写在前面
没想到我有一天会去研究汇编,这是我从未设想的道路。😭
学习环境安装
项目地址:aHR0cHM6Ly9naXRodWIuY29tL0hhaVBlbmdsYWkvYmlsaWJpbGlfYXNzZW1ibHkv
教学视频:aHR0cHM6Ly93d3cuYmlsaWJpbGkuY29tL3ZpZGVvL0JWMWVHNHkxUzdSNQ==
安装配置具体可以参考视频,非常详细,本文不多介绍环境的安装与配置。
基础指令与寄存器
Debug命令
概述
Debug是DOS、Windows都提供的实模式(8086 方式)程序的调试工具。使用它,可以查看CPU各种寄存器中的内容,内存的情况和机器码级跟踪程序的运行。
功能
- R命令 查看、改变CPU寄存器的内容。
- D命令 查看内存中的内容。
- E命令 改写内存中的内容。
- U命令 将内存中的机器指令翻译成汇编指令。
- T命令 执行一条机器命令。
- A命令 以汇编指令的格式在内存中写入一条机器指令。
寄存器层级
在 x86 架构的汇编语言中,寄存器的命名和使用方式有一定的规律。在Debug中,使用R指令可以看到寄存器中的内容

以AX为例,他的内容是0000,他拥有16位,在汇编指令中AX即直接代表这个16位寄存器,如果是AH和AL则代表8位寄存器,H是高位,L是低位,当前是X86的,如果是64的他还有32位,即EAX。
MOV指令
MOV是做替换,在DEBUG中,执行下面汇编指令
mov ah,13
mov bl,33
mov ch,al
执行过后ax寄存器的高位变成了13,bx的低位变成了33,cx的低位变没变,因为他把cx的高位修改成了ax的低位,ax的低位本身没内容即00。
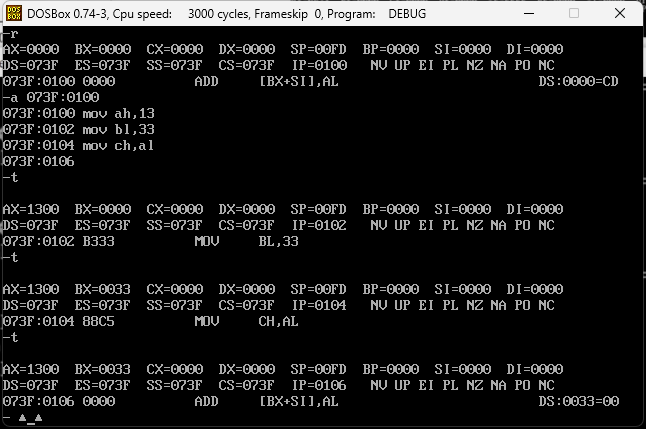
ADD指令
ADD是做加法,在DEBUG中,执行下面汇编指令
add ax,13
add bx,8
add cx,bx
AX从1300变成了1313,因为加了13,bx从0033变成了003B,他这里展示的是16进制,3+8=11,11刚好对应B,然后CX本身就是0000,加上bx那就是003B
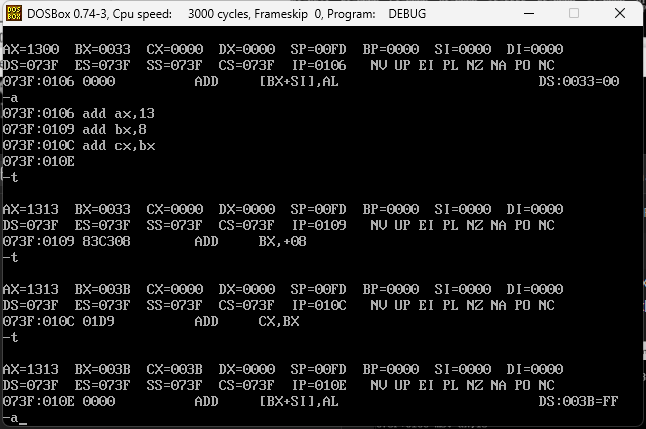
SUB指令
SUB是做减法,在DEBUG中,执行下面汇编指令
sub ax,8
mov bx,F
sub ax,bx
第一条是1313-8,即130B(11),之后bx改为F(15),用ax即130B-F则AX=12FC,相当于130B(11)-15 12F(15)C(12)
MUL指令
mul是乘法指令,使用mul做乘法的时候需要注意下面两点
- 相乘:两个相乘的数,要么都是8位,要么就都是16位。如果是8位,一个默认放在AL中,另一个放在8位reg或内存字节单元中,如果是16位,一个默认在ax中,另一个放在16位reg或内存字单元中。
- 结果:如果是8位乘法,结果默认放在AX中,如果是16位乘法,结果高位默认在DX中存放,低位在AX中放。
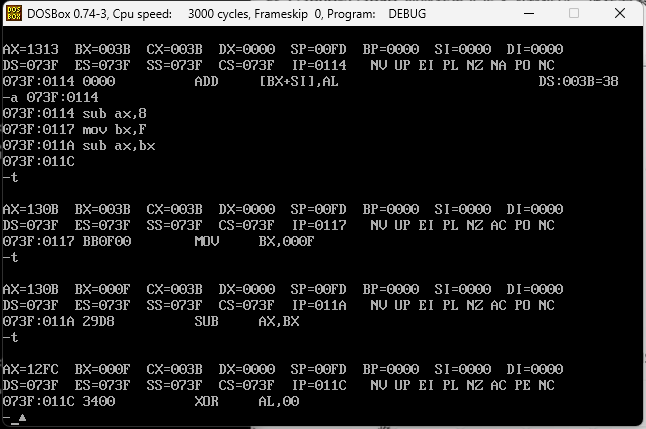
例如我要做100*10的运算,他应该是执行下面的汇编代码
mov al,64
mov bl,A
mul bl
64是100的16进制,A是10的16进制,然后mul是运算,得到03E8,03E8刚好是1000的16进制。
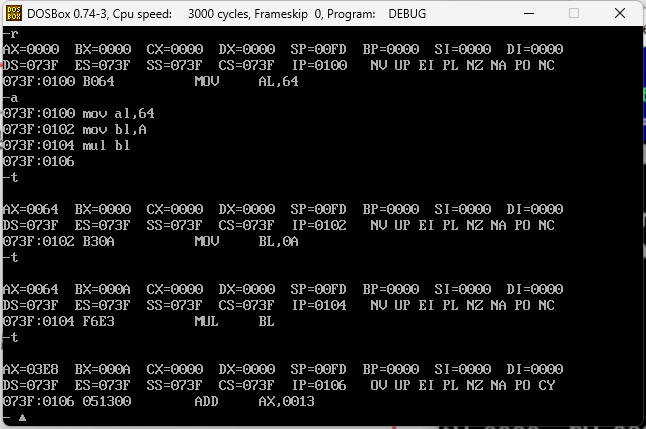
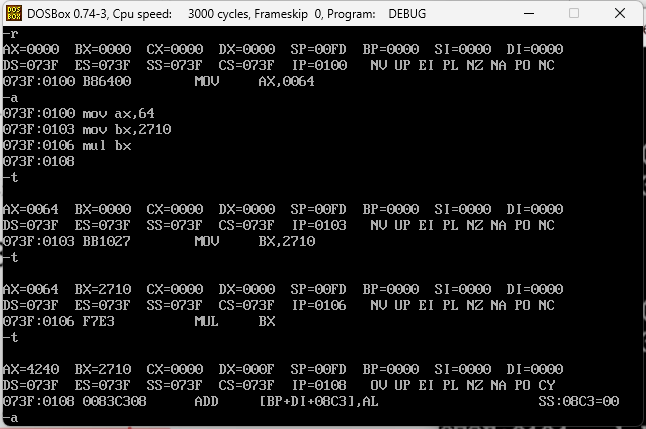
下面做一个100*10000的运算,他会不会出现溢出?100小于255,可是10000大于255,所以必须走16位的乘法,汇编代码如下
mov ax,64
mov bx,2710
mul bx
这个正常的答案应该是1000000,16进制即F4240,在执行之后的结果中,因为位数不够他会把低位放到AX中,高位放到DX中,DX即F,AX就是4240,实际就是F4240即1000000。
DIV指令
div是除法指令,使用div做除法的时候应该注意一下问题
- 除数:有8位和16位两种,在一个reg或内存单元中。
- 被除数:默认放在AX或DX和AX中,如果除数为8位,被除数则为16位,默认在AX中存放;如果出书为16位,被出示则为32位,在DX和AX中存放,DX存放高位16位,AX存放低位16位。
- 结果:如果除数为8位,则AL存储触发操作的商,AH存储触发操作的余数;如果储是为16位,则AX存储除法操作的商,DX存储法操作的余数。
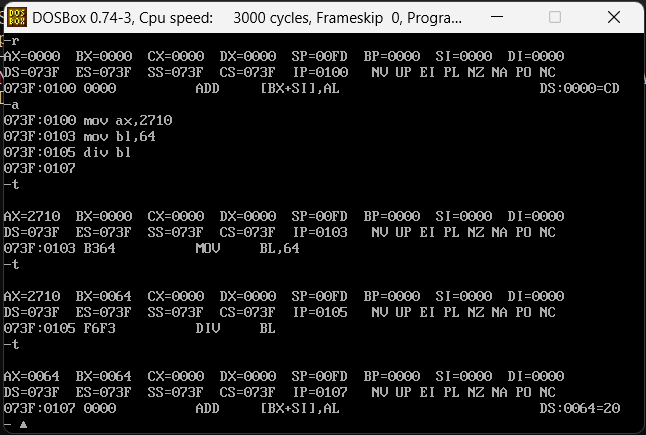
下面做一个10000/100的一个计算,10000的16进制是2710,100的16进制是64,那么计算的汇编代码将是这样
mov ax,2710
mov bl,64
div bl
运行div之后他把答案最终放置到了ax中,64即16进制的100,10000/100=100
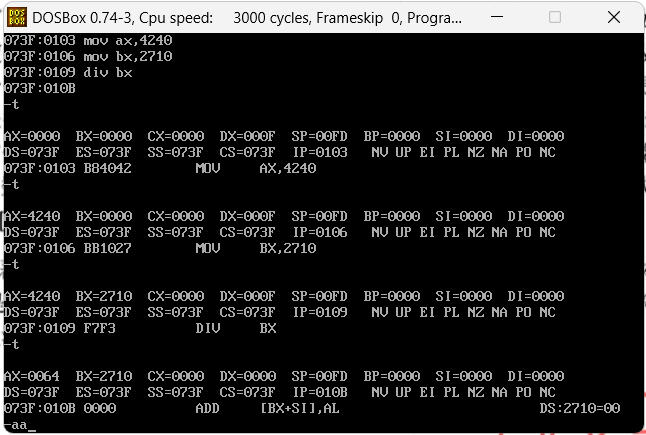
上面这种情况一个是被除数是16位,如果计算1000000/10000,10000000的16进制数是F4240,很显然16位数是放不下的,那就需要把高位放到dx中,参考下面的汇编代码
mov dx,F
mov ax,4240
mov bx,2710
div bx
成功运行那道ax中的运行结果64即10进制的100。
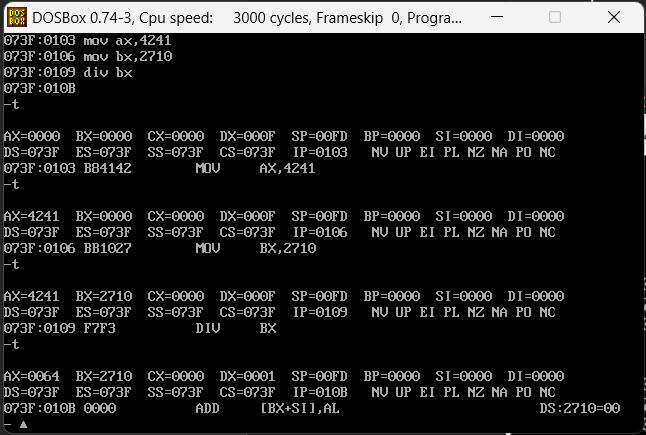
如果运算结果中有余数呢?这里也可以做一下试验,1000001/10000的结果应该是100余1,我们执行下面汇编代码来查看结果
mov dx,F
mov ax,4241
mov bx,2710
div bx
这里发现余数会存储在dx寄存器中。
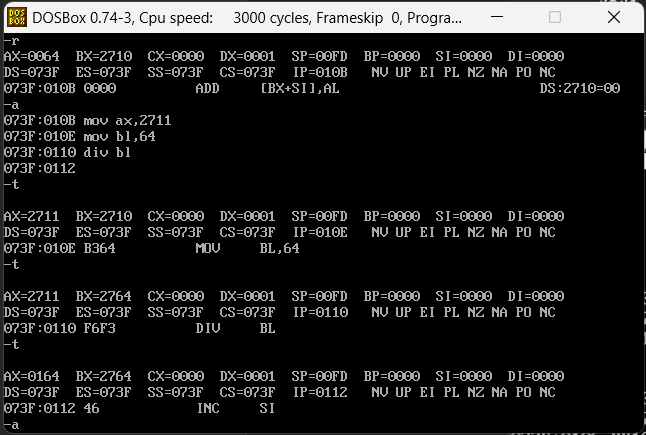
