引言
本文介绍后台任务延迟队列的“元素” 后台任务构造器 以及Curator 对于常见的ZK节点操作封装API。后台任务构造器对应了和ZK交互的常见”后台“操作,比如创建和销毁Watch,而ZK节点操作API涉及各种建造者模式的应用。可以说,Curator 整个框架各种地方都有建造者模式的身影。
Curator除了对于ZK本身交互和操作封装之外,还引入了Cache的概念来实现对ZooKeeper服务器端进行事件监听,本质上就是构建本地缓存,在远程节点出现”状态“变动的时候进行”联动“触发各种事件。
不过,Cache 的部分个人认为并不是很重要的内容,更多重心还是在分布式锁,再加上查询各种资料本身应用场景也比较少,因此放到了文章最后分析,读者可以按需阅读。
相关应用场景和重要概念
本文的源码分析涉及到 ZK 的应用场景和重要概念,这里先补充相关概念,为后面的源码分析铺垫。
相关应用场景
ZK 中可以完成数据发布订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举,分布式锁和分布式队列。
命名服务: 使用 ZooKeeper 的顺序节点生成全局唯一 ID。
数据发布/订阅:通过 Watcher 机制 可以很方便地实现数据发布/订阅。
分布式锁:通过创建唯一节点获得分布式锁,通常会使用临时节点的方式持有锁,特点是在节点宕机之后会自动释放。
重要概念
ZNode 概念
Zookeeper 的数据模型使用的是多叉树结构,每个节点上面可以存储任意类型的数据,比如数组、字符串、二进制序列。由于是树状节点,每个节点还可以有子节点。
树状节点的组成每个节点可以有N个子节点,根节点为 "/",每个数据节点在Zookeeper中都被叫做ZNode,整个树的组成有点类似Linux的文件系统结构。
注意 ZNode 通常用于临时创建,适合用于比较小体积的锁应用,不建议存储过大的业务数据,不要把过大的数据放到 ZNode上。
ZNode 数据节点
Zookeeper 的数据节点 ZNode 是最小组成单元,ZNode 是 ZK 实现分布式锁的重要基础,它主要有如下分类:
- 持久(PERSISTENT)节点:一旦创建就会一直存在,直到 ZK集群宕机才会删除。
- 临时(EPHEMERAL)节点:临时节点的生命周期是与 客户端会话(session) 绑定,会话消失则节点消失,
- 持久顺序(PERSISTENT_SEQUENTIAL)节点:在持久节点的特性上,子节点的名称依然有顺序性,比如
/node1/app0000000001、/node1/app0000000002 。
- 临时顺序(EPHEMERAL_SEQUENTIAL)节点:除了具备临时(EPHEMERAL)节点的特性之外,子节点的名称还具有顺序性。
Watcher(事件监听器)
Watcher 事件监听器是 Zookeeper 当中非常重要的特性,ZK 允许用户在指定的 Znode 上面注册监听器 Watcher,特定的事件触发时候,ZK服务端会把事件通知到注册Watcher的客户端,。事件监听器也是分布式协调服务的重要组成部分。
在 Curator 中,Watcher 事件监听器是不同客户端监听分布式锁释放的重要应用组件。
ZK可视化客户端 PrettyZoo
为了方便我们调试源码的同时观察ZK节点变更,这里推荐使用 PrettyZoo 客户端。
PrettyZoo 是一个基于 Apache Curator 和 JavaFX 实现的 Zookeeper 图形化管理客户端。使用了 Java 的模块化(Jigsaw)技术,并基于 JPackage 打包了多平台的可运行文件(无需要额外安装 Java 运行时)。
目前已提供了 mac(dmg 文件)、Linux(deb 和 rpm 文件)、windows(msi 文件) 的安装包,下载地址。
个人为Win系统,选择win.msi 的安装包,安装并启动并且就进入到主页面
完成配置之后进行连接,最终的连接效果如图:

前面的铺垫已经完成,下面正式进入主题。
后台任务构造器
在[【Zookeeper】Apach Curator 框架源码分析:初始化过程(一)【Ver 4.3.0】]当中,我们介绍了Curator实例化、Zookeeper连接以及各种组件初始化和启动过程,其中就有一个后台执行操作队列不断执行后台操作。
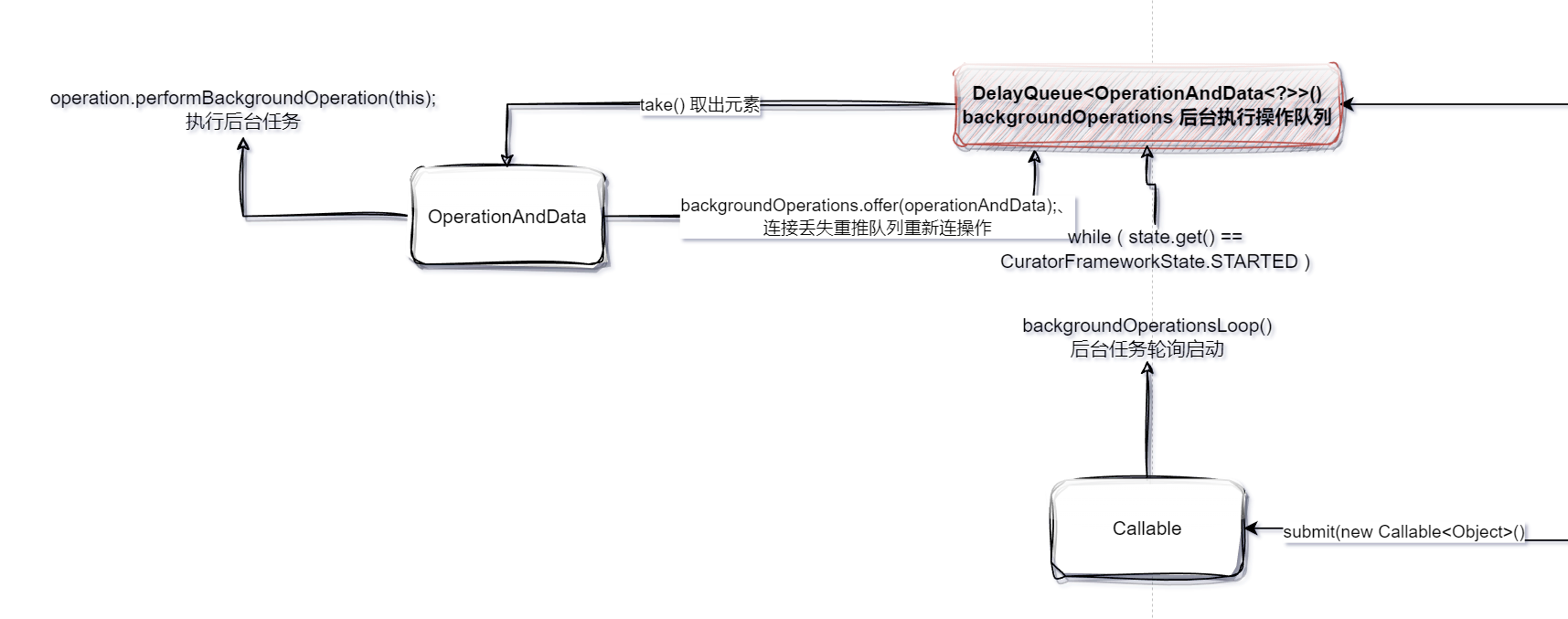
OperationAndData中的 BackgroundOperation ,封装各种常见ZK指令的构造器。
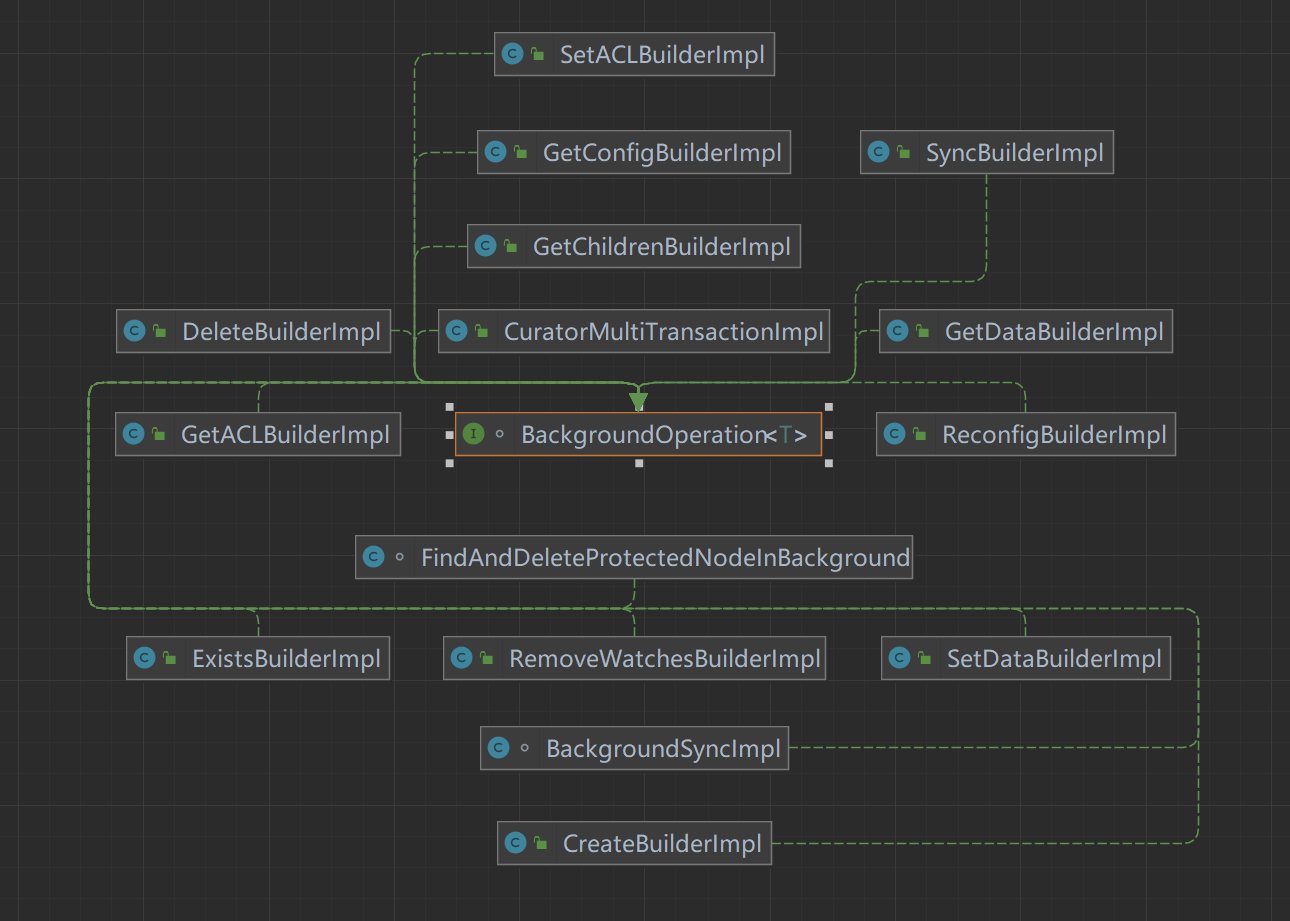
下面以 BackgroundOperation 作为切入点,看看它的构造器是如何实现的?
后台操作接口 BackgroundOperation< T >
BackgroundOperation 是后台操作接口的 顶级接口,其中只有一个方法,它接收 OperationAndData 作为请求参数。
org.apache.curator.framework.imps.BackgroundOperation
interface BackgroundOperation<T>
{
public void performBackgroundOperation(OperationAndData<T> data) throws Exception;
}
这种设计让我联想到 Executor 的设计(略显牵强),Runnable 是线程的执行操作分离抽象,与之对应的OperationAndData是对于后台操作的抽象。
public interface Executor {
void execute(Runnable command);
}
后台事件数据对象 OperationAndData
org.apache.curator.framework.imps.OperationAndData
OperationAndData 对象的代码略多,这里拆分介绍,首先来看下继承结构, OperationAndData 最终被存储在后台线程执行的操作队列backgroundOperations,backgroundOperations使用JDK原生并发延迟队列DelayQueue作为基础。
按照 DelayQueue 的设计存储要求,内部元素必须实现Delayed接口以支持延迟操作,除此之外, OperationAndData 还实现了 RetrySleeper 接口,从英文名称也可以大致猜出它是 对重试政策的抽象化。
class OperationAndData<T> implements Delayed, RetrySleeper
//后台线程执行的操作队列
backgroundOperations = new DelayQueue<OperationAndData<?>>();
下面来看下相关成员变量定义:
/**
初始化为0,每执行一次 reset() 重置,此计数器的值会+1
*/
private static final AtomicLong nextOrdinal = new AtomicLong();
/**
BackgroundOperation 相关引用
*/
private final BackgroundOperation<T> operation;
/**
后台操作的相关对象
*/
private final T data;
/**
异步后台操作
*/
private final BackgroundCallback callback;
/**
执行开始时间
*/
private final long startTimeMs = System.currentTimeMillis();
/**
错误回调
*/
private final ErrorCallback<T> errorCallback;
/**
重试次数
*/
