者说它没有达到Themida的水平。破解vmp虚拟机引擎是耗时的,我们目前不会花费精力在这上面。但是VMP的另外一个功能是我非常感兴趣的,那就是代码变异引擎。它基本上是一种改变代码形式的方法,而不改变代码的运行结果。
注意 : 我使用的是VMProtect 3.5 Demo Version版本做的测试
介绍
首先,你需要标记你想让VMP进行变异的函数。一种方式是在代码中调用VMProtectBeginMutation,或者使用VMP软件手动指定函数地址,或者通过pdb符号文件指定。如果没有进行任何函数标记,而只是应用了虚拟化保护,那么这样加壳是没有用的,现实中确实存在这样一些软件。
为了学习代码变异,我生成了一个模板函数,然后把这个函数变异了20次。
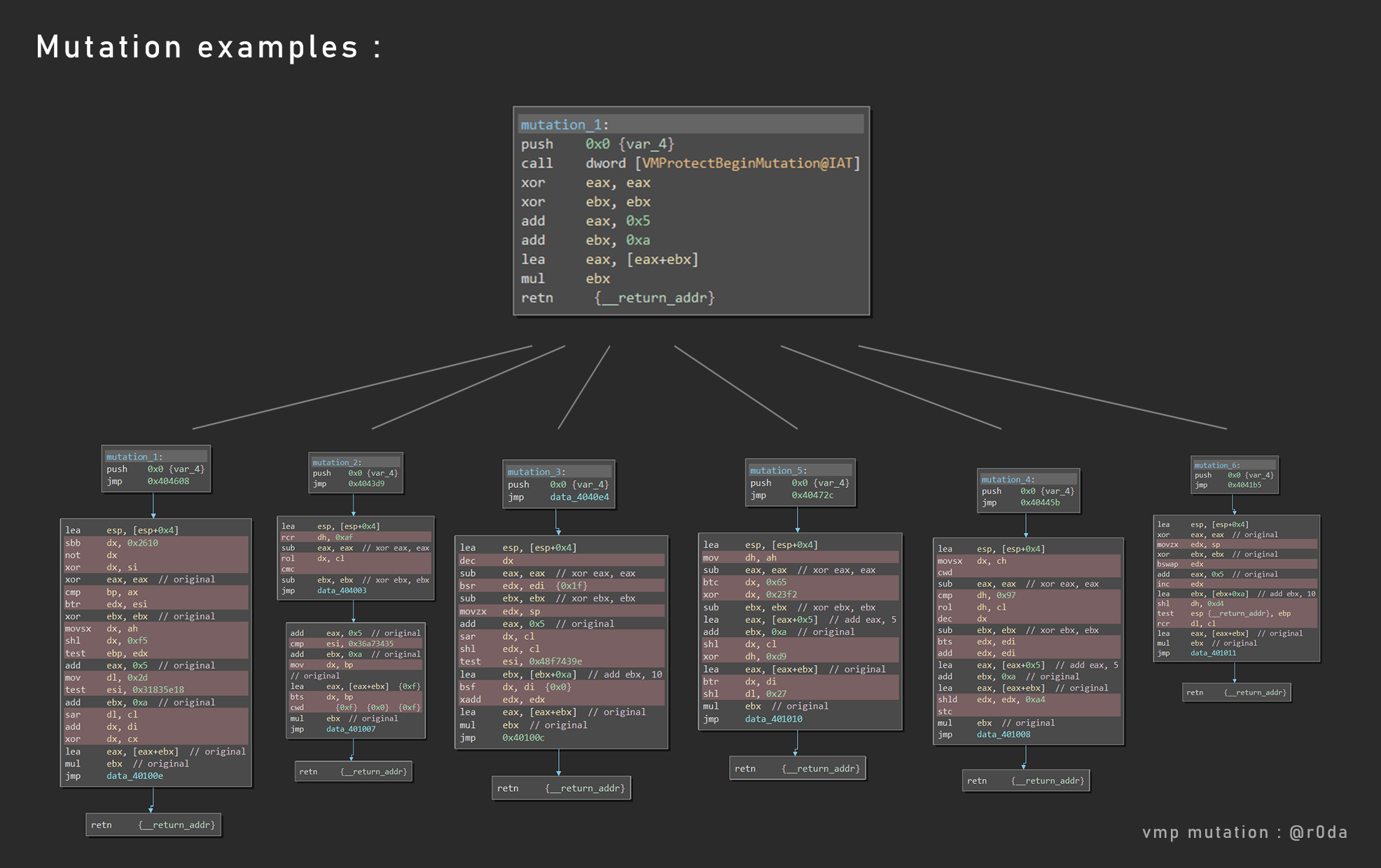
