本帖最后由 MyModHeaven 于 2022-4-2 10:27 编辑
考计算机二级,我准备的 python 科目,在学校图书馆我找到了这本书:《高教版 Python 语言程序设计冲刺试卷(含线上题库)》(第 3 版),ISBN:978-7-04-053636-2。虽然这本书是2020年出版的,但python考试大纲变化不大,我又想白嫖,,,。激活码还没被用过,我给用了,得到了线上题库。其实线上题库就是书中的内容,只是在 python123 的网站上可以做而已。
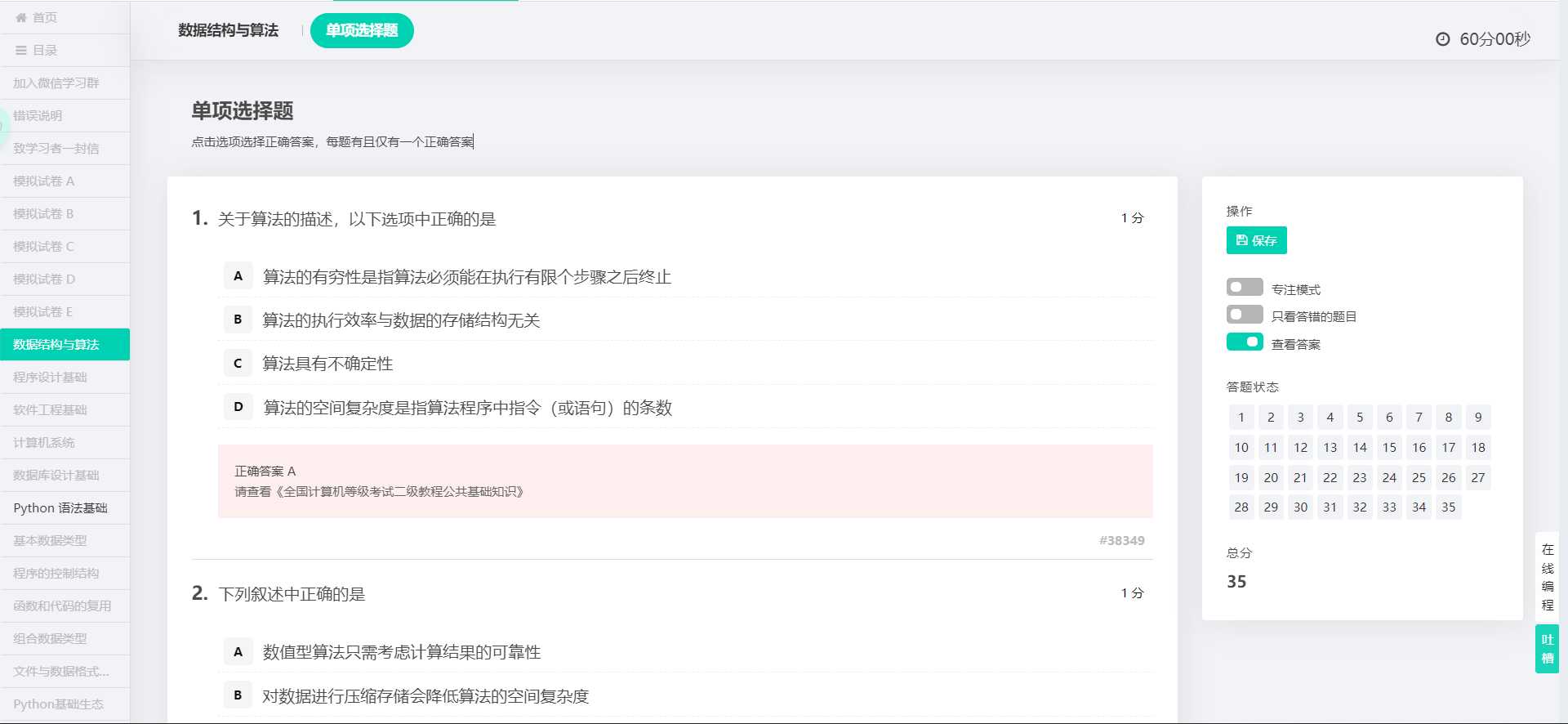
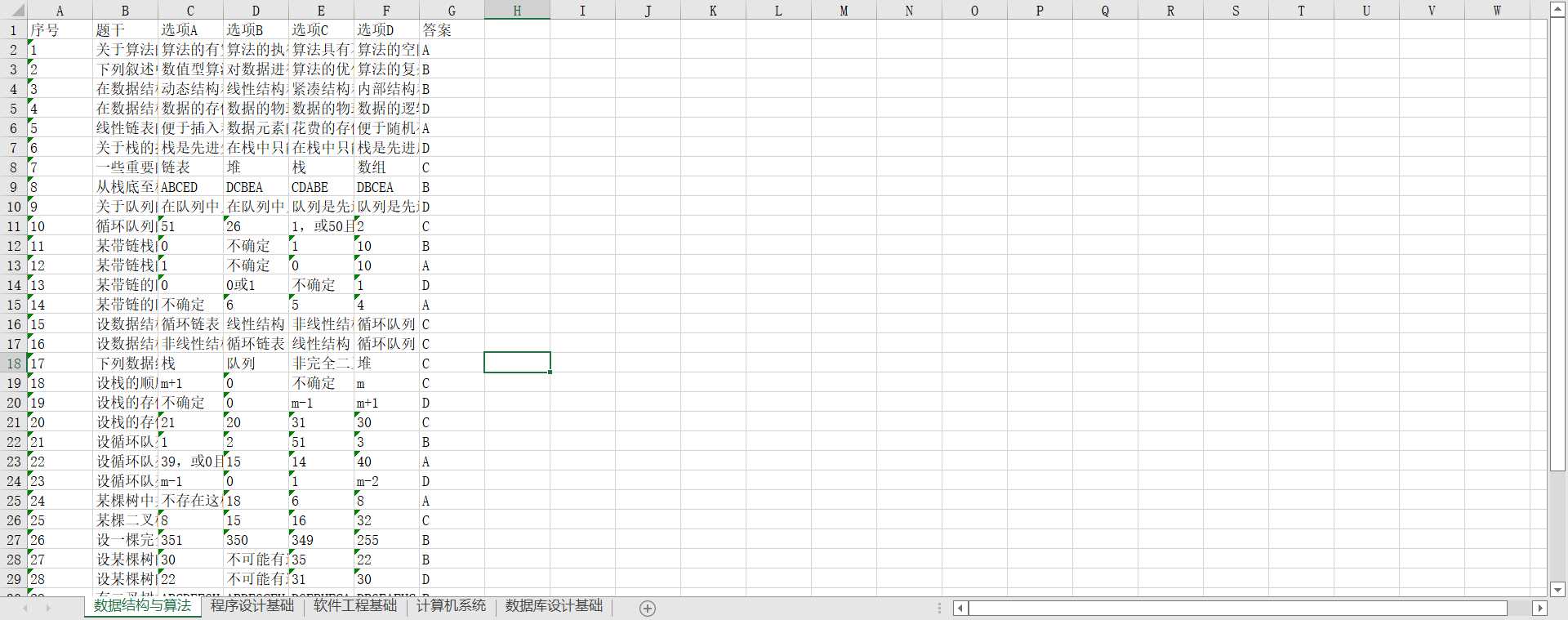
今天我把里面的选择题题库爬下来了,来分享一下。选择题包括公共基础知识和python单选题,公共基础知识又包括计算机系统、数据结构与算法、程序设计基础、软件工程基础和数据库设计基础,python单选题库包括python语法基础、基本数据类型、程序的控制结构、函数和代码复用、组合数据类型、文件和数据格式化、python基础生态和python计算生态。
因为没账号在 python123 上看不到题库,所以我把程序源码和爬下来的题都发一下
from selenium import webdriver
from selenium.webdriver.common.by import By
import xlsxwriter
browser = webdriver.Chrome()
browser.maximize_window()
browser.get('https://python123.io/index/login')
'''
# 扫码登陆
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser.find_element(By.XPATH, '//button[@class="button is-primary is-outlined is-fullwidth"]/i').click()
WebDriverWait(browser, 30).until(EC.text_to_be_present_in_element((By.CLASS_NAME, 'is-text-small'), '我的主页'))
'''
# cookie 登录
browser.delete_all_cookies()
browser.add_cookie({})
browser.get('https://python123.io/student/series/12/')
browser.implicitly_wait(5)
catalogs = browser.find_elements(By.XPATH, '//div[@class="catalog"]')[1:]
d = {}
for catalog in catalogs:
catalog_head = catalog.find_element(By.CLASS_NAME, 'heading').text
node_a = catalog.find_elements(By.XPATH, './div/a')
items = []
for a in node_a:
name = a.find_element(By.XPATH, './/div[@class="media-content"]/b').text