private final AtomicInteger retryCount = new AtomicInteger(0);
/**
休眠时间
*/
private final AtomicLong sleepUntilTimeMs = new AtomicLong(0);
/**
执行顺序
*/
private final AtomicLong ordinal = new AtomicLong();
/**
上下文
*/
private final Object context;
/**
需要连接
*/
private final boolean connectionRequired;
重要的方法如下,执行后台操作就是调用operation.performBackgroundOperation(this);方法:
void callPerformBackgroundOperation() throws Exception
{
operation.performBackgroundOperation(this);
}
BackgroundOperation 的实现类非常多。这里举几个例子。
BackgroundSyncImpl
从单词意思来看,这个实现是负责后台同步的。
class BackgroundSyncImpl implements BackgroundOperation<String>
{
private final CuratorFrameworkImpl client;
private final Object context;
BackgroundSyncImpl(CuratorFrameworkImpl client, Object context)
{
this.client = client;
this.context = context;
}
@Override
public void performBackgroundOperation(final OperationAndData<String> operationAndData) throws Exception
{
final OperationTrace trace = client.getZookeeperClient().startAdvancedTracer("BackgroundSyncImpl");
final String data = operationAndData.getData();
client.getZooKeeper().sync
(
data,
new AsyncCallback.VoidCallback()
{
@Override
public void processResult(int rc, String path, Object ctx)
{
trace.setReturnCode(rc).setRequestBytesLength(data).commit();
CuratorEventImpl event = new CuratorEventImpl(client, CuratorEventType.SYNC, rc, path, null, ctx, null, null, null, null, null, null);
client.processBackgroundOperation(operationAndData, event);
}
},
context
);
}
}
这里通过构造CuratorEventImpl实现类,把operationAndData和event事件传给CuratorFrameworkImpl。
RemoveWatchesBuilderImpl
RemoveWatchesBuilderImpl定义了删除Watcher监听器的后台操作,简单看下相关代码实现。
public class RemoveWatchesBuilderImpl implements RemoveWatchesBuilder, RemoveWatchesType, RemoveWatchesLocal, BackgroundOperation<String>, ErrorListenerPathable<Void>
{
private CuratorFrameworkImpl client;
private Watcher watcher;
private CuratorWatcher curatorWatcher;
private WatcherType watcherType;
private boolean guaranteed;
private boolean local;
private boolean quietly;
private Backgrounding backgrounding;
@Override
public void performBackgroundOperation(final OperationAndData<String> operationAndData)
throws Exception
{
try
{
final TimeTrace trace = client.getZookeeperClient().startTracer("RemoteWatches-Background");
AsyncCallback.VoidCallback callback = new AsyncCallback.VoidCallback()
{
@Override
public void processResult(int rc, String path, Object ctx)
{
trace.commit();
CuratorEvent event = new CuratorEventImpl(client, CuratorEventType.REMOVE_WATCHES, rc, path, null, ctx, null, null, null, null, null, null);
client.processBackgroundOperation(operationAndData, event);
}
};
ZooKeeper zkClient = client.getZooKeeper();
// 命名空间 Watch
NamespaceWatcher namespaceWatcher = makeNamespaceWatcher(operationAndData.getData());
if(namespaceWatcher == null)
{
// ZK 客户端移除 Watch
zkClient.removeAllWatches(operationAndData.getData(), watcherType, local, callback, operationAndData.getContext());
}
else
{
zkClient.removeWatches(operationAndData.getData(), namespaceWatcher, watcherType, local, callback, operationAndData.getContext());
}
}
catch ( Throwable e )
{
backgrounding.checkError(e, null);
}
}
}
执行后台事件 CuratorFrameworkImpl#processBackgroundOperation
所有的后台任务操作都会回调Curator 实例CuratorFrameworkImpl的 processBackgroundOperation方法,下面简单分析相关方法细节。
org.apache.curator.framework.imps.CuratorFrameworkImpl#processBackgroundOperation
主要的逻辑如下:
- 判断是否初次执行,初次执行会进行连接状态检查呵护后续的重试判断处理。
