三、主要代码
# region 弹幕获取相关函数
import base64
import hashlib
import json
import re
import time
import traceback
import zlib
from dataclasses import dataclass, field, asdict
from typing import List
from urllib.parse import urljoin
from venv import logger
import parsel
# import requests
import xmltodict
from retrying import retry
from tqdm import tqdm
from Fuctions.Fuction import request_data
from curl_cffi import requests
@dataclass
class DanMuType:
text: str = '' # 弹幕文本
time: int = 0 # 弹幕时间
mode: int = 1 # 弹幕模式
color: str = '#FFFFFF' # 弹幕颜色
border: bool = False # 弹幕是否有描边
style: dict = field(default_factory=dict) # 弹幕自定义样式
other: dict = field(default_factory=dict) # 其他数据
def __dict__(self):
return dict(
text=self.text.replace('&#', ''),
time=int(self.time),
mode=self.mode,
color=str(self.color) if isinstance(self.color, str) and self.color.startswith(
"#") else f'#{int(self.color):06X}',
border=self.border,
style=self.style
)
def escape_xml(self):
# 定义需要转义的字符及其对应的转义序列
escape_chars = {
'&': '&',
'<': '<',
'>': '>',
'"': '"',
"'": '''
}
# 按照需要转义的字符顺序进行替换
for char, escaped_char in escape_chars.items():
self.text = self.text.replace(char, escaped_char)
return self.text
@dataclass
class RetDanMuType:
list: List[DanMuType]
xml: str
class DataclassJSONEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, DanMuType):
return obj.__dict__()
return super().default(obj)
class GetDanmuBase(object):
base_xml = '''<?xml version="1.0" encoding="utf-8"?>
<i>
{}
</i>'''
data_list = []
name = ""
domain = ""
def error(self, msg):
return {
"msg": msg,
"start": 500,
"data": None,
"name": self.name
}
def success(self, data):
return {
"msg": "success",
"start": 0,
"data": data,
"name": self.name
}
def get_data_dict(self) -> DanMuType:
return DanMuType()
def main(self, url) -> list[DanMuType]:
"""
获取弹幕的主逻辑
"""
pass
def parse(self):
"""
解析返回的原始数据
:param _type: 数据类型,xml 或 list
"""
pass
def get(self, url, _type='json'):
self.data_list = []
try:
data = self.main(url)
return RetDanMuType(json.loads(json.dumps(data, cls=DataclassJSONEncoder)),
self.base_xml.format('\n'.join([self.list2xml(d) for d in data])))
except Exception as e:
return self.error(f"程序出现错误:{traceback.print_exc()}")
def getImg(self, url):
"""
获取弹幕的表情链接
"""
return []
def list2xml(self, data: DanMuType):
xml_str = f' <d p="{data.time},{data.mode},{data.style.get("size", 25)},{int(data.color[1:], 16) if isinstance(data.color, str) and data.color.startswith("#") else data.color},0,0,0,0">{data.escape_xml()}</d>'
return xml_str
def time_to_second(self, _time: list):
s = 0
m = 1
for d in _time[::-1]:
s += m * int(d)
m *= 60
return s
class GetDanmuTencent(GetDanmuBase):
name = "腾讯视频"
domain = "v.qq.com"
def __init__(self):
self.api_danmaku_base = "https://dm.video.qq.com/barrage/base/"
self.api_danmaku_segment = "https://dm.video.qq.com/barrage/segment/"
