免责声明:仅供个人学习及研究使用,严禁用于其他用途。
需求分析
获取相对全局的招聘岗位信息,以及准备相关的欺诈防范、简历收集等资料。
相关发现问题及处理
一、直接读取json,打印出来的信息复制到vs code并不能成一个正确格式的json文件,但对其保存成json文件,是正常的,可以的。
二、招聘网站基本做了挺多的反爬处理,限制爬虫频率:
- 时间:限制时间通常在十几分钟至个把小时不等,爬两次易触发访问异常,三次基本上就在受限名单了,过于频繁会ban IP。
- 页码:最多只能爬3页,每一页最多30条数据。90条记录其实对于大多数人已经够用了。
- cookie:若发现终端粘贴cookie,不能回车,删除最后的键值对,即可。
部分要点说明
招聘条目API
https://www.zhipin.com/wapi/zpgeek/search/joblist.json?scene=1&query=IT%E6%8A%80%E6%9C%AF%E6%94%AF%E6%8C%81&city=101280600&experience=&payType=&partTime=°ree=&industry=&scale=&stage=&position=&jobType=&salary=&multiBusinessDistrict=&multiSubway=&page=1&pageSize=30
招聘条目web链接分析
https://www.zhipin.com/web/geek/job?query=IT%E6%8A%80%E6%9C%AF%E6%94%AF%E6%8C%81&city=101280600&experience=106&salary=405
参数分析
city=101280600 深圳
experience=105 3-5年
salary=405 10-20k
通过分析为utf-8编码
from urllib.parse import unquote
encoded_str = '%E6%8A%80%E6%9C%AF%E6%94%AF%E6%8C%81'
decoded_str = unquote(encoded_str, encoding='utf-8')
print(decoded_str)
城市代码
https://www.zhipin.com/wapi/zpCommon/data/cityGroup.json
code_value = city_json["zpData"]["cityGroup"][0]["cityList"][0]["code"]
# 假设您已经将 JSON 数据加载到了 city_json 字典中
user_city = input("请输入城市:") # 获取用户输入的城市名
city_code = None # 初始化城市编码为 None
# 遍历城市列表,查找与用户输入城市名匹配的城市信息
for group in city_json["zpData"]["cityGroup"]:
for city in group["cityList"]:
if city["name"] == user_city:
city_code = city["code"]
break
if city_code is not None:
print("匹配到的城市编码:", city_code)
else:
print("未找到匹配的城市编码")
api json拼接结构
具体结构树
[
{
"code": 0,
"message": "Success",
"zpData":{
"jobList": [
{
}
]
}
},
{
"code": 0,
"message": "Success",
"zpData":{
"jobList": [
{
}
]
}
}
]
循环取出
data_list = []
for item in zhipin_json:
if "zpData" in item and "jobList" in item["zpData"]:
data_list.extend(item["zpData"]["jobList"])
for job in data_list:
分析整合并输出
使用效果
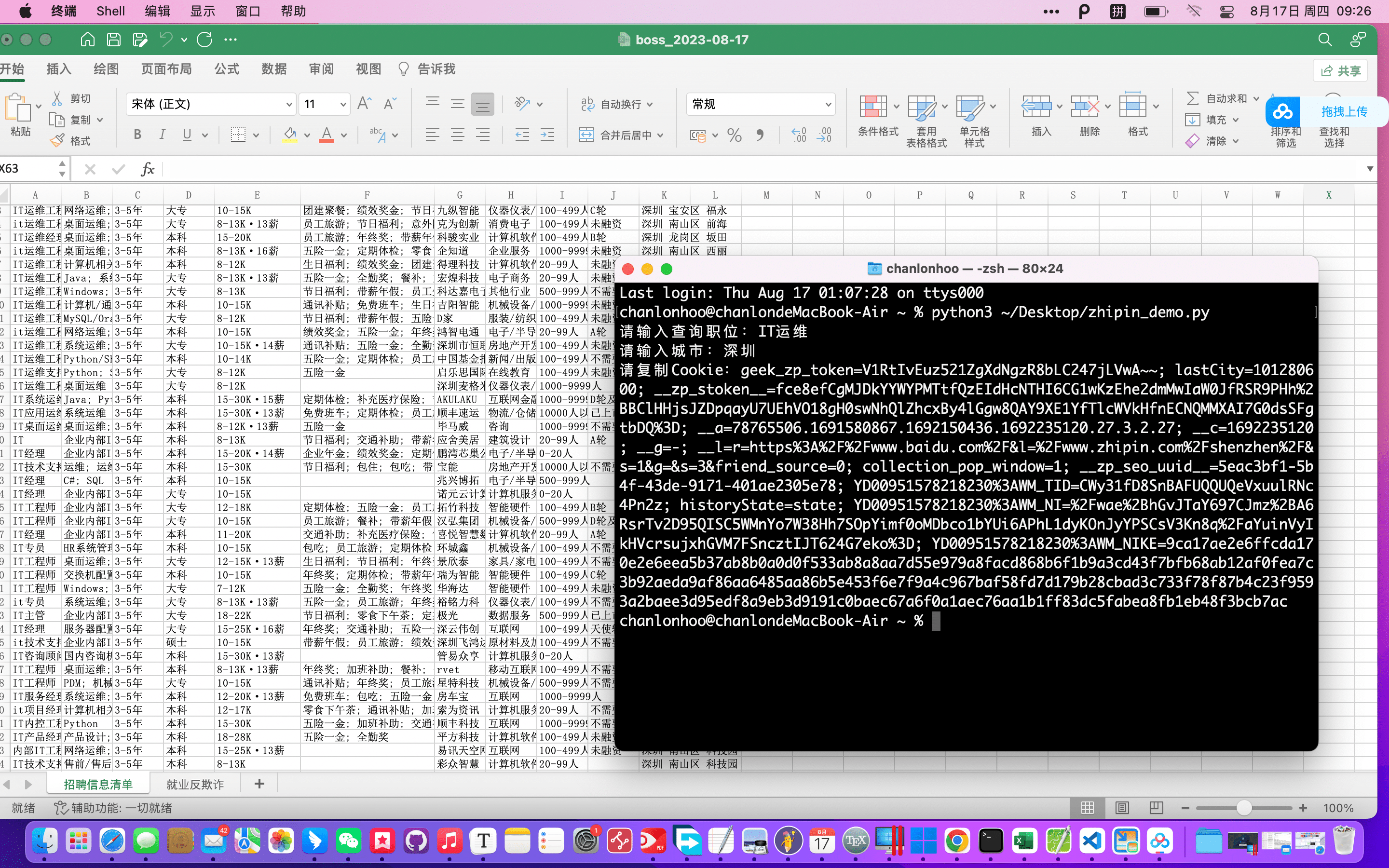
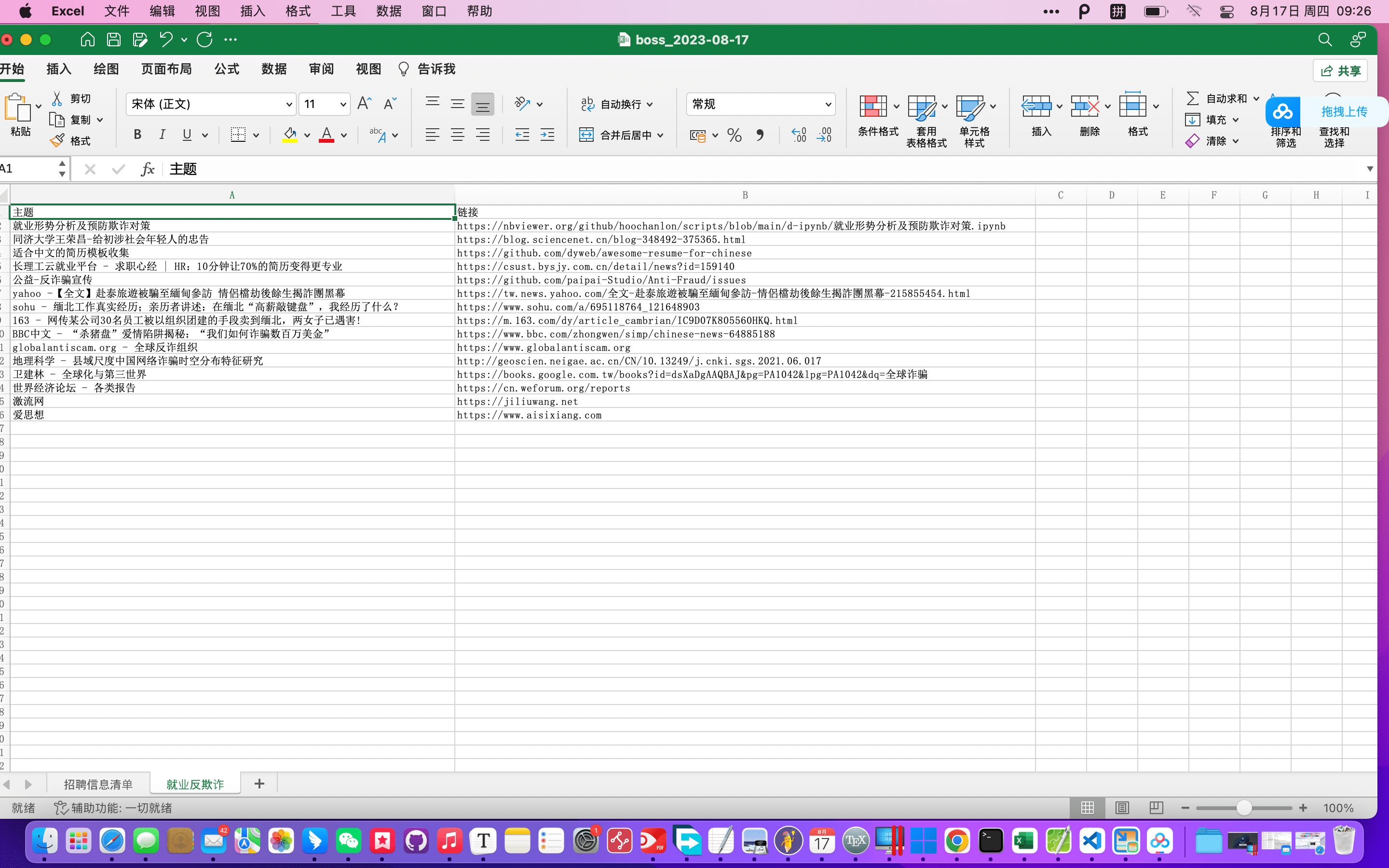
附源码
https://github.com/hoochanlon/scripts/blob/main/d-python/zhipin_demo.py