每一个代码节区中的变异函数都会跳转到一个vmp节区,这个节区包含了将要执行的下一个代码。因为在不破坏整个代码结构的情况下,修改(插入)由编译器生成的原始代码是不可能的。因此VMP将所有被变异的函数存储了到一个新的节区,用来避免空间大小问题。详情请参考在PE中插入代码
VMP 变异是许多技巧的组合,如代码变异,垃圾代码,控制流和非对其代码块等。
垃圾代码和变异
当我开始研究它时,我十分惊讶地发现vmp并不是变异全部的原始指令。原始的指令仅仅只被变异了1/2。这是根据我的观察所得到的,当然也有可能是错误的结论。
然而,这并不算是一件坏事。VMP对于代码优化的研究是非常出名的。如果他真的实际只做了1/2的代码变异,那么一定是有原因的。
总之,当你比较变异函数之间的差别时,你会发现主要的区别在于垃圾代码的插入。
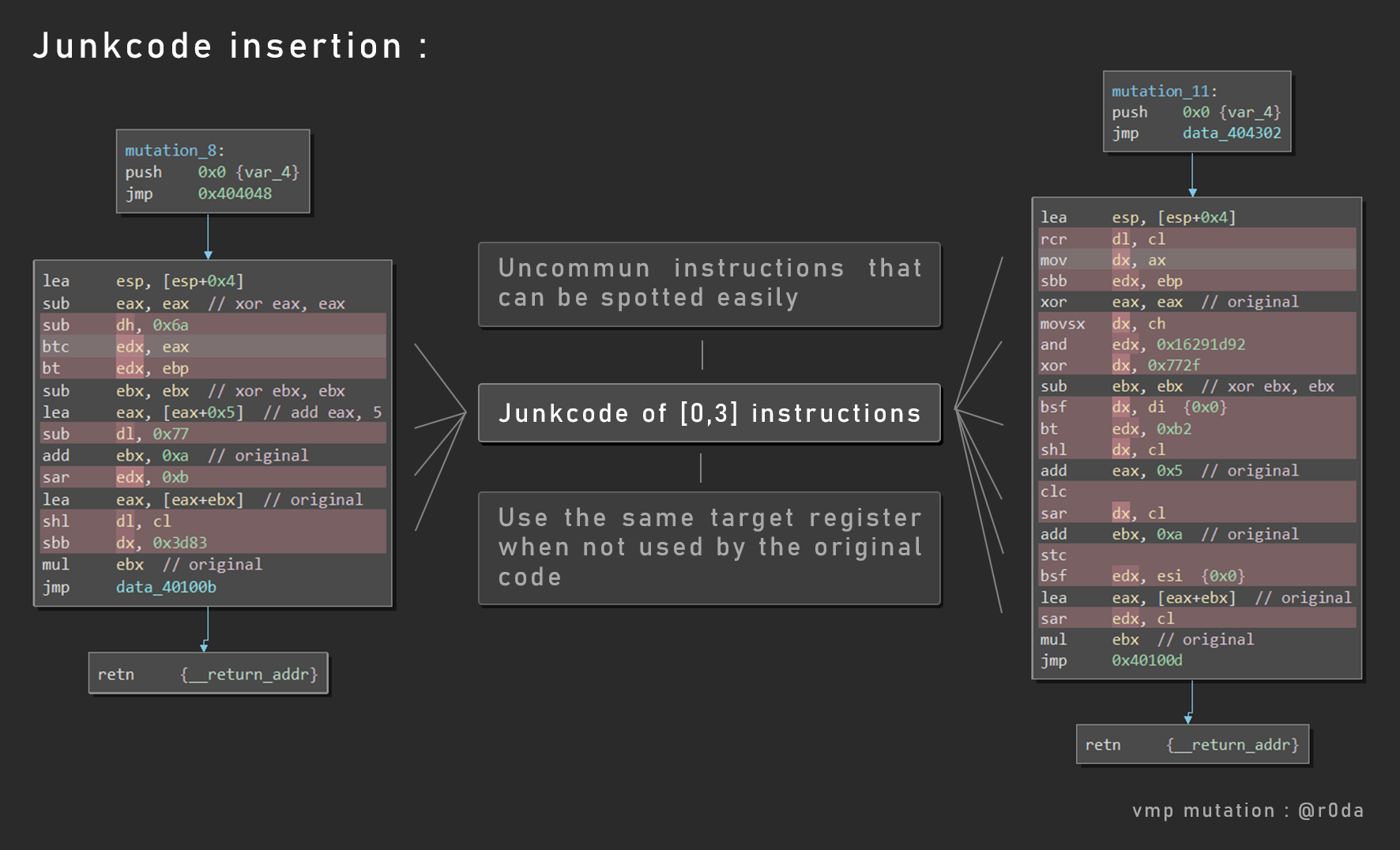
你可以看到红色的垃圾代码,它被插入到每个原始或者变异后的指令之后。通常每次插入的垃圾代码数量在0到3之间。你常常可以发现原始指令后面的垃圾指令使用完一个寄存器后,该寄存器的运算结果又被下一条原始指令运算的结果给覆盖了。
