本帖最后由 甘霖之霜 于 2023-4-15 11:53 编辑
前言
前几天发一个帖子https://www.52pojie.cn/thread-1773549-1-1.html
各路大佬纷纷提出优化方案
其中@Ashtareve 给提出了并行流解决方案我实装一下 速度也是相当滴快(相比之前蜗牛速度)
决定把源码发出来
程序源码还是简单介绍一下把 思路
获取目录代码
先获取目录 根据目录到具体的页面爬取对应章节
参数说明 root 网站根路径(不是起始路径) next:下一页 dir:目录
[Java] 纯文本查看 复制代码 private static void getDir(String root,String next,List<String> dir) throws Exception {
Document document = Jsoup.connect(next).get();
Elements elements = document.select("a[href$=\".html\"]");
List<String> list = elements.eachAttr("href");
list.remove(0);
if (elements.last().text().equals("下一页")){
String nextPage = list.get(list.size() - 1);
nextPage = root + nextPage.substring(nextPage.lastIndexOf("/") + 1);
list.remove(list.size() - 1);
if (elements.get(elements.size() - 2).text().equals("上一页")){
list.remove(list.size() - 1);
}
dir.addAll(list);
getDir(root,nextPage,dir);
return;
}
if ((elements.last().text().equals("上一页"))){
list.remove(list.size() - 1);
}
dir.addAll(list);
}
单章节获取
参数说明 url该章节地址
[Java] 纯文本查看 复制代码 private static String getDetail(String url){
try {
Document document = Jsoup.connect(url).get();
String title = document.select("h1").text() + "\n";
System.out.println(title);
Elements content = document.select("div[id=\"content\"]");
String text = content.toString();
int i = text.indexOf("&");
if (i != -1){
text = text.substring(i);
}
text = text.replaceAll(" ","").replaceAll("<br><br>","").replaceAll("</div>","");
return title + text;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
使用stream并行流获取全部章节
此为 @Ashtareve 大佬提出的解决方法 还是很有必要说明一下 这种简单高效的处理方式深得我心
参数说明 dir 刚才获取的目录 root 同上 writer输出流用于保存本地
[Java] 纯文本查看 复制代码 private static void getContent(List<String> dir,String root, Writer writer) throws Exception {
List<String> list = dir.stream().parallel().map(url -> getDetail(root + url)).toList();
System.out.println("正在写入文件...");
IOUtils.writeLines(list,"\n",writer);
writer.close();
IOUtils.close();
}
程序依赖
[XML] 纯文本查看 复制代码 <dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.15.4</version>
</dependency>
​
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.11.0</version>
</dependency>
整体代码
[Java] 纯文本查看 复制代码 public class Demo {
public static void main(String[] args) throws Exception {
System.out.println("软件来自:吾爱破解 甘霖之霜");
Scanner input = new Scanner(System.in);
System.out.println("书籍搜索地址:https://www.bbiquge.net/");
System.out.print("请输入书籍编号:");
String s = input.next();
long begin = System.currentTimeMillis();