- 校验是否需要重试。
- 检查是否发送回调。
- 监听器事件回调通知(这里会进行事件通知回调)。
<DATA_TYPE> void processBackgroundOperation(OperationAndData<DATA_TYPE> operationAndData, CuratorEvent event)
{
boolean isInitialExecution = (event == null);
// 如果是初次执行
if ( isInitialExecution )
{
// 初次执行会进行连接状态检查呵护后续的重试判断处理
performBackgroundOperation(operationAndData);
return;
}
boolean doQueueOperation = false;
do
{
// 校验是否需要重试
if ( RetryLoop.shouldRetry(event.getResultCode()) )
{
doQueueOperation = checkBackgroundRetry(operationAndData, event);
break;
}
// 检查是否发送回调
if ( operationAndData.getCallback() != null )
{
// 发送后台回调
sendToBackgroundCallback(operationAndData, event);
break;
}
// 监听器事件回调通知
processEvent(event);
}
while ( false );
if ( doQueueOperation )
{
queueOperation(operationAndData);
}
}
真心看不懂 while ( false ); 这的写法=-=。
以上简单分析了后台任务构造器以及如何执行,设计比较好懂,这里就不做过多分析了。
Curator 节点操作
创建节点API
这里以个人阅读的 Curator 4.3.0 版本为例,创建节点的 API 涉及下面几个组件:
- CuratorFramework:
public CreateBuilder create();
- CreateBuilder:
public ProtectACLCreateModePathAndBytesable<String> createParentsIfNeeded();
- CreateModable:
public T withMode(CreateMode mode);
- PathAndBytesable< T>:
public T forPath(String path, byte[] data) throws Exception;public T forPath(String path) throws Exception;
下面是几个常见的API使用Demo:
创建一个节点,初始内容为空
client.create().forPath(path);
// 创建一个节点,初始内容为空
client.create().forPath("/tmp");
从结果可以看到,如果没有设置节点属性,那么Curator默认创建的是持久节点。
创建一个节点,附带初始内容
// 创建一个节点,附带初始内容
client.create().forPath("/tmp", "init".getBytes());;
和上面的区别就是在对应的节点写入内容,注意 Curator 使用了 Zookeeper 的原始API风格。
// KeeperErrorCode = NodeExists for /tmp
由于上面已经创建过节点,这里创建节点出现报错,我们在Pretty客户端中执行删除节点操作。删除之后重新执行,"/tmp"节点被正确创建。
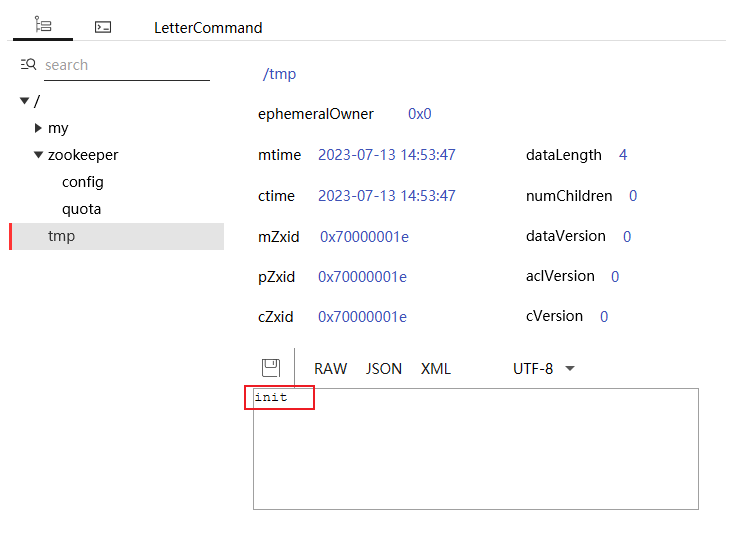
创建一个临时节点,初始内容为空
client.create().withMode(CreateMode.EPHEMERAL).forPath(path);
临时节点属于会话级别,我们在编写Demo代码的时候,如果没有手动 close 客户端,那么服务端会判断客户端会在会话超时之后自动释放临时节点。
临时节点的好处是即使ZK集群宕机,也可以保证及时释放,防止锁长期占用,适合作为分布式锁设计使用。
// 创建一个临时节点,初始内容为空
client.create().withMode(CreateMode.EPHEMERAL).forPath("/temp");
// 如果立即Close,那么临时节点会立即释放
client.close();
如果我们 close 客户端,那么临时节点的创建和销毁会立即触发,在 prettyZoo 看来就是“什么也没发送过”。
创建一个临时节点,并自动递归创建父节点
使用ZooKeeper的过程中,开发人员经常会碰到NoNodeException异常,其中一个可能的原因就是试图对一个不存在的父节点创建子节点。
// 试图对一个不存在的父节点创建子节点
client.create().withMode(CreateMode.EPHEMERAL).forPath("/temp/childNode");
// 报错KeeperErrorCode = NoNode for /temp/childNode
在使用Curator之后,通过调用creatingParentsIfNeeded接口,Curator就能够自动递归创建所有需要的父节点:
lient.create().creatingParentsIfNeeded().withMode(CreateMode.EPHEMERAL).forPath(path);
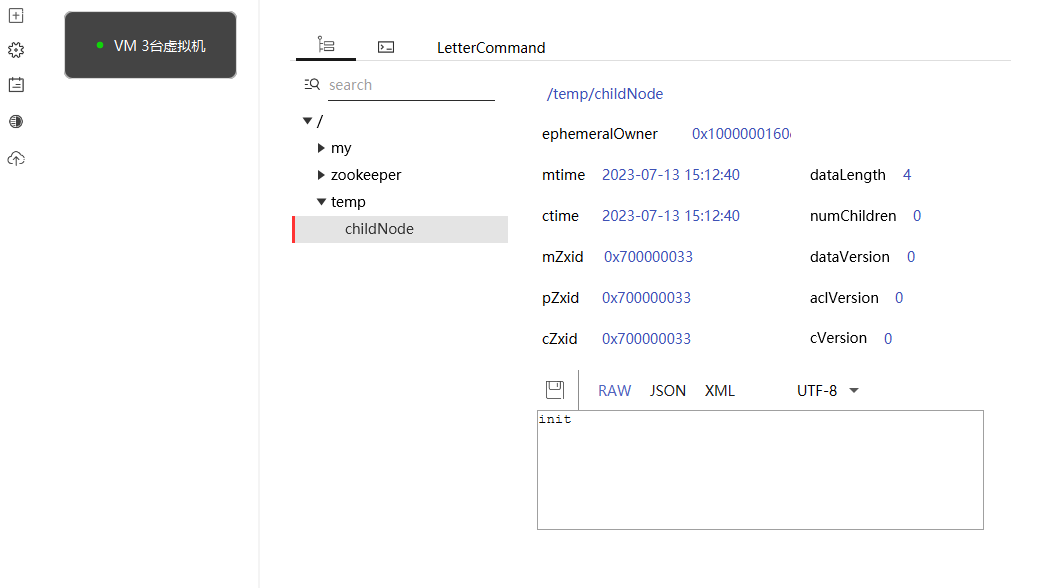
创建节点源码分析
节点API的涉及都比较简单,CreateBuilder 的继承结构图如下:
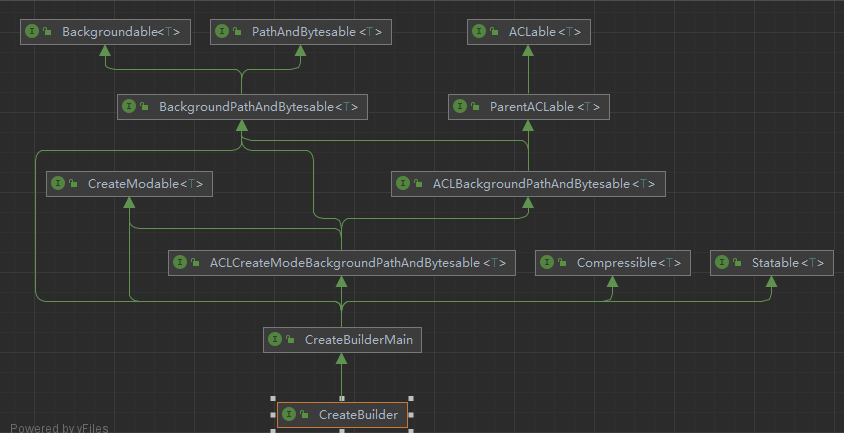
CreateBuilder 的对应实现类为 CreateBuilderImpl,我们通过一串API调用Demo来简单分析构建过程:
client.create().creatingParentsIfNeeded().withMode(CreateMode.EPHEMERAL).forPath("/temp/childNode", "init".getBytes());
org.apache.curator.framework.imps.CuratorFrameworkImpl#create
- 检查ZK的连接状态。
- new CreateBuilderImpl,,这里的 this 为 CuratorFrameworkImpl ,也就是client 客户端实例。
public CreateBuilder create()
{
// 检查ZK的连接状态
checkState();
// new构造器, this 为 CuratorFrameworkImpl 也就是client 客户端实例
return new CreateBuilderImpl(this);
}
org.apache.curator.framework.imps.CreateBuilderImpl#creatingParentsIfNeeded
下面代码的关键是createParentsIfNeeded = true;这一行,其他代码可以忽略。
@Override
public ProtectACLCreateModeStatPathAndBytesable<String> creatingParentsIfNeeded()
{
createParentsIfNeeded = true;
return new ProtectACLCreateModeStatPathAndBytesable<String>()
{
//....