此外,你可以发现,垃圾代码生成器所使用的指令都是不常见的指令,你可以一眼就识别出来。比如说 rcr,bt,btc,sbb,lahf等。
下面是VMProtect生成垃圾代码时使用的最多的指令。
["cwd","stc","rcl","cdq",
"setb","nop","cmovge","setae",
"sete","rdtsc","cmovs","sbb",
"setl","setno","cmovo","setbe",
"cmovl","cmovae","btc","cwde",
"cdq","cmovg","seta","cmovnp",
"shld","cmova","cmovp","shrd",
"bsf","clc","cbw","rcr",
"btr","stc","adc","cmc",
"cmovle","bt","bts","bsr",
"setge"]
也有一些纯粹的垃圾指令被插入。如mov,xchg,cmp对同一寄存器的操作;nops;在一个寄存器上运算后,紧接着又被真正的指令重新设置。关于eflags的影响,我们可以看见一些使用两次cmp或者test的垃圾指令。
关于原始指令的变异,我们可以观察到一些围绕着lea指令做变化的操作。如 mov eax,ebx到lea eax,[ebx];add eax,3到lea eax,[eax+3]或者sub eax,5到lea eax,[eax-4]。还有像xor eax,eax翻译为sub eax,eax或者mov eax,0。可以看出,其垃圾代码的插入能力比较强。
控制流
VMP使用了控制流保护技术。VMP保护的重心在于跨越了所有基本代码块的跳转指令,而不是条件性跳转指令,所以即使在变异后,依然可以分析出原始的控制流。
