Day 10 包(package):设计与应用模块
第8章介绍了函数,第9章介绍了类,其实在大型程序设计中,每人可能只负责一小块功能的函数或类设计,为了可以让团队的其他人互相分享设计成果,最后每 个人所负贵的功能函数或类将存储在模块(module)中,然后供团队其他成员使用。在网络上或国外的技术文件中常将模块(module)称为包(package),意义是一样的。
通常我们将模块分成3大类:
1)我们自己建立的模块,下面4小节会说明。
2)Python内建的模块,下列是Python常用的模块:
| 模块名称 |
功能 |
出现的章节 |
| calendar |
日历 |
</a id=“”> |
| csv |
日期与时间 |
|
| email |
电子邮件 |
|
| html |
HTML |
|
| html.parser |
解析HTML |
|
| http |
HTTP |
|
| io |
输入与输出 |
|
| json |
json文件 |
|
| keyword |
关键词 |
|
| logging |
程序日志 |
|
| math |
常用数学 |
|
| os |
操作系统 |
|
| os.path |
路径管理 |
|
| pickle |
pickle串行化数据 |
|
| random |
随机数 |
|
| re |
正则表达式 |
|
| socket |
网络应用 |
|
| sqlite3 |
SQLite |
|
| statistics |
统计 |
|
| sys |
系统 |
|
| time |
时间 |
|
| urllib |
URL |
|
| urllib.request |
URL的相关操作 |
|
| xml.dom |
XML DOM |
|
| zipfile |
压缩与解压 |
|
3)外部模块,须使用pip安装,未来章节会在使用时说明。
本章的内容是介绍如何将自己设计的函数或者类存储为模块然后加以引用,最后讲解Python 常用的内建模块。
10.1 将自建函数/类打包
一个大型程序一定是由许多的函数或类所组成,为了让程序的工作可以分工以及增加程序的可读性,我们可以将所建的函数或类存储成模块(module)形式的独立文件,未来再加以引用。
10.1.1 建立函数内容的模块
假设有一个程序内容用于建立冰激凌(ice cream)和饮料(drink),如下所示:
# makefood.py
# 这是一个包含两个函数的模块(module)
def make_icecream(*toppings):
# 列出制作冰淇淋的配料
print("这个冰淇淋所加配料如下")
for topping in toppings:
print("--- ", topping)
def make_drink(size, drink):
# 输入饮料规格与种类,然后输出饮料
print("所点饮料如下")
print("--- ", size.title())
print("--- ", drink.title())
make_icecream('草莓酱')
make_icecream('草莓酱', '葡萄干', '巧克力碎片')
make_drink('large', 'coke')
output:
这个冰淇淋所加配料如下
--- 草莓酱
这个冰淇淋所加配料如下
--- 草莓酱
--- 葡萄干
--- 巧克力碎片
所点饮料如下
--- Large
--- Coke
假设需要在其他程序调用make_icecream()和make_drink(),此时可以考虑将这两个函数建立成模块(module),未来供其他程序调用。
10.2 应用自己建立的模块
有几种方式可以应用函数模块,下列简要说明。
10.2.1 import 模块名称
语法格式:
import 模块名称 # 导入模块
程序实例:
import makefood # 导入模块makefood.py
makefood.make_icecream('葡萄干', '巧克力碎片')
makefood.make_drink('large', 'Fanta')
output:
这个冰淇淋所加配料如下
--- 草莓酱
这个冰淇淋所加配料如下
--- 草莓酱
--- 葡萄干
--- 巧克力碎片
所点饮料如下
--- Large
--- Coke
这个冰淇淋所加配料如下
--- 葡萄干
--- 巧克力碎片
所点饮料如下
--- Large
--- Fanta
| 应用模块的操作 |
语法 |
| 导入模块内特定单一函数 |
from 模块名称 import 函数名称 |
| 导入模块内多个函数 |
from 模块名称 import 函数名称1,...,函数名称n |
| 导入模块所有函数 |
from 模块名称 import * |
| 使用as给函数指定替代名称 |
from 模块名称 import 函数名称 as 替代名称 |
| 使用as给模块指定替代名称 |
import 模块名称 as 替代名称 |
10.2.2 main()与_ name _的搭配
我们发现在10.2.1的主程序实例导入模块makefood.py运行后,结果发现模块里面的程序也被运行了,那么对于模块makefood.py,为了不希望将此程序当成模块被引用时,执行其中程序的内容,即15-17行内容,其实我们可以重新设计makefood.py:
# makefood.py
# 重新设计makefood.py
# 这是一个包含两个函数的模块(module)
def make_icecream(*toppings):