def parse(self):
data_list = []
for data in tqdm(self.data_list):
for item in data.get("barrage_list", []):
_d = self.get_data_dict()
_d.time = int(item.get("time_offset", 0)) / 1000
_d.text = item.get("content", "")
_d.other['create_time'] = item.get('create_time', "")
if item.get("content_style") != "":
content_style = json.loads(item.get("content_style"))
if content_style.get("color") != "ffffff":
_d.color = int(content_style.get("color", "ffffff"), 16)
data_list.append(_d)
return data_list
def main(self, url):
self.data_list = []
# res = request_data("GET", url)
# sel = parsel.Selector(res.text)
# title = sel.xpath('//title/text()').get()
# vid = re.findall(f'"title":"{title}","vid":"(.*?)"', res.text)[-1]
# if not vid:
vid = re.search("/([a-zA-Z0-9]+)\.html", url)
if vid:
vid = vid.group(1)
if not vid:
return self.error("解析vid失败,请检查链接是否正确")
res = request_data("GET", urljoin(self.api_danmaku_base, vid))
if res.status_code != 200:
return self.error("获取弹幕详情失败")
for k, segment_index in res.json().get("segment_index", {}).items():
self.data_list.append(
request_data("GET",
urljoin(self.api_danmaku_segment,
vid + "/" + segment_index.get("segment_name", "/"))).json())
parse_data = self.parse()
return parse_data
def getImg(self, url):
vid = re.search("/([a-zA-Z0-9]+)\.html", url)
if vid:
vid = vid.group(1)
if not vid:
return self.error("解析vid失败,请检查链接是否正确")
cid = url.split('/')[-2]
data = {
"vid": vid,
"cid": cid,
"lid": "",
"bIsGetUserCfg": True
}
res = request_data("POST",
"https://pbaccess.video.qq.com/trpc.danmu.danmu_switch_comm.DanmuSwitch/getVideoDanmuSwitch",
json=data)
danmukey = res.json().get('data', {}).get('registResultInfo', {}).get('dataKey')
res = request_data("POST", "https://pbaccess.video.qq.com/trpc.message.danmu_richdata.Richdata/GetRichData",
json={
"danmu_key": danmukey,
"vip_degree": 0
},
headers={
'origin': "https://v.qq.com",
'referer': "https://v.qq.com",
})
emoji_infos = res.json().get('data', {}).get('emoji_configs', {}).get('emoji_infos', [])
emoji_data_list = []
for emoji_info in emoji_infos:
emoji_data_list.append(
{
'emoji_code': emoji_info.get('emoji_code'),
'emoji_url': emoji_info.get('emoji_url'),
}
)
return emoji_data_list
class GetDanmuBilibili(GetDanmuBase):
name = "B站"
domain = "bilibili.com"
def __init__(self):
self.api_video_info = "https://api.bilibili.com/x/web-interface/view"
self.api_epid_cid = "https://api.bilibili.com/pgc/view/web/season"
def parsel(self, xml_data):
data_list = re.findall('<d p="(.*?)">(.*?)<\/d>', xml_data)
for data in tqdm(data_list):
_d = self.get_data_dict()
_d.text = data[1]
data_time = data[0].split(",")
_d.time = int(data_time[0])
_d.mode = data_time[1]
_d.style['size'] = data_time[2]
_d.color = data_time[3]
self.data_list.append(_d)
return self.data_list
def main(self, url: str):