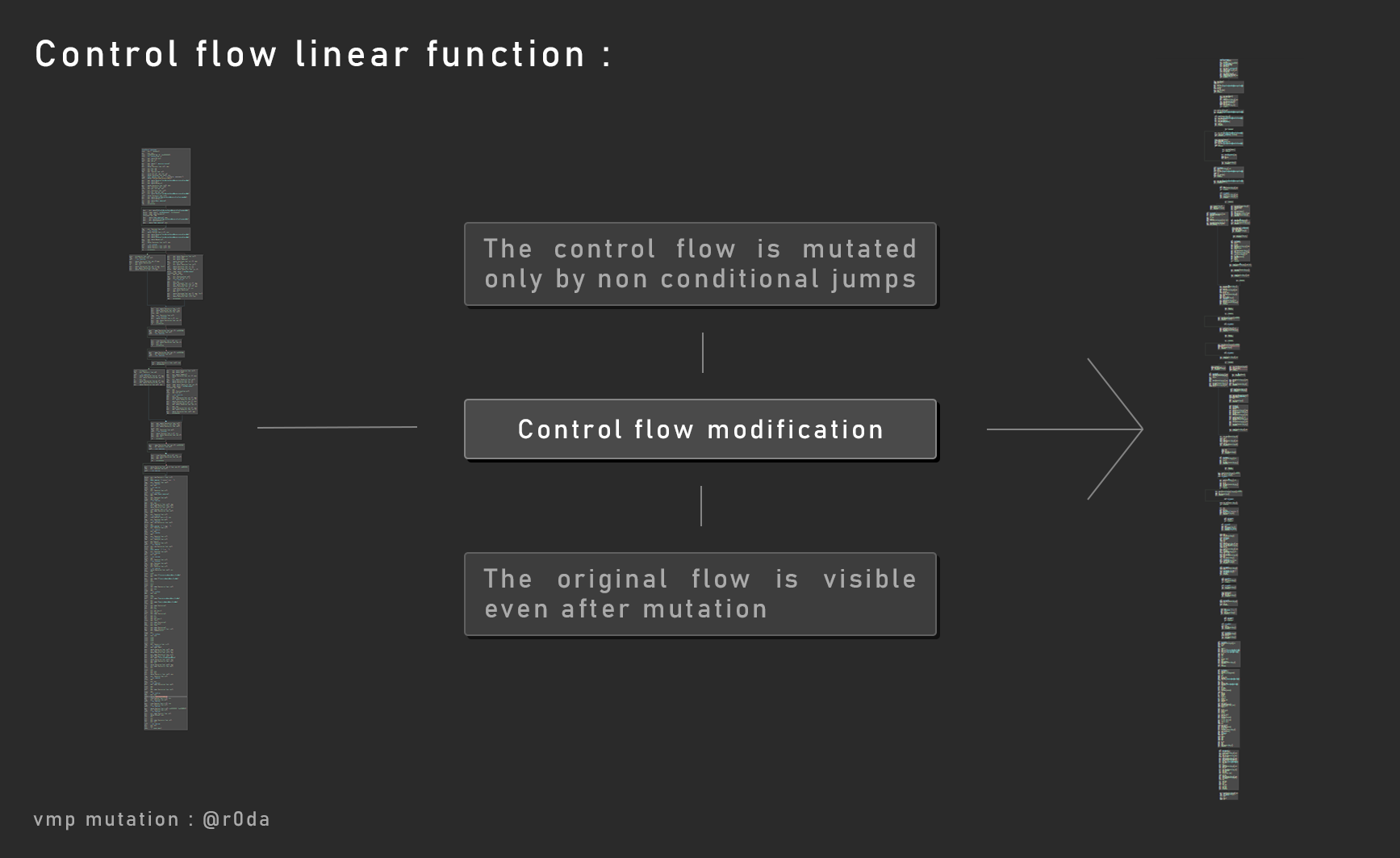
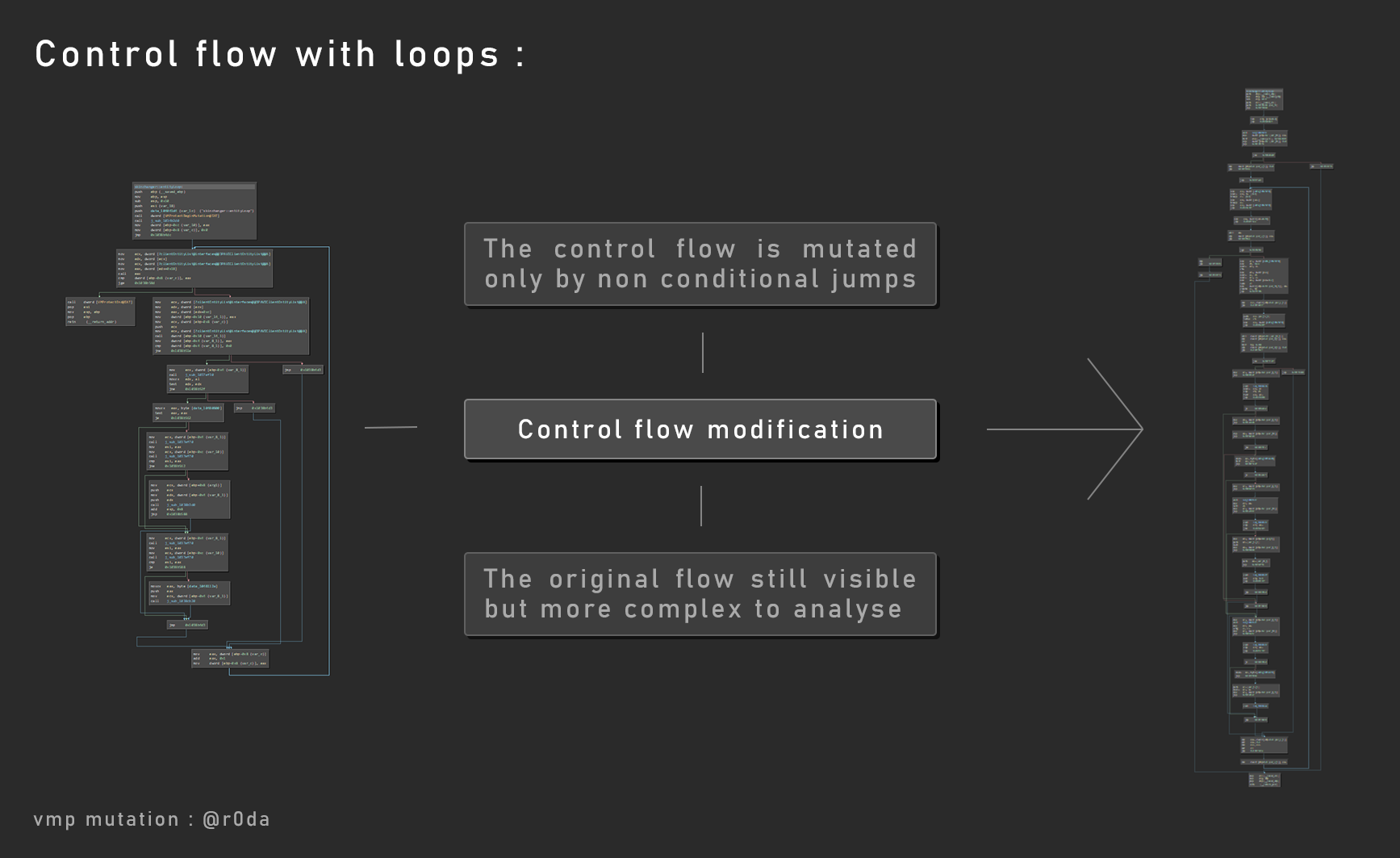
代码块定位
关于控制流,每个基本块(代码块)都是以某种方式放置的,目的是欺骗逆向人员。
函数拆分
让我们用一个代码节区来说明,下面是一些深灰色的代码节区。
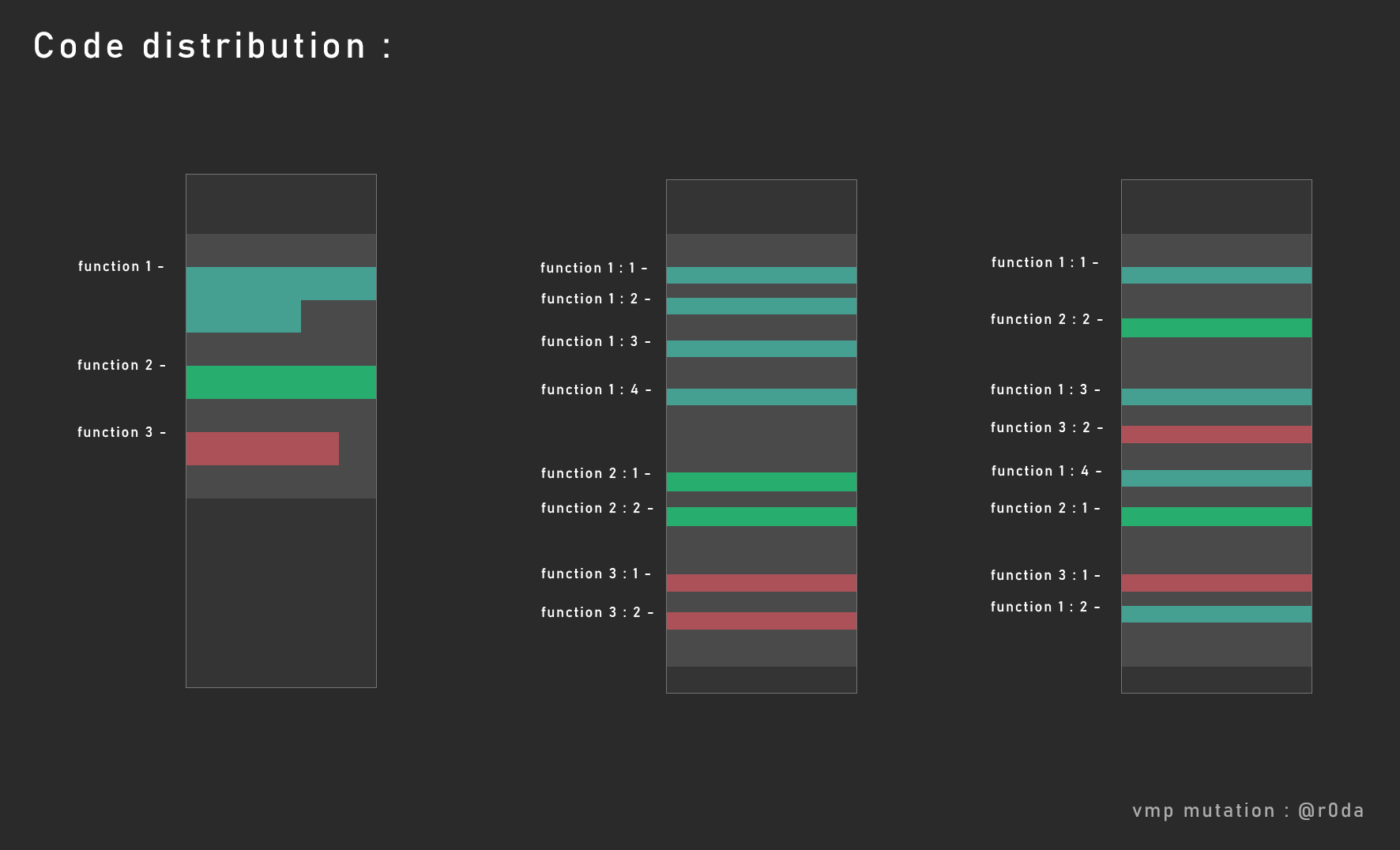
正如你在第一部分所看到的,这些指令被作为函数包含在一个块中。浅灰色的部分是代码节区中函数之间的填充指令。nop指令或者0xcc int3指令。这些填充指令是编译器生成出来做函数对齐的。
非对齐代码块
除了函数分割以外,VMP还在代码之间使用随机大小的填充指令。下面有一个由编译器生成的对齐代码片段。
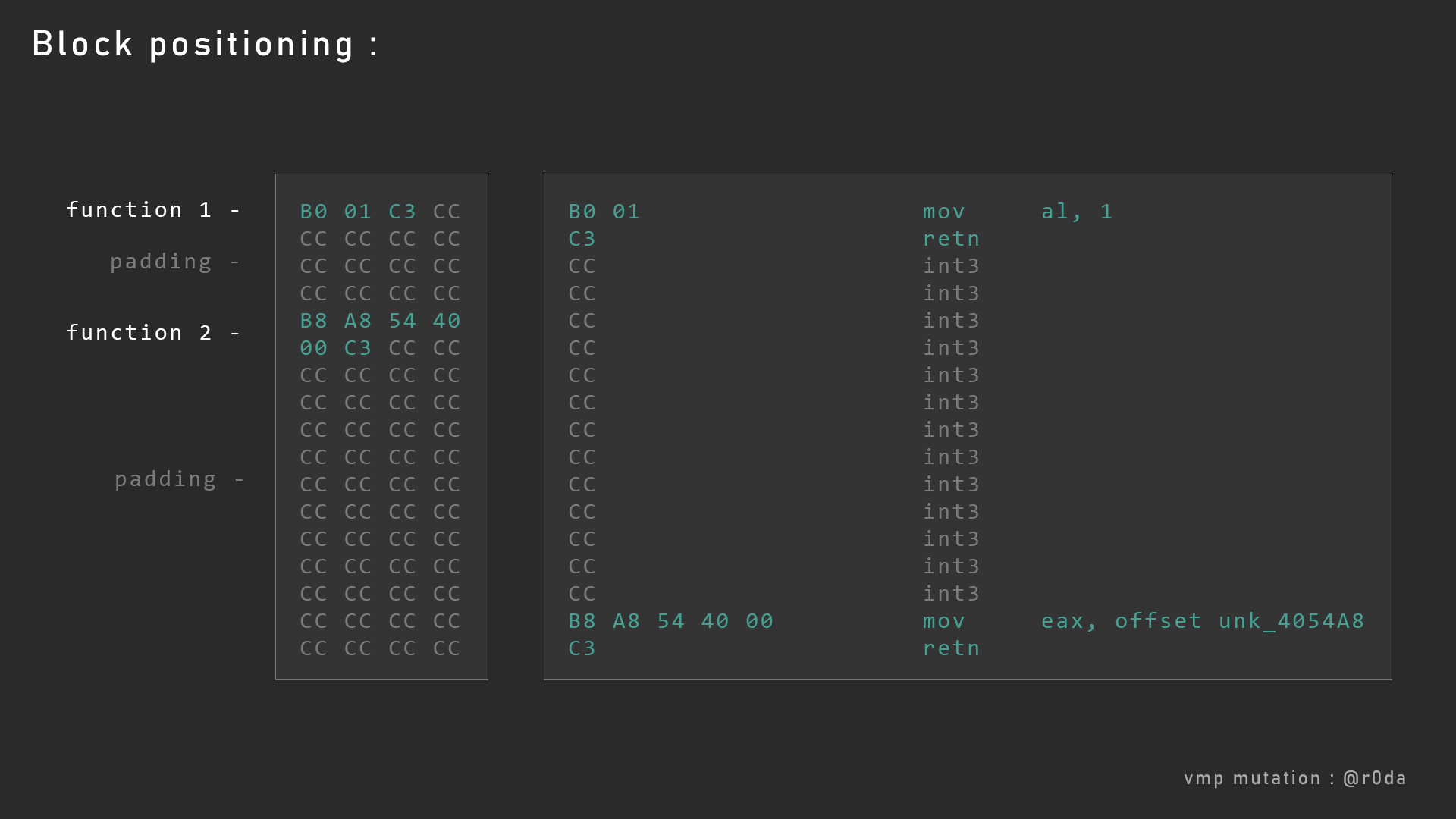
正如你所看到的,第一条绿色的指令后面跟着1字节的指令0xCC。如果被执行了的话,将会产生一个调试事件。