上面的是一个32位占用的被除数,如果被除数是8位,则AL存储除法操作的商,AH放余数,可以参考10001/100,汇编代码如下
mov ax,2711
mov bl,64
div bl
结果应该是100余1,对应的al的值则就是64,ah的值则就是1
AND指令
and指令的作用是按位进行与运算,举个例子

0和0则就是0,1和0还是0,1和1即1,参考汇编代码
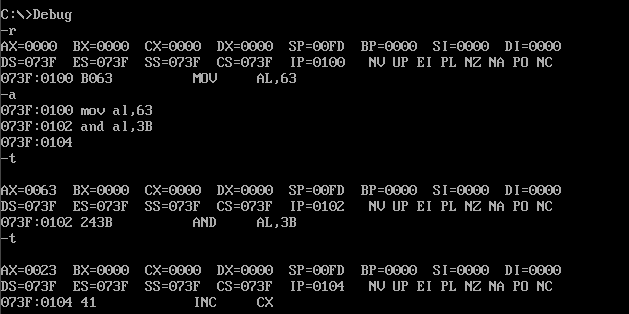
mov al,63(01100011B)
and al,3B(00111011B)
执行过后会把内容丢到al中,运行结果应该是00100011即16进制的23。
OR指令
or指令的作用是按位进行或运算,举个例子
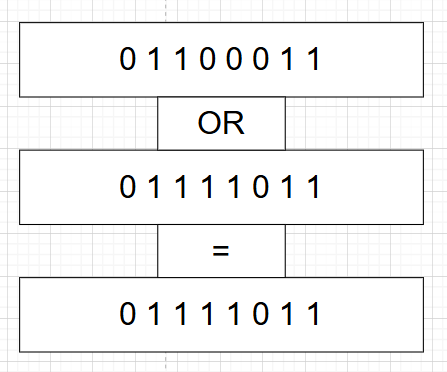
0和0就是0,1和1就是1,1和0就是1,0和1也是1,参考汇编代码
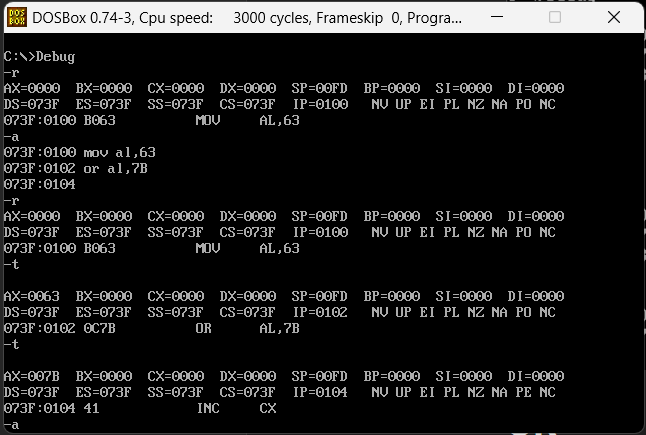
mov al,63(01100011B)
or al,7B(01111011B)
二进制结果应该是01111011,16进制即7B。
SHL和SHR指令
shel和shr分别代表左移和右移,左移就是左边去除一个右边补0,右移则就是右边移除一个左边补零。如下图
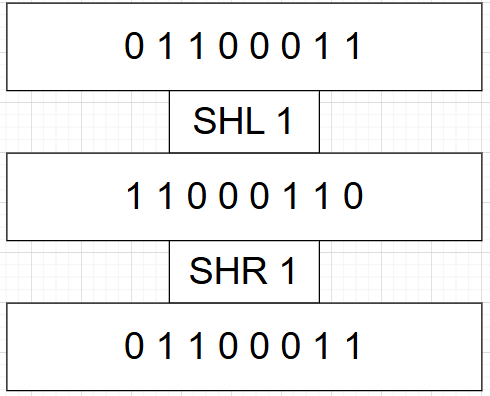
参考汇编代码如下
mov al,63
shl al,1
shr al,1
63的二进制是01100011即16进制63,左移一位二进制变成11000110即16进制C6,右移一位则就变回去了即01100011即16进制的63。

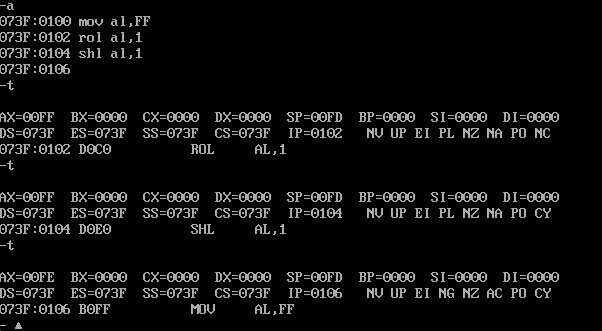
ROL和ROR指令
他俩是循环左移和循环右移,他和普通的左移和右移区别是,循环左移是把最右边的一位补到最左边,循环右移是把最左边的一位补到右边,参考下面的汇编代码查看区别
mov al,FF
rol al,1
shl al,1
FF的2进制是11111111,不管是循环左移还是右翼都是会把一边的1补到另一边,而shl和shr是补0。
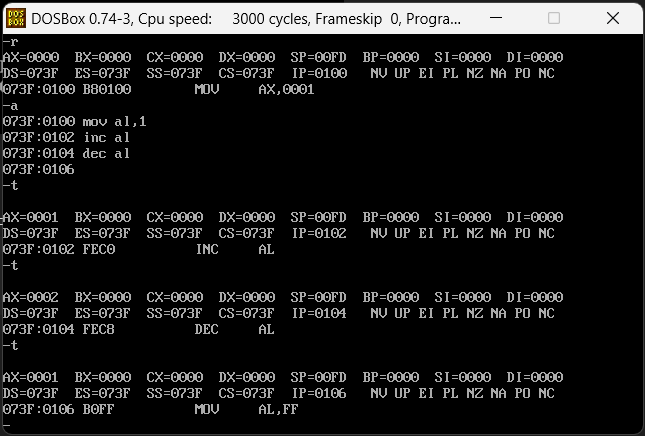
INC和DEC指令
INC和DEC的作用是增加1和减少1,例如C语言中的++和--,例子汇编代码如下
mov al,1
inc al
dec al
这个不错介绍,需要注意的是,如果本身是al是00,再去给他dec(--)那么他就会变成FF,对应的如果是al是FF再去给他inc(++)那就会变成00。
NOP指令
这个指令是空代码段,执行不会干任何事情,他所占的空间恰好是1个字节。这里不多说,后面会用到。
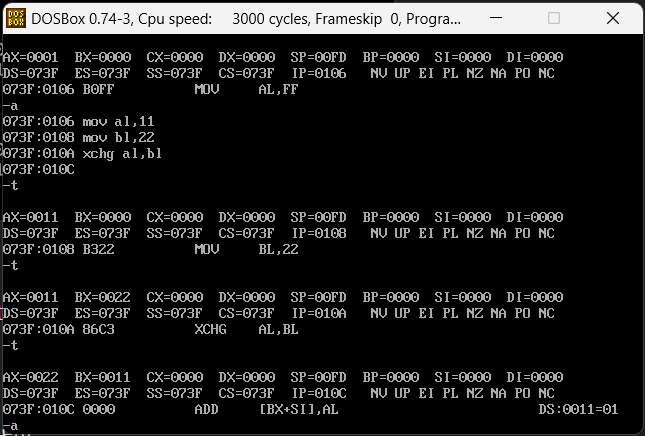
XCHG指令
xchg指令的作用是做数据调换,参考下面汇编代码
mov al,11
mov bl,22
xchg al,bl
al和bl的内容互换了,如果是不通过这个指令来去作交换,则需要三个地方存储数据,A把数据给C,然后B把数据给A,再然后C给B这样才能呼唤,这个指令可以直接交换。
NEG指令
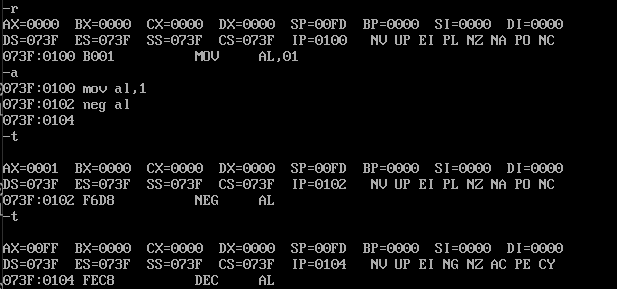
neg的作用是取反并加 1,如果原数据为00000001,通过neg取反+1就是11111110+00000001,具体汇编代码参考如下
mov al,1
neg al
00000001取反就是11111110,再去加1那就是FF了,这里不多说。
INT指令
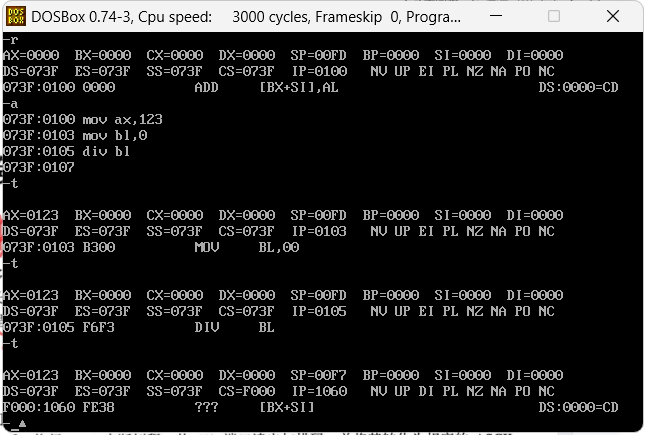
INT指令的含义是中断,在做除法运算的时候如果除数为0那就会自动触发int 0这个指令,也可以手动执行这个指令,这个指令最终会把内存的执行指针做一个跳转,跳转到最初的位置,具体参考案例如下,第一个是除法除以0,汇编代码如下
mov ax,123
mov bl,0
div bl
运行到div命令开始执行除法的时候,把CS和IP调到F000和1060,这个就是执行int 0会发生的事,出现问题则会跳转到这个位置。
第二个例子直接运行int 0
int 0
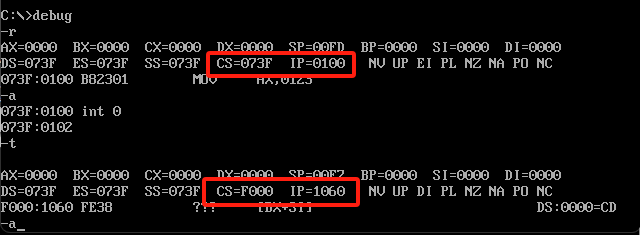
这俩寄存器是用来存储执行代码位置的,他这里直接跳转了。
中断编号有很多,这里是调用的0,除法出现错误也会调用中断0,还有很多后面慢慢接触就可以了。
进阶指令与寄存器
物理地址、段地址、偏移地址关系
我这里说的都是基于8086CPU的内容,其他的可能和我这个不一样的。CPU在访问内存的时候,会用一个基础地址(段地址*16)和一个相对地址的偏移地址相加,给出内存单元的物理地址。
更一般的说,8086CPU的这种寻址功能是“基础地址+偏移地址=物理地址”寻址模式的一种具体实现方案。8086CPU中,段地址x16可看作是基础地址。
段寄存器
在8086CPU中,访问内存时要由相关部件提供内存单元的段地址和偏移地址,送入地址加法器合成物理地址。这里,需要看一下,什么是部件提供段地址。段地址在8086CPU中段寄存器中存放。8086CPU有4个段寄存器:CS、DS、SS、ES。当8086CPU要访问内存时由这四个段寄存器提供内存单元的段地址。
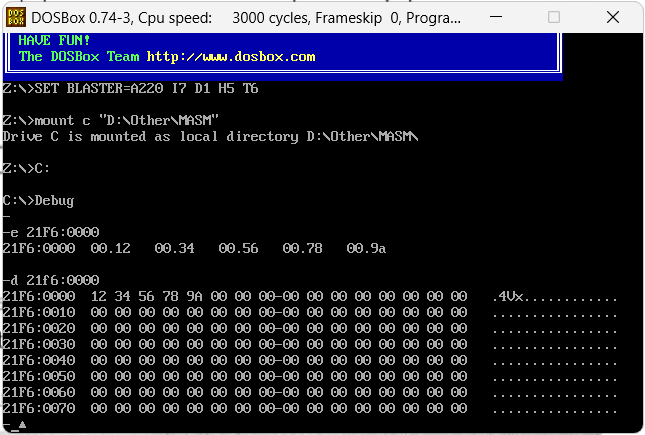
关于内存写入数据
通过Debug程序的e命令可以直接对内存中的数据做修改,可以参考下面截图
DS寄存器-数据段地址
CPU要读写一个内存单元的时候,必须先给出这个内存单元的地址,在8086PC中,内存地址由段地址和偏移地址组成。8086CPU中有一个DS寄存器,通常用来存放要访问的数据的段和地址。举个例子,通过下面debug命令在21f6:0000的位置写入一点内容,命令如下

再去修改DS寄存器的内容,DS寄存器的内容应该是数据段的地址,例如采用debug命令去直接修改DS(段寄存器是不可以直接mov数值修改,需要通过其他寄存器进行赋值)寄存器的内容,参考命令截图如下

