转自:https://xz.aliyun.com/t/3422
(接上文)
入口点逆向分析
在第一篇文章中,我们已经给出了数据库的定义,现在,我们再来回顾一下。数据库是一组二进制文件,用于存放结构化数据和相互之间的交叉引用。现在,我们只对定义的第一部分感兴趣,即文件中的数据是结构化的。这里的结构属性,则意味着文件是具有相同格式的记录组成的。例如,文件catalogue的单个记录用于描述单个车辆。因此,在定义一个记录的格式后,就会自动定义所有记录的格式。换句话说,对于上图来说,只要弄清楚了Bob Cat ML 1980相关的字节的含义,就足以理解所有其他车辆相关字节的含义。但是,文件实际上很少仅包含单种类型的记录,实际上,它们通常是由多个表组成的,并且不同的表通常存放的是不同格式的记录。
如何对记录格式和文件格式进行逆向分析?所有针对文件格式的逆向分析技术都适用于该任务(回想一下第一篇文章中抽象级的层次结构,当时已将数据库逆向分析置于顶部)。实际上,这些技术的面世时间已经很长了(具体参见文章末尾的参考文献部分),下文中我们将用到它们。
对文件进行逆向分析时,第一步就是确定文件中表的数量。为此,可以通过观察不同格式的相邻记录来完成这一任务。我们以grpinc.dat文件为例。请查看下面的屏幕截图,其中两种记录格式的区别是非常明显的,我们可以轻松区分开来。


其中,四个彩色的记录可能与表1相关,其后的纯文本则可能与表2相关。表1中每个记录的大小为0x3A字节。但是,表2中的记录的大小则是未知的,也许所有这些文本都只是单个硕大的记录。不过,我们可以得出这样的结论:grpinc.dat文件包含2个表,即包含两种不同的记录格式。这只是一个非常简单的例子。有时您可能遇到具有高熵的二进制文件,这时,我们就只能通过某些字节模式的消失/出现来确定从一个表到另一个表的切换情况。然而,这时只靠肉眼来区分就有点难度了。
现在,让我们回到catalogue文件。查看整个文件后,我们没有发现任何对比明显的数据:开头和结尾部分都有车辆名称。

FNAc.dat文件的开头部分

FNAc.dat文件的结尾部分
接下来,我们需要确定单个记录的大小。为此,我们需要找出相应的模式,并计算两个相邻模式的间距。下面,让我们来看一个具体的例子。让我们在catalogue文件的开头部分寻找重复出现的信息。需要注意的是,这里谈论的是信息的含义,而不是那些重复的字节内容。就这里来说,重复出现的信息是车辆名称,即以“!CAT”开头的字符串和以“VL”开头的字符串。实际上,这里共有三种不同的模式,现在,让我们取其中一种模式,即车辆名称模式,然后计算第一个和第二个车辆名称之间的间距。


这里的间距是0x800-0x0 = 0x800。因此,文件catalogue中保存的记录的大小为0x800字节。这是一种非常重要的文件格式逆向分析技术,我们应该熟练掌握它(当然,其他的非也应该熟练掌握)。另外,其实没有必要采用最前面两个或最后面两个记录来计算模式之间的间距。当确定位于文件中间部分的记录的大小时,即使不知道记录的起始字节在哪里,仍然可以设法计算出它们之间的间距。
现在,是将这些结果记录下来的时候了。下面,我们将使用前一篇文章中提到的Kaitai Struct来描述文件格式。如果将来需要以编程方式处理文件的话,可以使用KS支持的编程语言轻松地将文件格式的描述转换为相应的代码。到目前为止,我们对catalogue文件的了解,仅限于其记录的大小,因此,我们将其内容视为原始字节来对待。
meta:
id: catalogue
file-extension: dat
endian: le
encoding: ascii
seq:
- id: vehicle
type: vehicle
repeat: eos
types:
vehicle:
seq:
- id: unk_1
size: 0x800
Kaitai Struct有一个可视化工具,名为ksv,具体显示如下。