# 番剧
if url.find("bangumi/") != -1 and url.find("ep") != -1:
epid = url.split('?')[0].split('/')[-1]
params = {
"ep_id": epid[2:]
}
res = request_data("GET", url=self.api_epid_cid, params=params, impersonate="chrome110")
res_json = res.json()
if res_json.get("code") != 0:
return self.error("获取番剧信息失败")
for episode in res_json.get("result", {}).get("episodes", []):
if episode.get("id", 0) == int(epid[2:]):
xml_data = request_data("GET", f'https://comment.bilibili.com/{episode.get("cid")}.xml',
impersonate="chrome110").text
return self.parsel(xml_data)
class GetDanmuIqiyi(GetDanmuBase):
name = "爱奇艺"
domain = "iqiyi.com"
def parse(self):
data_list = []
for data in tqdm(self.data_list):
# 解压缩数据
decompressed_data = zlib.decompress(data)
data = decompressed_data.decode('utf-8')
for d in re.findall('<bulletInfo>.*?</bulletInfo>', data, re.S):
d = d.replace('&#', '')
try:
d_dict = xmltodict.parse(d).get("bulletInfo")
_d = self.get_data_dict()
_d.time = int(d_dict.get("showTime"))
_d.text = d_dict.get("content")
_d.color = int(d_dict.get("color"), 16)
_d.style["size"] = int(d_dict.get("font"))
data_list.append(_d)
except Exception as e:
logger.error(e)
pass
return data_list
def main(self, url):
_req = requests.Session(impersonate="chrome124")
res = _req.request("GET", url,
headers={"Accept-Encoding": "gzip,deflate,compress"}, impersonate="chrome124")
res.encoding = "UTF-8"
js_url = re.findall(r'<script src="(.*?)" referrerpolicy="no-referrer-when-downgrade">', res.text)[0]
res = _req.request('GET', f'https:{js_url}', headers={'referer': url})
tv_id = re.findall('"tvId":([0-9]+)', res.text)[0]
i = 1
while True:
url = f"https://cmts.iqiyi.com/bullet/{tv_id[-4:-2]}/{tv_id[-2:]}/{tv_id}_300_{i}.z"
params = {
}
r = request_data("GET", url=url, params=params,
headers={'Content-Type': 'application/octet-stream'})
if r.status_code == 404: break
self.data_list.append(r.content)
i += 1
parse_data = self.parse()
return parse_data
class GetDanmuMgtv(GetDanmuBase):
name = "芒果TV"
domain = "mgtv.com"
def __init__(self):
self.api_video_info = "https://pcweb.api.mgtv.com/video/info"
self.api_danmaku = "https://galaxy.bz.mgtv.com/rdbarrage"
def parse(self):
data_list = []
for data in tqdm(self.data_list):
if data.get("data", {}).get("items", []) is None:
continue
for d in data.get("data", {}).get("items", []):
_d = self.get_data_dict()
_d.time = d.get('time', 0) / 1000
_d.text = d.get('content', '')
data_list.append(_d)
return data_list
def main(self, url):
_u = url.split(".")[-2].split("/")
cid = _u[-2]
vid = _u[-1]
params = {
'cid': cid,
'vid': vid,
}
res = request_data("GET", url=self.api_video_info, params=params)
_time = res.json().get("data", {}).get("info", {}).get("time")
end_time = self.time_to_second(_time.split(":")) * 1000
for _t in range(0, end_time, 60 * 1000):