通过mov去赋值DS
mov ax,21f6
mov ds,ax
要注意直接去mov ds,21f6是不可行的,他是一个段寄存器在设计的时候就不允许这样。
去执行下面的汇编代码
mov al,[0]
执行之后结果如下
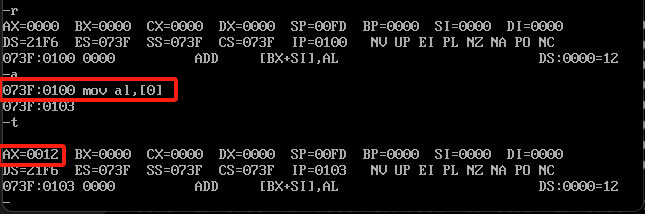
al寄存器变成了12,这个12是哪里来的呢?在执行mov指令的时候,给的值是[0]这个值是指基于数据段地址的偏移,也就是基于DS,21F6这个位置的第0偏移的数据内容给al,即12。
在看一个案例,还是上面的内容,执行下面的汇编指令
mov bx,[2]
结果如下
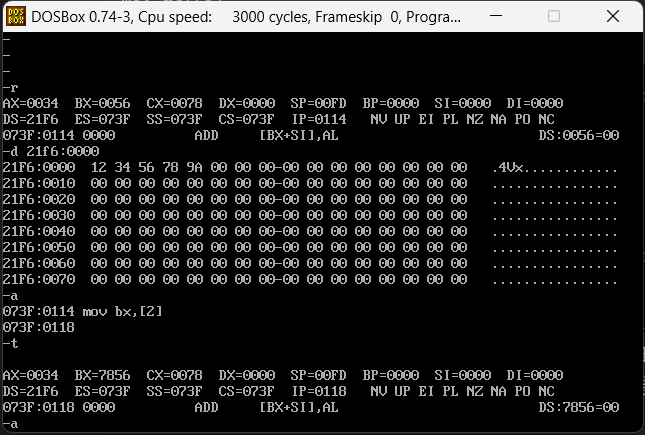
为什么BX是7856?bx给的是216f的第2位,也就是从56开始,数值应该是5678,变成7856的原因是因为他要对其高低位,低位在bl,高位在bh,高位是78,低位是56,对其之后bx就是7856。
CS和IP指令
CS和IP是8086CPU中两个最关键的寄存器,它们指示了CPU当前要读取指令的地址。CS为代码段寄存器,IP为指令指针寄存器,从名称上我们可以看出它们和指令的关系。先看个案例,我们先在2000:0000的位置写入一些汇编指令,参考指令如下
a 2000:0000
mov ax,0123
mov bx,0003
mov ax,bx
add ax,bx
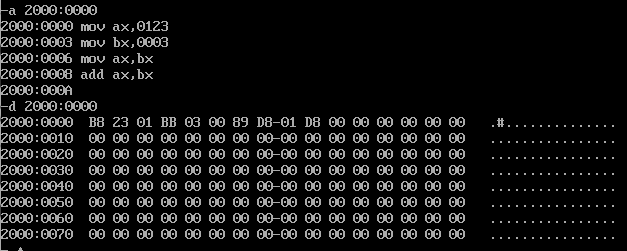
执行过后看一下对应位置的内容,发现里面的内容根本看不懂,这里的内容是刚才汇编指令的机器码,可以使用debug的u命令去看这些内容到底是执行的什么内容,参考下图
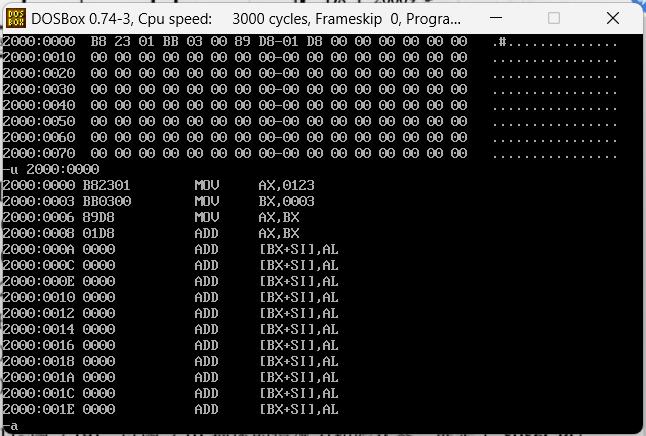
使用u命令可以看到咱们刚才输入的指令,具体怎么执行这些指令呢,这里就可以通过修改cs和ip寄存器来指定咱们写入命令的位置,再去使用t即可执行咱们这些指令,具体操作如下图
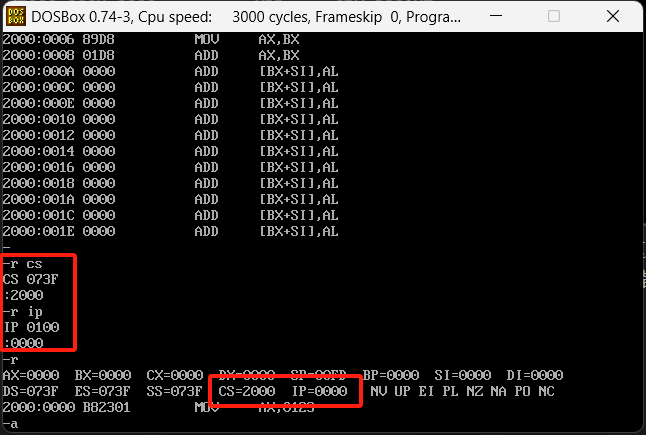
这个时候就相当于命令的指针指向了这里,通过t命令去执行命令结果如下
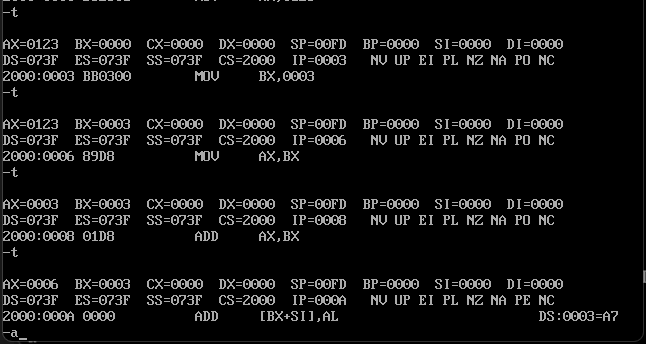
发现咱们再2000:0000设置的指令都依次执行了。
JMP指令
jmp是一个跳转指令,具体的作用可以做一个实践,根据下图把命令写入内存。
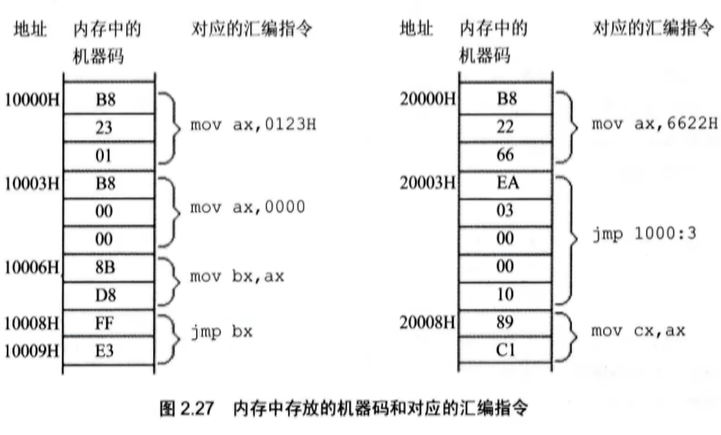
具体命令参考如下
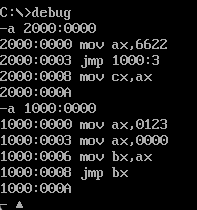
我们把指针跳转到2000:0000开始执行命令,具体命令参考如下
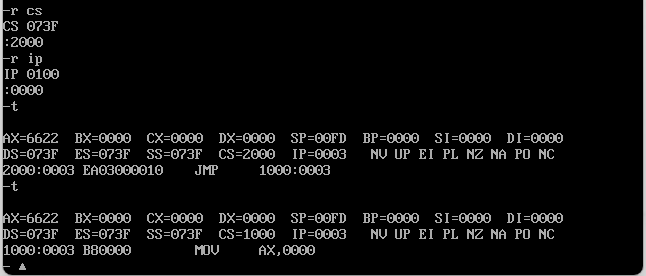
当我们执行第二次的时候也就是命令jmp 1000:3的时候,cs和ip变成了1000和0003,下一个命令就会去执行mov ax,0000了,继续执行查看结果
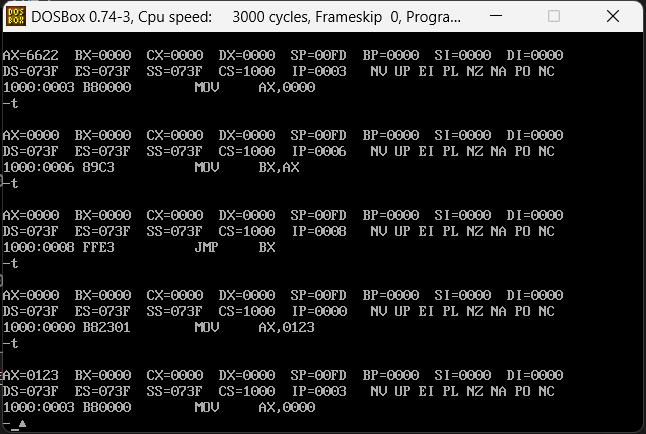
继续执行会发现,他后面会有个jmp指令,jmp的参数是bx,bx是0000,就是把ip改为0000,那就是从mov ax,0123从头继续执行,然后一直重复,如果一直去执行那么这就是一个死循环。
栈概念
栈是一种后进先出的数据结构,通常用于存储临时数据、管理函数调用和返回地址。栈在内存中通常从高地址向低地址增长,用于保存寄存器值、局部变量等。简单说,就是程序运行时的“临时记事本”。
SS和SP寄存器
这两个寄存器用来定义栈顶的位置,基于栈的操作都是基于这俩寄存器指定的位置来做操作。这俩也是段指令,无法直接mov xx,数值来直接赋值,得通过mov 寄存器,段寄存器来修改,或者通过debug名的r命令去修改。
PUSH和POP指令
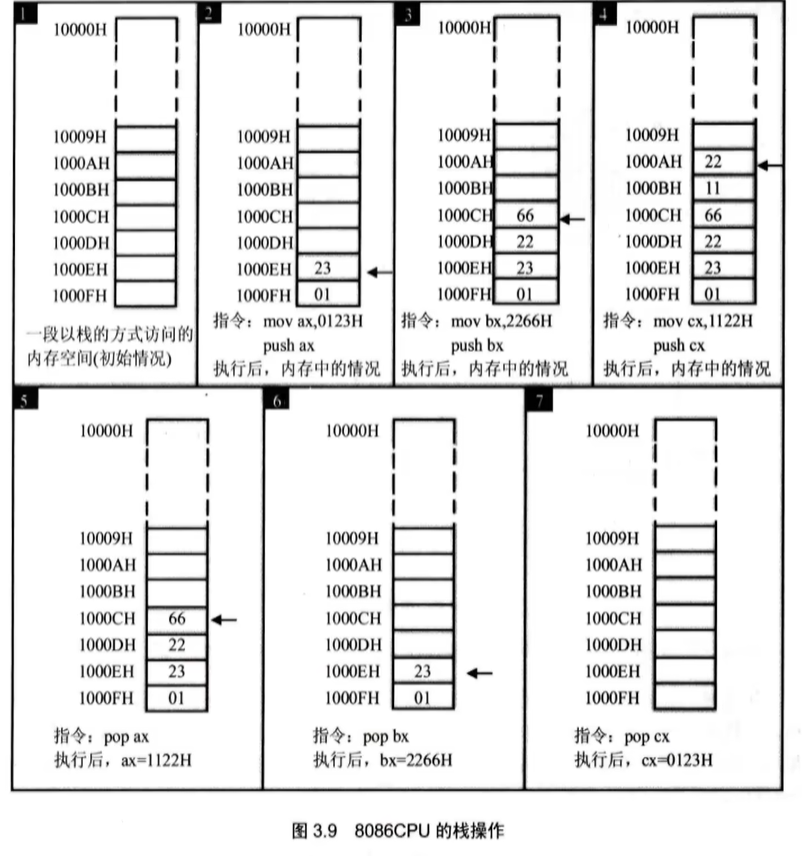
push就是压栈,指的是将一个元素添加到栈的顶部。pop就是出栈,指的是从栈的顶部移除并返回一个元素。
push和pop指令具体可以参考下图
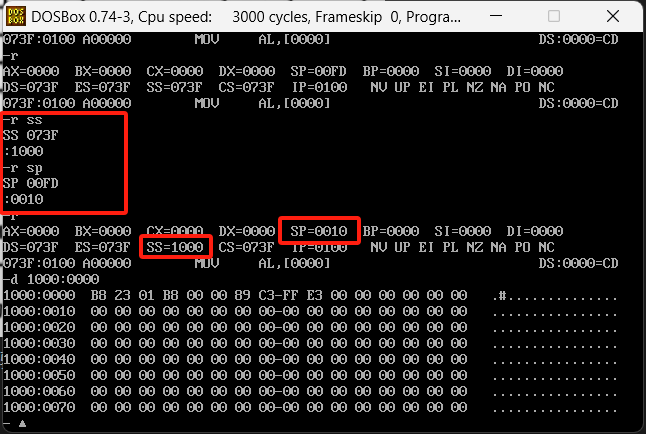
下面做个实验,我们先指定1000:0010这块内存作为栈实验的栈顶,用来做压栈和出栈的实验,通过debug的r命令来修改ss和sp段寄存器,如下图
我们根据最上面的指令进行操作,我们先把指令写进去然后一步一步去执行,具体的汇编指令如下
mov ax,0123
push ax
mov bx,2266
push bx
mov cx,1122
push cx
pop ax
pop bx
pop cx
先去执行前两条查看一下栈里的内容有啥变化
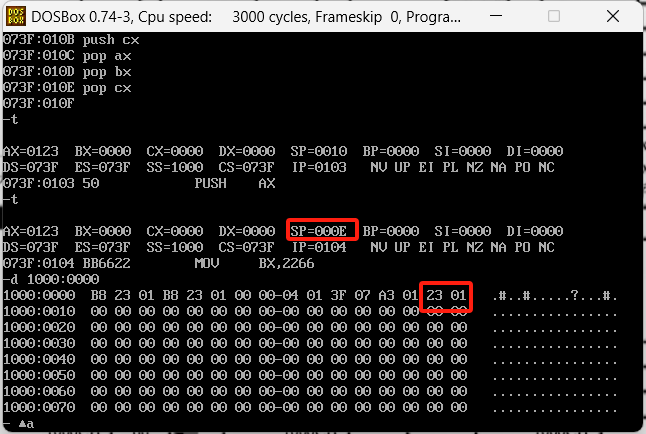
0123被压入栈了,而且是顶部,并且SP也发生了更变,我们继续把压栈的命令都执行完,还剩4条,看一下结果
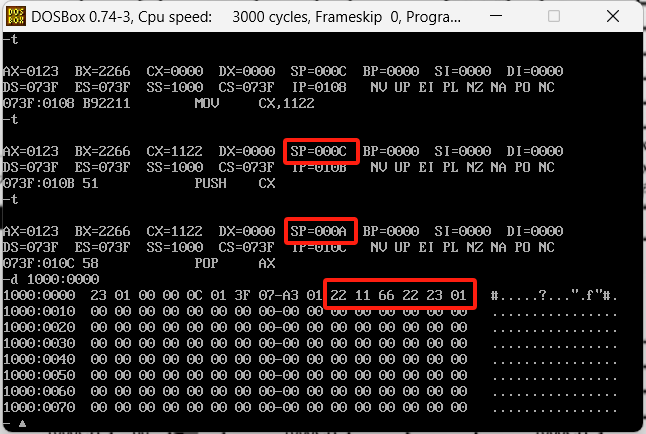
全部压进去了,并且位置是往小的来推进的。
接着我们继续执行指令,还有三条pop指令,先执行一条查看一下效果
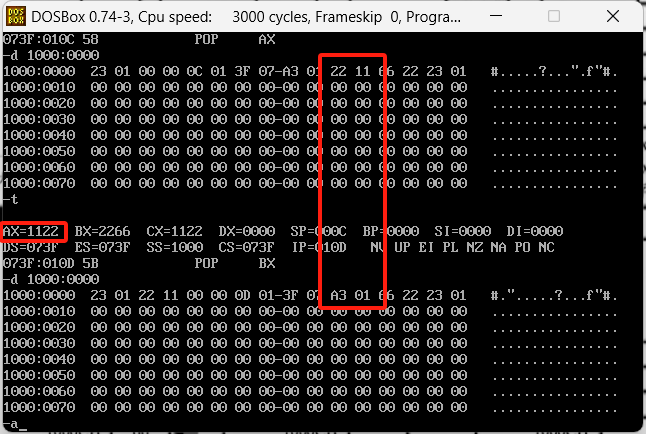
原本栈内的2211,已经被丢到ax中了,并且他是把第一个丢到低位,然后第二个丢到高位中,这个操作不回去平衡高低位。接着继续执行两个pop命令,执行结果如下
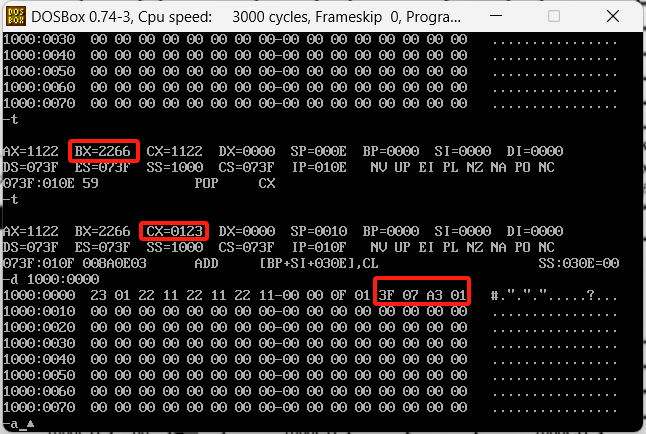
栈内的数据以此丢到了bx和cx中了,并且栈内也没内容了,这里的内容其实我举得例子不好,应该找一块全空的位置来去做这个实验。这里他自动填充了其他数据。
BX寄存器的独特性
bx寄存器有一个额外的作用,就是它可以来指明内存单元,这个是其他大部分寄存器做不到的,举个例子,在2000:100的位置放一些数据,命令如下