import os
import re
import platform
import requests
import json
import urllib.request
from openpyxl import Workbook
from datetime import datetime
class GetDataTools:
@staticmethod
def get_citycode(input_city):
response = urllib.request.urlopen('https://ghproxy.com/https://raw.githubusercontent.com/hoochanlon/scripts/main/d-json/bosszhipin_citycode.json')
city_json = json.loads(response.read().decode('utf-8'))
city_code = None
for group in city_json["zpData"]["cityGroup"]:
for city in group["cityList"]:
if city["name"] == input_city:
city_code = city["code"]
return city_code
return None
@staticmethod
def validate_cookie(input_cookie):
cookie_list = input_cookie.split("; ")
cookies_dict = {}
try:
for item in cookie_list:
key, value = item.strip().split("=", 1)
cookies_dict[key] = value
except ValueError:
return False
return True
class ZhiPin:
@staticmethod
def get_job_list():
input_keywords = input("请输入查询职位:")
input_city = input("请输入城市:")
city_code = GetDataTools.get_citycode(input_city)
while city_code is None:
print("未找到匹配的城市编码,请重新输入城市名。")
input_city = input("请输入城市:")
city_code = GetDataTools.get_citycode(input_city)
# input_num = input("请输入需要遍历的页码:")
input_cookie = input("请复制Cookie:")
# while not GetDataTools.validate_cookie(input_cookie):
# input_cookie = input("请重新复制Cookie:")
job_data_list = []
# boss直聘最多只能遍历前三页,不然会直接报错。
for page in range(1,4):
url = f'https://www.zhipin.com/wapi/zpgeek/search/joblist.json?query={input_keywords}&city={city_code}&experience=105&salary=405&page={page}&pageSize=30'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.101 Safari/537.36',
'Cookie': input_cookie,
}
data = requests.get(url, headers=headers).json()
job_data_list.append(data)
return job_data_list
@staticmethod
def save_to_json(job_data_list):
save_json = os.path.join(
os.path.join(os.path.expanduser("~"), "Desktop"),
"boss_{}.json".format(datetime.now().strftime('%Y-%m-%d'))
)