接下来,您需要逐步调查记录字段,而不是一次考察单个大字段(在我们的示例中为0x800字节)。为此,有许多方法可用,但是具体取决于字节的异构性。在我们的例子中,您可以看到几乎所有字节都是字符串字符,因此,我们可以将一个字符串从其开头到下一个字符串的开头之间的内容划分为单个字段。完成该操作后,我们将得到如下所示的记录格式。
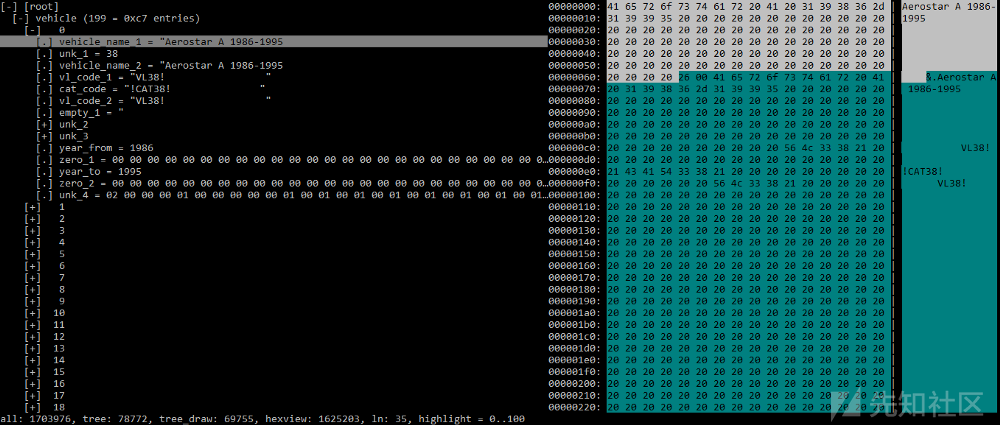
让我们分析每个字段。从记录开头到最后一个空格字符之间的第一个0x64字节,名为vehicle_name_1,其内容为汽车名称。接下来的两个字节(0x0026)可能是一个单独的字段,但其含义目前还不清楚,因此,我们将其命名为unk_1。那么,我们该如何确定它是一个单独的字段,还是这两个字节属于前一个字符串,甚至属于下一个字符串呢?没有灵丹妙药,我们应该做出假设并进行类推:如果所有字符串都以空格字符(0x20)结尾且没有NULL字节,则第一个字符串则是个例外,这是不太可能的。此外,这两个字节还可能是表示第二个字符串的长度的字段,但是,首先,其长度为0x64(从“Aerostar”到“VL38!”),其次,它似乎再次成为例外,这是非常值得怀疑的。我们需要检查该假设对其他记录的有效性(记住,我们现在讨论的是第一个记录),以确保该假设对它们都有效。
unk_1字段后面是vehicle_name_2,因为其内容是vehicle_name_1的副本。接下来的字段是vl_code_1和cat_code以及vl_code_2字符串,这些字符串以其值的前几个字母来命名。其中,前两个字段的大小为0x16字节。vl_code_2的长度可以是0x1A2字节,但是要具体视下一个“MX”字符串出现的位置,所以不要草率地将其大小设置为0x16。

事实上,vl_code_2字段在许多记录中具有与vl_code_1相同的值,所以,我们不妨假设它们的长度是相同的。另一方面,从vl_code_2 + 0x16偏移处到“MX”字符串之间的字节间距,在所有记录中都是0x20(个空格),因此,它们可以包含在vl_code_2字段中,但为了清楚起见,我们将它们划分到empty_1字段。
从“MX”字符串到“A”字符串之间为下一个假想字段,大小为0xD2。

事实证明,它是一个字符串数组,而非字符串,其中每个字符串的长度为0xA字节。将0xD2除以0xA,得到0x15,这就是数组的元素数量。这些字符串的具体含义尚不清楚,不过,其中某些字符串看起来像是国家代码(US,CA)或州代码(CA,MX),所以,不妨将该字段命名为unk_2。

再后面是“A”字符串,其长度可以直至充满最后0x20字节为止。利用前面类似的计算方法,我们发现,该数组有0x9个元素,每个元素的长度为0xC字节,在这里我们将其命名为unk_3。