修改DS数据段的地址为2000,然后通过偏移位置来去设置其他寄存器的内容,命令如下

这里发现ax成功更变成了2000:100位置的内容,这个在上面也进行过,下面开始通过bx来去当作编译来去拿数据,命令如下
mov bx,0102
mov ax,[bx]
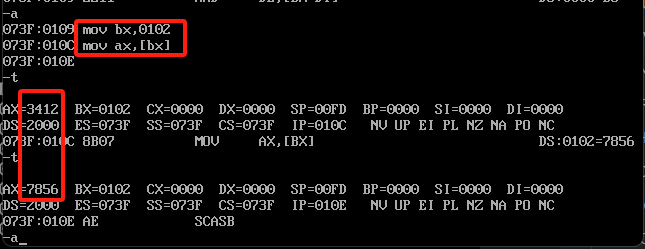
这里发现通过bx的偏移设置了ax的内容,他还有其他的写法,具体命令如下
mov ax,[bx-1]
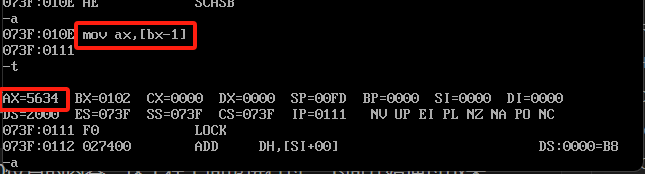
这样也是可以的,本身bx是0102通过[bx-1]那就是0101的偏移位置来写入ax,把寄存器当作偏移的操作只有bx能做到,尝试其他的会报错,具体错误可以参考下图
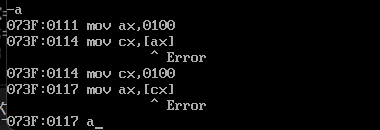
使用mov cx,[ax]和mov ax,[cx]都是不可行的,这个功能是bx单独的功能但不是他独有的功能,后面会说其他的,这个bx寄存器也一般用来存储偏移地址。
SI和DI寄存器
si和di是8086CPU中和bx功能相近的寄存器,si和di不能够分成两个8位寄存器来使用。具体使用方法和上面BX寄存器一样。然后这些可以用来当作偏移来用的寄存器可以相加,例如下面汇编指令
mov cx,[bx+si]
mov cx,[bx+di]
# 下面这个不允许
mov cx,[si+di]
BP寄存器
他和上面的BX、SI、DI用处都是可以指明内存单元。但是BP在用法上和它们三个是有区别的,BX、SI、DI采用这三个寄存器去寻址的时候,他是基于DS寄存器来做偏移找内容,而BP是基于SS寄存器,这个SS寄存器上面也讲述了他是用来设置栈顶的段地址的,BP也可以理解为基于栈顶的位置偏移找内容。具体可以参考下面的案例,我在5000:0000和6000:0000的位置存放了一些内容,一个正序一个倒叙

下面我把这俩位置分给数据段地址和栈顶的位置,参考下面代码
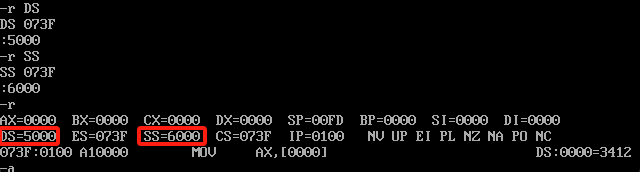
之后开始测试数据,具体执行的汇编代码如下
mov bx,0001
mov ax,[bx]
mov bp,0001
mov ax,[bp]
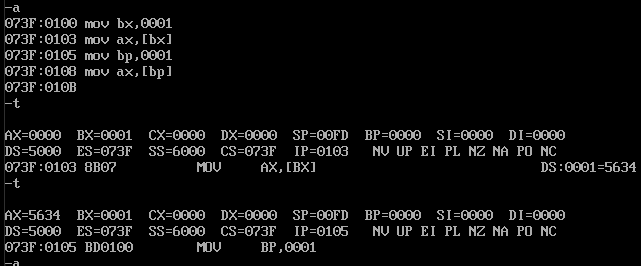
ax现在的内容是5000:0000位置偏移为1的内容,我们再去看bp的内容,继续执行两次查看结果
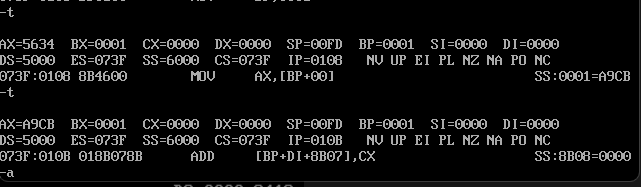
ax变成了A9CB,这里的内容是从6000:0000中拿出的。要注意的是bp是可以配合其他的寄存器和偏移使用的,但是他不可以配合bx寄存器来用,因为bx是基于DS寄存器的。具体参考下面汇编代码,以及报错输出
mov ax,[bp]
mov ax,[bp+1]
mov ax,[bp+si]
mov ax,[bp+di]
# bp和bx不能一起用
mov ax,[bp+bx]
错误输出如下
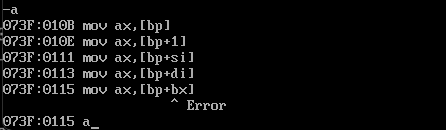
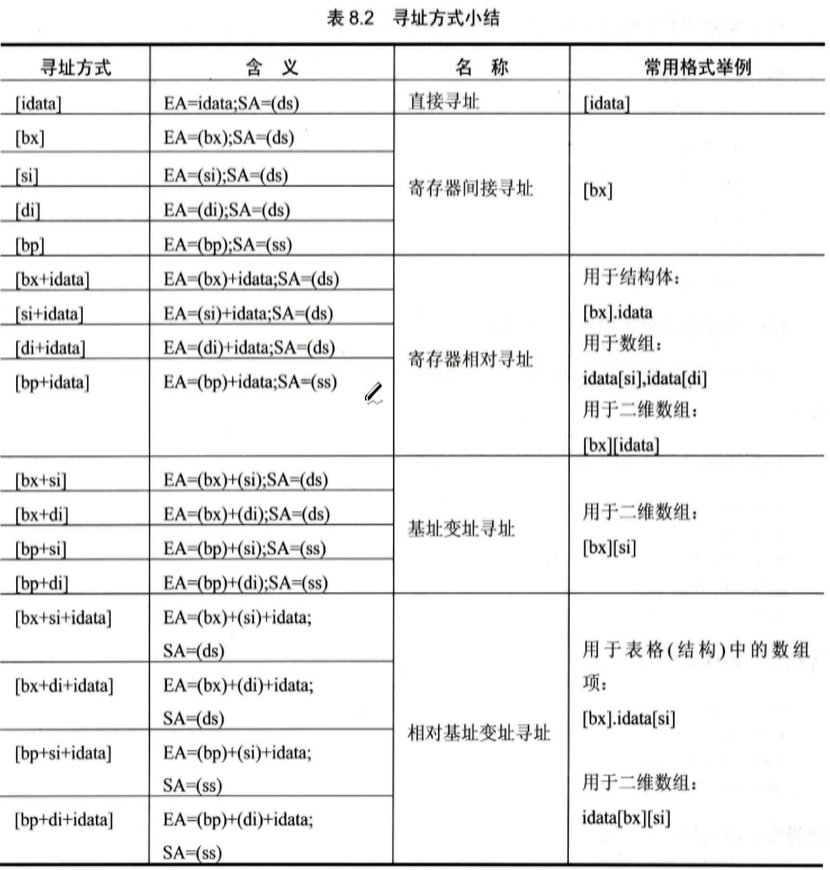
寻址寄存器相关总结
标志位寄存器
CPU内部的寄存器中,有一种特殊的寄存器(低于不通的处理机,个数和结构都可能不同)具有以下三种作用。
- 用来存储相关指令的某些执行结果。
- 用来为CPU执行相关指令提供行为依据。
- 用来控制CPU的相关工作方式。
这些特殊的寄存器在8086CPU中,被称为标志寄存器。8086CPU的标志寄存器有16位,其中存储的信息通常被称为程序状态字(PSW)。我们已经使用过8086CPU的ax、bx、cx、dx、si、di、bp、sp、ip、cs、ss、ds、es等13个寄存器了,当前章节的标志寄存器(以下简称flag)是我们要学习的最后一个寄存器。
flag和其他寄存器不一样,其他寄存器是用来存放数据的,都是整个寄存器具有一个含义。而flag寄存器是按位起作用的,也就是说,它的每一位都有专门的含义,记录特定的信息。
8086CPU的flag寄存器的结构图如下

flag的1、3、5、12、13、14、15位在8086CPU中没有使用,不具有任何含义。而0、2、4、6、7、8、9、10、11位都具有特殊的含义。
在这一章节中,我们学习标志寄存器中的CF、PF、ZF、SF、OF、DF标志位,以及一些与其相关的典型指令。
ZF标志
flag的第6位是ZF,0标志位。他记录相关指令执行后,其结果是否为0。如果结果为0,那么zf=1;如果结果部位0,那么zf=0。
参考下面汇编指令,来去验证zf的变动
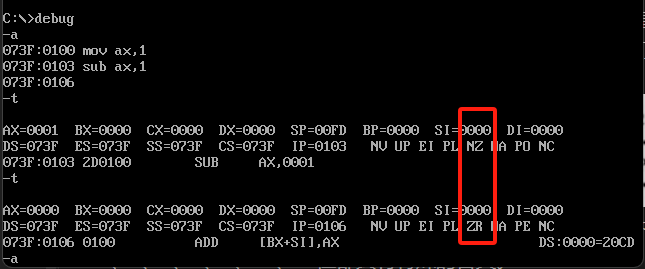
mov ax,1
sub ax,1
执行结果在Debug中的体现如下图,先把ax改成1,执行之后NZ那个东西就是ZF标识即NoZero应该是这样理解,这是我自己理解的。然后等sub命令执行之后ax变成了0,ZF标志位变成了ZR,他代表zero
PF标志
flag的第二位是PF,奇偶标志位。他记录相关指令执行后,其结果的所有bit位中1的个数是否为偶数。如果1的个数为偶数,pf=1,如果奇数,那么pf=0。在命令中的具体体现可以参考下面汇编代码
mov ax,0000
add ax,1
add ax,1
add ax,1
执行结果如下,pe即代表偶数也就是pf=1,po即代表是奇数也就是pf=0
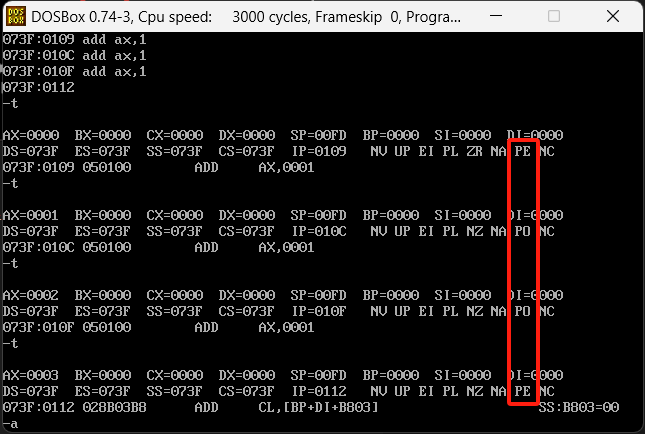
然后这里有个问题,算奇数偶数为什么ax的值是1和2的时候都是奇数呢?因为他算的是一个bit中的1的数量,ax=0001的时候,他的bit8位表示是00000001他就一个1所以标识奇数,ax=0002的时候,他的bit8位标识是00000010,还是一个1,所以还是一个奇数。
SF标志
负数如何表示?