url = a.get_attribute('href')
items.append((name, url))
d[catalog_head] = items
def c_pool(part):
# 爬取选择题题库
wb = xlsxwriter.Workbook('d:/{}.xlsx'.format(part))
global d
for item in d[part]:
ws = wb.add_worksheet(item[0])
d = {'A1': '序号', 'B1': '题干', 'C1': '选项A', 'D1': '选项B', 'E1': '选项C', 'F1': '选项D', 'G1': '答案'}
for l in d:
ws.write(l, d[l])
n = 2
browser.get(item[1]+'/choices')
browser.find_element(By.XPATH, '//div[@class="column is-3"]/div/div/div/div[4]').click()
node_div = browser.find_elements(By.XPATH, '//div[@class="column is-9"]/div/div/div')
for div in node_div:
index = div.find_element(By.CLASS_NAME, 'problem-index').text
body = div.find_element(By.CLASS_NAME, 'mce-content-body').text
options = div.find_elements(By.XPATH, './/div[@class="options is-clickable"]/div/div')
options = [i.text for i in options]
answer = div.find_element(By.XPATH, './div[2]/div[2]/span[4]').text
content = [index, body, *options, answer]
for i in range(7):
ws.write('ABCDEFG'[i]+str(n), content[i])
n += 1
wb.close()
c_pool('公共基础知识题库')
c_pool('PYTHON 单选题库')
https://wwp.lanzouy.com/b01jb6omj[/color]
密码:fnok
虽然就这一点东西,但也花了一天的时间,从昨天晚上到今天下午。中间碰到两个实在解决不了的问题,也通过吾爱得到了答案,事后来看,真的不是什么问题。
-
用了两个第三方库:selenium 和 xlsxwriter,selenium 用来爬取网页的内容,xlsxwriter 用来把内容写入到excel文件里
-
一开始写的是扫码登陆,但是在调试过程中发现太麻烦,每次都要登录,所以尝试用cookie登录。这是第一次用,不知道怎么弄,光知道是个字典。就 F12 找cookie,虽然找到了,但是没用对,登录不上。后来就扫码登陆,然后得到cookie,再用cookie登录。将cookie写入本地txt文件后,发现有三个。百度之后,知道了cookie必须有的是 name 和 value, 即:cookie = {'name': '', 'value': ''},其他的可以没有。虽然不知道三个cookie有什么不同,但是一个一个试,试到第二个就成功登陆了