这种情况时不应该发生的,这些填充数据是为了保证了会被执行的代码是对齐的。
接下来,让我们看看VMP变异代码的排列情况。
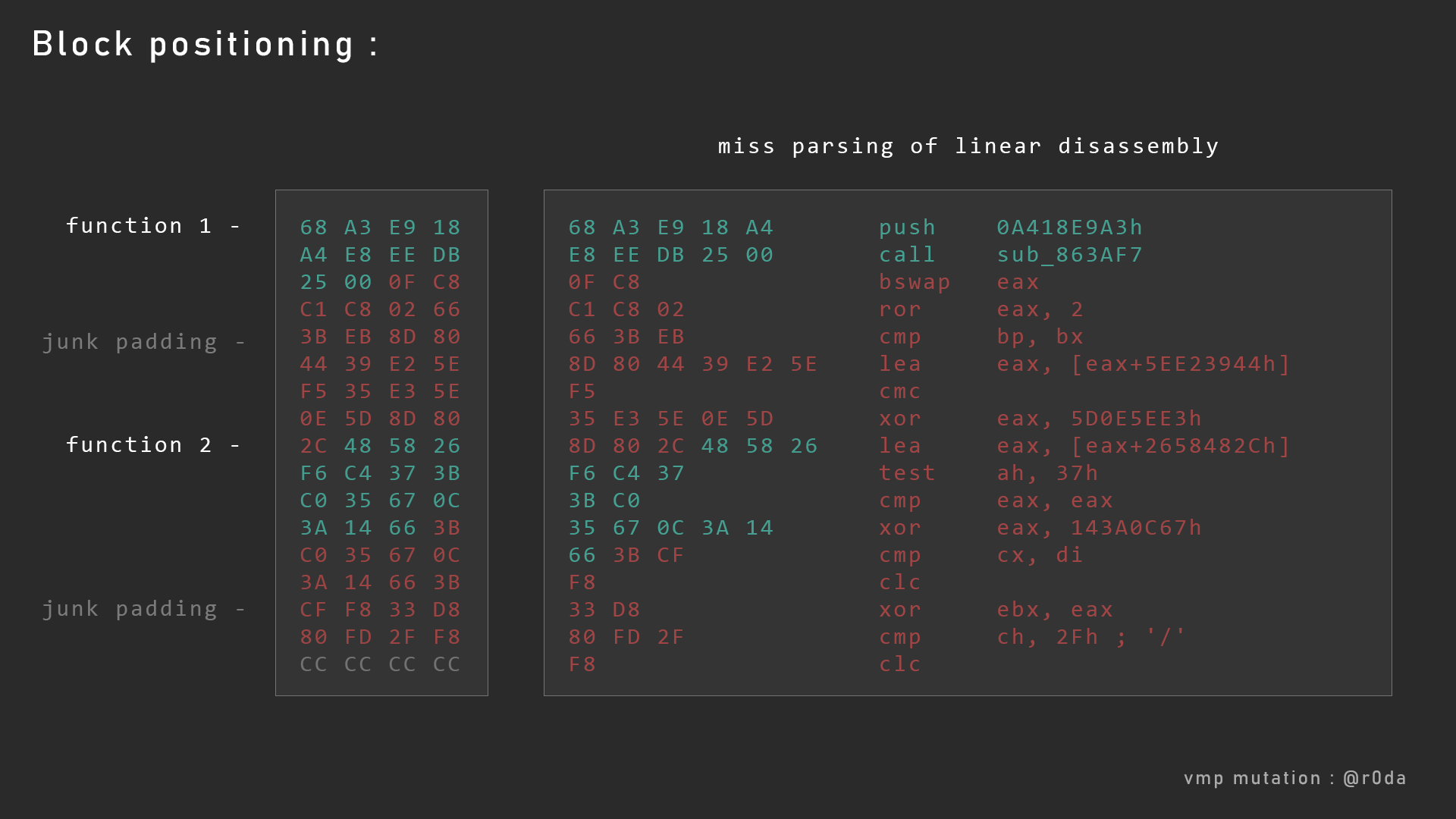
在这里,第一段绿的代码被执行,但在某些时候,他会跳到代码的某个地方(第二个绿色的部分), 但我们不知道跳到哪里。所以call sub_853AF7后面的那条指令永远不会被执行,但是反汇编引擎并不知道这一点。它还是把后面的指令给反汇编了。这就是vmp用来愚弄反汇编引擎所填充的随机数据。正如你所看到的红色代码,它完全是错误反汇编结果。
下面的才是正确的反汇编结果:
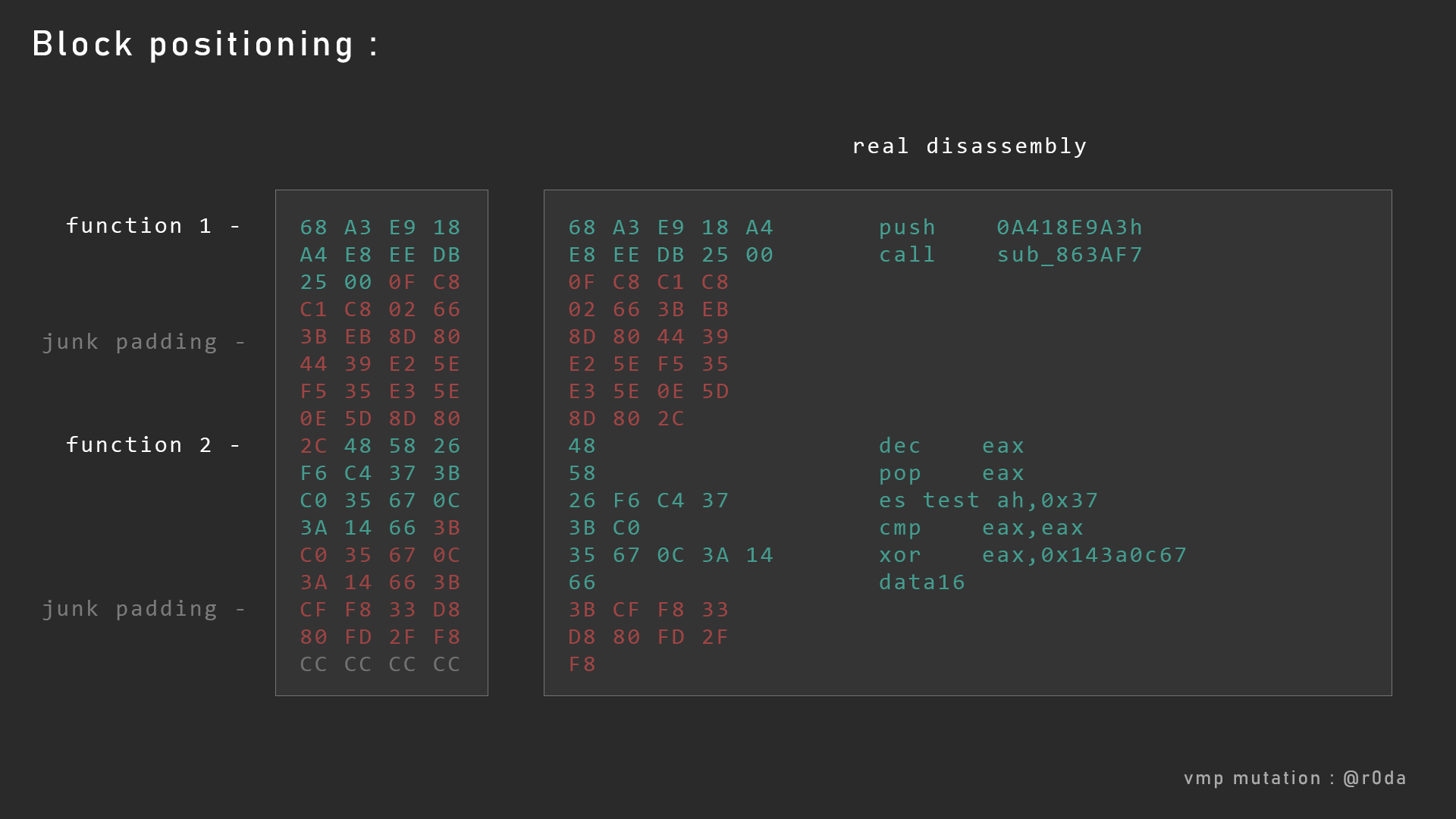
但是我们针对这种情况,我们只能通过运行程序,然后追踪程序的执行流程然后才能标记所有的执行块。
具体的例子