在二进制中,负数的表示方式通常采用 补码,它的计算方法如下:
- 正数:与原码相同
- 负数:
- 先求该数的 绝对值的二进制(原码)。
- 按位取反(0 变 1,1 变 0)。
- 加 1(即 +1 操作)。
假设使用 8 位二进制来表示 -5:
- +5 的二进制(原码): 00000101
- 按位取反: 11111010
- 加 1: 11111011(即 -5 的补码)
所以,-5 在 8 位二进制中表示为:11111011
实验
flag的第七位是SF,符号标志位。他记录相关指令后,结果是否为负。如果结果为负,SF=1;如果非负,SF=0。计算机中通常用补码来标识有符号数据。计算机中的一个数据可以看作是有符号数,也可以看成是无符号数。比如:
- 00000001B,可以看作为无符号数1,或有符号数+1;
- 10000001B,可以看作无符号数129,也可以看作有符号数-127;
也就是说对于同一个二进制数据,计算机可以将他当作无符号数据来运算,也可以当作有符号数据来运算。比如下面汇编代码
mov al,10000001B(81h)
add al,1
可以将add指令进行的运算当作无符号的运算,那么add指令相当于计算129+1,结果为130(10000010B);也可以将add指令进行的运算当作有符号数的运算,那么add指令相当于计算-127+1,结果为-126(10000010B)。
下面举个例子,执行下面汇编代码
mov ax,0
add ax,1
sub ax,1
sub ax,1
add ax,1
sub ax,1
执行4次后的输出如下
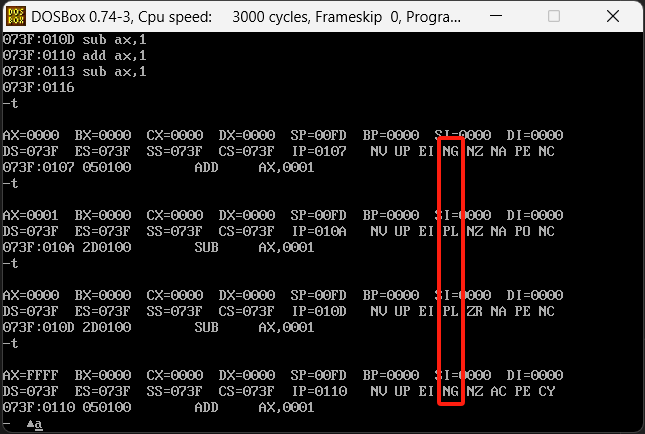
在mov的时候是ng即负,这应该是一个默认值,然后变成正数之后变成了PL,然后从0减到-1的时候变成了NG,好,继续运行
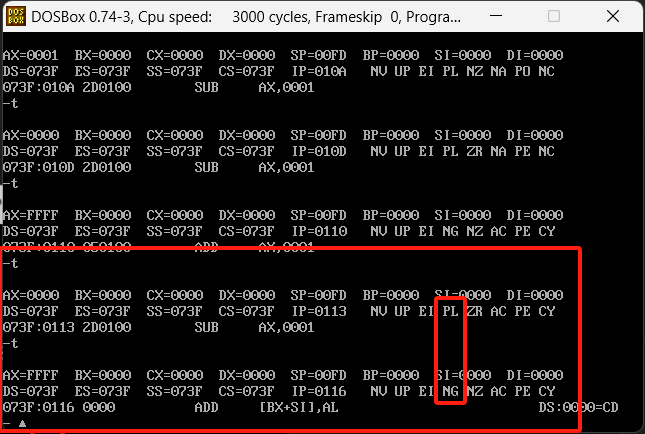
继续运行是+1然后-1 变成0之后在变-1,对应的这里的SF标志也在变。
CF标志
flag的第0位是CF,进位标志位。一般情况下,在进行无符号数运算的时候,他记录了运算结果的最高有效位向更高位的进位值,活从更高位的借位值。对于位数为N的无符号数来说,其对应的二进制信息的最高位。
看个例子,执行下面汇编代码
mov al,10
mov bl,10
add al,bl
mov al,20
mov bl,21
add al,bl
mov al,98
mov bl,98
add al,bl
先看前3个执行效果,如下
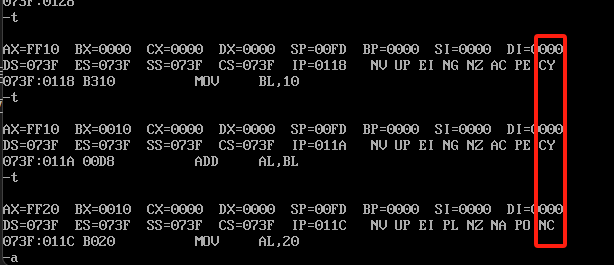
CY代表进位,NC代表没有,也可以理解为进位,是否影响了更高位
继续执行3个效果,运行结果如下
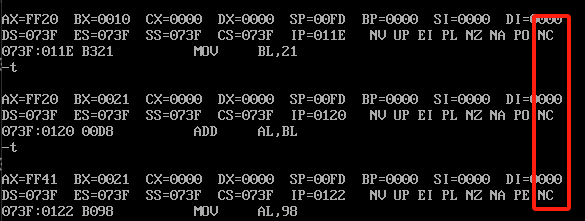
这里al-20去加bl-21变成了41,更高位没有变化,所以都是NC,继续执行后三条指令,运行结果如下
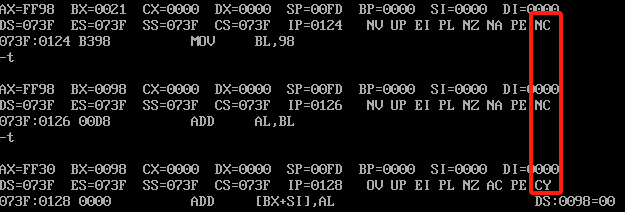
这里影响更高位了,98h+98h=130h,所以变成了CY。
OF标志
在进行有符号运算的时候,如果结果超过了机器所能表示的范围称为溢出。
那么什么是机器所能表示的范围呢?
比如说,指令运算的结果用8位寄存器或内存单元来存放,比如,add al,3,那么对于8位的有符号数据,机器所能表示的范围就是-128~127。同理,对于16位有符号数据,机器所能表示的范围是-32768~32767。
注意,这里所说的溢出,只是对有符号数运算而言。参考下面的例子,汇编代码如下
mov ax,634
mov al,63
mov bl,62
add al,bl
mov al,10
mov bl,20
add al,bl
mov al,ff
mov bl,ff
add al,bl
mov al,aa
mov bl,aa
add al,bl
先执行4次命令,结果如下
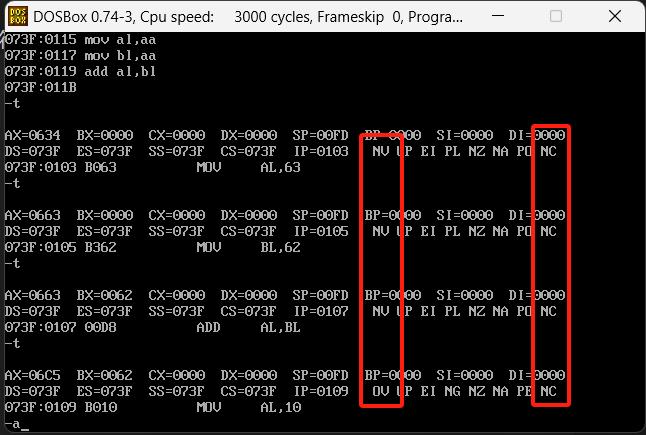
第一竖行是OF标志位,第二竖行是CF标志位,OV就是代表溢出了,那为什么63h+62h就溢出了?他会产生一个正的197,如果是带符号的那就是负的59,而8位能表示的范围是-128~127,不带符号的结果出现了溢出。继续运行3次指令,结果如下
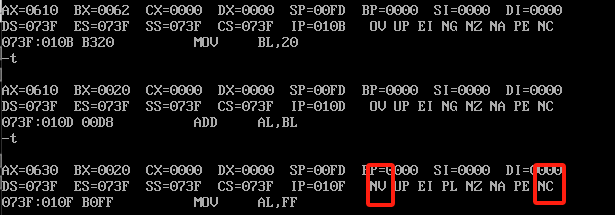
这个是没有进位也没有溢出的结果,我们继续运行三次看一下结果
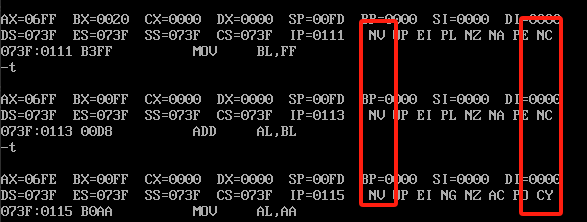
FF+FF最终是1FE,没有溢出但是影响了最高位,好,我们继续看,再次执行3次指令,结果如下
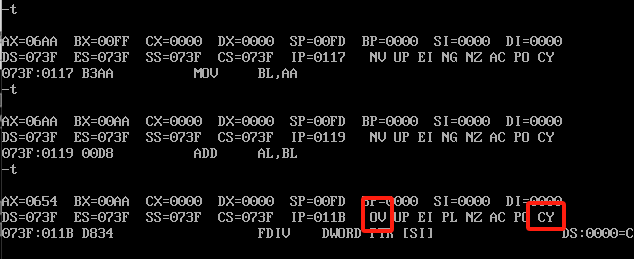
aa+aa的结果是154,高位进了,而且八位最高127,他这里154也溢出了。(这个位置其实我并没有理解,看了一会感觉应该是没那么重要,后面用到再回来看应该理解会更加深入一些,有清楚的大佬欢迎指正。)
ADC指令
ADC是带进位加法指令,它利用了CF位上记录的进位值。具体用法参考下面汇编代码
mov ax,2
mov bx,1
sub bx,ax
adc ax,1
执行过后发现经过adc指令之后ax变成了4,ax(2)+1变成了4,为什么会这样呢?按照当前例子来算,他的加法原理是(ax)=(ax)+(1)+CF,他在add基础上加上了一个CF标志位寄存器的内容,这个CF是一个进位的标志位,在第三条命令的时候bx(1)-ax(2)的时候借位了,而CF要么是0要么是1,借位的时候变成了1,他就会多加1,结果就变成4了。
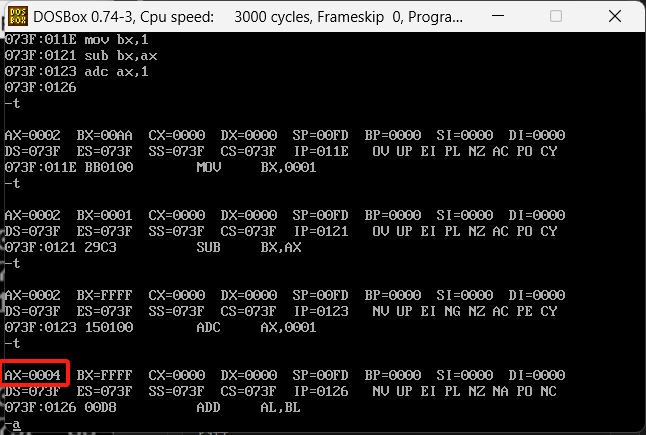
这个指令一般应用到下面场景,汇编代码如下
mov ax,0198
mov bx,0183
add al,bl
adc ah,bh
最终ax的结果是正确的,在al(98)+bl(83)的时候会产生进位,进位的那个一个数值会直接丢弃,通过adc计算高位就可以拿回刚才进位产生的一个数值。
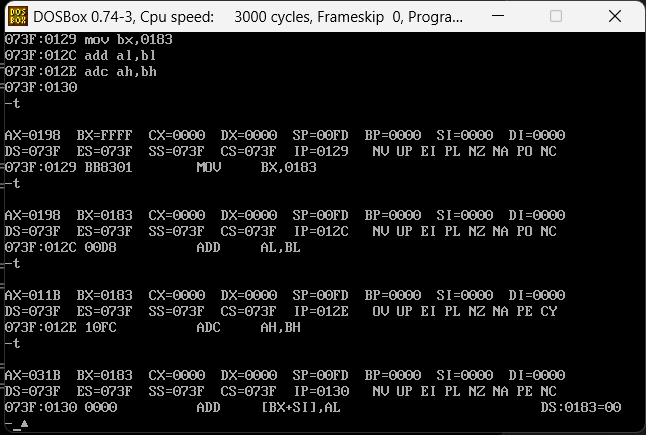
SBB指令
sbb是带借位减法指令,它利用了CF位上记录的借位值。举个例子,汇编指令为sbb ax,bx最终的运算结果是(ax) = (ax) - (bx) - CF
这个指令和adc设计思想都是相同的,具体的例子这里不多讲述。虽然这两个命令并不常用,但是我们通过学习这两条指令,可以领会一下标志位寄存器CF位的作用和意义。
CMP指令与跳转指令
cmp是比较指令,cmp的功能相当于减法指令,只是不保存结果。CMP指令执行后,将对标志寄存器产生影响。其他相关指令通过识别这些被影响的标志寄存器位来得知比较结果。具体参考如下
ZF(零标志,Zero Flag):如果比较结果为0(即目的操作数等于源操作数),ZF置1。
SF(符号标志,Sign Flag):结果的最高位(符号位)为1时,SF置1,表示结果为负。