剩余字节的含义目前还不太清楚,因为它们都不是字符串。

不过,我们不难看出这里有两个字(或双字),它们位于不同的位置,其中,第一个值是0x7C2,第二个值是0x7CB。如果将它们翻译成十进制数值的话,就会发现它们好像是两个年份:0x7C2 = 1986,0x7CB = 1995。大家还记得vehicle_name_1 = “Aerostar A 1986–1995”吗?由此看来,这两个数字分别表示生产年份的起止时间,所以,我们分别将其命名为year_from和year_to。
year_from和year_to之间的字节在所有记录中都是零,因此,我们将它们划归为大小为0x28的zero_1字段。在year_to之后,具有相同数量的归零字节,让我们将其划归为zero_2字段。其余字节的用途目前尚不清楚,所以,我们将其命名为unk_4。
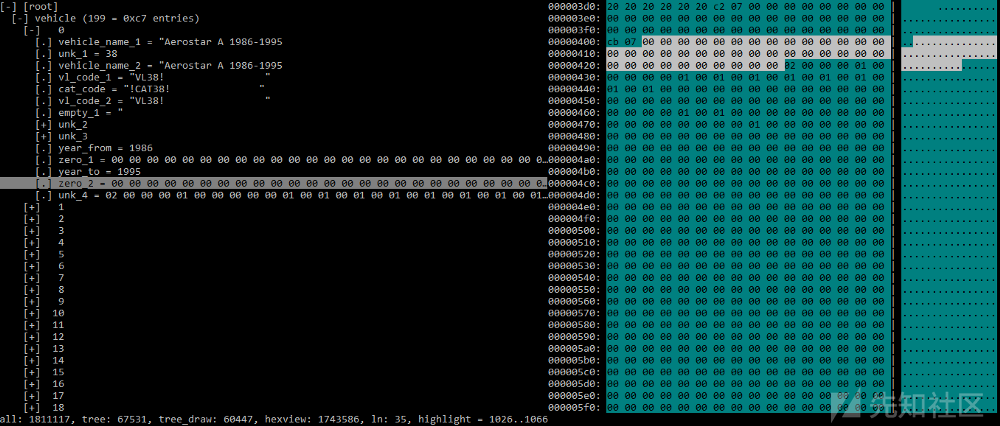
如果我们仔细浏览几条记录,unk_1和vl_code_1以及vl_code_2和cat_code字段就会引起我们的注意——我们会发现,unk_1的数字值以字符形式存在于这些字段中。因此,我们可以推断unk_1是车辆标识符,所以,我们将其重命名为vehicle_id。这时,文件格式变成下面的样子。
meta:
id: catalogue
file-extension: dat
endian: le
encoding: ascii
seq:
- id: vehicle
type: vehicle
size: 0x800
repeat: eos
types:
vehicle:
seq:
- id: vehicle_name_1
type: str
size: 0x64
- id: vehicle_id
type: u2le
- id: vehicle_name_2
type: str
size: 0x64
- id: vl_code_1
type: str
size: 0x16
- id: cat_code
type: str
size: 0x16
- id: vl_code_2
type: str
size: 0x16
- id: empty_1
type: str
size: 0x18C
- id: unk_2
type: str
size: 0xA
repeat: expr
repeat-expr: 0x15
- id: unk_3
type: str
size: 0xC
repeat: expr
repeat-expr: 9
- id: year_from
type: u2le
- id: zero_1
size: 0x28
- id: year_to
type: u2le
- id: zero_2
size: 0x28
- id: unk_4
size-eos: true
这是一个非常简单的示例,因为这里的研究目的只是确定每个字段的含义。在更复杂的情况下,研究过程中还需要假设字段类型和字段长度,搜索不同表的字段之间的交叉引用,等等。由于本文的重点是数据库的逆向工程,而不是文件格式的逆向工程,因此,我们不会对其他单独的文件进行详细分析,因为我们感兴趣的是更高级别的事情,即这些文件之间的瓜葛。
[2.7]研究并描述表示数据库入口点的文件格式。
顺便说一下,该数据库入口点是无可置疑的:我们没有发现对其他结构的任何依赖,并且,同时获得了足够的信息用于进一步的研究。
研究交叉引用
我们可以通过下列方式继续进行逆向工程:
- 根据已知信息搜索所需信息;
- 搜索所需信息并了解它与已知信息的交互方式。
第一种方法是获取字段值——例如vehicle_id、vl_code_1、vl_code_2、cat_code等字段——并在其他文件中搜索它们。如果在某些文件中发现了它们,则意味着catalogue文件与这些文件之间可能存在某种关联。第二种方式实际上就是搜索关键字,通过关键字查找包含所需信息的文件,对其进行逆向工程并显示这些文件和catalogue文件之间的交叉引用。我们可以将其视为互相指引的两种方式,它们是实现同一目标的两种方式。