这里有一个C++函数。我们可以注意到,变异的重心是控制流,但是代码的可阅读性还是有的。垃圾指令使用的寄存器将被下一条真实指令改写,所以程序的运行结果不会被破坏。
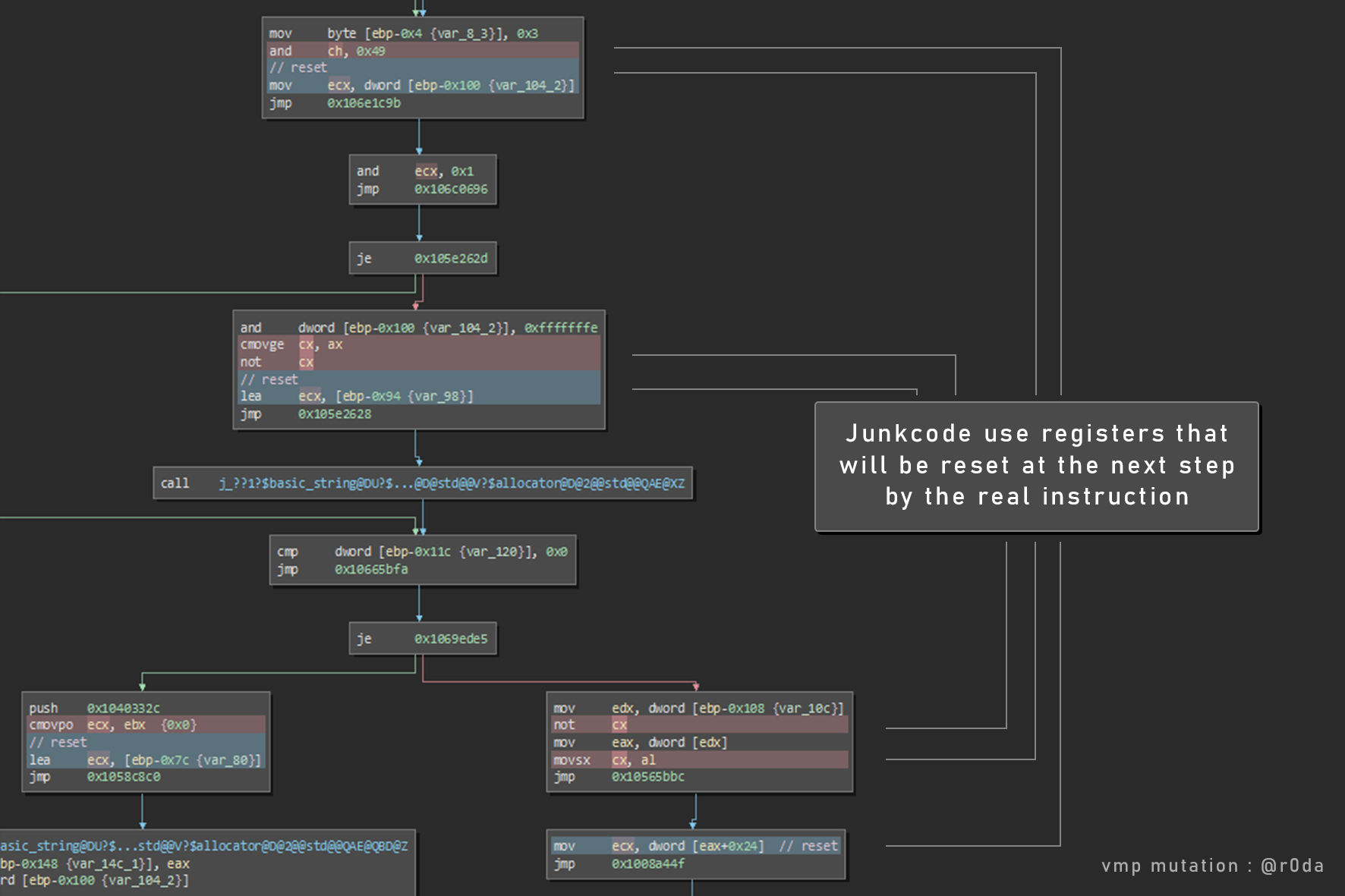
如何消除垃圾代码?
如果你想移除他,首先你可以编写一个工具,移除的规则是该指令在操作寄存器后的运算结果又被下一条指令给改写了。删除无用的指令还包括对同一寄存器的movs、cmps运算以及之前提到的其他指令。另一种思路是移除不常见的指令,但是如果程序真的用到了这些指令,那么这种操作是十分危险的。最后一种方法是使用数据追踪或者污点流分析,通过追踪寄存器及其数据行为,我们能够定义出什么是垃圾代码。也可以使用符合模拟,比如说miasm或者triton等框架来删除无效指令。具体的例子请参考这个链接(https://www.sstic.org/2014/presentation/Tutorial_miasm/)
结论
VMP的保护令人印象深刻。他的变异引擎使得逆向工作和去虚拟化过程变得更加艰难。即使我们可以发现其中的垃圾代码。在编译器高性能优化的情况下,垃圾指令可能很难从真正的代码中分离除了。在VMP的超级模式中,即变异+虚拟同时保护的情况下,对opcode进行去虚拟化也是一件非常痛苦的事情。
似乎使用代码签名是最有效的方法。如果你想让你的代码不被添加任何无用的垃圾代码。我个人会使用代码签名来绕过一下反作弊签名验证。但是你可用来干点其他猥琐的事情。
VMP未来发展方向:
在虚拟化后的VMP函数例程中,我认为他将来会使用更多的传统指令和普通寄存器。不然的话,逆向人员很容易发现他的垃圾代码,而且到后面VMP可能做出根据代码上下文去感知所使用的寄存器的操作数大小,然后使用同样操作数大小的代码流进行混淆,而不是从eax切换到al,然后又返回到ax的垃圾指令。

 发表于 2021-12-21 17:37
发表于 2021-12-21 17:37