CF(进位标志,Carry Flag):如果目的操作数小于源操作数(无符号数比较),CF置1。
OF(溢出标志,Overflow Flag):如果有符号数运算溢出,OF置1。
PF(奇偶标志,Parity Flag):结果低8位中1的个数为偶数时,PF置1。
AF(辅助进位标志,Auxiliary Carry Flag):低4位向高4位有进位时,AF置1。
它通常与跳转指令配合使用,下面是一些常用的跳转指令
JE 等于则转移 ZF=1
JNE 不等于则转移 ZF=0
JB 低于则转移 CF=1
JNB 不低于则转移 CF=0
JA 高于则转移 CF=0且ZF=0
JNA 不高于则转移 CF=1或CF=1
这些指令都比较常用,它们都很好记忆,它们的第一个字母都是J,表示JUMP;后面的字母表示含义如下
e 表示equal
ne 表示not equal
b 表示below
nb 表示not below
a 表示above
nb 表示not above
这里就不作实验了,后面会直接使用,具体可以参考下面章节的内容。
源文件编写代码
运行ASM源代码文件
在最初安装学习环境的时候,工具包中提供了很多二进制命令,运行源码文件可以通过MASM去处理成OBJ文件,通过LINKE编译成可执行文件,然后通过debug去运行。具体参考案例如下
先创建一个asm文件,内容如下
assume cs:codesg
codesg segment
mov ax,0123H
mov bx,0456H
add ax,bx
add ax,ax
mov ax,4c00H
int 21H
codesg ends
end
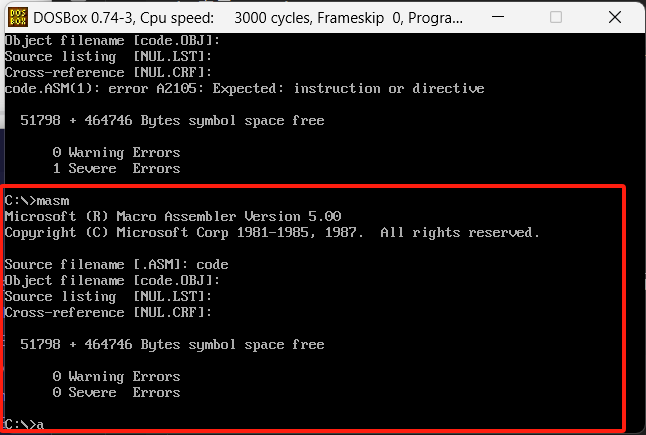
之后在DOSBox中执行MASM指令去处理,参考下面运行结果
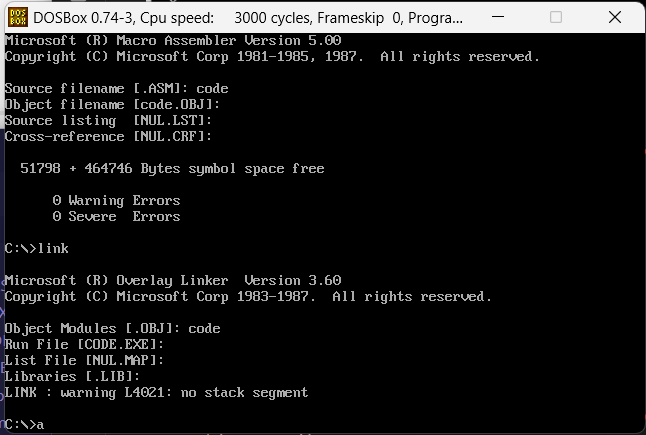
之后通过link去做编译
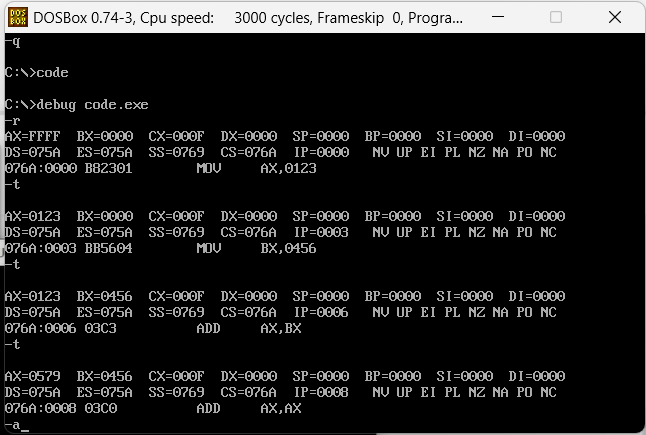
此时这个目录下会多出一个CODE.EXE,因为这些代码并没有实际能实现什么效果,直接运行不会出现任何内容,可以采用debug的形式去运行他,参考下面结果
LOOP指令
对于汇编指令,loop指令是无法在debug中写的,因为他是要去写函数的,在debug中无法直接去写,他涉及了一些伪指令,需要去txt中去写。LOOP指令的作用是循环,CPU在执行LOOP指令的时候,要进行两步操作,先是(cx)=(cx)-1,然后判断cx中的值,不为零则转至标号处执行程序,如果为0则向下执行。具体参考例子为计算2的12次方,参考代码如下
assume cs:code
code segment
mov ax,2
mov cx,11
s: add ax,ax
loop s
code ends
end
执行4次结果如下
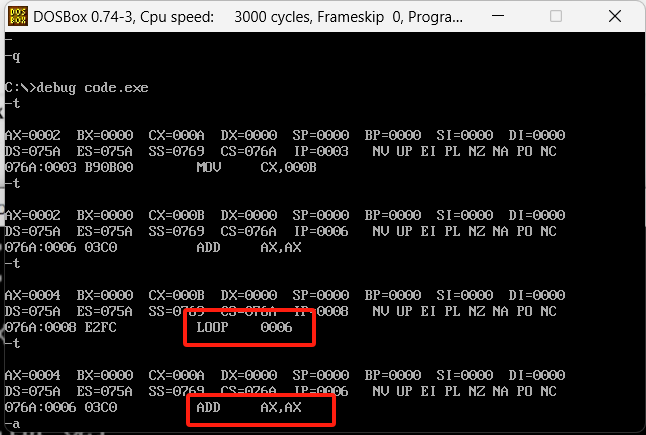
loop干了一个偏移的事,把IP寄存器改成了0006,我们通过u命令查看一下这个位置的内容,如下图
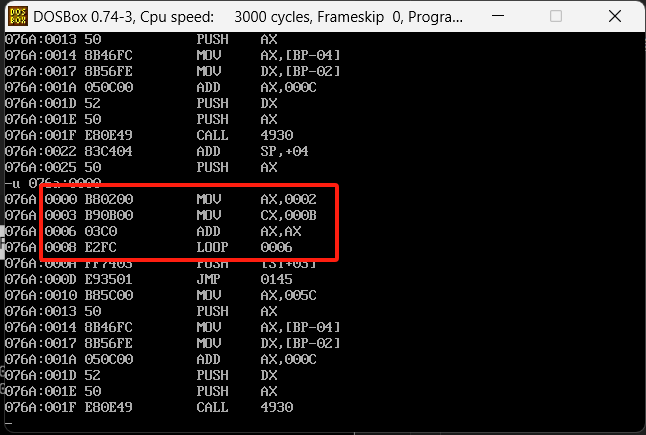
发现0006就是s函数中的内容。继续执行会发现一直在0006这个偏移中跳转,并且发现CX每到loop的时候都会-1
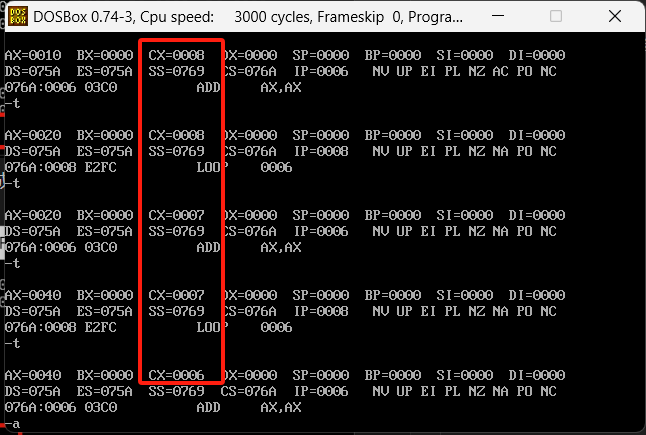
一直到cx到0的时候IP到了000A,并且不再继续跳转,2的12次方也拿到了正确的数值
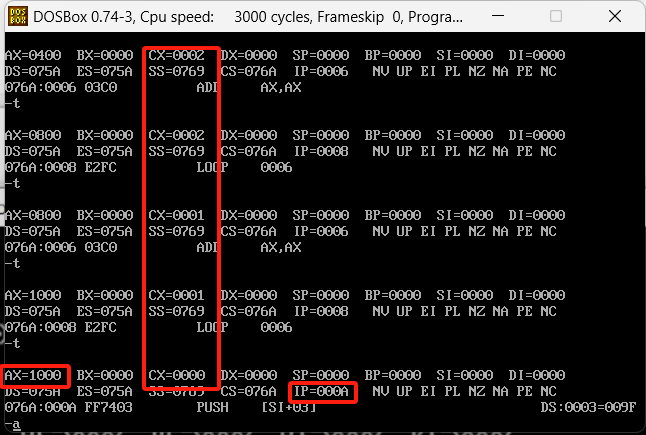
要注意的是,loop执行之前,cx不要为0,因为它运行会先去给cx-1,然后去判断是否为0再去执行,cx如果是0然后-1,那么他就会变成FFFF,会一直把FFFF循环完,近似于一个死循环了......
Debug指令G
上面的loop案例都是通过debug的t指令一步一步执行的,我们也可以使用debug的g指令一次性执行到头,例如我们整个命令是到000A结束,参考下图
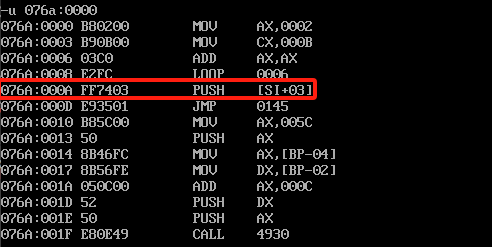
我们可以直接通过debug的g命令运行到这个位置,使用结果如下图
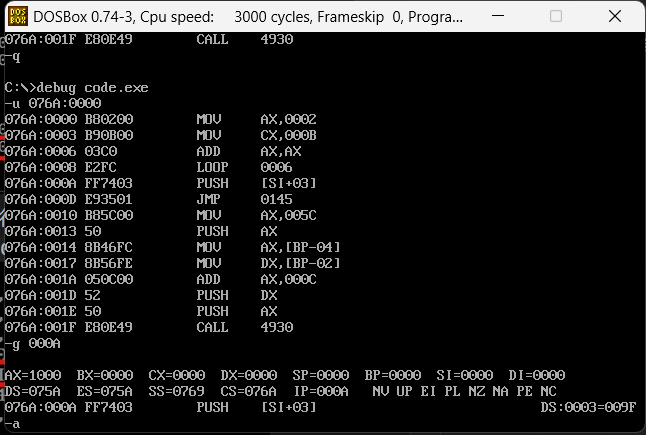
直接用G跳转到了000A并且成功运算出了结果。
Debug指令P
上面使用了t一步一步执行,也用了g一次性执行到某个位置,然后我再学习一下p指令,他的作用是把当前当前循环执行的命令一次性运行完。参考下面执行结果

CX到A也就是10的时候我这里直接输入p一次性执行完循环了,直接成功运算出了结果。
CALL与RET指令
call和ret都是转移指令,他们都修改IP,或同时修改CS和IP。他们经常被共同用来实现子程序的设计。上面是简单创建了一个函数去使用,函数写进去之后,会被直接根据顺序直接调用,那么我们如何更优雅的去运行他们呢?这里就可以通过CALL和RET指令来去配合使用,具体参考下面代码
assume cs:code
code segment
mov ax,2
mov cx,11
call s
int 21H
s: add ax,ax
loop s
ret
code ends
end
运行就不具体运行了,要注意的是int 21H这个中断,这个中断的含义是用来结束运行的,如果没有这个则会继续返回到call执行的下一个指令即运行s函数的内容,可能会造成于一个近似死循环的一个行为。。。
RET和RETF
ret指令用栈中的数据,修改IP的内容,从而实现近转移;
retf指令用栈中的数据,修改CS和IP的内容,从而实现远转移。
具体应用的体现在哪呢?如果使用ret,他只能修改IP的内容,也就是偏移的值,但是偏移是有上线的,在8086CPU中,偏移的上线是FFFF,超过这个就回不去了,而retf还可以修改cs寄存器,这样修能实现远偏移。
call和“call far ptr”
call和“call far ptr”的关系和ret与reft的关系基本对应,有一个近远的区别。
具体使用就是下面代码
assume cs:code
code segment
mov ax,3
mov cx,11
call far ptr s
int 21H
s: add ax,ax
loop s
retf
code ends
end
我这里就不继续运行了,看一参考底部案例实践的内容。
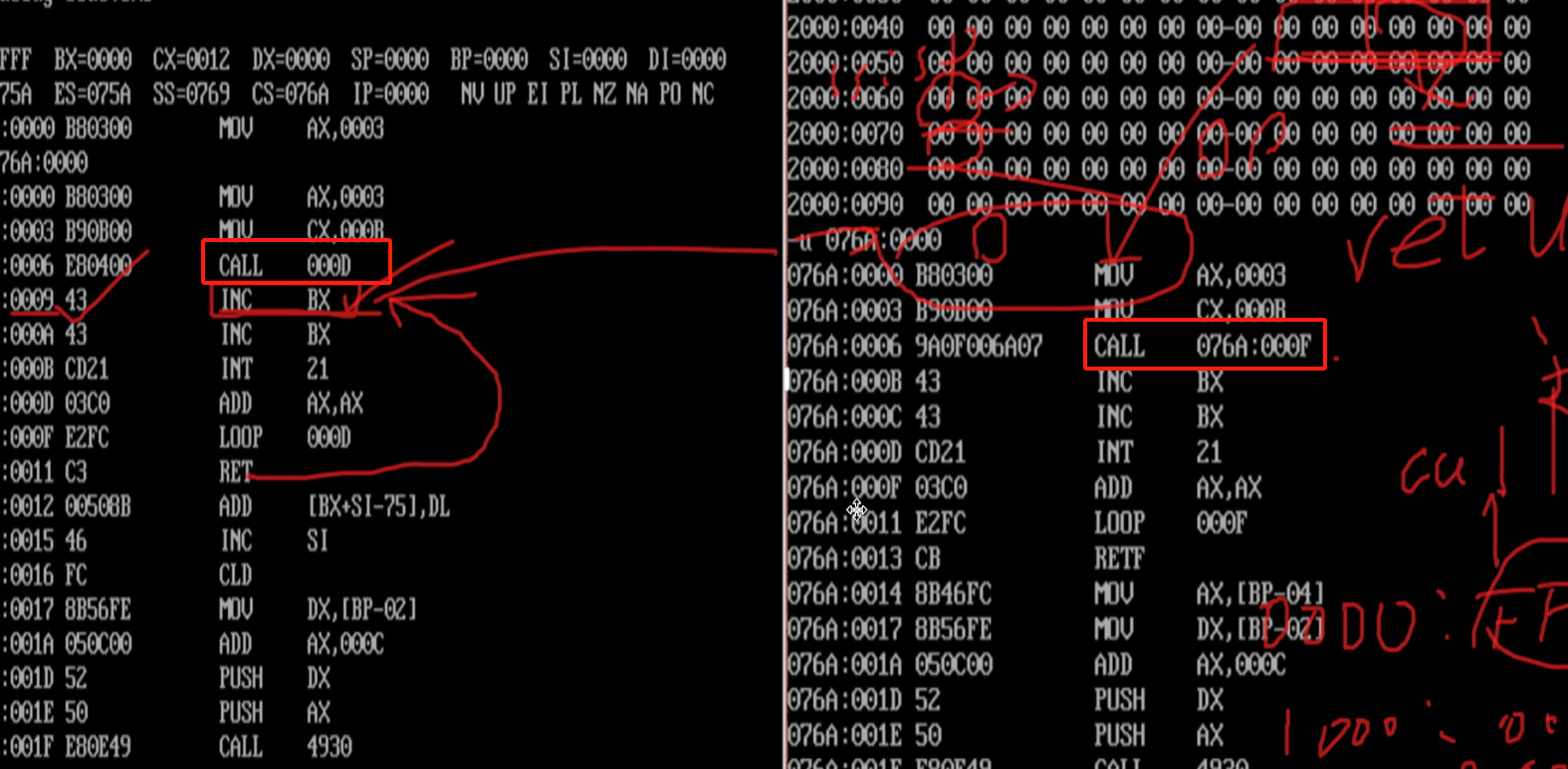
CALL指令的本质
CPU执行CALL指令的时候,会进行两步操作,首先会把当前的IP或CS和IP压入栈中。然后转移到被调函数的位置。CALL指令不能实现短转移,除此之外,CALL指令实现转移的方法和JMP指令的原理相同。
RET指令的本质
当CALL指令把指针相关数据压入栈中,最终执行到RET的时候,会进行弹栈的操作,然后修改指针偏移。
案例实践
以下面代码为例,我们看一下栈中的内容
assume cs:code
code segment
mov ax,2
mov cx,11