self.data_list.append(
request_data("GET", self.api_danmaku, params={
'vid': vid,
"cid": cid,
"time": _t
}).json()
)
parse_data = self.parse()
return parse_data
class GetDanmuYouku(GetDanmuBase):
name = "优酷"
domain = "v.youku.com"
def __init__(self):
super().__init__()
self.req = requests.Session()
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"
}
self.get_cna()
self.get_tk_enc()
@retry(stop_max_attempt_number=5, wait_random_min=1000, wait_random_max=2000)
def request_data(self, method, url, status_code=None, **kwargs):
"""
发送请求
:param method: 请求方式
:param url: 请求URL
:param status_code: 成功的状态码
:param kwargs:
:return:
"""
res = self.req.request(method, url, **kwargs)
# res.encoding = res.apparent_encoding
if status_code:
if res.status_code == status_code:
return res
else:
return
return res
def get_cna(self):
url = "https://log.mmstat.com/eg.js"
res = self.request_data("GET", url, headers=self.headers)
def get_tk_enc(self):
res = self.request_data("GET",
"https://acs.youku.com/h5/mtop.com.youku.aplatform.weakget/1.0/?jsv=2.5.1&appKey=24679788",
headers=self.headers)
if '_m_h5_tk' in res.cookies.keys() and '_m_h5_tk_enc' in res.cookies.keys():
return True
return False
def get_vinfos_by_video_id(self, video_id):
url = "https://openapi.youku.com/v2/videos/show.json"
params = {
'client_id': '53e6cc67237fc59a',
'video_id': video_id,
'package': 'com.huawei.hwvplayer.youku',
'ext': 'show',
}
res = self.request_data("GET", url, params=params, headers=self.headers)
return res.json().get('duration')
def get_msg_sign(self, msg_base64):
secret_key = 'MkmC9SoIw6xCkSKHhJ7b5D2r51kBiREr'
combined_msg = msg_base64 + secret_key
hash_object = hashlib.md5(combined_msg.encode())
return hash_object.hexdigest()
def yk_t_sign(self, token, t, appkey, data):
text = '&'.join([token, t, appkey, data])
md5_hash = hashlib.md5(text.encode())
return md5_hash.hexdigest()
def parse(self):
data_list = []
for data in tqdm(self.data_list):
result = json.loads(data.get('data', {}).get('result', {}))
if result.get('code', '-1') == '-1':
continue
danmus = result.get('data', {}).get('result', [])
for danmu in danmus:
_d = self.get_data_dict()
_d.time = danmu.get('playat') / 1000
_d.color = json.loads(danmu.get('propertis', '{}')).get('color', _d.color)
_d.text = danmu.get('content')
data_list.append(_d)
return data_list
def main(self, url):
video_id = url.split('?')[0].split('/')[-1].replace("id_", '').split('.html')[0]
max_mat = self.get_vinfos_by_video_id(video_id)
for mat in range(0, int(float(max_mat) / 60) + 1):
url = "https://acs.youku.com/h5/mopen.youku.danmu.list/1.0/"
msg = {
'ctime': int(time.time() * 1000),
'ctype': 10004,
'cver': 'v1.0',
'guid': self.req.cookies.get('cna'),
'mat': mat,
'mcount': 1,
'pid': 0,
'sver': '3.1.0',
'type': 1,
'vid': video_id
}
