本帖最后由 Lengxiy 于 2024-5-27 15:03 编辑
前言
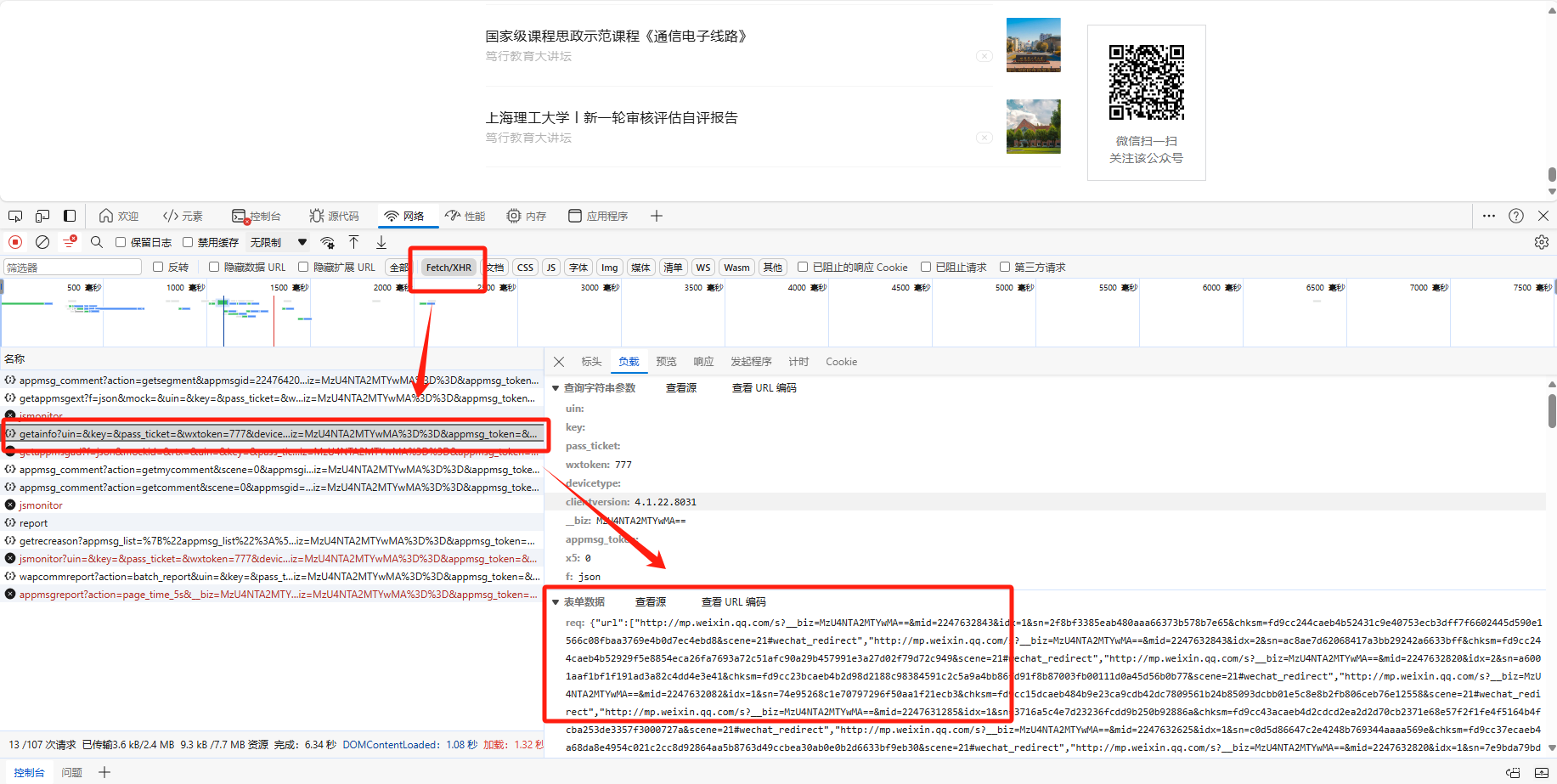
这里是直接读取txt文本内的json数据,没有太过高深的技术之类的,至于这些链接哪儿来的是通过浏览器F12找到对应的数据包找到的
这个txt里面的数据来自该链接:https://mp.weixin.qq.com/s/4qlRBicxn2cXPqJLxR4_TQ?from=industrynews&version=4.1.22.8031&platform=win&nwr_flag=1#wechat_redirect
然后里面有个数据包,都是页面上面的超链接

我这里只是单纯的将这些全都复制到了txt文本内再用python读取的,当然也可以通过python直接访问该链接,找到这个数据包获取里面json数据即网址再通过下面的代码下载图片
可以简单修改就可以用在其他地方了
至于为啥只下载图片,因为我随便瞅了几眼,全是图片的内容,然后也没几个文字,就直接下载了
领导反正也没说让我筛选,就偷懒没写筛选的相关代码了
运行模式:
1.读取txt文本内的所有链接
2.根据每个链接建立一个文件夹,将访问后的页面的所有图片下载下来存在对应的文件夹内
3.图片名称按照数字顺序命名
4.用的selenium按照固定的滑动距离快速滑动滑动至底部以确保页面加载完毕下面是txt文本内的格式数据参考

代码
[Python] 纯文本查看 复制代码 import json
import os
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManager
import time
# 设置Chrome选项
chrome_options = Options()
# chrome_options.add_argument("--headless") # 无头模式
chrome_options.add_argument("--disable-gpu")
chrome_options.add_argument("--no-sandbox")
# 初始化webdriver
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=chrome_options)
# 假设txt文件名为"urls.txt",并且位于当前工作目录中
txt_file_path = "{.txt"
# 读取txt文件中的内容
with open(txt_file_path, 'r', encoding='utf-8') as file:
content = file.read()
# 解析JSON内容
urls = json.loads(content)
urls1 = urls["url"]
# 创建一个主文件夹来保存所有下载的图片
os.makedirs('downloaded_images', exist_ok=True)
# 遍历URL列表,下载每个网页上的所有图片
for idx, url in enumerate(urls1):
print(f"正在处理URL {idx+1}: {url}")
driver.get(url)
# 模拟缓慢滚动行为
SCROLL_PAUSE_TIME = 0.1
scroll_increment = 500