call s
int 21H
s: add ax,ax
loop s
ret
code ends
end
我们先设置一块空的地方为栈顶
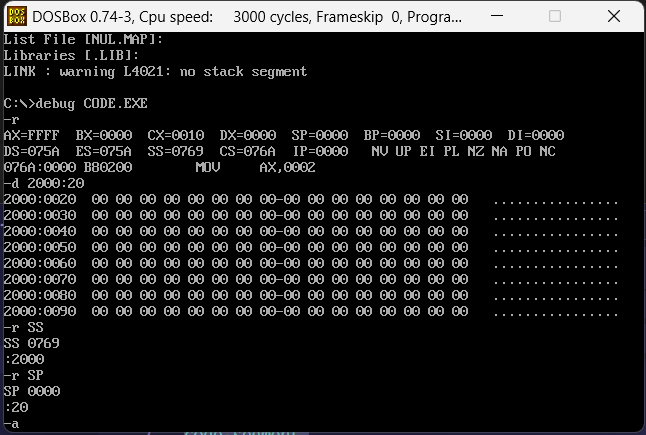
然后把命令执行到call s的下一条指令,看一下栈中的数据

这里存储了一个0900,这个是高低位转换之后的,实际应该是0009,我们再看一下我们命令的偏移,如下图
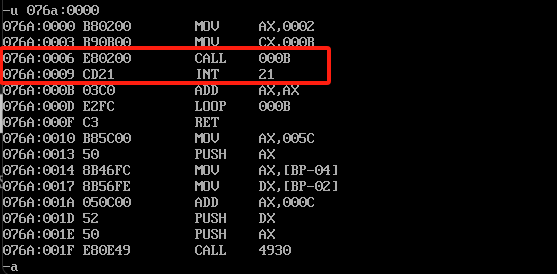
0009的偏移位置是直接ini 21刚好对应执行顺序,我们去运行到ret的时候会自动弹栈拿到这个位置,并跳转。一直到ret,CS和IP的内容更变如下
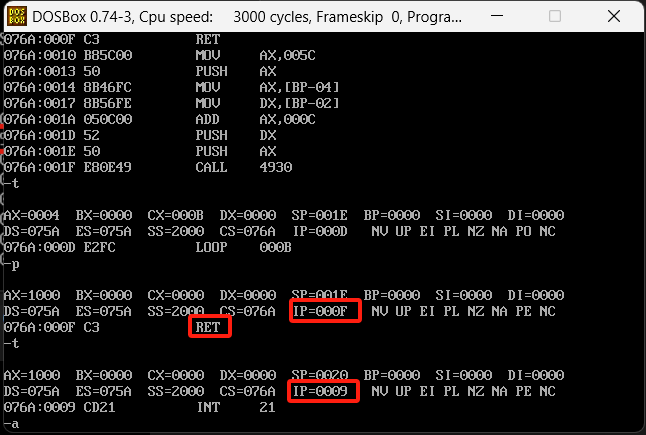
这里是call和ret的对应关系,然后call far ptr和reft是对应的,远位转移在栈中存储的是CS和IP的位置,这个要注意,具体参考下图。
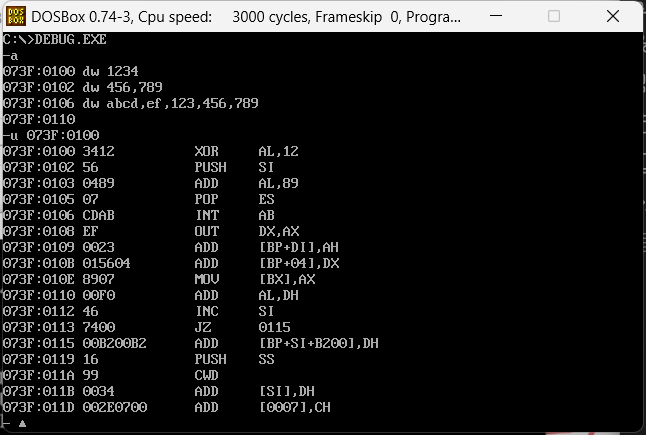
代码中装载数据
MASM内部以数据位的个数定义了多种数据类型
- BYTE,db,8bit
- WORD,dw,16bit
- DWORD,dd,32bit
- QWORD,dq,64bit
我们通过debug用这些指令定义数据查看一下会CPU会执行什么内容
dw 1234
dw 456,789
dw abcd,ef,123,456,789
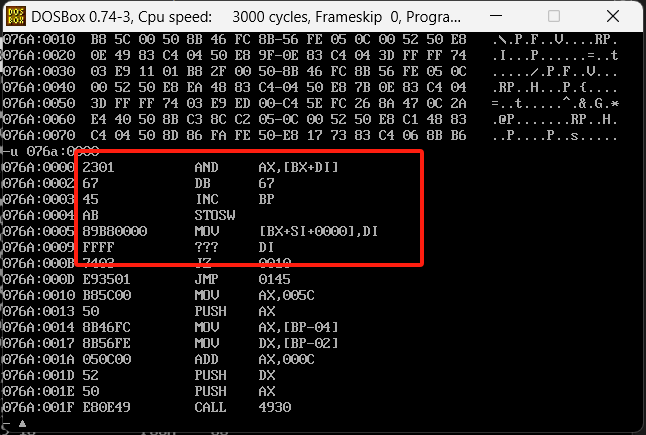
他把这些数据直接丢到了代码段,在汇编中,数据和指令是不会去做区分的,数据可以当作指令去执行,指令也可以当作数据去用。再去参考下面汇编代码
assume cs:code
code segment
dw 0123h, 4567h, 89ABh
mov ax, 0
code ends
end
把上面代码丢到debug中运行,再去查看代码段的内容会发现,前面数据都是对的,后面的mov指令变没了,出现这个问题主要是因为上面说的,数据和指令他不会去做区分,拿到什么内容既可以当作数据也可以当作命令,这里的数据堆起来之后变成了另外的命令,所以mov指令就没了
想要做到分离数据与指令,可以通过下面的汇编代码
assume cs:code
code segment
dw 0123h, 4567h, 89ABh
start: mov ax, 0
code ends
end start
主要是在数据定义完之后通过start创建一个指令入口,我们放到debug中查看一下与上面的区别
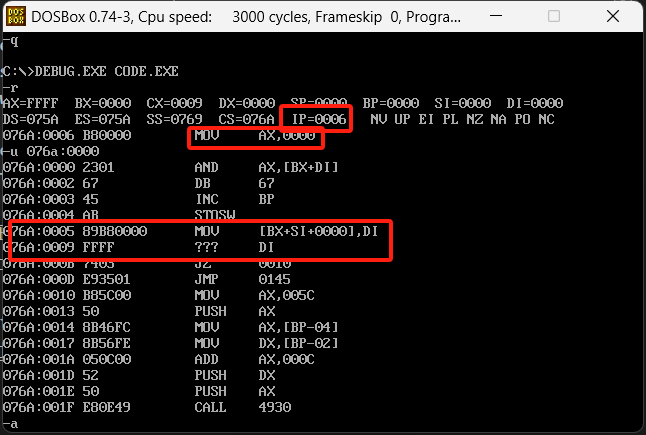
使用start的代码最终执行的时候IP会自动到指令的位置,而不是从头执行,虽然这里通过debug的u指令看到命令还是乱的,但是IP寄存器指向的位置却是一个正常的。
将数据、代码、栈放入不同的段
assume cs:code,ds:data,ss:stack
data segment
db 'Hello, world!'
dw 123h, 456h, 789h, 0ABh,0defh
db 3 dup (1,2,3)
db 3 dup ('abc','def')
data ends
stack segment
db 10 dup (0)
stack ends
code segment
start: mov ax, 0
code ends
end start
参考上面汇编代码,其中cs、ds、ss分别用来定义不通的段,这三个具体的含义参考如下
- cs:code: 将代码段寄存器(CS)关联到名为 code 的段,表示程序的指令存放在 code 段。
- ds:data: 将数据段寄存器(DS)关联到名为 data 的段,表示程序的数据存放在 data 段。
- ss:stack: 将堆栈段寄存器(SS)关联到名为 stack 的段,表示程序的堆栈存放在 stack 段。
然后这里还引入了一个dup指令,他的含义是数据需要多少份来放到对应的位置。例如上面的db 10 dup (0) 意为创建10份为0的数据。再data段的dw指令,后面的数据为什么都带0,原因是因为MASM是不支持16进制以字母开头的,全字母需要使用0来作为前缀
然后这里再具体说一下start的含义,他是用来定义代码运行的起始位置的,然后后面的end start是执行完成之后还会回到start的最初位置。我们运行一下代码,查看这些数据是什么形式存储的
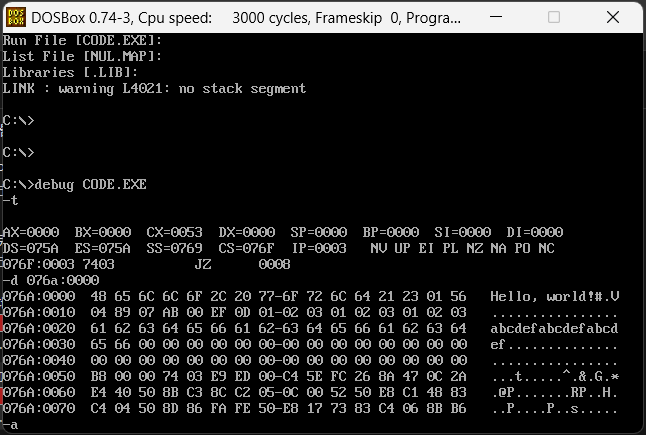
首先开启程序之后CS和IP寄存器和原本的不一样,原因是因为之前的位置都存储了数据,通过d指令去查看原本位置的内容,我们的代码存储了字母,字母的存储方式为字母的ascii码的16进制,丢到里面,然后以知道bcdef,也就是076A:0030的位置,填充完后面还是跟随了很多0,然后紧接着是栈段的10个0,但是他这里存储的不仅仅是10个,除去ef,就是14+16个0,为什么会这样?因为每一个段不是通过偏移来设置位置的,而是通过CS,CS是必须被16整除的,也就是说如果细分到16以内的位置只能通过偏移来找,就是说基础单位就是16个,最终的数据如果是没撑满这16位,那么剩下的他都会不作为,并且依旧作为当前段的内容,包括上面定义的stack。所以实际数据段和栈段的范围是这样的
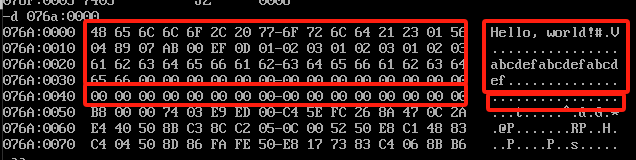
上面的红框是数据段,下面的红框是栈段。
OFFSET指令
offset是只能在编写代码文件时使用的指令,他的作用是获取某个数据的位置,具体可以参考下面汇编代码
assume cs:code
code segment
a: db 10 dup(10H)
b: db 10 dup(11H)
; start: mov ax,offset a[0]
; mov bx,offset b[0]
start: mov ax,offset a
mov bx,offset b
code ends
end start
直接查看内存中的内容,然后再去看要执行的内容,结果如下图
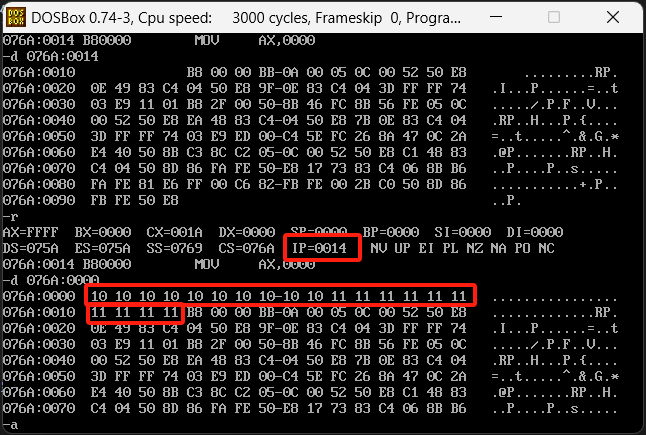
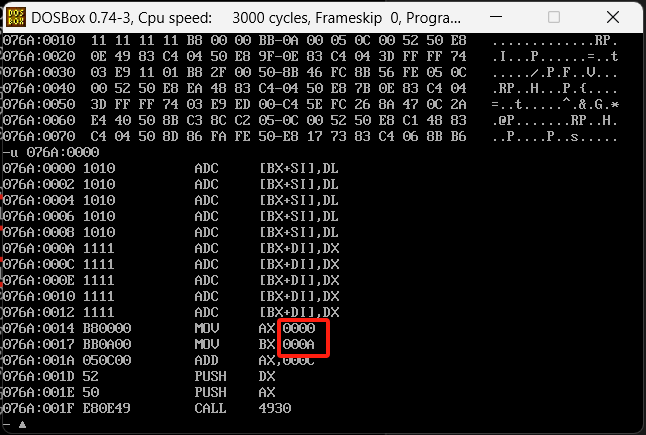
写入了10个10和11,在执行MOV的时候对应的值也是这俩数据的偏移位置,这就是offset的作用,用来查找对应数据的偏移值。
JMP指令进阶
jmp的作用是跳转,上面也实践了一下,他还有很多其他写法,这里列举一下
jmp short 近跳转,通过修改IP来跳转偏移,偏移量是一个有符号的 8 位数,范围为 -128 到 +127 字节。jump far ptr 远跳转,通过CS和IP来跳转,它可以实现很远的跳转。jmp near ptr 这个跳转是拿到数值的2个字节来跳转jmp dword ptr 这个跳转是拿到数值的4个字节来跳转
具体举个他们的例子,汇编代码如下
