本帖最后由 illuminate123 于 2022-10-13 09:47 编辑
)
效果还不错,爬了100000多个评论
本次用selenium关于selenium的下载及安装,这里不在讲述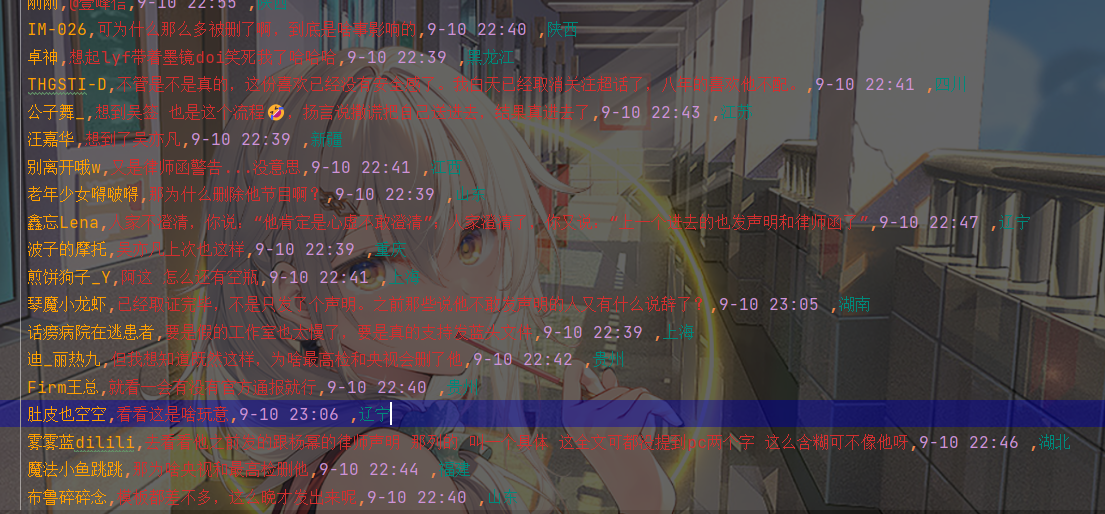
[Python] 纯文本查看 复制代码
# 说明本次使用的是手机版微博
# 地址为https://m.weibo.cn/
# 爬取评论的地址应该类型于https://m.weibo.cn/detail/4812281315337380
from selenium.webdriver.support.wait import WebDriverWait # 显示等待,登陆好了咱就爬取
from tqdm import tqdm
import csv
import time
from time import sleep
from fake_user_agent import user_agent
from selenium import webdriver
from selenium.webdriver.common.by import By
import numpy as np
with open("李易峰评论.csv", 'w') as f:
csv_writer = csv.writer(f)
csv_writer.writerow(["nick_name", "content", "time", 'location'])
us = user_agent()
headers = {
'user_agent': us
}
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_experimental_option('excludeSwitches', ['enable-automation'])
###
driver = webdriver.Chrome(options=chrome_options)
def scrape(url):
driver.get(url)
time.sleep(20) # 你先登录,再加上验证码最低也要20s吧,下滑界面5s左右就会让你登录
# 下面这个解释一下:等待20s继续等待,在等待30s,如果再次期间登录完毕就开始爬,每隔0.2s就检查一次
# 如果,我是说如果50s你都登录不好,那你确实废物,哈哈哈,开个玩笑,我才是废物
text = WebDriverWait(driver, 30, 0.2).until(
lambda x: x.find_element(By.XPATH, '//*[@id="app"]/div[1]/div/div[1]/div[2]/h4')).text
print(text)
print("请登录,下滑页面登录")
print("*" * 100)
for i in tqdm(range(100000), colour="yellow"):
driver.execute_script("window.scrollBy(0,100)")
nick_name = driver.find_elements(By.XPATH,
'//*[@id="app"]/div[1]/div/div[4]/div[2]/div/div/div/div/div/div[2]/div[1]/div/div/h4')
content = driver.find_elements(By.XPATH,
'//*[@id="app"]/div[1]/div/div[4]/div[2]/div/div/div/div/div/div[2]/div[1]/div/div/h3')
time_local = driver.find_elements(By.XPATH,
'//*[@id="app"]/div[1]/div/div[4]/div[2]/div/div/div/div/div/div[2]/div[2]/div')
for i, j, k in zip(nick_name, content, time_local):
with open("李易峰评论.csv", 'a', encoding="utf-8-sig", newline='') as f:
csv_writer = csv.writer(f)
csv_writer.writerow([i.text, j.text, k.text.split("来自")[0], k.text.split("来自")[1]])
# print(i.text, ":", j.text, ":", k.text.split("来自")[0], k.text.split("来自")[1])
time.sleep(abs(np.random.randn(1))[0] / 10)
driver.quit()
driver.close()
url = "https://m.weibo.cn/detail/4812281315337380" # 这里修改自己的url
scrape(url)
爬完总共大概有10000条吧
我写的代码,中间有问题,导致有大量重复数据,这个要等我晚上改一下(两个手机号都登录不了微博了,验证码接受次数上限了) | 
 [复制链接]
[复制链接]
 发表于 2022-10-12 22:57
发表于 2022-10-12 22:57
 |
发表于 2022-10-13 09:44
|
发表于 2022-10-13 09:44



