本帖最后由 5698741236ls 于 2023-10-19 15:13 编辑
作用:为没有字幕的视频生成字幕,无需联网,本地运行
基本步骤:
- 安装python
安装最新版就好
- 安装ffmepg
下载自己系统对应的版本,windows是win64那个,将下载的压缩包解压后得到的ffmpeg.exe ffplay.exe ffprobe.exe放到一个你想放的目录,然后将这个目录的路径加入环境变量的Path里,不知道添加就百度一下
- 安装cuda
安装最新的就好;在下载页面选自己的对应配置就可以下载了
- 安装PyTouch
安装最新的就好; 在下载页面选最新的cuda版本,然后会有一个Run this Command,在cmd运行即可安装;例如:pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
- 安装whisper (附:whisper源页面)
打开cmd,运行 pip install git+https://github.com/openai/whisper.git就可以安装好了
使用方法:打开cmd -> 输入 whisper 视频路径 --output_format=srt --model=模型名称 就可以开始运行了
- 视频路径直接把视频拖进来就可以
- 模型根据自己的配置选,模型越大,显存要求越高,越精确,速度越慢
| 模型名称 |
模型大小 |
English-only model |
Multilingual model |
显存需求 |
速度 |
| tiny |
39 M |
tiny.en |
tiny |
~1 GB |
~32x |
| base |
74 M |
base.en |
base |
~1 GB |
~16x |
| small |
244 M |
small.en |
small |
~2 GB |
~6x |
| medium |
769 M |
medium.en |
medium |
~5 GB |
~2x |
| large |
1550 M |
N/A |
large |
~10 GB |
1x |
为了不用每次都输入命令行,所以我写了个py程序,按照上面的步骤安装好后,每次就只要运行这个py程序,拖入视频然后选模型就可以了
import os
videoName = input("请拖入视频:")
model = input("请选择模型(1:tiny 2:base 3:small 4:medium 5:large):")
if(model == "1"):
model = "tiny"
elif(model == "2"):
model = "base"
elif(model == "3"):
model = "small"
elif(model == "4"):
model = "medium"
elif(model == "5"):
model = "large"
else:
model = "small"
print(f"模型:{model}\t转换视频:{videoName}\n现在开始转换...")
cmd = f"whisper {videoName} --output_format=srt --model={model}"
try:
os.system(cmd)
input("转换完成!")
except Exception as e:
print(f"发生错误:{e}")
input("转换失败!")
效果图:
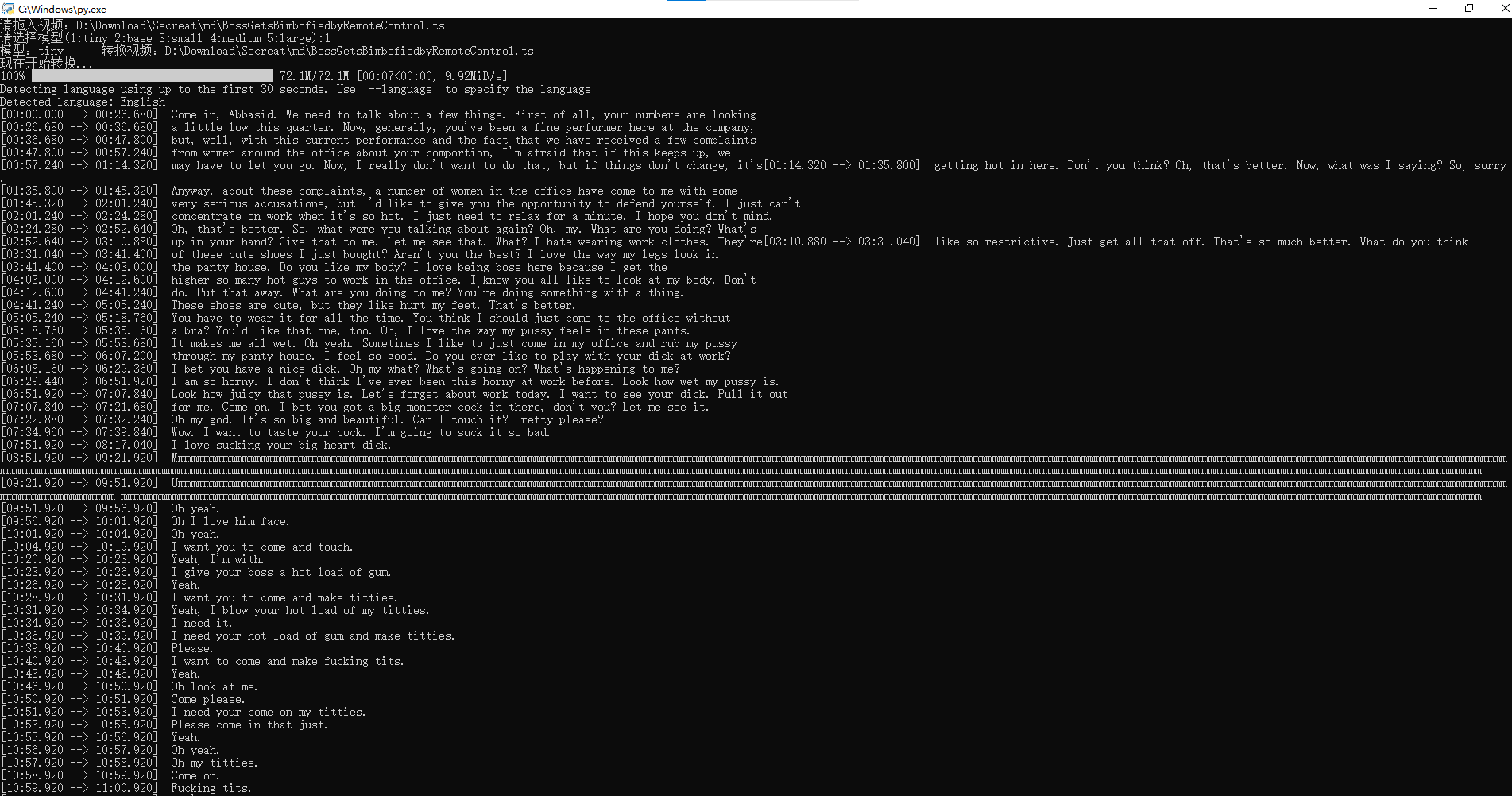
另外,因为不能生成中文字幕,默认是英文,所以一般是配合potplayer的实时字幕翻译使用。 | 
 [复制链接]
[复制链接]
 发表于 2023-10-19 14:39
发表于 2023-10-19 14:39
 |
发表于 2023-10-23 11:52
|
发表于 2023-10-23 11:52