};
}
withMode(CreateMode.EPHEMERAL)
这一部分属于ZK的客户端提供的,CreateMode 一般用的比较多的是临时节点。
具体使用这里不一一介绍,简单看下源码中的英文注释很容易理解不同模式的作用。
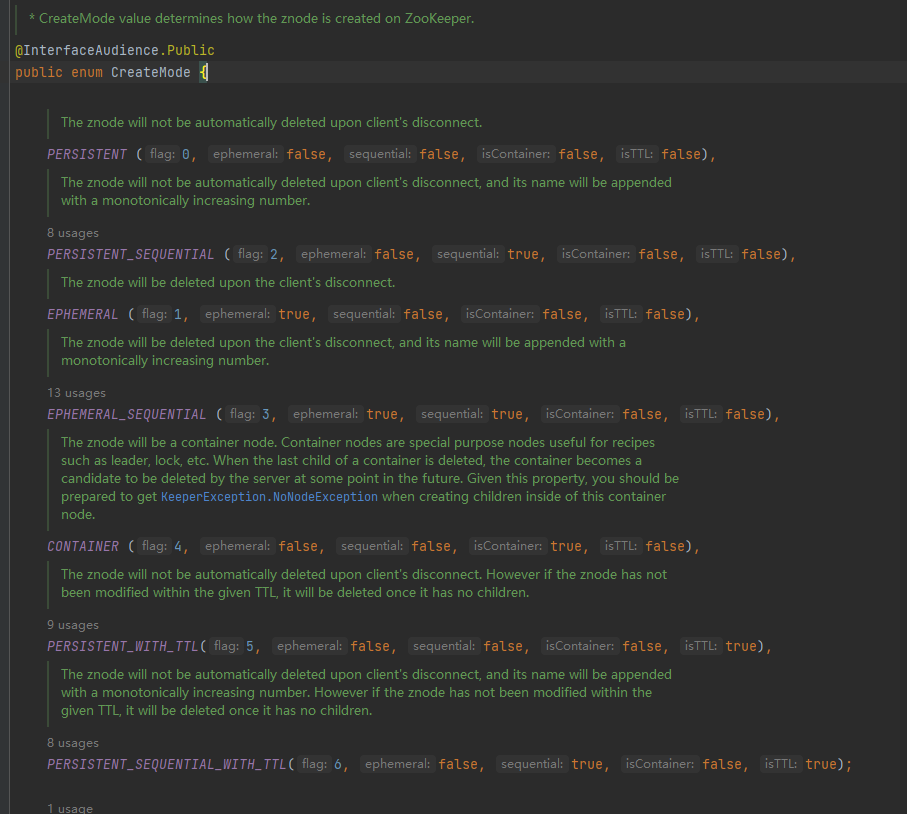
默认为 PERSISTENT 持久节点。
org.apache.curator.framework.imps.CreateBuilderImpl#forPath(java.lang.String, byte[])
forPath 对应了创建节点的最终操作,这里大致逻辑如下:
- 判断是否需要压缩。
- acl 权限检查。
- 判断是否执行回调。
- 核心:使用 ZooKeeper 的顺序节点生成全局唯一 ID。
@Override
public String forPath(final String givenPath, byte[] data) throws Exception
{
// 判断是否需要压缩
if ( compress )
{
data = client.getCompressionProvider().compress(givenPath, data);
}
final String adjustedPath = adjustPath(client.fixForNamespace(givenPath, createMode.isSequential()));
List<ACL> aclList = acling.getAclList(adjustedPath);
client.getSchemaSet().getSchema(givenPath).validateCreate(createMode, givenPath, data, aclList);
String returnPath = null;
// 后台回调
if ( backgrounding.inBackground() )
{
pathInBackground(adjustedPath, data, givenPath);
}
else
{
// forpath 会走这一段逻辑
//
String path = protectedPathInForeground(adjustedPath, data, aclList);
returnPath = client.unfixForNamespace(path);
}
return returnPath;
}
顺着String path = protectedPathInForeground(adjustedPath, data, aclList);这一段代码一路往下探,找到对应截图部分的代码:
org.apache.curator.framework.imps.CreateBuilderImpl#pathInForeground
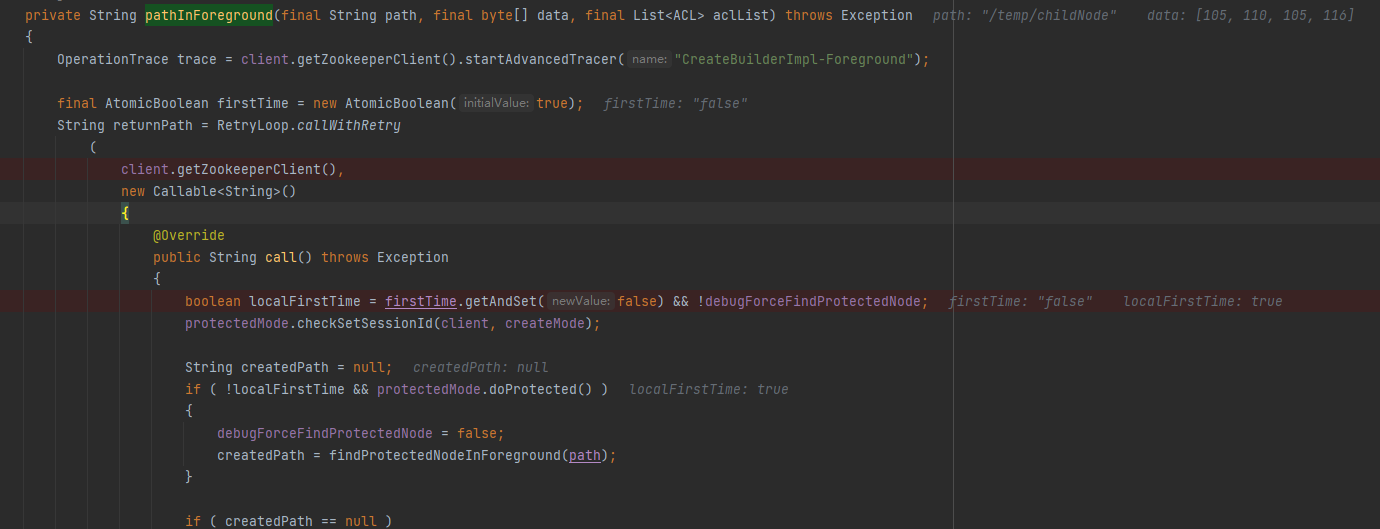
这里使用RetryLoop.callWithRetry嵌套了一个 Callable操作,但是这个操作并没有做任何多线程操作,而是进行了result = proc.call();调用???不太理解这一段封装处理的含义,于是看了下JavaDoc解释:
在Zookeeper上执行操作的机制,可安全防止断开连接和 "可恢复 "错误。如果在操作过程中出现异常,RetryLoop将处理该异常,检查当前重试策略,并尝试重新连接或重新抛出异常。
典型用法如下:
RetryLoop retryLoop = client.newRetryLoop();
while ( retryLoop.shouldContinue() )
{
try
{
// do your work
ZooKeeper zk = client.getZooKeeper(); // it's important to re-get the ZK instance in case there was an error and the instance was re-created
retryLoop.markComplete();
}
catch ( Exception e )
{
retryLoop.takeException(e);
}
}
说白了,它主要封装了类似下面这样的操作:
int count = 0;
while (count < 3){
try{
// ZooKeeper zk = client.getZooKeeper();
// zk.create(final String path, byte data[], List<ACL > acl,
// CreateMode createMode)
break;
}catch (Exception e){
count++;
continue;
}
}
结果就是把重试的重复代码做了一个封装,其中call()方法则是具体委托ZK的客户端进行节点的创建操作了,这里的ttl为 -1。
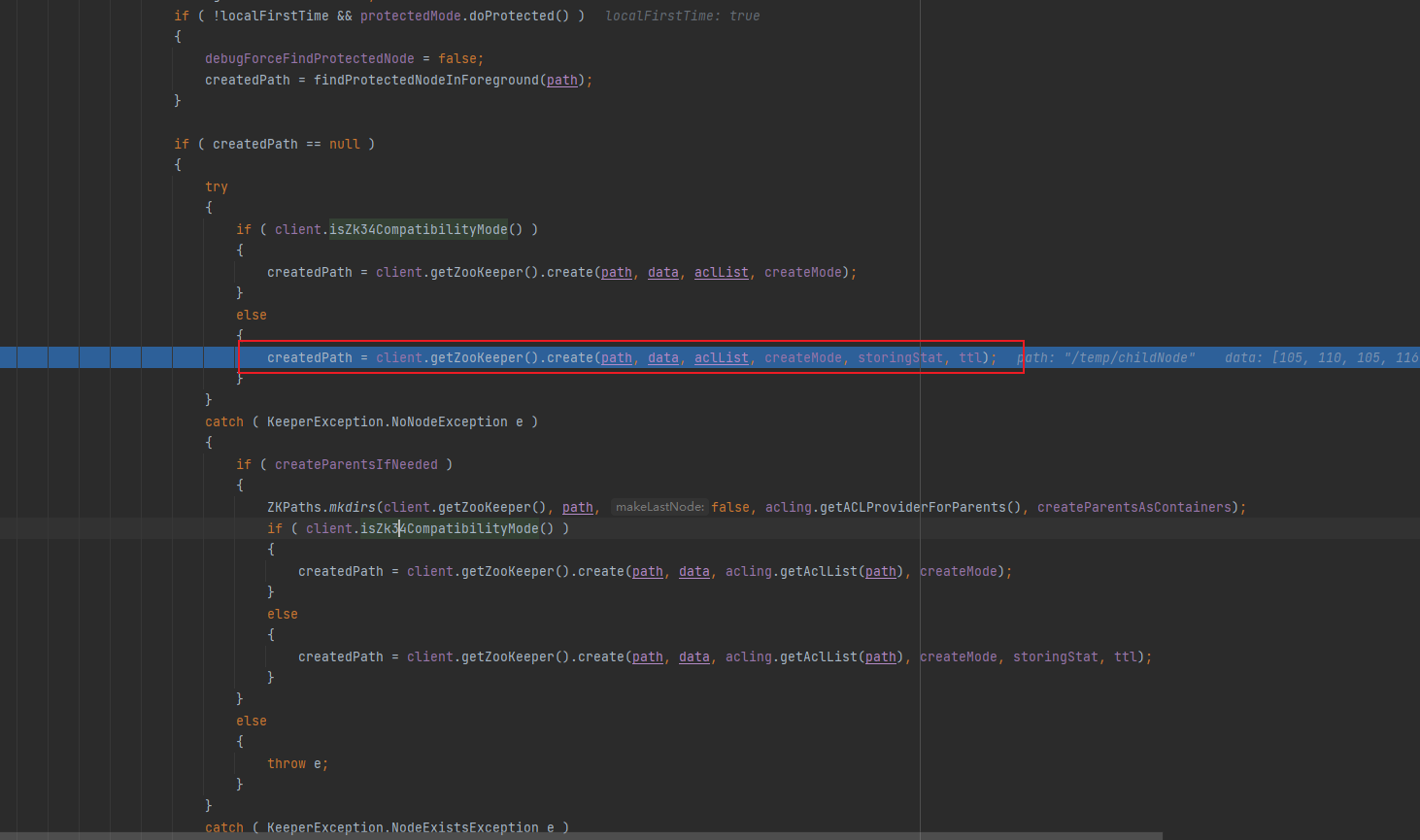
截图对应代码如下:
createdPath = client.getZooKeeper().create(path, data, aclList, createMode, storingStat, ttl);
此外,个人在阅读代码过程中,发现在进行path的字符串拼接操作的时候,这里有一个小小的 StringBuilder 优化。
// Avoid internal StringBuilder's buffer reallocation by specifying the max path length
StringBuilder path = new StringBuilder(maxPathLength);
至此,创建节点的相关操作源码已经了解,下面我们来过一下删除的相关API操作和源码。
删除节点API
- CuratorFramework:
public CreateBuilder create();
- DeleteBuilder
- ChildrenDeletable
public BackgroundVersionable deletingChildrenIfNeeded();
- PathAndBytesable< T>:
public T forPath(String path, byte[] data) throws Exception;- `public T forPath(String path) throws Exception;
DeleteBuilder 的继承结构图如下:
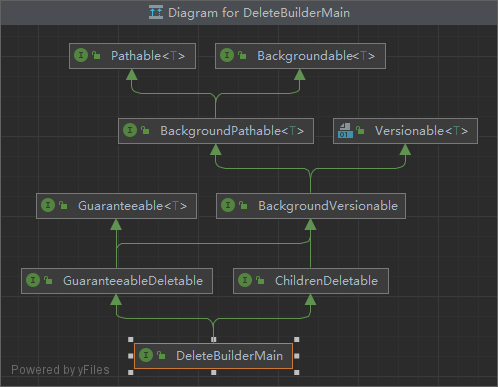
删除节点的API较为简单,这里直接贴出相关的Demo代码。
// 先创建一个持久节点
client.create().forPath("/create");
// 删除节点
client.delete().forPath("/create");
// 如果节点不存在:KeeperErrorCode = NoNode for /create
// 先创建一个持久节点
client.create().creatingParentsIfNeeded().forPath("/create/child0");
client.create().creatingParentsIfNeeded().forPath("/create/child1");
// 删除并且判断是否需要同时删除子节点,如果有子节点并且确定一并删除需要添加
deletingChildrenIfNeededclient.delete().deletingChildrenIfNeeded().forPath("/create");

