一些可以略过的话
最近突然想买个抱枕,在淘宝上翻了翻,您猜怎么找,居然碰到了一个抱枕图库,这不整的我手痒了不是,于是就有了这篇文章。
一个超简单的抱枕图库爬取
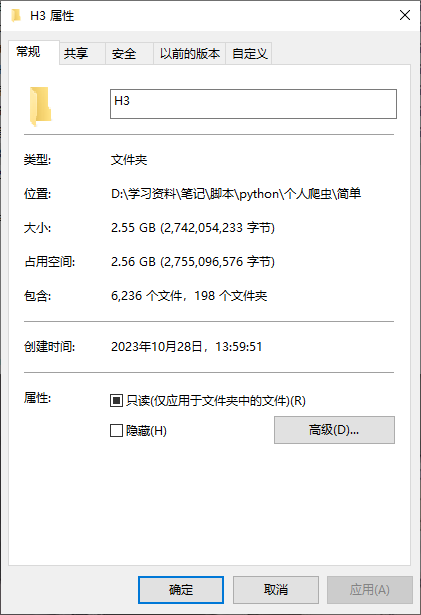
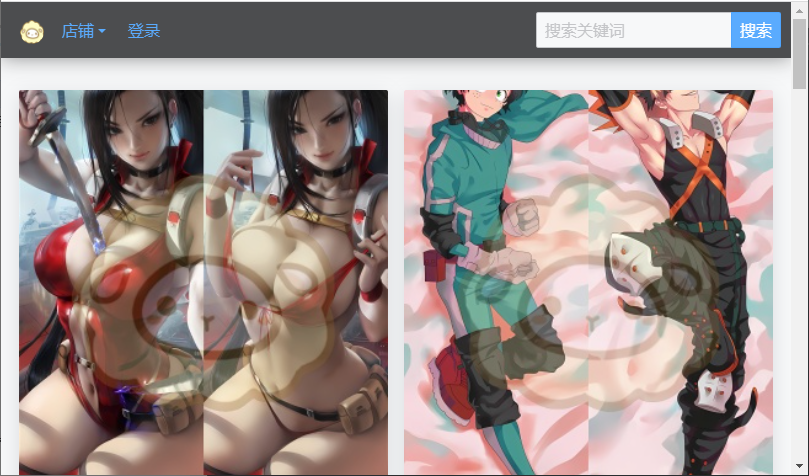
效果图
第一步:获取动漫集列表
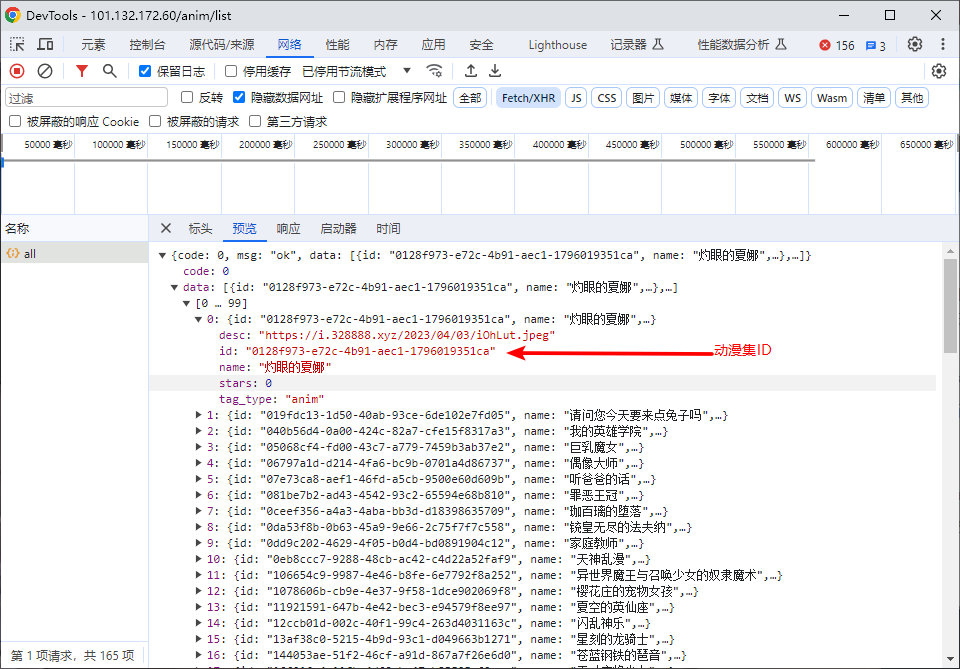
-
说明:返回中的动漫集ID用于后续请求动漫集内容
-
python示例:
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.69"}
def all_li():
url = 'http://101.132.172.60/api/anim/all'
res = requests.post(url, headers=headers)
return [(i['name'], i['id']) for i in res.json()['data']]
第二步:动漫集内容获取
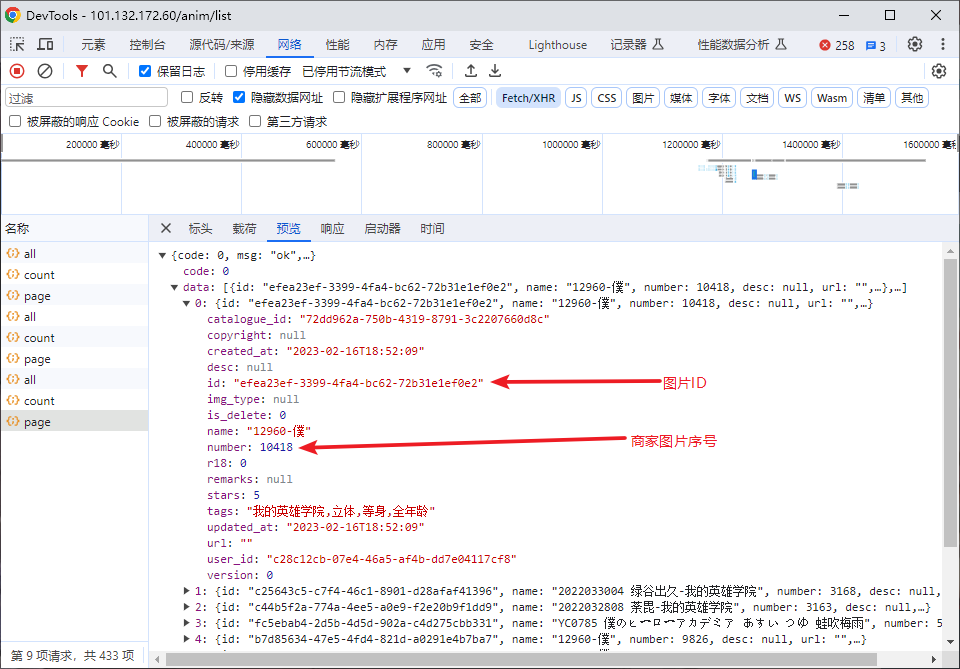
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.69"}
def in_li(title_id):
url = f'http://101.132.172.60/api/anim/{title_id}/page'
n = 1
result = []
while True:
data = {
'page': n,
'size': 50
}
res = requests.post(url, json=data, headers=headers)
li = [(i['number'], i['id']) for i in res.json()['data']]
if not li: break
result.extend(li)
n += 1
return result
第三步:图片下载
def image_save(name, _id):
url = f'http://101.132.172.60/api/imgs/{_id}/regular.jpg'
res = requests.get(url, headers=headers, timeout=10)
with open(name, 'wb') as f:
f.write(res.content)
注意事项
- 目录/文件保存时,注意符合系统命名方式(可恶的windows命名规范
- 该服务器貌似比较弱,并发10请求仍存在断包的情况
完整代码见附件(解压码:52pojie) | 
 发表于 2023-10-29 17:56
发表于 2023-10-29 17:56
 |
发表于 2023-10-31 16:03
|
发表于 2023-10-31 16:03






{kind=link}