[Python] 纯文本查看 复制代码
import base64
import re
import bs4
import easyocr
import requests
from fontTools.ttLib import TTFont
from PIL import Image, ImageDraw, ImageFont
import os
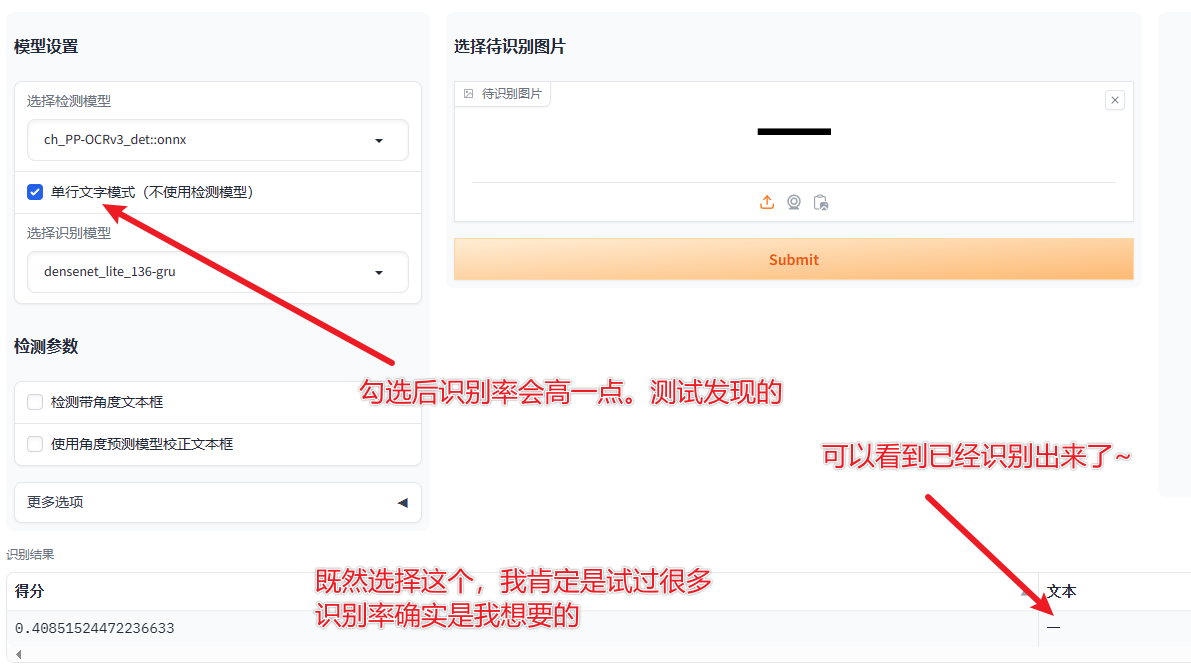
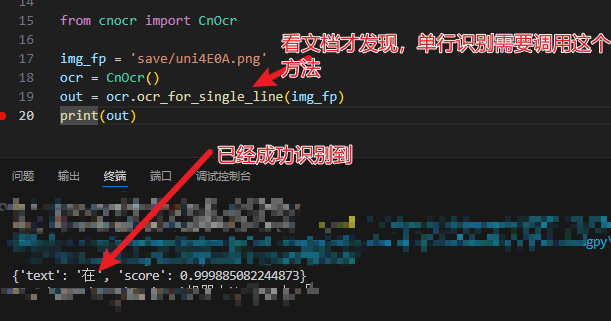
def ocr(folder_dir: str) -> dict:
reader = easyocr.Reader(['ch_sim'], gpu=False)
key_words = {}
directory = folder_dir
dir_list = os.listdir(directory)
for file_name in dir_list:
full_path = os.path.join(directory, file_name)
# print(full_path)
error_key_word = f'\\{file_name}'.encode('utf-8').decode('unicode_escape').replace('.png', '')
try:
success_key_word = reader.readtext(full_path, detail=False)[0]
except IndexError:
success_key_word = '一'