删除节点源码分析
由于基本的CRUDE操作逻辑实现比较类似,这里主要介绍下deletingChildrenIfNeeded是如何作用的,处理思路是在访问ZK出现NotEmptyException异常之后,这里在异常中判断是否设置删除子节点的操作并且重新发起请求。
catch ( KeeperException.NotEmptyException e )
{
if ( deletingChildrenIfNeeded )
{
ZKPaths.deleteChildren(client.getZooKeeper(), path, true);
}
else
{
throw e;
}
}
ZKPaths.deleteChildren(client.getZooKeeper(), path, true);这个工具方法具体操作是利用递归的方式遍历所有子ZNode,然后挨个执行delete方法删除。
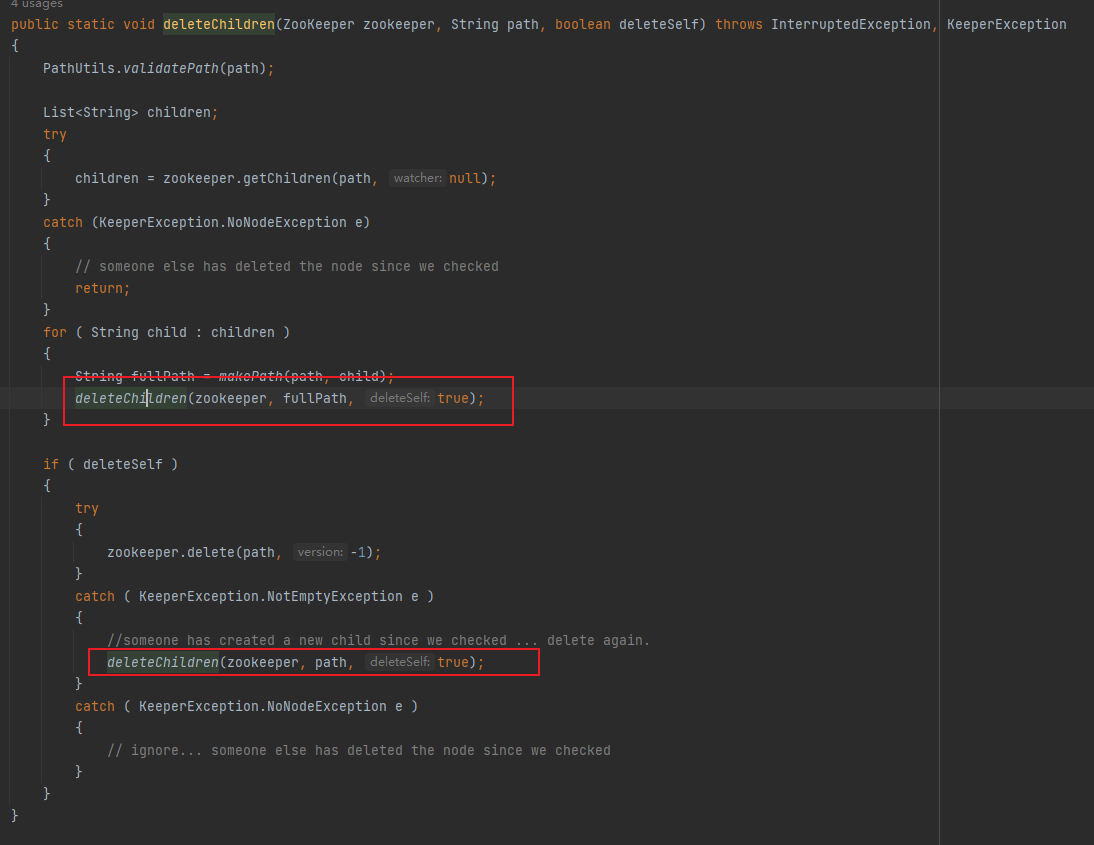
获取节点API
- CuratorFramework:
public GetDataBuilder getData();
- GetDataBuilder
- GetChildrenBuilder
public GetChildrenBuilder getChildren();
- PathAndBytesable< T>:
- `public T forPath(String path) throws Exception;
GetDataBuilder 的类继承结构图如下:
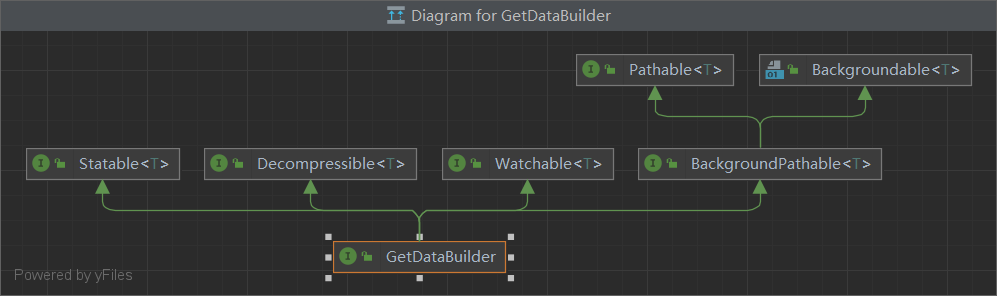
下面是简单的API使用:
client.create().creatingParentsIfNeeded().withMode(CreateMode.CONTAINER).forPath("/app2", "Test".getBytes());
//1、查询数据:get
byte[] data = client.getData().forPath("/app2");
// KeeperErrorCode = NoNode for /app1
log.info("查询数据 {}", new String(data));
// 运行结果:查询数据 Test
//2、查询子节点:ls
List<String> list = client.getChildren().forPath("/app2");
log.info("查询子节点 {}", list);
//运行结果:查询子节点 []
client.close();
//3、查询节点状态信息:ls -s
Stat stat = new Stat();
client.getData().storingStatIn(stat).forPath("/app2");
获取节点源码分析
获取节点的代码如下:
public byte[] forPath(String path) throws Exception
{
client.getSchemaSet().getSchema(path).validateWatch(path, watching.isWatched() || watching.hasWatcher());
path = client.fixForNamespace(path);
byte[] responseData = null;
if ( backgrounding.inBackground() )
{
client.processBackgroundOperation(new OperationAndData<String>(this, path, backgrounding.getCallback(), null, backgrounding.getContext(), watching), null);
}
else
{
responseData = pathInForeground(path);
}
return responseData;
}
前台调用方法操作如下:
private byte[] pathInForeground(final String path) throws Exception
{
OperationTrace trace = client.getZookeeperClient().startAdvancedTracer("GetDataBuilderImpl-Foreground");
byte[] responseData = RetryLoop.callWithRetry
(
client.getZookeeperClient(),
new Callable<byte[]>()
{
@Override
public byte[] call() throws Exception
{
byte[] responseData;
if ( watching.isWatched() )
{
responseData = client.getZooKeeper().getData(path, true, responseStat);
}
else
{
responseData = client.getZooKeeper().getData(path, watching.getWatcher(path), responseStat);
watching.commitWatcher(KeeperException.NoNodeException.Code.OK.intValue(), false);
}
return responseData;
}
}
);
trace.setResponseBytesLength(responseData).setPath(path).setWithWatcher(watching.hasWatcher()).setStat(responseStat).commit();
return decompress ? client.getCompressionProvider().decompress(path, responseData) : responseData;
}
修改节点API
- CuratorFramework:
public SetDataBuilder setData();
- SetDataBuilder
- PathAndBytesable< T>:
- `public T forPath(String path) throws Exception;
//1、修改节点数据(基本修改)
curatorFramework.setData().forPath("/app1", "333".getBytes(StandardCharsets.UTF_8));
//2、根据版本号修改
Stat stat1 = new Stat();
curatorFramework.getData().storingStatIn(stat1).forPath("/app1");
curatorFramework.setData().withVersion(stat1.getVersion()).forPath("/app1", "itcast".getBytes(StandardCharsets.UTF_8));
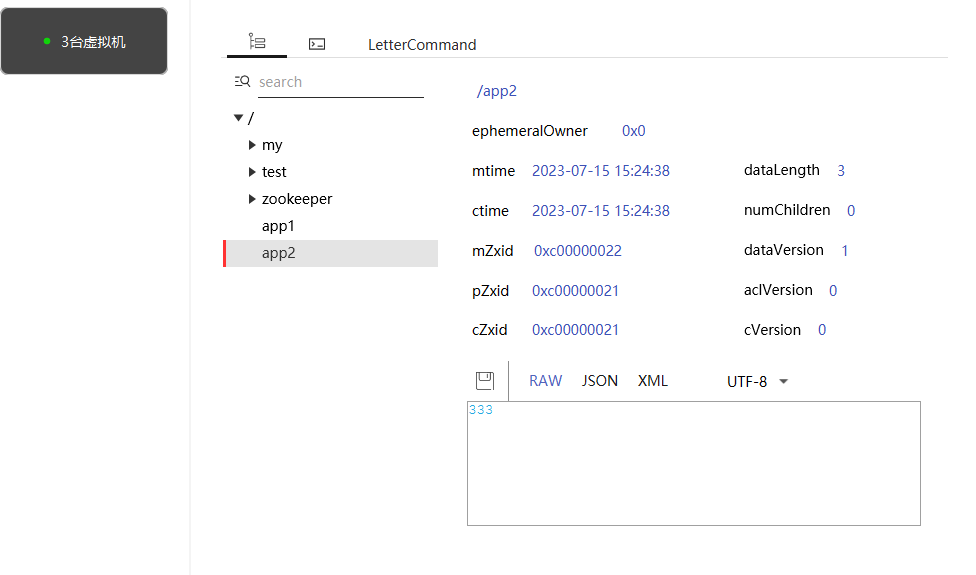
修改节点源码分析
设计思路都是类似的,这里挑选forPath的相关代码进行展示。
@Override
public Stat forPath(String path, byte[] data) throws Exception
{
client.getSchemaSet().getSchema(path).validateGeneral(path, data, null);