研究交叉引用的两种方法
在生活中,事情要更复杂,所以这两种方式应该结合起来。首先,我们应该定义所需信息。根据“入口点选择”部分的图,下一个待研究的结构是车辆零件。研究零件图现在还不到时候,因为它们在概念上是通过零件与车辆相互关联的(如果这个假设是真的话)。下面,让我们看看该程序如何提供对车辆零件的访问的。

第一级部件树

第二级部件树
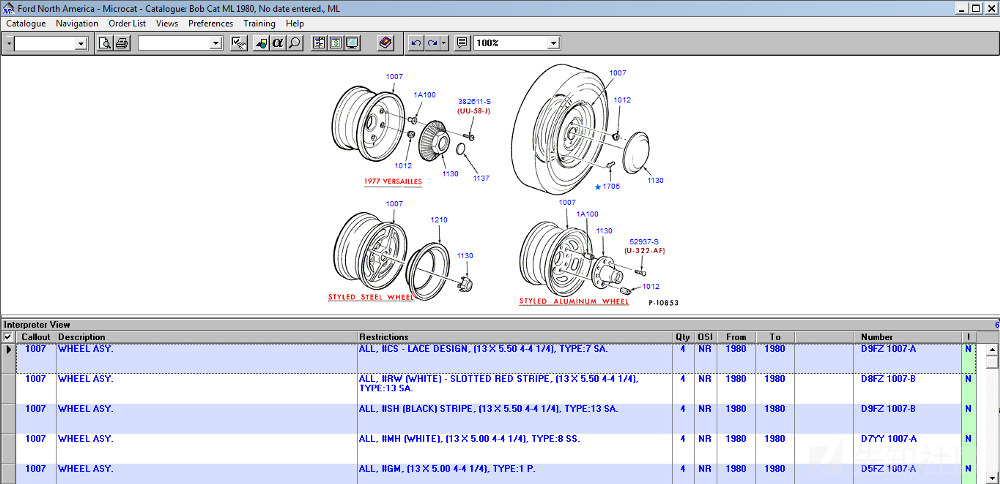
带有标记详细信息的零件图
选择车辆后,会显示一个部件列表(例如“10 WHEELS & RELATED PARTS”、“20 BRAKE SYSTEM”等)。当选择其中一个列表时,就会显示第二个部件列表(例如“10 WHEELS AND WHEEL COVERS WHEELS 1980–1980 [P10853]”等)。当选择相应的条目后,将显示零件列表,其中包含以零件编号命名的超链接,单击该超链接,则会弹出包含零件列表的底部菜单。目前,我们的目标是“接触”零件列表。
如您所见,车辆和零件通过两个部件列表绑定在一起的,我们称之为部件树。部件树有两个级别,分别名为“Alpha Index—Major”和“Alpha Index—Minor”,为简单起见,我们将其称为第一级和第二级。根据研究其他车辆数据库的经验,我们假设部件树和部件本身位于不同的数据结构或不同的文件中。这意味着我们应该调整一下目标路线:我们从车辆出发到达第一级部件树,然后从第一级部件树达到第二级部件树,最后到达零件级别。
进度条
如何实现这一目标呢?如果在文件中搜索第一级部件树中的相关名称(如“10 WHEELS&RELATED PARTS”),那么,在包含所有本地化程序字符串的FEULex.dat文件中只会找到一个匹配项。然后,我们可以据此算出到达字符串的偏移量,并再次在文件中以little-endian字节顺序进行搜索,并且这次要偏移四个字节——这是一种有效的技术,但对本例来说不起作用,因为FEULex.dat被偏移引用而不是从文件的开头。
下面,我们将介绍另一种强大的技术,重要的是,这种技术还非常简便。该技术是基于[2.1]方法的,这说明将程序视为DBMS是非常有意义的。由于它是DBMS,所以,肯定会向DB发送请求,即从文件中读取数据。因为DBMS必须高效运行,所以,它不会在启动时就将所有文件都读入内存。因此,当用户通过单击某些菜单、按钮等方式对程序发出相应的请求时,就会进行相应的文件访问。因此,我们可以判断出用户操作期间程序访问了哪些文件,即从包含所有文件的全集中选择了哪些包含所需数据的文件子集。
要想监视文件的访问操作,我们需要使用打过补丁的ProcMon。其中,该补丁程序的作用是将Detail 列中十进制数改为的十六进制数,具体可以参考下面的屏幕截图。