last_height = driver.execute_script("return document.body.scrollHeight")
current_position = 0
while current_position < last_height:
driver.execute_script(f"window.scrollTo(0, {current_position});")
current_position += scroll_increment
time.sleep(SCROLL_PAUSE_TIME)
last_height = driver.execute_script("return document.body.scrollHeight")
# 确保已滚动到页面底部
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(SCROLL_PAUSE_TIME)
soup = BeautifulSoup(driver.page_source, 'html.parser')
images = soup.find_all('img') # 查找指定类名的图片 , class_='rich_pages wxw-img'
# 为每个URL创建一个独立的文件夹
folder_name = f"url_{idx+1}"
folder_path = os.path.join('downloaded_images', folder_name)
os.makedirs(folder_path, exist_ok=True)
for img_idx, img in enumerate(images):
img_url = img.get('data-src')
if not img_url:
img_url = img.get('src') # 尝试获取src属性
if img_url and not img_url.startswith('data:'):
# 检查URL是否完整
if not img_url.startswith(('http:', 'https:')):
img_url = requests.compat.urljoin(url, img_url)
# 获取图片内容的响应
img_response = requests.get(img_url)
if img_response.status_code == 200:
# 按顺序命名图片
img_name = f"{img_idx+1}.png"
img_path = os.path.join(folder_path, img_name)
# 保存图片
with open(img_path, 'wb') as f:
f.write(img_response.content)
print(f"图片已下载: {img_path}")
else:
print(f"无法下载图片: {img_url}")
else:
print(f"无效的图片URL: {img_url}")
driver.quit()
print("所有图片下载完成。")
| 
 发表于 2024-5-27 13:12
发表于 2024-5-27 13:12
 |
发表于 2024-5-27 14:57
|
发表于 2024-5-27 14:57