if ( compress )
{
data = client.getCompressionProvider().compress(path, data);
}
path = client.fixForNamespace(path);
Stat resultStat = null;
if ( backgrounding.inBackground() )
{
client.processBackgroundOperation(new OperationAndData<>(this, new PathAndBytes(path, data), backgrounding.getCallback(), null, backgrounding.getContext(), null), null);
}
else
{
resultStat = pathInForeground(path, data);
}
return resultStat;
}
监听节点
在使用原生的ZooKeeper的时候,是可以使用Watcher对节点进行监听的,但是唯一不方便的是一个Watcher只能生效一次,也就是说每次进行监听回调之后我们需要自己重新的设置监听才能达到永久监听的效果。
Curator在这方面做了优化,Curator引入了Cache的概念用来实现对ZooKeeper服务器端进行事件监听。Cache是Curator对事件监听的包装,其对事件的监听可以近似看做是本地缓存视图和远程ZooKeeper视图的对比过程。而且Curator会自动再次监听,我们就不需要自己手动的重复监听了。
Curator支持的cache种类有3种Path Cache,Node Cache,Tree Cache。
1)Path Cache
Path Cache用来观察ZNode的子节点并缓存状态,如果ZNode的子节点被创建,更新或者删除,那么Path Cache会更新缓存,并且触发事件给注册的监听器。
Path Cache是通过PathChildrenCache类来实现的,监听器注册是通过PathChildrenCacheListener。
2)Node Cache
Node Cache用来观察ZNode自身,如果ZNode节点本身被创建,更新或者删除,那么Node Cache会更新缓存,并触发事件给注册的监听器。
Node Cache是通过NodeCache类来实现的,监听器对应的接口为NodeCacheListener。
3)Tree Cache
可以看做是上两种的合体,Tree Cache观察的是所有节点的所有数据。
Curator 拥有一套在节点上进行监听的API,具体操作是利用节点缓存上的监听器监听节点的数据变化。监听节点主要分为下面几个操作:
监听单个节点API
监听单个节点的案例代码如下:
//----------------- 监听单个节点 -----------------------------------
//1. 创建NodeCache对象
final NodeCache nodeCache = new NodeCache(client,"/app1");
//2. 注册监听
nodeCache.getListenable().addListener(new NodeCacheListener() {
@Override
public void nodeChanged() throws Exception {
System.out.println("节点变化了~");
//获取修改节点后的数据
byte[] data = nodeCache.getCurrentData().getData();
System.out.println(new String(data));
}
});
//3. 开启监听.如果设置为true,则开启监听是,加载缓冲数据
nodeCache.start(true);
监听子节点API
//----------------- 监听子节点 -----------------------------------
//1.创建监听对象
PathChildrenCache pathChildrenCache = new PathChildrenCache(client,"/app2",true);
//2. 绑定监听器
pathChildrenCache.getListenable().addListener(new PathChildrenCacheListener() {
@Override
public void childEvent(CuratorFramework client, PathChildrenCacheEvent event) {
System.out.println("子节点变化了~");
System.out.println(event);
//监听子节点的数据变更,并且拿到变更后的数据
//1.获取类型
PathChildrenCacheEvent.Type type = event.getType();
//2.判断类型是否是update
if(type.equals(PathChildrenCacheEvent.Type.CHILD_UPDATED)){
System.out.println("数据变了!!!");
byte[] data = event.getData().getData();
System.out.println(new String(data));
}
}
});
//3. 开启
pathChildrenCache.start();
监听节点树
//----------------- 监听节点树 -----------------------------------
//1. 创建监听器
TreeCache treeCache = new TreeCache(client,"/app2");
//2. 注册监听
treeCache.getListenable().addListener(new TreeCacheListener() {
@Override
public void childEvent(CuratorFramework client, TreeCacheEvent event) {
System.out.println("节点变化了");
System.out.println(event);
}
});
//3. 开启
treeCache.start();
NodeCache 源码解析
有关节点监听机制,和ZK 的 watch 机制也有关,下面来简单解析 NodeCache 相关源码实现。
初始化部分
public NodeCache(CuratorFramework client, String path, boolean dataIsCompressed)
{
this.client = client.newWatcherRemoveCuratorFramework();
this.path = PathUtils.validatePath(path);
this.dataIsCompressed = dataIsCompressed;
}
关键部分是构建了WatcherRemovalFacade监听器的门面对象,在Cache 发生变化之后会触发事件监听回调通知。
return new WatcherRemovalFacade(this);
start() 启动
NodeCache 使用必须要结合 xxx.start(); 方法。
public void start(boolean buildInitial) throws Exception
{
// 检查启动状态
Preconditions.checkState(state.compareAndSet(State.LATENT, State.STARTED), "Cannot be started more than once");