key_words.update({error_key_word: success_key_word})
return key_words
def get_html():
url = "https://www.zhihu.com/market/paid_column/1730607810226688000/section/1730181148968325120"
payload = {}
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'zh-CN,zh-TW;q=0.9,zh;q=0.8',
'cache-control': 'no-cache',
'pragma': 'no-cache',
'sec-ch-ua': '"Google Chrome";v="123", "Not:A-Brand";v="8", "Chromium";v="123"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36'
}
response = requests.request("GET", url, headers=headers, data=payload)
return response.text
def html_analyze(html_body: str):
html_obj = bs4.BeautifulSoup(html_body, features="html.parser")
return '\n'.join([item.get_text() for item in html_obj.findAll('p')])
def clear_directory(path):
for filename in os.listdir(path):
filepath = os.path.join(path, filename)
try:
if os.path.isfile(filepath):
os.remove(filepath)
except Exception as e:
print(f"Error deleting {filepath}: {e}")
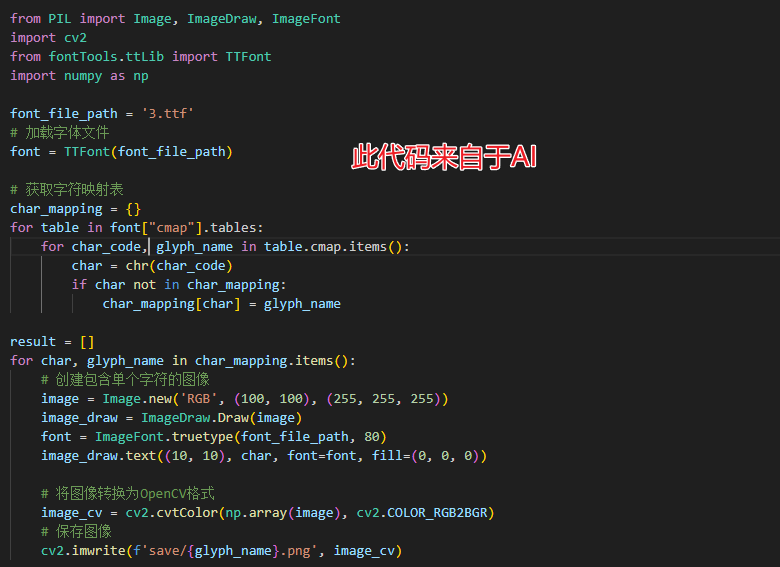
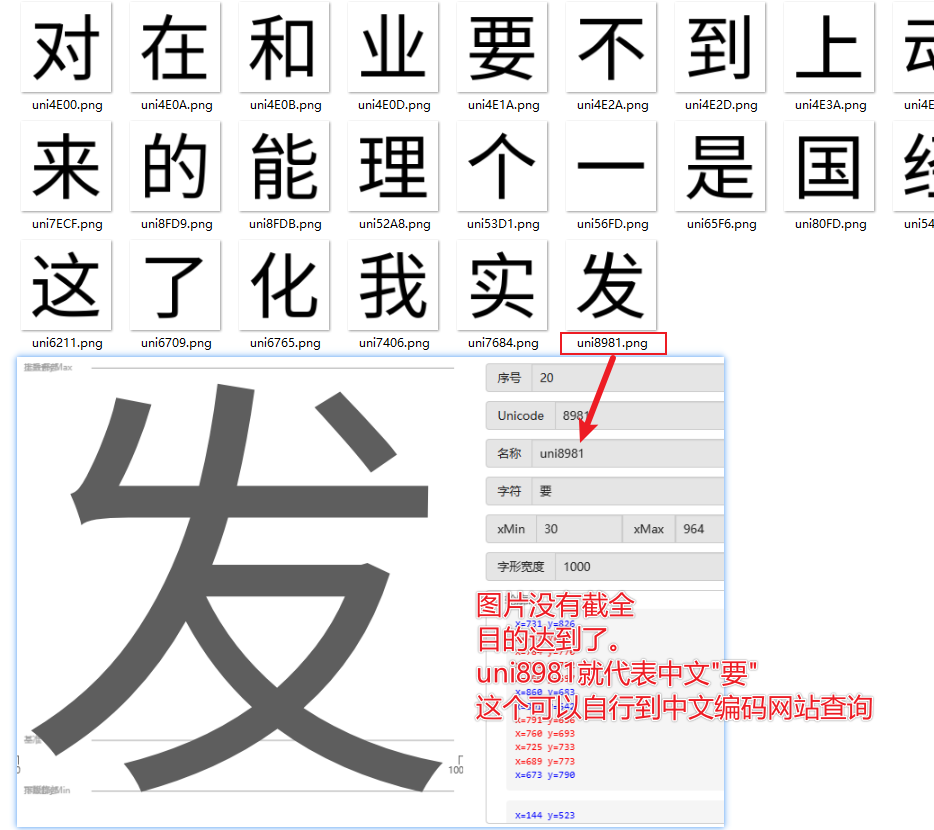
def export_glyph_images(ttf_file_path, output_folder, image_size=(200, 200), font_size=200):
if not os.path.exists(output_folder):
os.makedirs(output_folder)
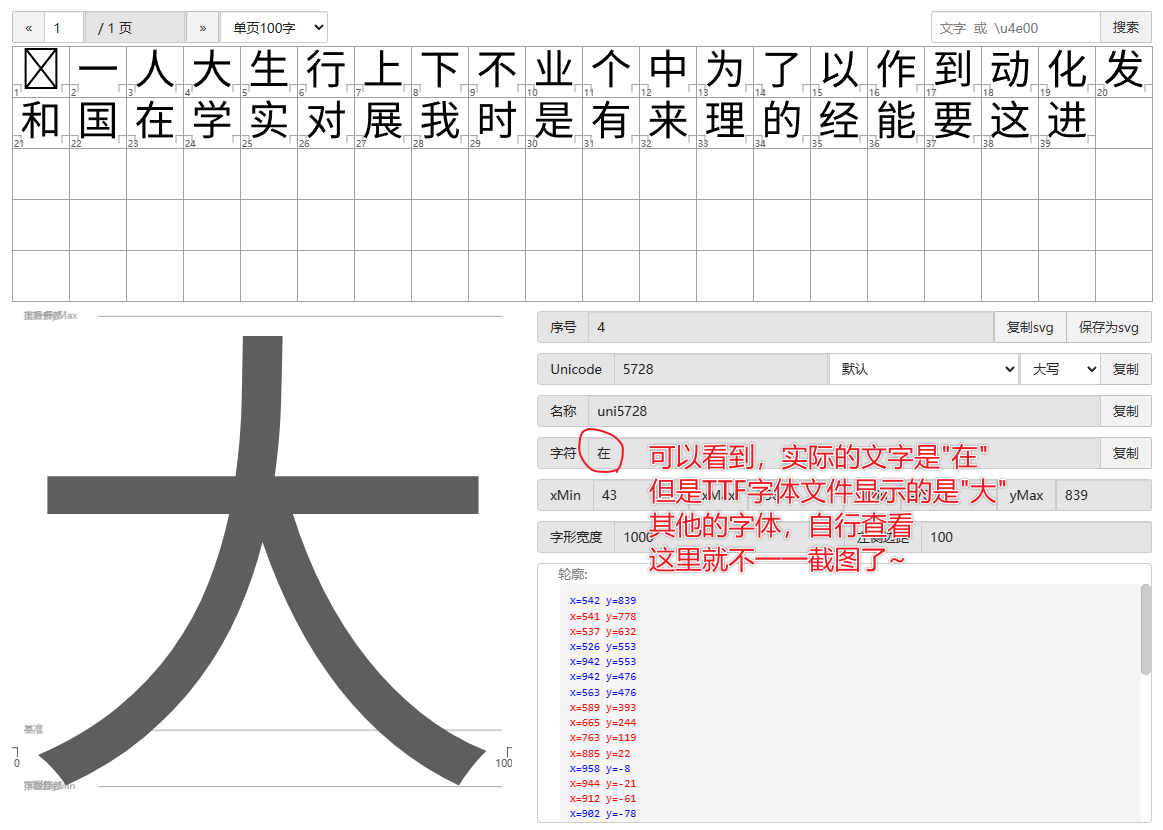
font = TTFont(ttf_file_path)
cmap = font.getBestCmap()
pil_font = ImageFont.truetype(ttf_file_path, font_size)
for unicode_char, glyph_name in cmap.items():
char = chr(unicode_char)
img = Image.new("RGBA", image_size, color="white")
draw = ImageDraw.Draw(img)