# 列出制作冰淇淋的配料
print("这个冰淇淋所加配料如下")
for topping in toppings:
print("--- ", topping)
def make_drink(size, drink):
# 输入饮料规格与种类,然后输出饮料
print("所点饮料如下")
print("--- ", size.title())
print("--- ", drink.title())
def main():
make_icecream('草莓酱')
make_icecream('草莓酱', '葡萄干', '巧克力碎片')
make_drink('large', 'coke')
if __name__ == "__main__"
main
上述程序我们将原先主程序内容放在第16~19行的main()内,然后在第21~22行增加下列描述:
if __name__ == "__main__"
main
上述表示,如果自己独立执行new_makefood.py会去调用majn()执行main()的内容。如果这个程序被当作模引用lmport new_makefood,则不执行main()。
10.3 将自建类存储在模块内
与函数相同,定义完类后就可以在其他程序中应用类了:
| 应用类模块的操作 |
语法 |
| 导入模块内单一类 |
from 模块名称 import 类名称 |
| 导入模块内多个类 |
from 模块名称 import 类1,...,类n |
| 导入模块所有类 |
from 模块名称 import * |
| 使用as给函数指定替代名称 |
from 模块名称 import 类名称 as 替代名称 |
| 使用as给模块指定替代名称 |
import 类名称 as 替代名称 |
| 模块内导入另一个模块的类 |
导入子类的模块时也必须将父类导入 |
| import导入模块后,程序中要引用模块的类 |
模块名称.类名称(中间有小数点) |
10.4 随机数random模块
所谓的随机数是指平均散布在某区间的数字’。
| 函数名称 |
说明 |
| randint(x,y) |
产生[x,y]的随机整数 |
| random() |
产生[0,1)的随机浮点数 |
| uniform(x,y) |
产生[x,y)的随机浮点数 |
| choice(列表) |
可以在列表中随机回传一个元素 |
| shuffle(列表) |
将列表重新排列 |
| sample(列表,数量) |
随机回传第二个参数数量的列表元素 |
| seed(x) |
x是种子值,未来每一次运行程序可以产生相同的随机数 |
10.4.1 random.choice()
import random # 导入模块random
for i in range(10):
print(random.choice([1,2,3,4,5,6]), end=",")
output:
5,2,6,4,6,1,2,6,1
10.4.2 random.shuffle()
import random # 导入模块random
porker = ['2', '3', '4', '5', '6', '7', '8',
'9', '10', 'J', 'Q', 'K', 'A']
for i in range(3):
random.shuffle(porker) # 将次序打乱重新排列
print(porker)
output:
['K', '2', 'A', '7', '3', 'J', '10', '9', 'Q', '4', '8', '6', '5']
['6', '10', 'K', '7', 'Q', '4', '9', 'A', '3', '5', '8', '2', 'J']
['6', '5', '9', '4', 'A', 'Q', '3', '10', 'K', 'J', '8', '2', '7']
10.5 时间time模块
| 函数名称 |
说明 |
| time() |
可以回传自1970年1月1日00:00:00:AM以来的秒数 |
| sleep(n) |
可以让工作暂停n秒 |
| asctime() |
列出可以阅读的目前系统时间 |
| localtime() |
可以返回目前时间的结构数据 |
| ctime() |
与localtime()相同,不过回传的是字符串 |
| clock() |
取得程序执行的时间(旧版,未来不建议使用) |
| process_time() |
取得程序执行的时间(新版) |
10.5.1 asctime()
import time
print(time.asctime())
output:
Tue Sep 5 21:58:20 2023
10.5.2 localtime()
这个方法可以返回日期与时间的元组(tuple)结构数据,所返回的结构可以用索引方式获得个别内容。
| 索引 |
名称 |
说明 |
| 0 |
tm_year |
公元的年,例如2023 |
| 1 |
tm_mon |
月份,值在1~12 |
| 2 |
tm_mday |
日期,值在1~31 |
| 3 |
tm_hour |
小时,值在0~23 |
| 4 |
tm_min |
分钟,值在0~59 |
| 5 |
tm_sec |
秒钟,值在0~59 |
| 6 |
tm_wday |
星期几的设定,0代表星期一,1代表星期2 |
| 7 |
tm_yday |