// 增加连接状态监听器
client.getConnectionStateListenable().addListener(connectionStateListener);
// 初始化处理
if ( buildInitial )
{
client.checkExists().creatingParentContainersIfNeeded().forPath(path);
internalRebuild();
}
reset();
}
我们需要注意client.getConnectionStateListenable().addListener(connectionStateListener);这一串代码实际上是注册到 CuratorFrameworkImpl内部的连接状态管理器 ConnectionStateManager。
连接状态监听器的实现如下,主要是解决了原生客户端Watch只能使用一次的问题,这里通过监听状态变化并且结合CAS操作完成更新。
private ConnectionStateListener connectionStateListener = new ConnectionStateListener()
{
@Override
public void stateChanged(CuratorFramework client, ConnectionState newState)
{
if ( (newState == ConnectionState.CONNECTED) || (newState == ConnectionState.RECONNECTED) )
{
if ( isConnected.compareAndSet(false, true) )
{
try
{
reset();
}
catch ( Exception e )
{
ThreadUtils.checkInterrupted(e);
log.error("Trying to reset after reconnection", e);
}
}
}
else
{
isConnected.set(false);
}
}
};
上下两部分代码都调用了reset()方法,它在内部传递了两个对象 监听对象watcher 以及 回调对象backgroundCallback(异步回调),前者在一开始启动就会注册进来,而后者则需要返回数据的时候执行回调函数。
// reset() 方法内部实现
private void reset() throws Exception
{
if ( (state.get() == State.STARTED) && isConnected.get() )
{
client.checkExists().creatingParentContainersIfNeeded().usingWatcher(watcher).inBackground(backgroundCallback).forPath(path);
}
}
监听对象watcher 所干的事情就是不断重新执行reset方法,把监听器重新注册到对应的节点上面。
private Watcher watcher = new Watcher()
{
@Override
public void process(WatchedEvent event)
{
try
{
reset();
}
catch(Exception e)
{
ThreadUtils.checkInterrupted(e);
handleException(e);
}
}
};
异步回调逻辑
异步回调的任务是判断当前事件是获取数据还是检查是否存在,之后进行本地缓存数据的变更,以及刷新本地缓存数据。
private final BackgroundCallback backgroundCallback = new BackgroundCallback()
{
@Override
public void processResult(CuratorFramework client, CuratorEvent event) throws Exception
{
processBackgroundResult(event);
}
};
private void processBackgroundResult(CuratorEvent event) throws Exception
{
// 当发生获取数据或者是判断节点是否存在时候进行监听
switch ( event.getType() )
{
// 响应状态为ok时,将刷新本地缓存的数据
case GET_DATA:
{
if ( event.getResultCode() == KeeperException.Code.OK.intValue() )
{
// 获取监听到的数据变动集合
ChildData childData = new ChildData(path, event.getStat(), event.getData());
// 刷新本地缓存数据
setNewData(childData);
}
break;
}
case EXISTS:
{
if ( event.getResultCode() == KeeperException.Code.NONODE.intValue() )
{
setNewData(null);
}
else if ( event.getResultCode() == KeeperException.Code.OK.intValue() )
{
if ( dataIsCompressed )
{
client.getData().decompressed().usingWatcher(watcher).inBackground(backgroundCallback).forPath(path);
}
else
{
client.getData().usingWatcher(watcher).inBackground(backgroundCallback).forPath(path);
}
}
break;
}
}
}
调用setNewData(childData); 之后会刷新本地缓存数据:
private void setNewData(ChildData newData) throws InterruptedException
{
// 比较最新数据和变更前的数据,查看是否有变更
ChildData previousData = data.getAndSet(newData);
if ( !Objects.equal(previousData, newData) )
{
listeners.forEach
(
// 用节点监听容器内部的监听器处理目录变更事件
new Function<NodeCacheListener, Void>()
{
@Override
public Void apply(NodeCacheListener listener)
{
try
{
listener.nodeChanged();
}
catch ( Exception e )
{
ThreadUtils.checkInterrupted(e);
log.error("Calling listener", e);
}
return null;
}
}
);
if ( rebuildTestExchanger != null )
{
try
{
rebuildTestExchanger.exchange(new Object());
}
catch ( InterruptedException e )
{
Thread.currentThread().interrupt();
}
}
}
}
如何触发注册的监听器?