with open(save_json, 'w', encoding='utf-8') as f:
json.dump(job_data_list, f, ensure_ascii=False, indent=4)
return save_json
class DataToExcel:
@staticmethod
def save_to_excel(workbook, zhipin_json):
with open(zhipin_json, 'r', encoding='utf-8') as f:
zhipin_json = json.load(f)
worksheet = workbook.create_sheet(title='招聘信息清单')
titles = [
'职位', '技能', '经验', '学历', '工资', '福利',
'公司', '公司类型', '人数规模', '融资状态', '地址'
]
for col, title in enumerate(titles, start=1):
worksheet.cell(row=1, column=col, value=title)
data_list = []
for item in zhipin_json:
if "zpData" in item and "jobList" in item["zpData"]:
data_list.extend(item["zpData"]["jobList"])
row = 2
column = 1
for job in data_list:
worksheet.cell(row=row, column=column, value=job['jobName'])
column += 1
worksheet.cell(row=row, column=column, value='; '.join(job['skills']))
column += 1
worksheet.cell(row=row, column=column, value=job['jobExperience'])
column += 1
worksheet.cell(row=row, column=column, value=job['jobDegree'])
column += 1
worksheet.cell(row=row, column=column, value=job['salaryDesc'])
column += 1
worksheet.cell(row=row, column=column, value='; '.join(job['welfareList']))
column += 1
worksheet.cell(row=row, column=column, value=job['brandName'])
column += 1
worksheet.cell(row=row, column=column, value=job['brandIndustry'])
column += 1
worksheet.cell(row=row, column=column, value=job['brandScaleName'])
column += 1
worksheet.cell(row=row, column=column, value=job['brandStageName'])
column += 1
worksheet.cell(row=row, column=column, value=f"{job['cityName']} {job['areaDistrict']} {job['businessDistrict']}")
column += 1
row += 1
column = 1
# 添加新的sheet并写入相关的行列数据
extra_sheet = workbook.create_sheet(title='就业反欺诈')
extra_data = [
['主题', '链接'],
['就业形势分析及预防欺诈对策', 'https://nbviewer.org/github/hoochanlon/scripts/blob/main/d-ipynb/就业形势分析及预防欺诈对策.ipynb'],
['同济大学王荣昌-给初涉社会年轻人的忠告', 'https://blog.sciencenet.cn/blog-348492-375365.html'],
['适合中文的简历模板收集', 'https://github.com/dyweb/awesome-resume-for-chinese'],