代表这是一年中的第几天 |
| 8 |
tm_isdst |
夏令时时间的设定,0代表不是,1代表是 |
程序实例:
import time # 导入模块time
xtime = time.localtime()
print(xtime) # 列出目前系统时间
print("年 ", xtime[0])
print("年 ", xtime.tm_year) # 对象设定方式显示
print("月 ", xtime[1])
print("日 ", xtime[2])
print("时 ", xtime[3])
print("分 ", xtime[4])
print("秒 ", xtime[5])
print("星期几 ", xtime[6])
print("第几天 ", xtime[7])
print("夏令时间 ", xtime[8])
output:
time.struct_time(tm_year=2023, tm_mon=9, tm_mday=6, tm_hour=9, tm_min=53, tm_sec=46, tm_wday=2, tm_yday=249, tm_isdst=0)
年 2023
年 2023
月 9
日 6
时 9
分 53
秒 46
星期几 2
第几天 249
夏令时间 0
10.5.3 process_time()
改函数功能是,取得程序运行的时间,第一次调用时回传程序开始执行到执行到 process_time()经历的时间,第二次以后的调用则是说明与第一次调用 process_time()间隔的时间,并且这个 process_time()的时间计算会排除CPU没有运作的时间,例如在等待使用者输入的时间就不会被计算。
程序实例:
import time
x = 1000000
pi = 0
time.process_time()
for i in range(1,x+1):
pi += 4*((-1)**(i+1) / (2*i-1))
if i != 1 and i % 100000 == 0: # 隔100000执行一次
e_time = time.process_time()
print(f"当 {i=:7d} 时 PI={pi:8.7f}, 所花时间={e_time}")
output:
当 i= 100000 时 PI=3.1415827, 所花时间=0.234375
当 i= 200000 时 PI=3.1415877, 所花时间=0.28125
当 i= 300000 时 PI=3.1415893, 所花时间=0.328125
当 i= 400000 时 PI=3.1415902, 所花时间=0.375
当 i= 500000 时 PI=3.1415907, 所花时间=0.421875
当 i= 600000 时 PI=3.1415910, 所花时间=0.46875
当 i= 700000 时 PI=3.1415912, 所花时间=0.515625
当 i= 800000 时 PI=3.1415914, 所花时间=0.5625
当 i= 900000 时 PI=3.1415915, 所花时间=0.609375
当 i=1000000 时 PI=3.1415917, 所花时间=0.671875
10.6 keyword模块
这个模块有一些Python关键词的功能。
10.6.1 kwlist属性
这个属性含有Python的关键词。
import keyword
print(keyword.kwlist)
output:
['False', 'None', 'True', '__peg_parser__', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
10.6.2 iskeyword()
这个方法可以回传参数的字符串是否时关键词,如果是,回传True,如果否,回传False。
import keyword
keywordLists = ['as', 'while', 'break', 'sse', 'Python']
for x in keywordLists:
print(f"{x:>8s} {keyword.iskeyword(x)}") # {:>8}右对齐,占8个字符空间
output:
as True
while True
break True
sse False
Python False
10.7 calendar模块
日期模块有一些日历数据,很方便使用,我们将介绍几个常用的方法。使用此模块前需要先导入calendar。
| 名称 |
用例 |
说明 |
| isleap() |
calendar.isleap(year) |
列出某年是否为闰年,是回传True,反正False |
| month() |
month(year,month) |
列出指定年份、月份的月历。 |
| calendar() |
calendar(year) |
列出指定年份的年历。 |
10.8 实用的Python模块
10.8.1 collections模块
10.8.1.1 defaultdic()
这个模块有defaultdic(fun)方法,这个方法可以为新建立的字典并设定默认值,它的参数是一个函数,如果参数是int,则参数相当于是int(),默认值会回传0。如果参数是list或dict,默认值分别回传[ ]或{ }。如果省略参数,回传None。
from collections import defaultdict
