本帖最后由 夏无道 于 2019-1-25 21:11 编辑
新年快到了,提前祝大家新年快了~
题外话:不列外,今年支付宝也有五福活动,但今年每天扫五福有限制。只能扫一定次数(严格来说,扫到一定张数的福卡,就不能扫了,我是扫到3张就不能扫了。)
论坛有win版的工具,但为什么我还要写这个工具呢?主要是,最近在学习vue,想找点简单的东西来练练手。
其实最简单的方法,就是去百度搜索“福字”就行了。http://image.baidu.com/search/index?tn=baiduimage&ps=1&ct=201326592&lm=-1&cl=2&nc=1&ie=utf-8&word=%E7%A6%8F%E5%AD%97
之所以写这个工具,就仅仅是为了练手,同时分享一点编程的乐趣~~~
截图:

正题:
1. 代码:https://github.com/Xwudao/alipay_blessing
2. 使用说明:
使用
克隆
克隆(clone)到你的本机,运行命令:
npm run install
or 淘宝镜像
cnpm run install
若进行二次开发,则最好
修改 webpack.config.js文件里的mode属性的值为development(开发模式)
默认为production(生产环境)
打包
运行命令
npm run build
进行打包,打包在dist目录
数据
数据存在data.json文件
演示
http://api.misiai.com/blessing
编写过程【重点】:编写过程中最开始仅仅是想采集到百度的网址就行,但是死活不能用在项目中,一直报错(403)。所以,直接采集图片并上传到图库罢了。
于是用python采集百度图片地址:
index.py 采集百度地址
[Python] 纯文本查看 复制代码 # -*- coding: utf-8 -*-
# [url=home.php?mod=space&uid=238618]@Time[/url] : 2019/1/25 18:17
# [url=home.php?mod=space&uid=686208]@AuThor[/url] : 无道
# [url=home.php?mod=space&uid=267492]@file[/url] : index.py
# @Software: PyCharm
import hashlib
import os
import requests
def get_link(key, n):
url = 'https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord={word}&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word={word}&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&cg=girl&pn={pageNum}&rn=30&gsm=1e00000000001e&1490169411926='
url = url.format(word=key, pageNum=str(n))
res = requests.get(url)
links = []
types = []
for data in res.json()['data']:
try:
links.append(data['middleURL'])
types.append(data['type'])
except:
try:
links.append(data['thumbURL'])
types.append(data['type'])
except:
pass
# print(len(links))
return links, types
def get_md5_value(str):
my_md5 = hashlib.md5() # 获取一个MD5的加密算法对象
my_md5.update(str.encode('utf-8')) # 得到MD5消息摘要
my_md5_digest = my_md5.hexdigest() # 以16进制返回消息摘要,32位
return my_md5_digest
def write_to_file(url, type):
data = requests.get(url).content
with open("images/" + get_md5_value(url) + "." + type, "ab+") as f:
f.write(data)
f.close()
def process():
n = 0
while (30 * 100 > n):