-
selenium 的显式等待也是前天刚弄会的,发现以前一直报错只是因为少了一对括号而已,大意了
-
最大的收获是学了一个语法糖,翻笔记发现我以前记过,只是忘了,看来笔记还是要常看
【python】如何优雅的把这3个字符串和一个列表放在一个列表里?


4.2 更新
这次我把简单编程题爬下来了,由于编程题的题干比选择题复杂,我用 selenium 登录上后,直接截图保存。绝大部分的题目都完全在截图内,个别的截不全也不影响做题。后面的简单应用题和复杂应用题就不能截图了(因为截不全,并且影响做题)
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
browser = webdriver.Chrome()
browser.maximize_window()
browser.get('https://python123.io/index/login')
# cookie 登录
browser.delete_all_cookies()
browser.add_cookie({})
browser.get('https://python123.io/student/series/12/modules/167/programmings')
browser.implicitly_wait(5)
i = 0
while i < 60:
titles = browser.find_elements(By.XPATH, '//div[@class="card-content programming-card"]')
node_b = titles[i].find_elements(By.XPATH, './/div[@class="media-content"]/b')
name = ''.join([name.text for name in node_b])
titles[i].click()
browser.implicitly_wait(1)
try:
browser.find_elements(By.XPATH, '//div[@class="card-content condense vertical-align has-border-bottom"]/div/a')[3].click()
except IndexError:
browser.find_elements(By.XPATH, '//div[@class="card-content condense vertical-align has-border-bottom"]/div/a')[2].click()
time.sleep(1)
browser.execute_script('window.scrollTo(0,120)')
browser.save_screenshot('D:\基本编程题\{}.png'.format(name))
browser.back()
i += 1

https://wwp.lanzouy.com/iZqBT02gm1yb | 
 发表于 2022-3-25 21:22
发表于 2022-3-25 21:22
 |
发表于 2022-3-25 21:44
|
发表于 2022-3-25 21:44