fruits = defaultdict(int)
fruits["apple"] = 20
fruits["orange"] # 使用int预设的0
print(fruits["apple"])
print(fruits["orange"])
print(fruits)
output:
20
0
defaultdict(<class 'int'>, {'apple': 20, 'orange': 0})
除了使用int、list外,我们还可以自行设计defaultdict()方法内的函数。
使用自行设计的函数重新设计上面的程序:
from collections import defaultdict
def price():
return 10
fruits = defaultdict(price)
fruits["apple"] = 20
fruits["orange"] # 使用自行设计的price()
print(fruits["apple"])
print(fruits["orange"])
print(fruits)
output:
20
10
defaultdict(<function price at 0x000002555BE26040>, {'apple': 20, 'orange': 10})
甚至可以用lambda函数重新设计。
当使用defaultdict(int)时,我们可以利用此特性建立计数器。
from collections import defaultdict
fruits = defaultdict(int)
for fruit in ["apple","orange","apple"]:
fruits[fruit] += 1
for fruit, count in fruits.items():
print(fruit, count)
output:
apple 2
orange 1
PS:对于上述程序而言,如果我们没有学过defaultdict()创建字典,还是使用dict字典方式时,那么上述程序的第5行就会出现KeyError错误,因为尚未建立该键,就会需要改写一下程序比较麻烦。
10.8.1.2 counter()
这个方法可以将列表元素转成字典的键,字典的值则是元素在列表出现的次数。注意,此方法所建的数据类型是Collections.Counter,元素则是字典。
from collections import Counter
fruits = ["apple","orange","apple"]
fruitsdict = Counter(fruits)
print(fruitsdict)
output:
Counter({'apple': 2, 'orange': 1})
10.8.1.3 most_common()
这个most_common(n),用于将字典按照“键:值”的数量从大到小顺序回传,n是设定的回传元素。
10.8.1.4 counter对象的加与减;交集与并集
对于Counter对象而言’我们可以使用加法与减法。相加的方式是所有元素相加,若有重复的元素则键的值会相加;若想列出A有B没有的元素,可以用A-B。
可以使用&当作交集符号,|当作并集符号。并集与加法不一样,它不会将数量相加,只是取多的部分。交集则是取数量少的部分。
from collections import Counter
fruits1 = ["apple","orange","apple"]
fruitsdictA = Counter(fruits1)
fruits2 = ["grape","orange","orange", "grape"]
fruitsdictB = Counter(fruits2)
# 加法
fruitsdictAdd = fruitsdictA + fruitsdictB
print("加法:",fruitsdictAdd)
# 減法
fruitsdictSub = fruitsdictA - fruitsdictB
print("减法:",fruitsdictSub)
# 交集
fruitsdictInter = fruitsdictA & fruitsdictB
print("交集:",fruitsdictInter)
# 并集
fruitsdictUnion = fruitsdictA | fruitsdictB
print("并集:",fruitsdictUnion)
output;
加法: Counter({'orange': 3, 'apple': 2, 'grape': 2})
减法: Counter({'apple': 2})
交集: Counter({'orange': 1})
并集: Counter({'apple': 2, 'orange': 2, 'grape': 2})
10.8.1.5 deque()
这是数据结构中的双头序列,具有堆栈stack和队列queue的功能,我们可以从左右两边增加元素,可以从左右两边删除元素。pop()方法可以移除右边的元素并回传,popleft()可以移除左边的元素并回传。
在程序设计有一个常用的名词“回文(palindrome)”,从从左右两边往内移动,如果相同就一直比对到中央,如果全部相同就是回文,否则不是回文。
# 判断回文
from collections import deque
def palindrom(word):
wd = deque(word)
while len(wd) > 1:
if wd.pop() != wd.popleft():
return False
return True
print(palindrom("abccba"))
print(palindrom("python"))
output:
True
False
这是一个迭代的模块,有几个方法很有特色。
10.8.2.1 chain()
这个方法可以将chain()参数的元素内容一一迭代出来。
import itertools
for i in itertools.chain([1,2,3],('a','d')):
print(i)
output:
1
2
3
a
d
10.8.2.2 cycle()
这个方法回产生无限迭代。
import itertools
for i in itertools.cycle(('a','b','c')):
print(i)
output:
a
b
c
a
b
10.8.2.3 accumulate()
accumulate()只有一个参数,则是列出累计的值,如果accumulate()有两个参数,则第2个参数是函数,可以依照此函数列出累计的计算结果。
import itertools
def mul(x, y):
return (x * y)
for i in itertools.accumulate((1,2,3,4,5)):
print(i)
for i in itertools.accumulate((1,2,3,4,5),mul):
print(i)
output:
1
3
6
10
15
1
2
6
24
120
10.8.2.3 combinations()
该方法必须是2个参数,第1个参数是可迭代对象,第2个参数是r,此方法可以返回长度为r的子序列,此子序列就是各种元素的组合。
import itertools
x = ['a', 'b', 'c']
r = 2
y = itertools.combinations(x, r)
print(list(y))
output:
[('a', 'b'), ('a', 'c'), ('b', 'c')]
其实这个函数可以应用在遗传的基因组合。例如:人类控制双眼皮的基因是F,这是显性,控制单眼皮的基因是f,这是隐性,基因组合方式有FF、Ff、ff。而在基因组合中FF、Ff皆是双眼皮, ff则是单眼皮。
假设父母基因皆是Ff,父母单一基因遗传给子女的概率相等,请计算子女单眼皮概率和双眼皮概率。注:真实世界子女基因一个来自父亲另一个来自母亲,这时概率分别0.25和0.75。
10.9 string模块
这是字符串模块,在这个模块内有—系列程序设计有关的字符串,可以使用strings的属性读取这些字符串。使用前
需要import string
string.digits:"0123456789"。
string.hexdigits:"0123456789abcdefABCDEF"。
string.octdigits:"01234567"。
string.ascii_letters:"abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"。
string.ascii_lowercase:"abcdefghijklmnopqrstuvwxyz"。
string.ascii_uppercase:"ABCDEFGHIJKLMNOPQRSTUVWXYZ"。
string.whitespace:"\t\n\r\x0b\x0c"
10.10 小测试
T10.10.1 赌场游戏骗局
(使用random模块)设计一个猜数字大小的游戏,程序开始即可设定庄家的输赢比例(例如设置:庄家输赢比为7:10),刚开始玩家有300美元赌本,每次赌注是l00美元,如果猜对,赌金增加100美元,如果猜错赌金减少100美元,赌金没了或者是按Q或者q结束游戏。
import random
Initial_money = 300
def game(money,ratio): # money为本金,ratio为庄家赢钱概率。
while True:
conti = input("猜单个骰子点数大小游戏:L或l表示大,S或s表示小,q或Q退出游戏:")
print("您的本金为{}美元!\n".format(money))
if conti in "LlSs":
print("游戏开始!您下注的金额为:100美元")
if ratio <= random.random(): # 30%的概率玩家赢
print("恭喜您猜对了!赌金增加100美元!")
money += 100
else: # 70%的概率玩家输
if conti in "Ll":
print("骰子的点数为{},很遗憾您猜错了,请再试一次!".format(random.choice([1,2,3])))
else:
print("骰子的点数为{},很遗憾您猜错了,请再试一次!".format(random.choice([4,5,6])))
money -= 100
print("您现在还有{}美元\n".format(money))
if money < 100:
print("本金不够,请及时充值!")
break
elif conti in "Qq":
print("欢迎下次光临!")
break
else:
print("输入有误,请重新输入!")
game(300,0.7)
out:
猜单个骰子点数大小游戏:L或l表示大,S或s表示小,q或Q退出游戏:l
您的本金为300美元!