我们回到 start() 启动这部分代码,来看下如何触发监听器:
// 增加连接状态监听器
client.getConnectionStateListenable().addListener(connectionStateListener);
这里注册到 CuratorFrameworkImpl内部的连接状态管理器 ConnectionStateManager,具体的注册过程如下:
public Listenable<ConnectionStateListener> getListenable()
{
return listeners;
}
这个 listeners 成员变量定义如下,可以看到它是一个监听器的管理容器:
private final UnaryListenerManager<ConnectionStateListener> listeners;
这个容器什么时候会通知注册在其中的监听器?
答案是在出现状态变更的时候:
org.apache.curator.framework.state.ConnectionStateManager#processEvents
listeners.forEach(listener -> listener.stateChanged(client, newState));
这部分内容在【Zookeeper】Apach Curator 框架源码分析:初始化过程(一)【Ver 4.3.0】 的通知机制中有详细介绍【参考:注册 ConnectionStateListener 通知部分】。
这里节省读者时间,我们直接看一个草图:
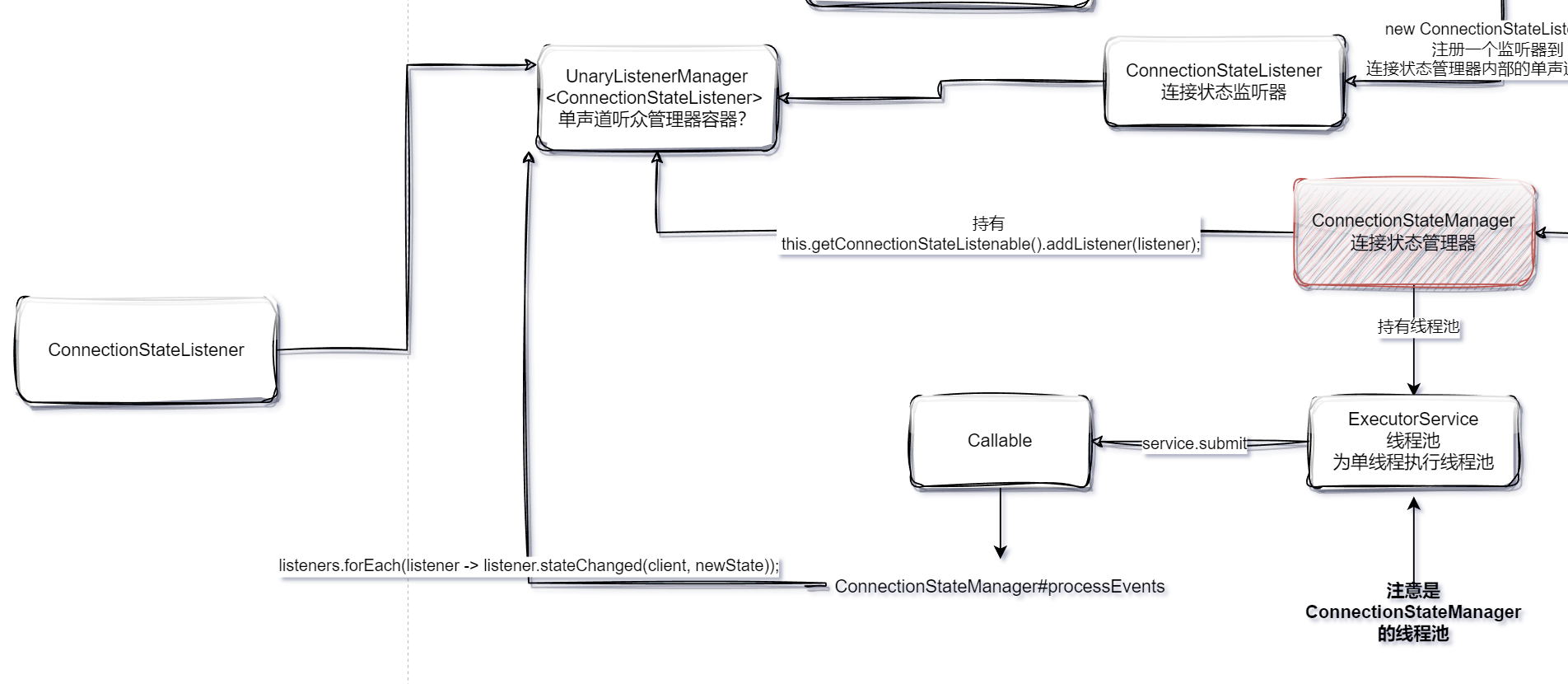
ConnectionStateManager 调用start 启动之后,会开启一个单线程线程池异步的轮询,并且在状态变更的时候回调UnaryListenerManager容器中注册的监听器。
以上就是关于如何触发注册的监听器的问题解答。
小结
节点监听缓存 NodeCache,内部关联Curator框架客户端CuratorFramework,通过节点内部的监听器容器 listeners(ListenerContainer)存放节点监听器。
添加节点监听器,实际上是注册到节点缓存的节点监听器容器ListenerContainer(CuratorFrameworkImpl内部的成员添加节点监听器,注册到节点缓存的节点监听器容器ListenerContainer)中。
启动节点监听器,注册节点监听器到CuratorFramework实现的连接状态管理器中ConnectionStateManager,如果需要则重新构建节点数据,同时重新注册节点监听器 CuratorWatcher,如果连接状态有变更, 重新注册节点监听器CuratorWatcher。
以上内容需要区分添加和启动过程,两者分别存储在两个不同的容器当中,这个添加过程类似先把鸡蛋放自己的篮子,启动之后再把自己篮子的鸡蛋倒入”机器“中运作。
当然上面的API没有分析PathChildrenCache,这里进行简单描述大致了解即可。
子目录监听器PathChildrenCache,主要成员变量为客户端框架实现CuratorFramework,子路径监听器容器 ListenerContainer(ListenerAble),及事件执行器CloseableExecutorService,事件操作集Set。
一级目录监听器PathChildrenCache,启动过程主要是注册连接状态监听器ConnectionStateListener,连接状态监听器根据连接状态来添加事件EventOperation和RefreshOperation操作到操作集。
事件操作EventOperation:主要是触发监听器的子目录事件操作;
事件刷新操作 RefreshOperation:主要是完成子目录的添加和刷新事件,并重新注册子目录监听器。 然后根据启动模式来决定是重添加事件操作,刷新、事件操作,或者重新构建,即刷新缓存路径数据,并注册刷新操作。
写在最后
这里还是吐槽 Curator 这代码设计挺绕的,还有很多贴合设计模式的古怪代码。
上一篇
[【Zookeeper】Apach Curator 框架源码分析:初始化过程(一)【Ver 4.3.0】]
参考资料
(3条消息) Curator之创建节点_curator创建节点_孤芳不自賞的博客-CSDN博客
ZooKeeper相关概念总结(入门) | JavaGuide(Java面试 + 学习指南)
https://www.jianshu.com/p/a864bf8a6c3c
https://donaldhan.github.io/zookeeper/2018/06/29/curator%E7%9B%AE%E5%BD%95%E7%9B%91%E5%90%AC.html#%E8%8A%82%E7%82%B9%E7%9B%91%E5%90%AC%E5%99%A8nodecache

 发表于 2023-9-9 07:45
发表于 2023-9-9 07:45