['长理工云就业平台 - 求职心经 | HR:10分钟让70%的简历变得更专业','https://csust.bysjy.com.cn/detail/news?id=159140'],
['公益-反诈骗宣传','https://github.com/paipai-Studio/Anti-Fraud/issues'],
['yahoo -【全文】赴泰旅遊被騙至緬甸參訪 情侶檔劫後餘生揭詐團黑幕','https://tw.news.yahoo.com/全文-赴泰旅遊被騙至緬甸參訪-情侶檔劫後餘生揭詐團黑幕-215855454.html'],
['sohu - 缅北工作真实经历;亲历者讲述:在缅北“高薪敲键盘”,我经历了什么? ','https://www.sohu.com/a/695118764_121648903'],
['163 - 网传某公司30名员工被以组织团建的手段卖到缅北,两女子已遇害!','https://m.163.com/dy/article_cambrian/IC9D07K805560HKQ.html'],
['BBC中文 - “杀猪盘”爱情陷阱揭秘:“我们如何诈骗数百万美金”','https://www.bbc.com/zhongwen/simp/chinese-news-64885188'],
['globalantiscam.org - 全球反诈组织','https://www.globalantiscam.org'],
['地理科学 - 县域尺度中国网络诈骗时空分布特征研究','http://geoscien.neigae.ac.cn/CN/10.13249/j.cnki.sgs.2021.06.017'],
['卫建林 - 全球化与第三世界','https://books.google.com.tw/books?id=dsXaDgAAQBAJ&pg=PA1042&lpg=PA1042&dq=全球诈骗'],
['世界经济论坛 - 各类报告','https://cn.weforum.org/reports'],
['激流网','https://jiliuwang.net'],
['爱思想','https://www.aisixiang.com'],
['心理测试','https://types.yuzeli.com/survey'],
['国际IQ测试','https://international-iq-test.com/zh-Hans/'],
['复旦大学博弈论','http://fdjpkc.fudan.edu.cn/201915/']
]
for row, data_row in enumerate(extra_data, start=1):
for col, value in enumerate(data_row, start=1):
extra_sheet.cell(row=row, column=col, value=value)
if __name__ == '__main__':
job_data_list = ZhiPin.get_job_list()
zhipin_json = ZhiPin.save_to_json(job_data_list)
workbook = Workbook()
workbook.remove(workbook.active)
# DataToExcel.save_to_excel(workbook, os.path.join(
# os.path.join(os.path.expanduser("~"), "Desktop"),
# "boss_{}.json".format(datetime.now().strftime('%Y-%m-%d'))
# ))
DataToExcel.save_to_excel(workbook,zhipin_json)
save_xlsx = os.path.join(
os.path.join(os.path.expanduser("~"), "Desktop"),
"boss_{}.xlsx".format(datetime.now().strftime('%Y-%m-%d'))
)
workbook.save(save_xlsx)


 发表于 2023-8-17 11:41
发表于 2023-8-17 11:41
 |
发表于 2023-8-17 15:40
|
发表于 2023-8-17 15:40