游戏开始!您下注的金额为:100美元
恭喜您猜对了!赌金增加100美元!
您现在还有400美元
......
T10.10.2 蒙特卡罗模拟
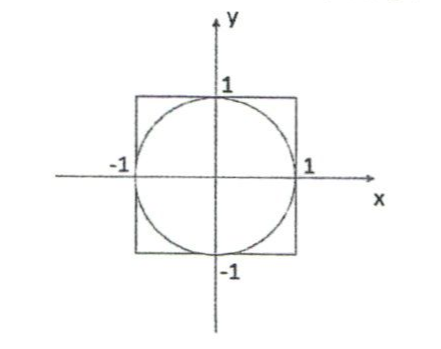
我们可以使用蒙特卡罗模拟计算PI(圆周率)值,首先绘制一个外接正方形的圆,圆的半径是1。由上图可以知道矩形面积是4,圆面积是PI。
如果我们现在要产生100万个落在正方形内的点,可以由下列公式计算点落在圆内的概率:
圆面积 / 矩形面积 = PI / 4
落在圆内的点个数(Hits)=10000000 * PI / 4
那么PI = 4 * Hits / 10000000
https://s1.ax1x.com/2023/09/08/pP6GPFU.png
import random
def MCMC_CalcuPI(sample):
regu_side = 2 # 正方形边长
cyc_radius = 1 # 内切圆半径
Hits = 0 # 落于圆内的点数
for i in range(sample):
sample_x = random.random() * regu_side - 1 # 采样点数的横坐标[-1,1)
sample_y = random.random() * regu_side - 1 # 采样点数的纵坐标[-1,1)
if sample_x**2 + sample_y**2 <= cyc_radius:
Hits += 1
PI =( 4 * Hits ) / sample
return PI
sample = 1000000 # 采样点数(在正方形内随机位置产生这些点)
print(MCMC_CalcuPI(sample))
out:
3.144072
T10.10.3 文件加密
我们之前在第6章练习了凯撒密码的加密过程,但是可以发现,加密规则过于简单,比较容易被破译(每个字母的密钥是固定不变的),因此想用用string、random模块重新设计凯撒密码的加密过程,但是新要求是:对于同一串字符,每次运行程序要求输出的密文都不同:
PS之前的加密程序要求是:通过将每个字母向后移动3个字符来加密26个字母如(a => d,z => c),要求程序输入明文:"python",输出密文:sbwkrq。(提示:将明文当键,密文当值;双值序列建立字典)
import string
import random
def encrypt(text, encryDict): # 加密文件
cipher = []
for i in text: # 执行每个字符加密
v = encryDict[i] # 加密
cipher.append(v) # 加密结果
return ''.join(cipher) # 将列表转成字符串
abc = string.printable[:-5] # 取消不可打印字符
newabc = abc[:] # 产生新字符串复制
abclist = list(newabc) # 字符串转列表
random.shuffle(abclist)
subText = "".join(abclist) # 重新排列列表内容,并将列表转换成字符串
encry_dict = dict(zip(subText, abc)) # 建立字典
print("打印编码字典\n", encry_dict) # 打印字典
msg = 'If the implementation is easy to explain, it may be a good idea.'