String url = String.format("https://www.bbiquge.net/book/%s/",s);
String fileName = Jsoup.connect(url).get().select("h1").text();
fileName = fileName.replace("/","") + ".txt";
File file = new File("D:\\" + fileName);
Writer writer =new FileWriter(file,true);
List<String> dir = new ArrayList<>();
System.out.println("正在获取目录中...");
getDir(url,url,dir);
System.out.println("正在获取章节内容...");
getContent(dir,url,writer);
System.out.println("下载完成,文件已保存至 D:\\" + fileName);
System.out.printf("花费时间%s秒",(System.currentTimeMillis() - begin) / 1000);
input.next();
}
private static void getDir(String root,String next,List<String> dir) throws Exception {
Document document = Jsoup.connect(next).get();
Elements elements = document.select("a[href$=\".html\"]");
List<String> list = elements.eachAttr("href");
list.remove(0);
if (elements.last().text().equals("下一页")){
String nextPage = list.get(list.size() - 1);
nextPage = root + nextPage.substring(nextPage.lastIndexOf("/") + 1);
list.remove(list.size() - 1);
if (elements.get(elements.size() - 2).text().equals("上一页")){
list.remove(list.size() - 1);
}
dir.addAll(list);
getDir(root,nextPage,dir);
return;
}
if ((elements.last().text().equals("上一页"))){
list.remove(list.size() - 1);
}
dir.addAll(list);
}
​
private static void getContent(List<String> dir,String root, Writer writer) throws Exception {
List<String> list = dir.stream().parallel().map(url -> getDetail(root + url)).toList();
System.out.println("正在写入文件...");
IOUtils.writeLines(list,"\n",writer);
writer.close();
IOUtils.close();
}
​
private static String getDetail(String url){
try {
Document document = Jsoup.connect(url).get();
String title = document.select("h1").text() + "\n";
System.out.println(title);
Elements content = document.select("div[id=\"content\"]");
String text = content.toString();
int i = text.indexOf("&");
if (i != -1){
text = text.substring(i);
}
text = text.replaceAll(" ","").replaceAll("<br><br>","").replaceAll("</div>","");
return title + text;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
使用方式
https://www.bbiquge.net去这个网站搜索点进详情 看地址栏
举个栗子
https://www.bbiquge.net/book/59265/ 其中59265 是书籍编号 输入即可
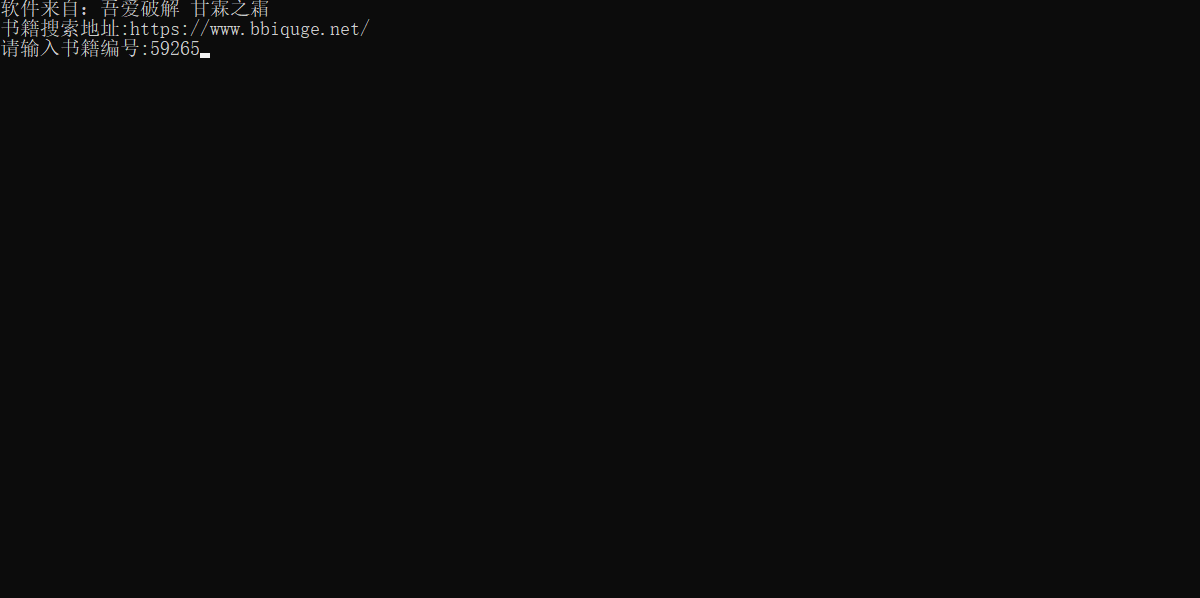
结果
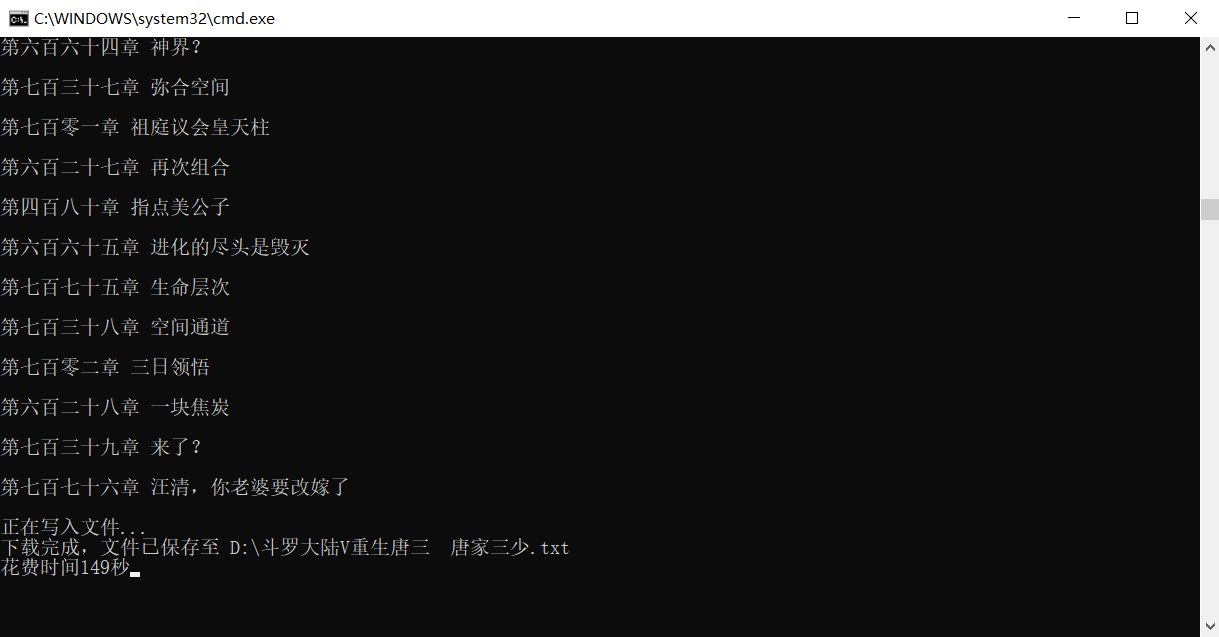
一千多章 速度我个人还挺满意(可能是之前的蜗牛速度)
下载地址:https://wwi.lanzoup.com/imQLI0t1amra | 
 [复制链接]
[复制链接]
 发表于 2023-4-15 10:34
发表于 2023-4-15 10:34
 |
发表于 2023-4-15 11:45
|
发表于 2023-4-15 11:45