assume cs:code
code segment
start: jmp short a
; 如果这里不注释这256个db则是跳转不过去的,大家可以自己尝试
; 跳转不过去的原因是因为近跳转范围只有`-128`~`127`字节
; db 256 dup(0)
a:
mov ax,1H
jmp far ptr b
db 256 dup(0)
b:
mov ax,cs
mov ds,ax
mov ax,offset c
mov ds:[0],ax
jmp word ptr ds:[0]
c:
mov ax,offset d
; mov ds:[0],0000h
mov ds:[0],ax
mov ds:[2],cs
jmp dword ptr ds:[0]
d:
mov ax,0FFFFh
int 21h
code ends
end start
先看前3条执行过程,如下图,第一个jmp是采用一个偏移的方式,第二个jmp是采用一个地址段+偏移的方式
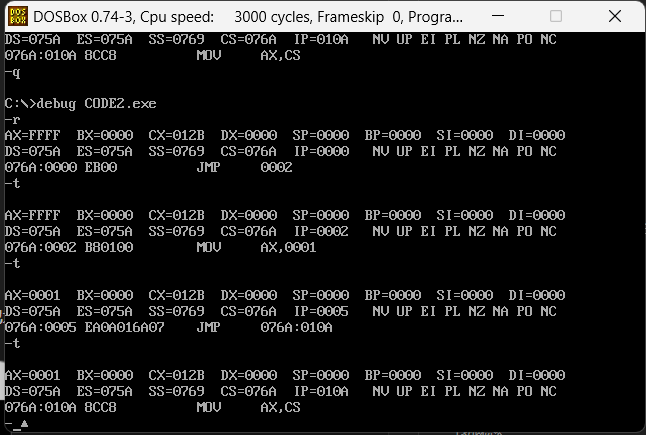
我们继续运行,查看第三个jmp,如下图,第三个jmp直接跳转DS的0000位置的地址
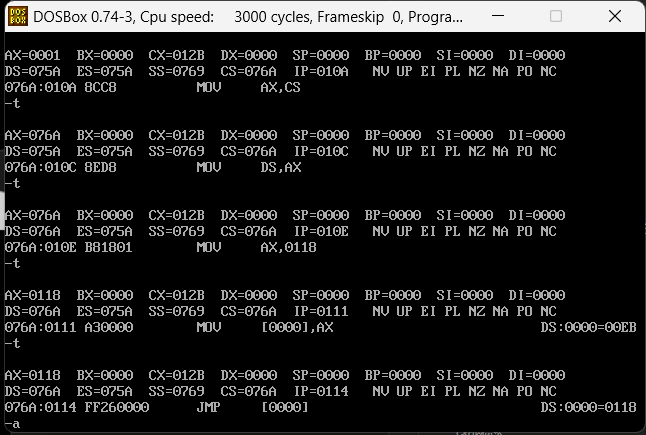
我们再去看一下这个DS:0000的内容,这个内容是什么那么他就会跳转到哪里,不出意外应该是在上图的倒数第三个位置,应该是0118,也就是C的偏移位置

因为有高低位平衡,所以这里是1801,实际就是0118,那这个偏移位置的内容是什么呢?我们继续用u指令看一下
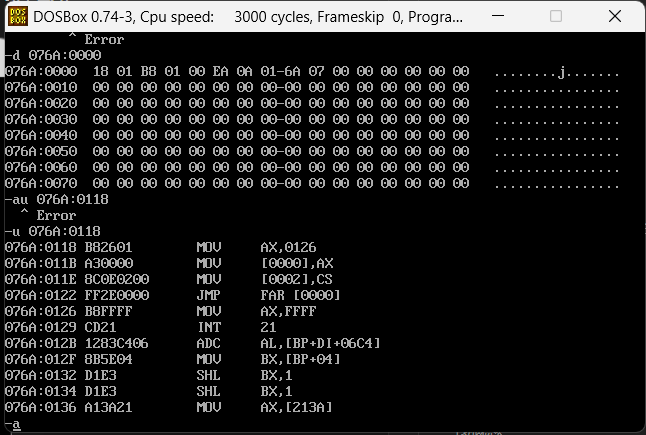
很明显这里就是C函数的入口,并且D函数的入口也被C的第一条指令打进了DS:0000的位置,然后采用JMP去跳转,我们先看一下jmp之前的DS:0000的内容,是不是076A:0126,我们继续运行
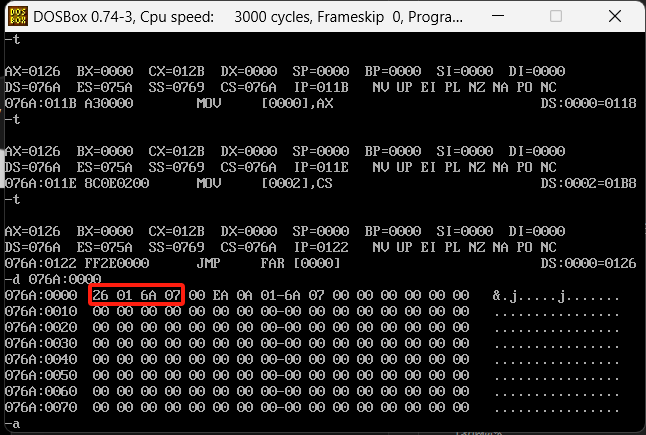
发现是没问题的,因为存在高低位平衡,所以是26016A07实际就是076A0126,分别指向下一个CS和IP的正确位置,我们继续运行
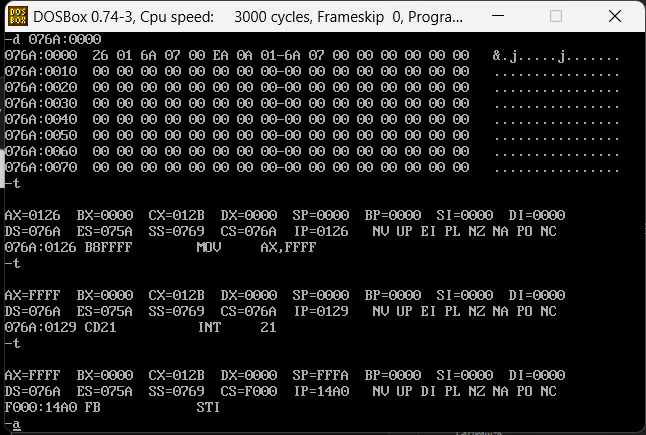
程序成功退出结束。
JCXZ指令
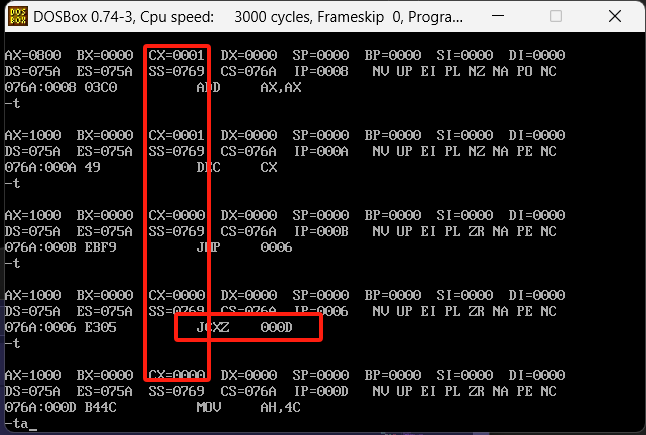
JCXZ是一条条件跳转指令,它的功能是检查CX寄存器是否为零,如果CX寄存器等于零,则跳转到指定的目标地址;如果CX寄存器不等于零,则继续执行下一条指令。具体参考代码如下
assume cs:code
code segment
mov ax, 2 ; AX初始值为2
mov cx, 11 ; CX设为11,表示循环11次
a:
jcxz done ; 如果CX为0,跳到done
add ax, ax ; AX = AX + AX(AX乘以2)
dec cx ; CX减1
jmp a ; 无条件跳回a,继续循环
done: ; 循环结束
mov ah, 4Ch ; 设置AH=4Ch,退出程序
int 21h
code ends
end
循环结束之后直接跳出了,这里需要一次性执行好多次t,可以自己修改代码,尝试个一两次知道怎么用就可以了。
TYPE伪指令
TYPE 可以用来查询某个变量的类型,返回其占用的字节数。简单举个例子,参考下面汇编代码
assume cs:code, ds:data
data segment
var1 DB 10h ; 定义一个字节变量
var2 DW 1234h ; 定义一个字变量
var3 DD 0DEADBEEFh ; 定义一个双字变量
data ends
code segment
start:
mov ax, TYPE var1 ; AX = 1(var1 是字节)
mov bx, TYPE var2 ; BX = 2(var2 是字)
mov cx, TYPE var3 ; CX = 4(var3 是双字)
int 21h
code ends
end start
数组的读取和写入
在代码段中读取和写入数组,直接上汇编代码,如下
assume cs:code,ds:data,ss:stack
data segment
data ends
stack segment
db 10 dup (0)
stack ends
code segment
arr db 12,34,56,78,9AH
start:
mov al,arr[2]
mov al,arr[4]
mov ax,word ptr arr[2]
mov si,offset arr
mov al,cs:[si+4]
mov al,cs:[si+6]
code ends
end start
我们看一下每个mov执行实际给的内容,如下图
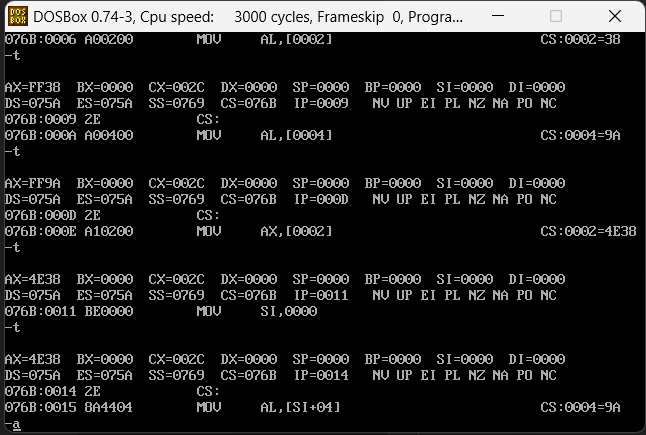
上面是执行了4次,我们挨个看内容,第一个把al设置成了数组中的第二个数据也就是56,56的16进制刚好为38,然后他继续去拿第四个位置的内容是9A,咱们定义的时候也是直接的16进制的9A,所以这里也是没问题的,然后有执行了一个ax为第二个内容,但是这里为什么是4e38呢?
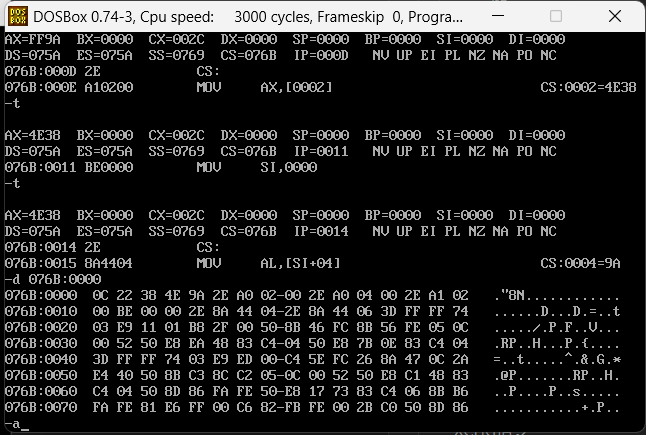
其实这里也是对的,通过d命令去查看这个位置的确就是这个内容。我们继续运行,查看内容
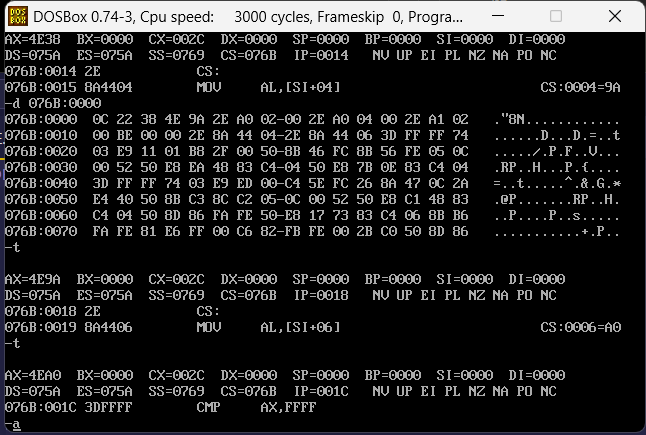
si拿到的数据是arr的0位偏移,也就是0000,这里拿到的内容也都是预期的。
上面的例子是基于代码段来去操作数据,下面来一个不同段的,原理都一样,主要是这里多了一个修改DS地址的指令,主要参考与下面汇编代码
assume cs:code,ds:data,ss:stack
data segment
arr db 10H,20H,30H,40H,50H
arr2 db 'hello world'
data ends
stack segment
db 10 dup (0)
stack ends
code segment
start:
mov ax,data
mov ds,ax
mov al,arr[2]
code ends
end start
我们执行以下看一下al的数据,如下图
还有一些额外写法都可以参考上面代码段中使用数组的汇编代码,这里DS修改之后就全都对的上了。然后如果数组不加[]那么他就是直接引用0的偏移位置。
写在后面
上面均为自己学习整理的笔记,仅限参考,也欢迎大佬指出错误,非常感谢。
导出:https://wwsj.lanzout.com/ioEnQ2qt3owh 密码:52pj
密码:52pojie.cn



 发表于 2025-3-16 17:57
发表于 2025-3-16 17:57
 |
发表于 2025-3-16 20:12
|楼主
|
发表于 2025-3-16 20:12
|楼主




 收藏
收藏 淘帖
淘帖 有用
有用 分享到朋友圈
分享到朋友圈