ciphertext = encrypt(msg, encry_dict)
print("原始字符串 ", msg)
print("加密字符串 ", ciphertext)
out1:
打印编码字典
{'>': '0', 'c': '1', 'u': '2', 'y': '3', '}': '4', '`': '5', 'I': '6', 'U': '7', '(': '8', '2': '9', '-': 'a', 'K': 'b', 'f': 'c', '3': 'd', 'd': 'e', 'r': 'f', 'n': 'g', 'F': 'h', '#': 'i', '7': 'j', 'o': 'k', '$': 'l', 'm': 'm', 's': 'n', 'V': 'o', 'h': 'p', '8': 'q', 'q': 'r', 'x': 's', 'P': 't', '/': 'u', '"': 'v', ',': 'w', 'Y': 'x', 'v': 'y', '_': 'z', 'L': 'A', '^': 'B', '!': 'C', 'Q': 'D', ';': 'E', '6': 'F', 'Z': 'G', 'R': 'H', 'w': 'I', 'j': 'J', '\\': 'K', 'J': 'L', 'S': 'M', '*': 'N', 'p': 'O', '0': 'P', 'C': 'Q', 'A': 'R', '{': 'S', 'z': 'T', 'E': 'U', 'a': 'V', 'T': 'W', '~': 'X', '%': 'Y', 'H': 'Z', 'G': '!', 'i': '"', 'k': '#', '9': '$', '4': '%', 'B': '&', '@': "'", '1': '(', ')': ')', 'O': '*', '+': '+', ':': ',', "'": '-', 'b': '.', '.': '/', '|': ':', '&': ';', 'D': '<', 'W': '=', 'l': '>', 'e': '?', 't': '@', '?': '[', 'g': '\\', 'X': ']', '=': '^', 'N': '_', ']': '`', '5': '{', ' ': '|', '[': '}', 'M': '~', '<': ' '}
原始字符串 If the implementation is easy to explain, it may be a good idea.
加密字符串 6c|@p?|"mO>?m?g@V@"kg|"n|?Vn3|@k|?sO>V"gw|"@|mV3|.?|V|\kke|"e?V/
out2:
打印编码字典
{'`': '0', 'W': '1', 'u': '2', 'q': '3', 'd': '4', '1': '5', '|': '6', '(': '7', 'B': '8', 'I': '9', '\\': 'a', 'J': 'b', 'C': 'c', 'T': 'd', 'L': 'e', 'P': 'f', 'g': 'g', 'N': 'h', 'Q': 'i', '}': 'j', ':': 'k', 'E': 'l', 'n': 'm', '3': 'n', '%': 'o', '5': 'p', 'o': 'q', 'i': 'r', 's': 's', '_': 't', 'F': 'u', 'K': 'v', 'O': 'w', 'Y': 'x', 'm': 'y', 'A': 'z', '9': 'A', 'r': 'B', 'G': 'C', 'S': 'D', ')': 'E', 'f': 'F', 'M': 'G', 'v': 'H', '#': 'I', 'b': 'J', 'w': 'K', '?': 'L', 'e': 'M', 'X': 'N', '!': 'O', ';': 'P', ']': 'Q', 'V': 'R', '>': 'S', ',': 'T', '8': 'U', '{': 'V', '@': 'W', 'c': 'X', "'": 'Y', '2': 'Z', '"': '!', '&': '"', 'x': '#', 'p': '$', '~': '%', '*': '&', 'z': "'", '.': '(', ' ': ')', 't': '*', 'a': '+', '<': ',', 'y': '-', 'U': '.', '^': '/', 'H': ':', 'h': ';', 'Z': '<', 'D': '=', '+': '>', '[': '?', 'j': '@', '/': '[', '6': '\\', '-': ']', 'R': '^', '=': '_', 'l': '`', '$': '{', '7': '|', '4': '}', 'k': '~', '0': ' '}
原始字符串 If the implementation is easy to explain, it may be a good idea.
加密字符串 9F)*;M)ry$`MyMm*+*rqm)rs)M+s-)*q)M#$`+rmT)r*)y+-)JM)+)gqq4)r4M+(

 [复制链接]
[复制链接]
 发表于 2023-9-8 19:53
发表于 2023-9-8 19:53




{kind=link}