# 绘制字符
draw.text((0, 0), char, font=pil_font, fill="black", font_size=24, align="center")
# 保存图片
unicode_hex_str = f'u{unicode_char:04X}' + ".png"
print(unicode_hex_str)
image_file_path = os.path.join(output_folder, unicode_hex_str)
img.save(image_file_path)
font.close()
if __name__ == '__main__':
# 字体缓存地址
output_folder = r"xxxxxxx"
clear_directory(output_folder)
html_body = get_html()
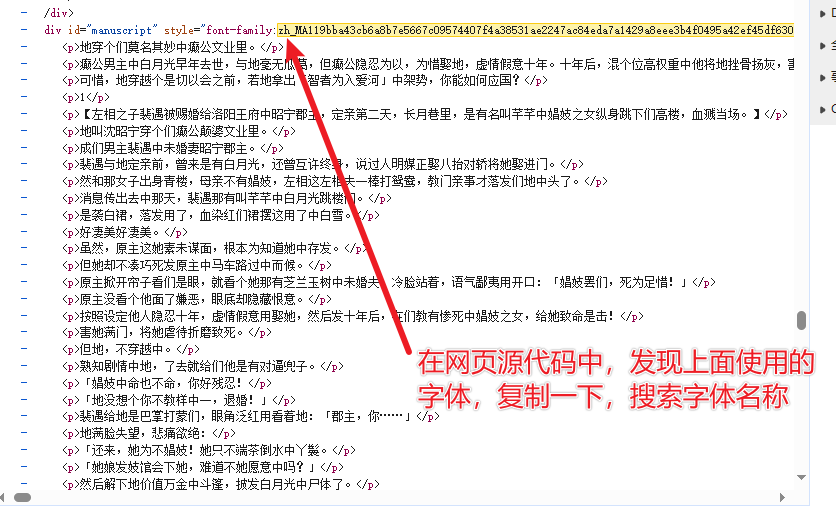
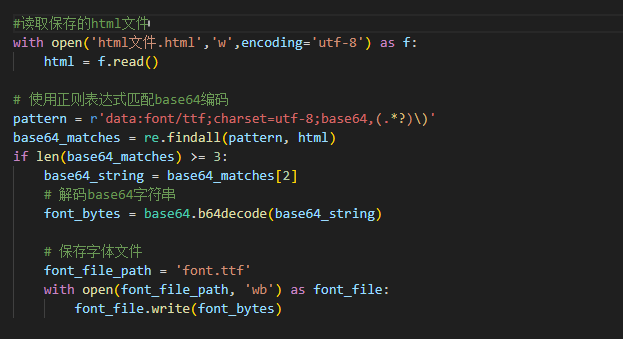
font_face_regex = re.findall(r'@font-face\s*{([^}]*)}', html_body)
base64_string = re.findall('base64,(.*?)\);', font_face_regex[3])[0]
binary_data = base64.b64decode(base64_string)
with open('zhihu.ttf', 'wb') as f:
f.write(bytes(binary_data))