msg['msg'] = base64.b64encode(json.dumps(msg).replace(' ', '').encode('utf-8')).decode('utf-8')
msg['sign'] = self.get_msg_sign(msg['msg'])
t = int(time.time() * 1000)
params = {
'jsv': '2.5.6',
'appKey': '24679788',
't': t,
'sign': self.yk_t_sign(self.req.cookies.get('_m_h5_tk')[:32], str(t), '24679788',
json.dumps(msg).replace(' ', '')),
'api': 'mopen.youku.danmu.list',
'v': '1.0',
'type': 'originaljson',
'dataType': 'jsonp',
'timeout': '20000',
'jsonpIncPrefix': 'utility'
}
headers = self.headers.copy()
headers['Content-Type'] = 'application/x-www-form-urlencoded'
headers['Referer'] = 'https://v.youku.com'
res = self.request_data("POST", url, data={"data": json.dumps(msg).replace(' ', '')}, headers=headers,
params=params)
self.data_list.append(res.json())
parse_data = self.parse()
return parse_data
def getImg(self, url):
api_url = 'https://acs.youku.com/h5/mtop.youku.danmu.common.profile/1.0'
video_id = url.split('?')[0].split('/')[-1].replace("id_", '').split('.html')[0]
msg = {
'pid': 0,
'ctype': 10004,
'sver': '3.1.0',
'cver': 'v1.0',
'ctime': int(time.time() * 1000),
'guid': self.req.cookies.get('cna'),
'vid': video_id
}
msg['msg'] = base64.b64encode(json.dumps(msg).replace(' ', '').encode('utf-8')).decode('utf-8')
msg['sign'] = self.get_msg_sign(msg['msg'])
t = int(time.time() * 1000)
params = {
'jsv': '2.5.6',
'appKey': '24679788',
't': t,
'sign': self.yk_t_sign(self.req.cookies.get('_m_h5_tk')[:32], str(t), '24679788',
json.dumps(msg).replace(' ', '')),
'api': 'mopen.youku.danmu.list',
'v': '1.0',
'type': 'originaljson',
'dataType': 'jsonp',
'timeout': '20000',
'jsonpIncPrefix': 'utility'
}
headers = self.headers.copy()
headers['Content-Type'] = 'application/x-www-form-urlencoded'
headers['Referer'] = 'https://v.youku.com'
res = self.request_data("POST", api_url, data={"data": json.dumps(msg).replace(' ', '')}, headers=headers,
params=params)
emoji_infos = res.json().get('data', {}).get('data', {}).get('danmuEmojiEnter', {}).get('danmuDynamicEmojiVO',
[])
emoji_data_list = []
for emoji_info in emoji_infos:
emoji_data_list.append(
{
'emoji_code': emoji_info.get('subtext'),
'emoji_url': emoji_info.get('previewPic'),
}
)
return emoji_data_list
if __name__ == '__main__':
print(GetDanmuBase.__subclasses__())
danmu = GetDanmuTencent()
a = danmu.get(
"https://v.qq.com/x/cover/mzc002007sqbpce/r4100zvgz9i.html?ptag=newdouban.tv",
)
print()
# danmu = GetDanmuMgtv()
# a = danmu.get(
# "https://www.mgtv.com/b/594763/20422016.html?fpa=1217&fpos=&lastp=ch_home",
# _type="xml")
# print()
# endregion



 [复制链接]
[复制链接]
 发表于 2024-12-15 21:41
发表于 2024-12-15 21:41
 |
发表于 2024-6-5 14:16
|楼主
|
发表于 2024-6-5 14:16
|楼主




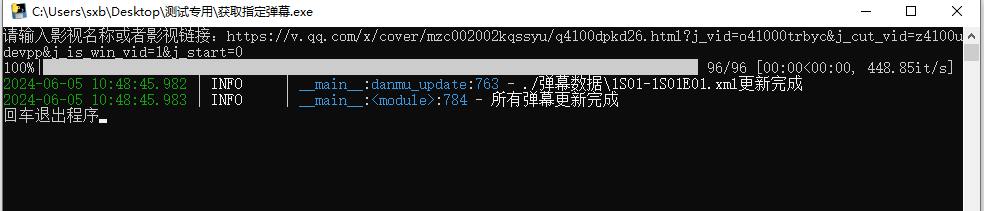
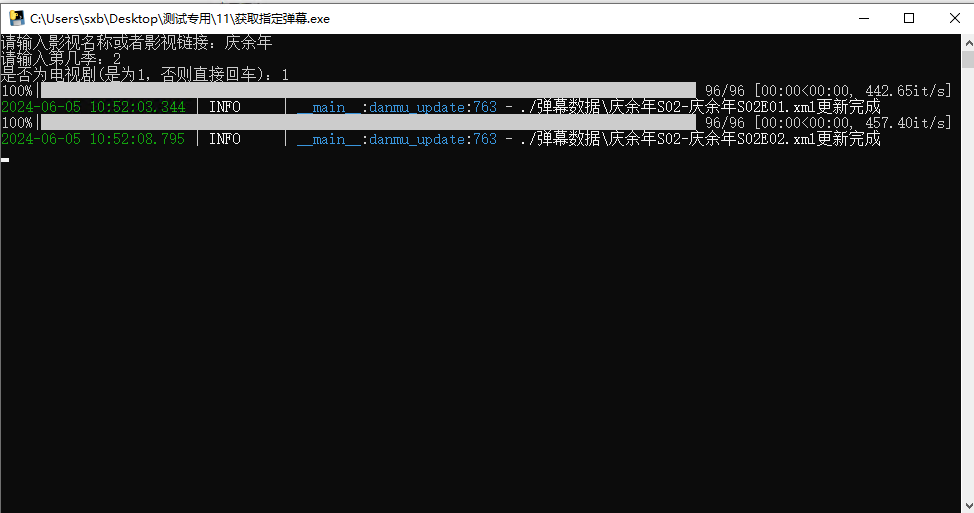
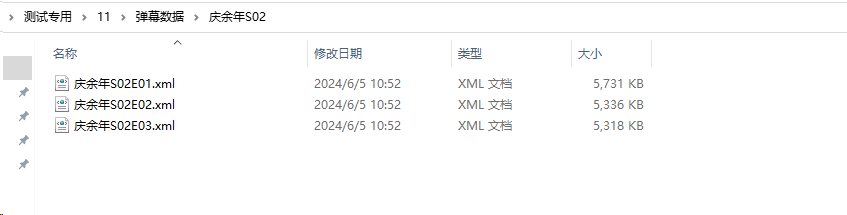
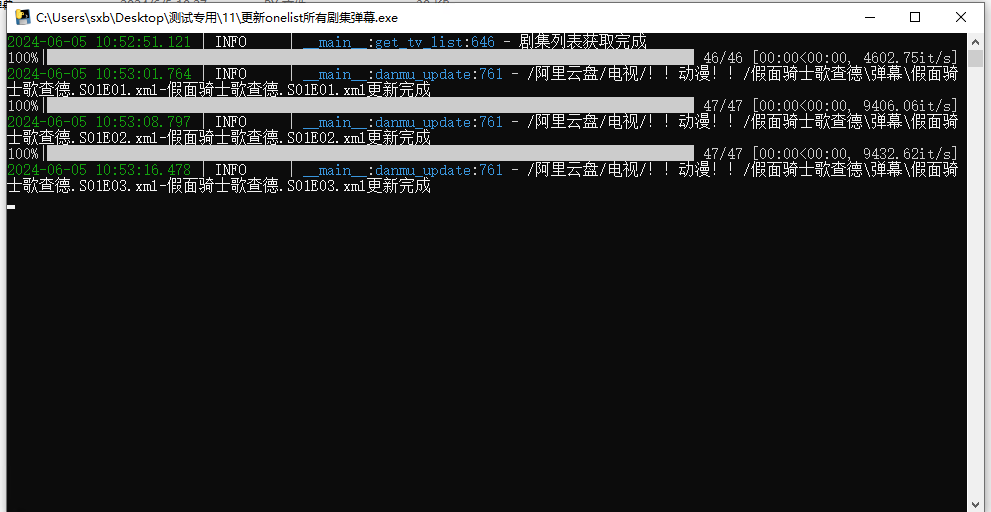
 收藏
收藏 淘帖
淘帖 有用
有用 分享到朋友圈
分享到朋友圈