n += 30
print("===============正在爬取===============")
links, types = get_link("福字", n)
for i, link in enumerate(links):
type = types[i]
write_to_file(link, type)
print("写入:" + link)
def main():
process()
if __name__ == '__main__':
main()
注意:需要在同目录下建立images文件夹
upload_img_to_share1223.py 上传图片到图库
[Python] 纯文本查看 复制代码 # -*- coding: utf-8 -*-
# @Time : 2019/1/25 19:18
# @Author : 无道
# @File : upload_img_to_share1223.py
# @Software: PyCharm
import os
import requests
def get_file_by_directory(filepath):
path_dir = os.listdir(filepath)
files = []
for allDir in path_dir:
child = os.path.join('%s\\%s' % (filepath, allDir))
# print(child.decode('gbk'))
# print(child)
files.append(child)
return files
def upload(file_path):
url = "https://sm.ms/api/upload"
files = {
"smfile": open(file_path, "rb")
}
res = requests.post(url, files=files)
data = res.json()
upload_url = ''
# print(res.json())
# {"code":"success","data":{"width":500,"height":457,"filename":"0a3225066d2f4e7e2f654cab5eca753e.jpg","storename":"5c4af214544cb.jpg","size":26963,"path":"\/2019\/01\/25\/5c4af214544cb.jpg","hash":"MQZslVH5WFGJXuU","timestamp":1548415508,"ip":"220.166.2.223","url":"https:\/\/i.loli.net\/2019\/01\/25\/5c4af214544cb.jpg","delete":"https:\/\/sm.ms\/delete\/MQZslVH5WFGJXuU"}}
try:
upload_url = data['data']['url']
except:
pass
# print(upload_url)
return upload_url
def write_to_file(data_url):
with open("url_list.txt", "a+") as f:
f.write(data_url + "\n")
f.close()
def process():
images_urls = get_file_by_directory("images")
for img in images_urls:
url = upload(img)
if url != '':
write_to_file(url)
print("写入:" + url)
def main():
process()
if __name__ == '__main__':
main()
但是该图库网站有上传限制,我仅仅是上传了不到100条就禁止了,所以就没上传了。
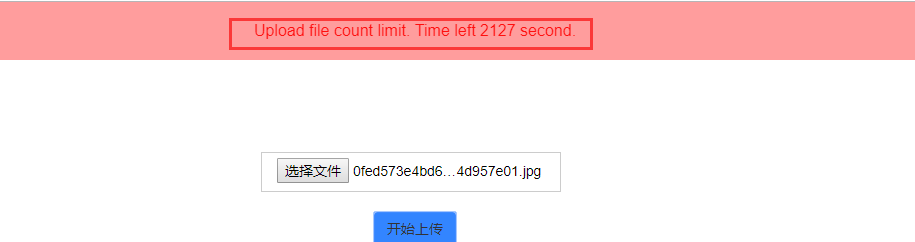
运行该文件后,会生成url_list.txt文件(一行一个),但是我们存储在项目中是以json格式的,所以需要稍微转换下。
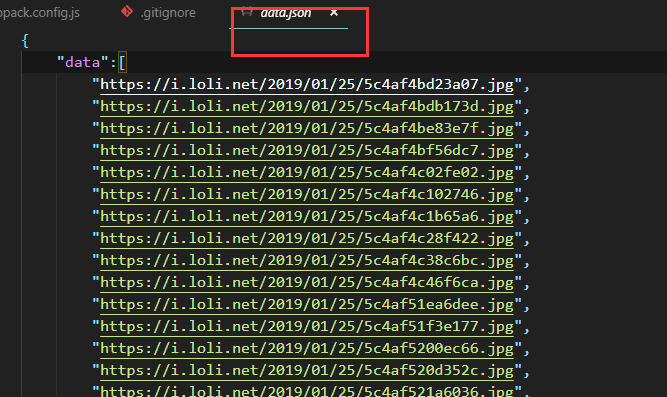
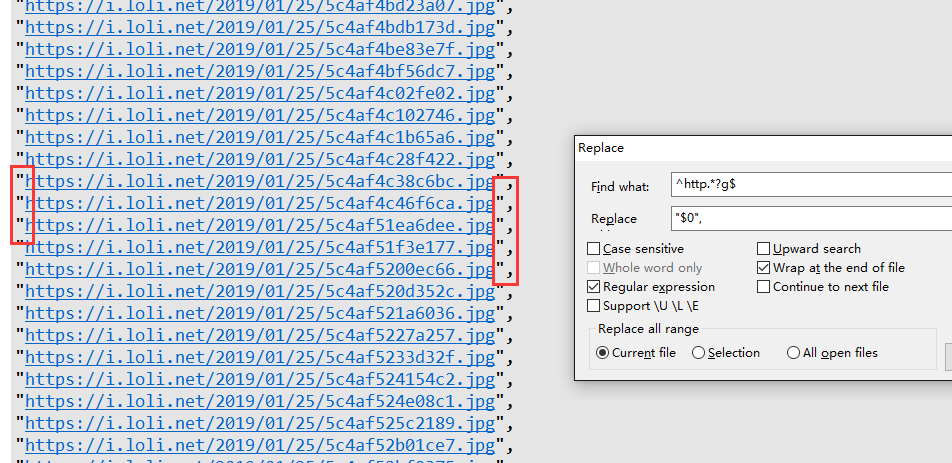
最后祝大家都扫到花花卡!!
PS:虽然估计仅得的到几元钱,但好歹是马云爸爸给你发的2333333 | 
 发表于 2019-1-25 20:41
发表于 2019-1-25 20:41
 |
发表于 2019-1-25 21:09
|
发表于 2019-1-25 21:09