原始的ProcMon

打过补丁的ProcMon
因此,我们能找出哪个文件代表第一级部件树。让我们启动ProcMon,并建立两个过滤器,即“Process Name is ntvdm.exe”和“Operation is ReadFile”,然后,终止监视器。启动程序,选择车辆,再次使用ProcMon启动监视器,然后,单击车辆数据加载按钮。


在读取第一级部件树时,程序所引用的文件其实很少,只有MCData.idx、MCData.dat、XGROUPS.idx、FEULex.dat和LexInd.idx。其中,最后两个文件与前面已经说过的本地化字符串有关。而XGROUPS.idx看起来并不是我们所感兴趣的,并且没有包含任何与部件树有关的线索。所以,我们只需搜索前两个文件的内容就行了。
[2.8]当程序要加载您感兴趣的数据时,监视它们对文件所执行的访问操作。
从现在开始,有趣的事情就全部结束了,剩下的就是繁琐的逆向分析工作了。需要说明的是,这里不会介绍这些文件的具体研究过程,因为针对每一个文件的分析过程,都值得单独发表一篇文章。为了理解它们,我花了一个多月的时间,当然,期间也研究了其他一些文件。下面是一个小结。
Name: MCData.idx
Size: 5,5 MB
Format: binary
Number of tables: 4 (2 headers + 2 data tables)
Purpose: binds a vehicle (vehicle_id) to the first part tree level (ai_major_id), the first level to the second level (ai_minor_id), the second level to a part list (part_list_offset) in MCData.dat and to part diagrams (image_offset) in MCImage.dat and MCImage2.dat
Name: MCData.dat
Size: 1,5 GB
Format: encrypted text
Purpose: consists of a part list at part_list_offset for each tree
这里必须讲一讲[2.1]方法的第二种衍生方法。通过使用ProcMon进行监控获得另外两个发现可以加深对文件内部机制的理解:
- 程序每次执行读取操作时的块偏移和块大小;
- 块的读取顺序。
我们知道,所谓的块,就是由多个字节组成的一个整体;并且,程序会逐块读取数据,而一个块通常代表一个记录。如果知道了块偏移量和块大小,我们就可以确定第一个表记录、表记录大小、表记录的数量以及表的数量(记录的大小不同,则意味着它们是从不同的表中读取的)。一旦了解了块读取的顺序,我们就可以规划文件的研究过程:如果程序首先读取表1,然后再读取表2,那么,我们最好从表1开始研究,因为,很可能只有理解了第一个表,才能理解第二个表。
此外,有时块读取顺序的知识还能够帮助我们理解程序的实现算法。我们不妨来看看下面的截图。
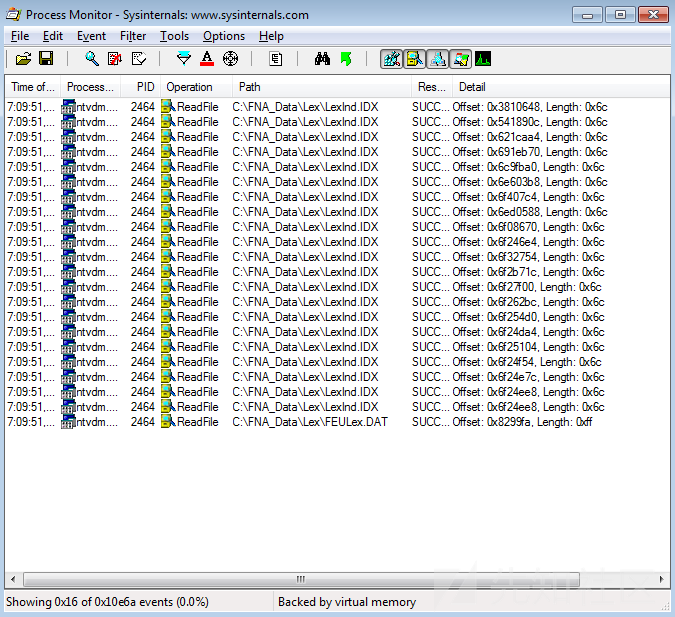
在这里,我们看到许多来自LexInd.idx的“随机性的”读取操作,然后是来自FEULex.dat的一个“精确的”读取操作。如果我们弄清楚了程序执行这些操作的原因(源于用户的某个操作),并将LexInd.idx的最后一次读取操作与其他读取操作进行比较,那么,就会发现这显然是在进行二进制搜索。就这里来说,程序先在LexInd.idx中搜索字符串ID,然后读取字符串偏移量,继而从FEULex.dat中读取相应的字符串。理解该算法能够帮助我们更快地了解这两个文件。
[2.9]借助监视期间收集的块偏移、块大小和块读取顺序等知识来研究文件。
小结
下面,我们将对前面进行的研究进行总结。我们弄清楚了车辆结构、部件树和零件信息存放在哪些文件中,以及这些文件的结构和它们之间的交叉引用。下面,我们用图形将其展示出来。
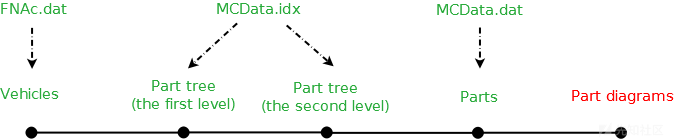
进度条