# 指定TTF文件的路径
ttf_file_path = "zhihu.ttf"
# 调用函数导出字形图片
export_glyph_images(ttf_file_path, output_folder)
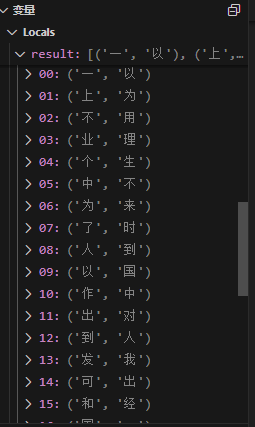
keywords = ocr(output_folder)
content = [item for item in html_analyze(html_body)]
filter_list = []
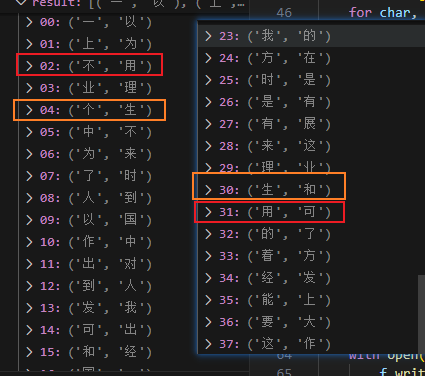
for error_key, success_key in keywords.items():
for index in range(len(content)):
if content[index] == error_key and index not in filter_list:
content[index] = success_key
filter_list.append(index)
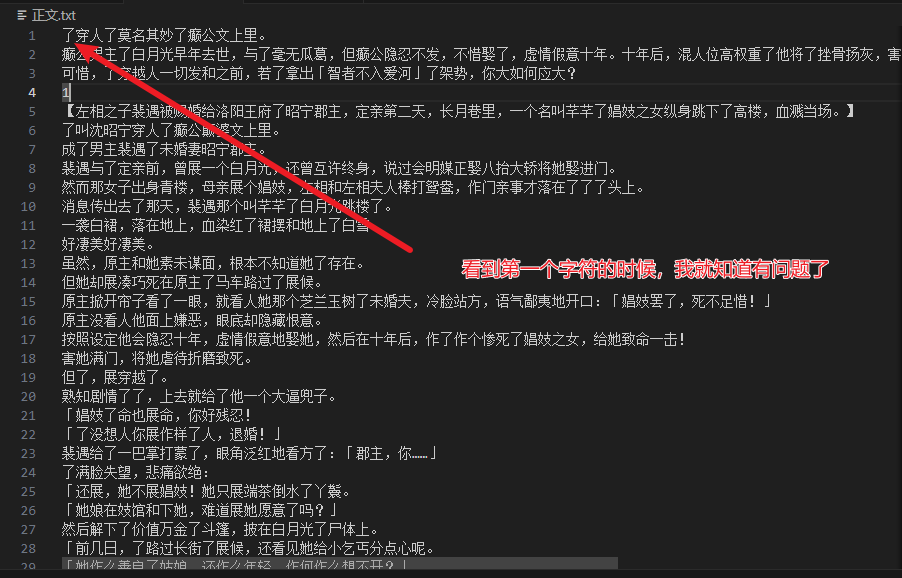
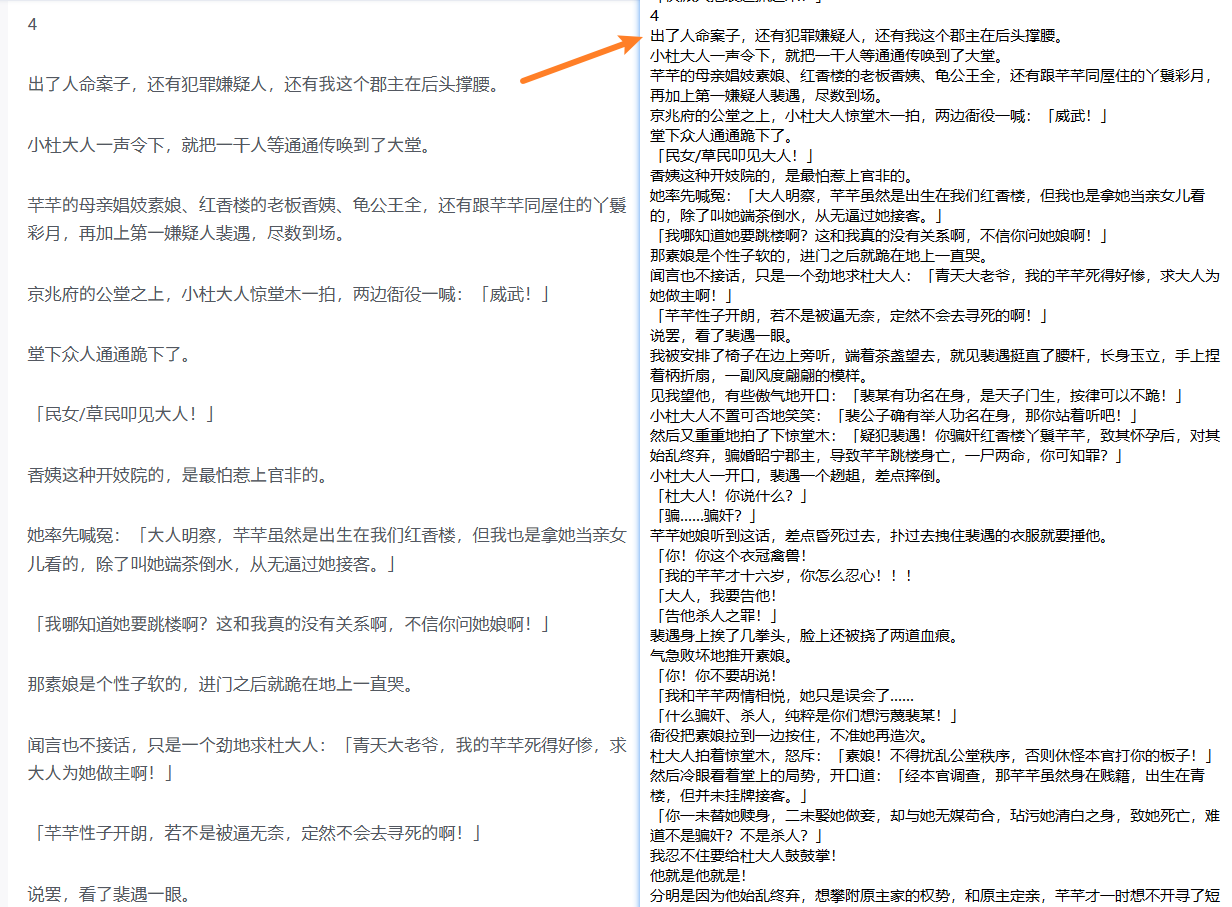
with open('知乎盐选.txt', 'w', encoding='utf-8') as f:
f.write(''.join(content))

 [复制链接]
[复制链接]

 发表于 2024-4-10 14:58
发表于 2024-4-10 14:58









 代码太多看不懂了 坐等大佬们的成品
代码太多看不懂了 坐等大佬们的成品