数据库架构
然而,这些并不是最重要的事情。实际上,本文的主要目标,是向读者介绍如何使用自己开发的方法对数据库进行逆向分析。在这个过程中,我试图从两个层面加以阐释,其中一个层次是关于独立于任何数据库内部的原则,另一个层次是将这些原则应用于实际的数据库研究,以证明它们的可行性和实用性。
在下一部分中,我们将使用代码重用方法来访问零件图,借以探索数据库的内部运行机制。届时,我们将开始与反汇编程序和调试程序打交道。
参考资料
主要方法清单
第一种数据库逆向分析方法
初步分析
- [2.2]对待处理的数据和代码进行初步分析。对于在审查期间找到的关键字,可以通过互联网进行搜索,尽量挖掘更多的信息。
- [2.3]审查各个程序模块,查找可重用代码。在数据库逆向分析的过程中,需要定期应用该方法,之所以这么做,是因为许多时候并不清楚哪些代码是可重用的,哪些不是。
- [2.4]代码重用的复杂性与黑盒子的数量成正比,与其执行的动作数量成反比。
研究入口点
- [2.5]选择数据库入口点:离初始入口点越近,需要预先研究的结构就越少。理想情况下,所需的入口点正好就是初始入口点。
- [2.6]考察代表数据库入口点的文件。
- [2.7]研究并描述表示数据库入口点的文件格式。
研究交叉引用
- [2.8]当程序要加载您感兴趣的数据时,监视它们对文件所执行的访问操作。
- [2.9]借助监视期间收集的块偏移、块大小和块读取顺序等知识来研究文件。
(未完待续)

 [复制链接]
[复制链接]
 发表于 2019-1-31 09:35
发表于 2019-1-31 09:35



